Sementic imaga segmentation은 라벨을 사용해 입력 이미지의 특정 영역을 표시하는 컴퓨터 비전 분야입니다.
오늘은 PyTorch에서 지원하는 DeepLabV3 모델을 TorchScript로 변환해 iOS 직접 올려보도록 하겠습니다.
1. Xcode 프로젝트 생성
iOS 앱을 개발하기 위해 프로젝트를 생성하겠습니다. 먼저 Xcode에서 DeepLabV3 앱을 만들기 위한 프로젝트를 생성합니다.
1-1. Xcode 실행하기
Xcode를 실행하면 다음과 같은 시작 화면이 나옵니다. Create a new Xcode project를 클릭해 새로운 프로젝트를 생성해주세요.
1-2. 템플릿 선택하기
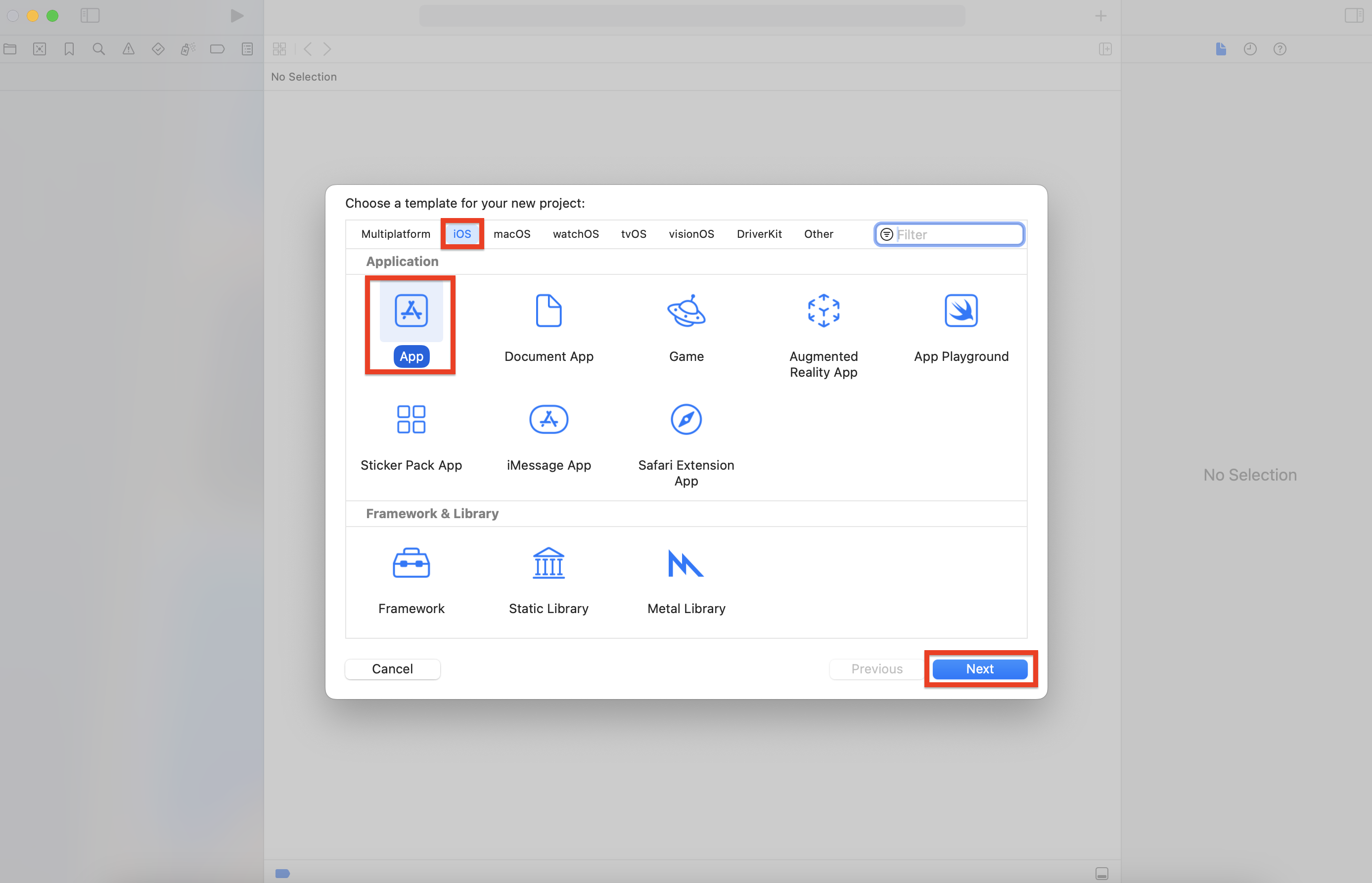
새 프로젝트를 시작할 템플릿을 선택하는 창이 나타납니다. 각 템플릿에는 앱을 개발하는데 필요한 기본 틀이 용도별로 설정되는데, 여기서는 [iOS] 탭의 [App]을 선택한 후 [Next] 버튼을 클릭해주세요.
1-3. 프로젝트 기본 정보 입력하기
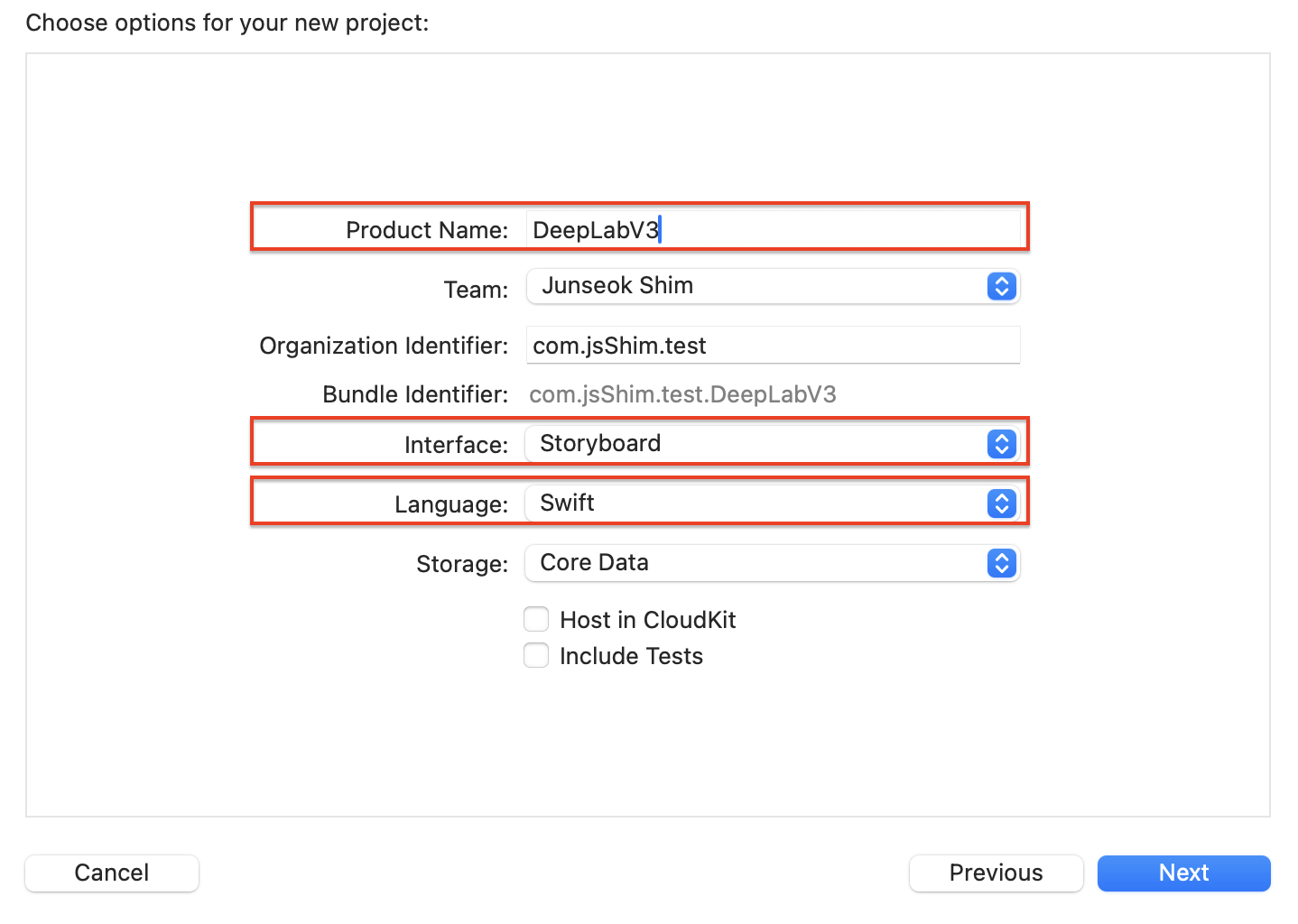
프로젝트 기본 정보를 입력하는 창이 나오면 다음과 같이 선택한 후, [Next] 버튼을 클릭해 주세요.
Product Name : 'DeepLabV3'
Interface : 스토리보드(Storyboard)
Language : Swift
그리고 아래와 같이 프로젝트 저장 팝업이 나올 경우, 저장할 작업 폴더 선택 후 [Create] 버튼을 클릭하세요.
1-4. 프로젝트 생성 완료
HelloWorld 프로젝트가 만들어졌습니다. 화면 왼쪽의 내비게이터 영역에 프로젝트 파일들이 있는 것을 볼 수 있습니다.
2. DeepLabV3 모델을 iOS 배포용으로 변환
iOS 애플리케이션을 본격적으로 만들어 보기 전에 iOS 배포를 위해 DeepLabV3 모델을 TorchScript로 변환하도록 하겠습니다.
2.1 TorchScript 모델 생성을 위한 준비
DeepLabV3 프로젝트의 가장 상위 경로에 traced_model_save.py 파이썬 스크립트를 생성해 주세요.

traced_model_save.py에 아래와 같은 코드를 넣고 실행하겠습니다.
(실습 3.1)
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile # --- (1)
model = torch.hub.load('pytorch/vision:v0.11.0', 'deeplabv3_resnet50', pretrained=True) # --- (2)
model.eval() # --- (3)
scripted_module = torch.jit.script(model) # --- (4)
optimized_model = optimize_for_mobile(scripted_module) # --- (5)
optimized_model.save("DeepLabV3/deeplabv3_scripted.pt") # --- (6)
optimized_model._save_for_lite_interpreter("DeepLabV3/deeplabv3_scripted.ptl") # --- (7)
(1)
torch.utils.mobile_optimizer모듈에서optimize_for_mobile함수를 가져옵니다. 이 함수는 모바일 기기에서 실행될 모델의 성능을 최적화하는 데 사용됩니다. 모바일 환경에 최적화된 모델은 더 빠른 추론 시간과 감소된 모델 크기를 제공합니다.
(2)torch.hub.load를 사용하여 사전 훈련된DeepLabV3모델을 로드합니다. 여기서 사용된 모델은deeplabv3_resnet50이며, 이는ResNet-50백본을 사용하는DeepLabV3모델입니다.pretrained=True옵션은 사전 훈련된 가중치를 사용하여 모델을 로드한다는 의미입니다.
(3) 모델을 평가(evaluation) 모드로 설정합니다. 이 모드에서는 모델을 추론에 사용할 준비가 되며, 학습 시에만 필요한 특정 연산들이 비활성화됩니다. 예를 들어, 드롭아웃(dropout)과 같은 연산이 비활성화됩니다.
(4)torch.jit.script를 사용하여 모델을TorchScript로 변환합니다.TorchScript는 파이썬 코드를 기반으로 하는PyTorch모델을 하드웨어에 종속되지 않는 중간 표현(intermediate representation, IR)으로 변환하는 과정입니다. 이는 모델을 다양한 플랫폼에서 실행할 수 있게 해 줍니다.
(5)optimize_for_mobile함수를 사용하여TorchScript로 변환된 모델을 모바일 기기에서 실행하기 위해 최적화합니다. 이 과정은 모델 크기를 줄이고, 실행 속도를 향상시키며, 모바일 기기의 리소스를 효율적으로 사용하도록 돕습니다.
(6) 최적화된 모델을DeepLabV3/deeplabv3_scripted.pt파일로 저장합니다..pt확장자는PyTorch모델의 표준 저장 포맷입니다.
(7)_save_for_lite_interpreter메소드를 사용하여 모델을 라이트 인터프리터 형식으로 저장합니다. 파일은DeepLabV3/deeplabv3_scripted.ptl로 저장됩니다. 이 형식은 모바일 기기에서의 실행을 더욱 최적화하기 위해 설계되었으며,PyTorch의 라이트 버전인PyTorch Mobile에서 사용됩니다.
2.2 TorchScript 모델 생성
VScode Terminal 또는 다른 터미널에서 traced_model_save.py를 실행해주세요.
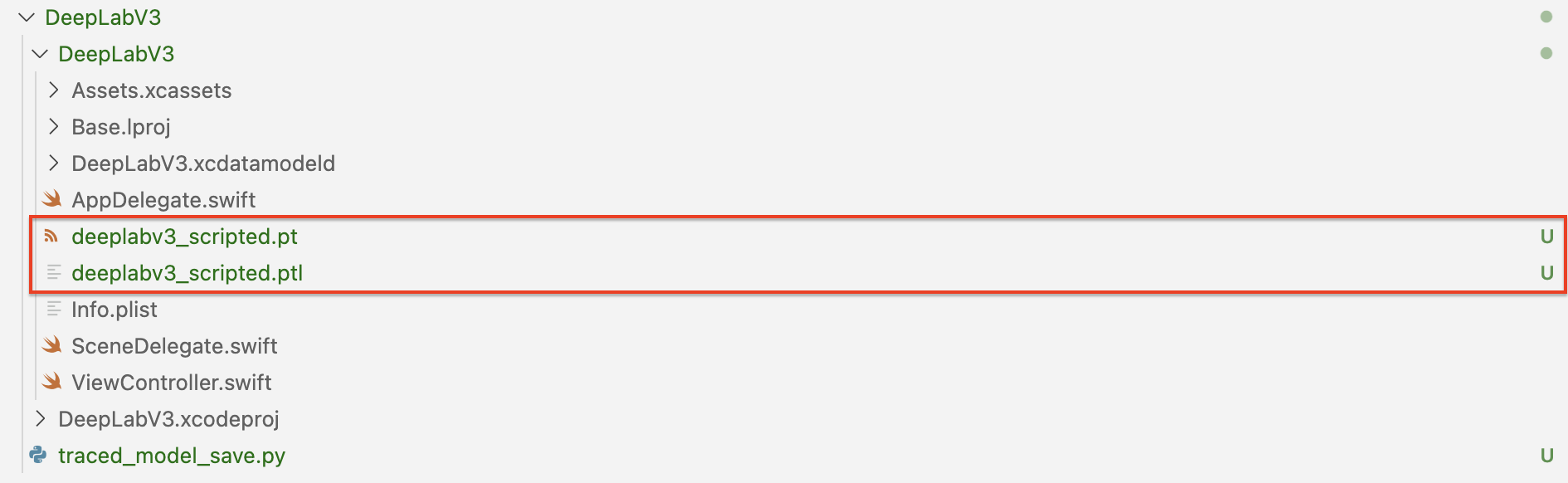
python traced_model_save.py정상적으로 실행됐다면, DeepLabV3 폴더에 deeplabv3_scripted.pt와 deeplabv3_scripted.ptl가 생성됩니다.
3. CocoaPods와 Podfiles로 iOS 개발 환경 의존성 관리
*CocoaPods는 macOS 및 iOS 프로젝트를 위한 의존성 관리자입니다. 오픈 소스이며, Objective-C, Swift, 그리고 모든 Cocoa 터치 프레임워크에서 사용할 수 있는 라이브러리와 소프트웨어 컴포넌트를 통합, 관리하는 데 사용됩니다. CocoaPods를 사용하면 프로젝트에 필요한 외부 라이브러리들을 쉽게 추가하고 업데이트할 수 있습니다.
CocoaPods는 Podfile이라는 특별한 파일을 사용하여 프로젝트의 의존성을 선언합니다. 개발자는 이 파일에 프로젝트에 필요한 라이브러리와 그 버전을 명시할 수 있습니다.
*CocoaPods을 설치하기 위해서는 매킨토시 터미널에서
brew install cocoapods명령어를 입력하면 됩니다.
3-1. Podfile 생성
.xcodeproj 파일과 같은 경로 수준의 프로젝트 폴더 안에 Podfile이라는 텍스트 파일을 생성해야합니다. VSCode나 Xcode에서 텍스트를 생성해도 되고, 프로젝트 경로로 간 뒤 pod init 명령어를 실행해도 Podfile이 생성됩니다.

3-2. 의존성 추가
파일의 내용을 다음과 같이 수정해주세요.
# platform :ios, '9.0'
target 'DeepLabV3' do
# Comment the next line if you don't want to use dynamic frameworks
# Comment the next line if you don't want to use dynamic frameworks
use_frameworks!
# Pods for ImageSegmentation
pod 'LibTorch', '~>1.10.0'
end
pod 'LibTorch', '~>1.10.0 명령어를 통해, DeepLabV3 프로젝트에서 LibTorch 라이브러리를 추가하게 됩니다.
그런 다음 터미널을 이용해 프로젝트 폴더(.xcproject)로 간 뒤, pod install 을 입력합니다. 잘 입력했으면 아래와 같이 됩니다.

4. iOS DeepLabV3 애플리케이션
Xcode 를 다시 실행해야합니다. Xcode IDE를 닫고 터미널로 HelloWorld 프로젝트가 있는 경로로 가주세요. 그리고 .xcworkspace로 HelloWorld 프로젝트를 실행해주세요.
open DeepLabV3.xcworkspace4-1. 스토리보드로 작업하기 위한 기본 환경 구성하기
화면 구성을 위해 스토리보드를 설정하고 필요한 이미지 정보를 불러오겠습니다.
화면 창 조정하기
Xcode 화면이 처음 열렸을 때 화면 왼쪽의 네비게이터 영역에 [Main.Storyboard]를 선택하면 스토리보드가 화면에 나타납니다. [Main.Storyboard]를 클릭하면 아래와 같이 스토리보드가 보이게 됩니다.
이미지 뷰에 사용할 이미지 추가하기
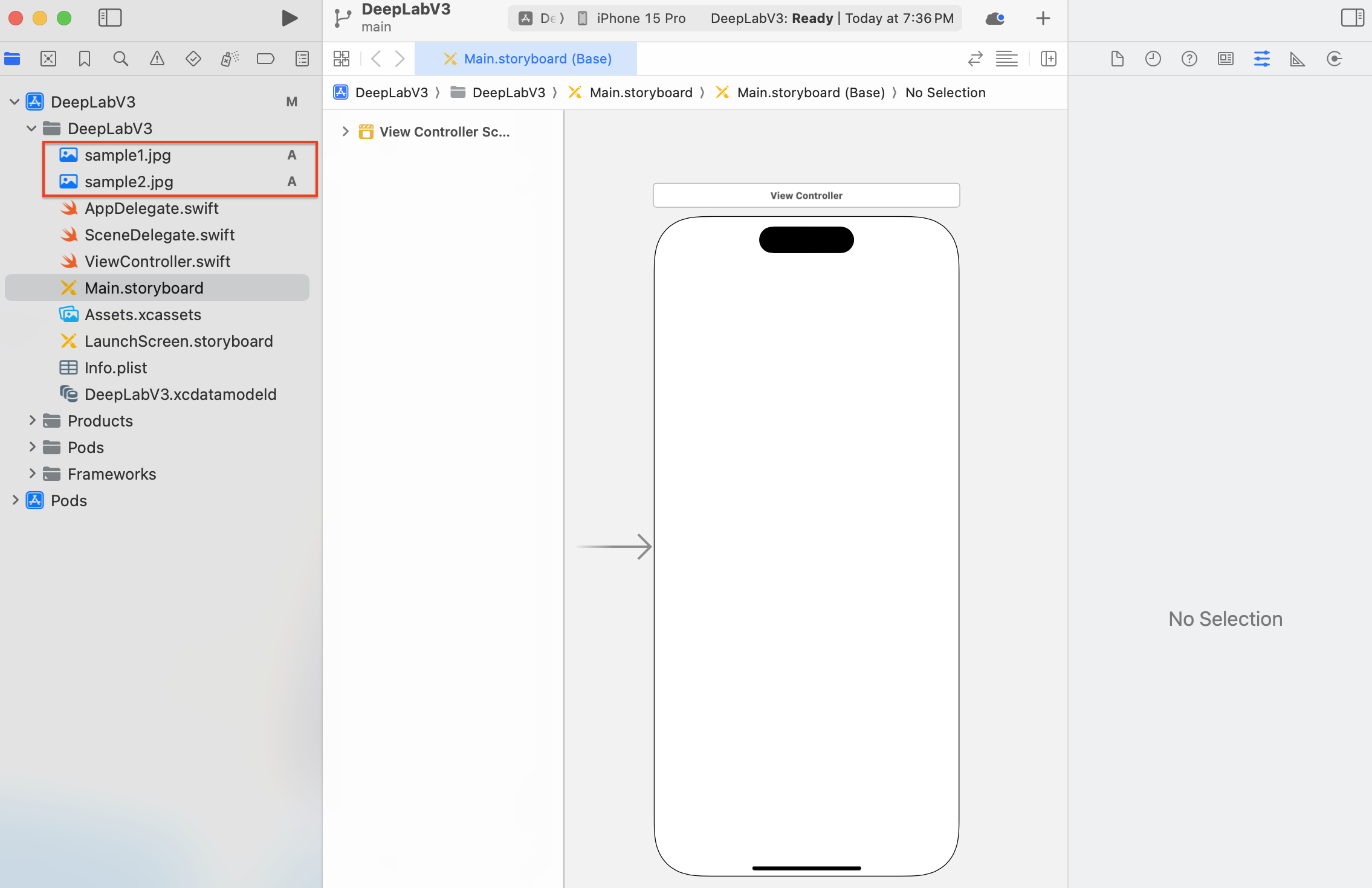
앱에서 사용할 이미지를 프로젝트에 추가해야합니다. 프로젝트에서 사용할 이미지 sample1.jpg, sample2.jpg를 선택하여 네비게이터 영역의 DeepLabV3 폴더 아래로 Drag&Drop해주세요.
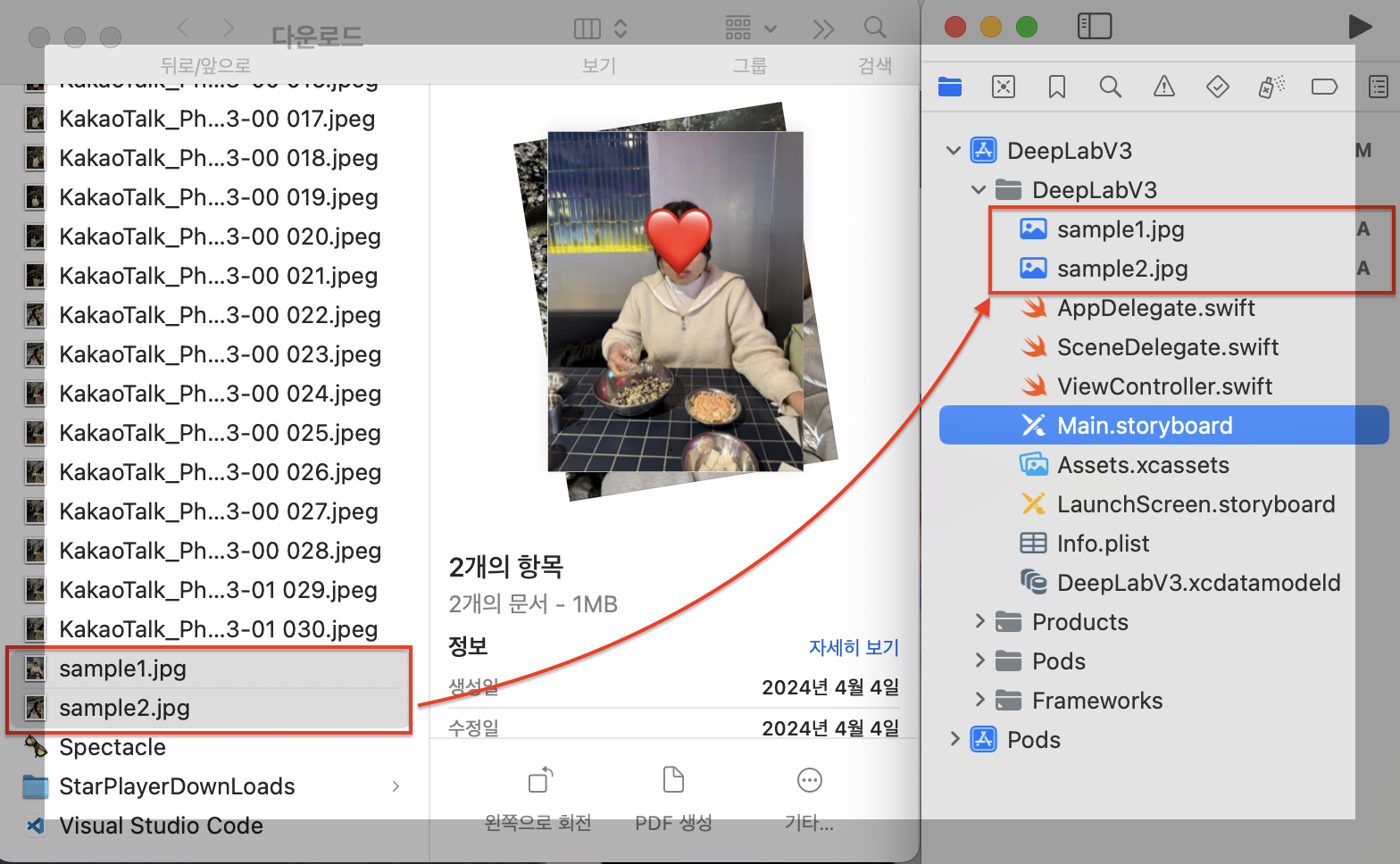
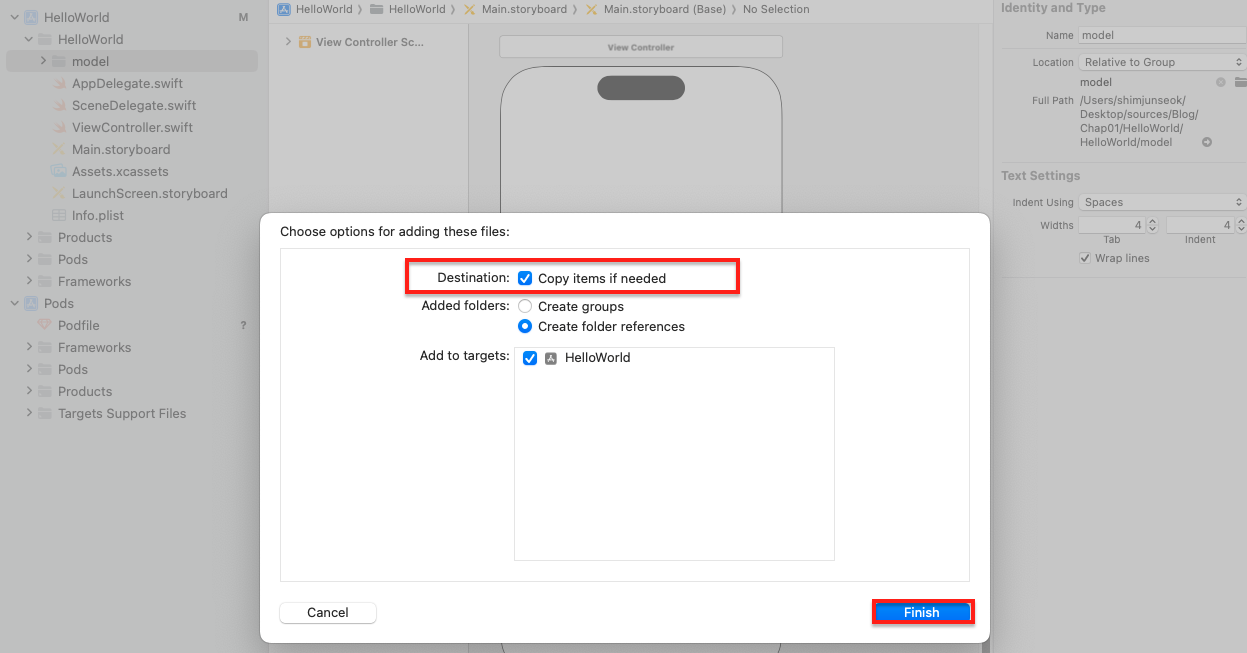
파일 추가에 대한 설정 창이 나타나는데 Destination에 Copy items if needed 항목에 체크가 되어 있는지 확인한 후 Finish 버튼을 클릭합니다.
이제 이미지가 프로젝트에 추가되었습니다.
이미지 뷰 추가하기
이제 이미지를 보여주기 위해 이미지 뷰 객체를 추가하겠습니다. Xcode 상단의 View에서 Show Library를 클릭한 후 팝업 창에서 이미지 뷰(Image View)를 찾아 스토리보드로 Drag&Drop 해주세요.
끌어온 이미지 뷰를 크기를 적절하게 조절해주세요. 오른쪽 인스펙터 영역의 Size inspector 버튼을 클릭하면 객체의 위치 및 크기를 더욱 세밀하게 수정할 수 있습니다.
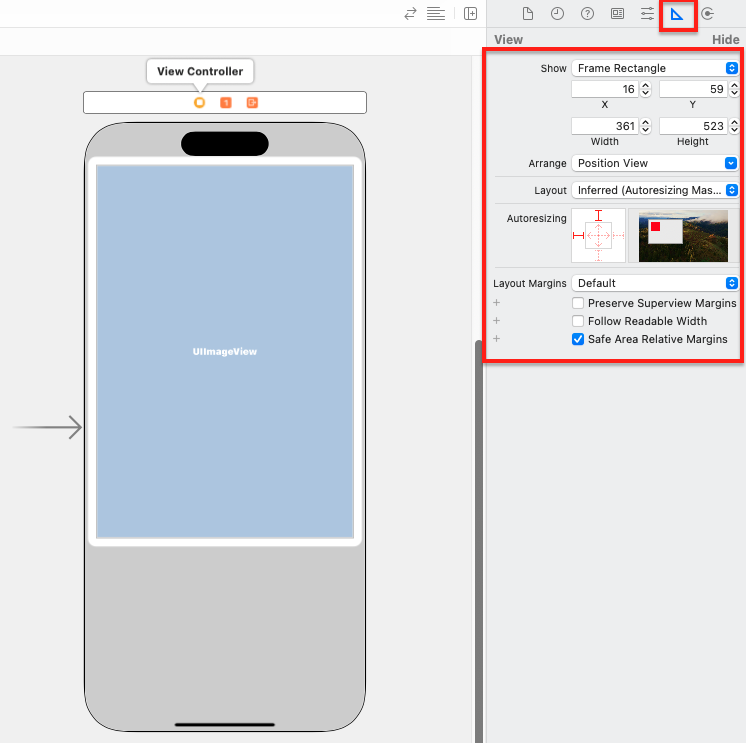
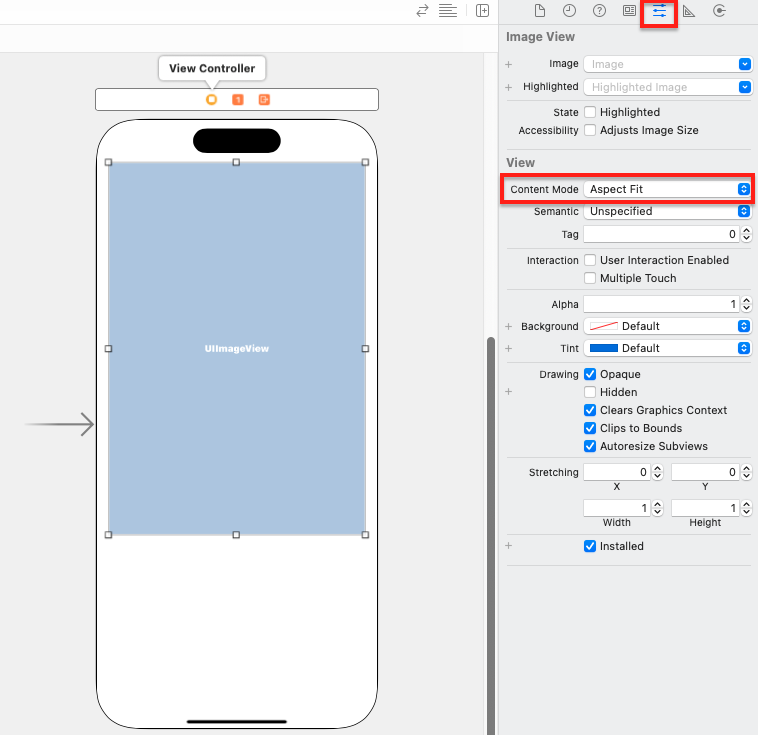
이미지 뷰의 크기에 상관없이 이미지의 가로, 세로 비율을 유지하기 위하여 뷰 모드를 수정해야 합니다. Attribites inspector 버튼을 클릭한 후 View 항목의 Content Mode를 Aspect Fit으로 변경해주세요.
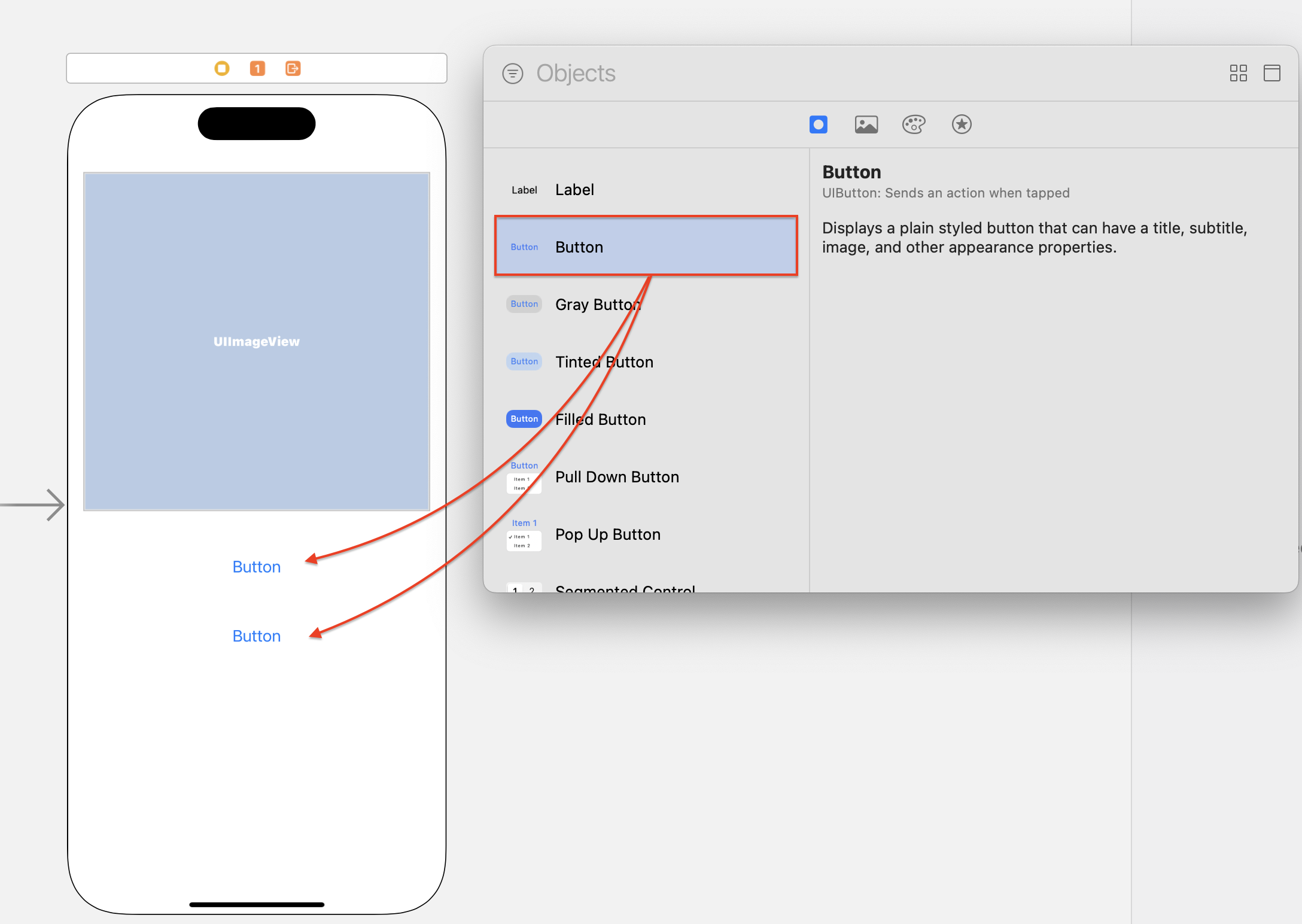
버튼 추가하기
이미지 세그멘테이션을 실행하기 위한 Button을 추가하겠습니다. 이미지 뷰와 마찬가지로 Library에서 Button를 끌어와 이미지 뷰 하단에 배치해주세요.
하나는 이미지 세그멘테이션 실행을 위한 버튼이고, 또 다른 하나는 다음 이미지로 넘어가기 위한 버튼입니다.
아웃렛 변수 추가
스토리보드에 추가한 객체를 선택하고 내용을 변경하거나 특정 동작을 수행하도록 하기 위해서는 해당 객체에 접근할 수 있는 변수인 **아웃렛 변수"가 필요합니다.
아웃렛 변수?
아웃렛 변수는 Interface Builder에서 UI 컴포넌트(예: 버튼, 텍스트 필드, 레이블 등)를 코드에 연결할 때 사용되는 변수입니다. 이를 통해 코드 내에서 해당 UI 컴포넌트의 속성을 읽거나 수정할 수 있습니다
액션 함수?
액션 함수는 사용자의 인터랙션(예: 버튼 탭, 스위치 토글 등)에 반응하여 실행되는 메서드입니다. 이를 통해 사용자의 동작에 따라 특정 코드를 실행할 수 있습니다.
앞에서 추가한 이미지 뷰와 버튼에 연결할 아웃렛 변수를 추가해보겠습니다. 화면 우측 상단의 Adjust Editor Options 버튼을 클릭한 후 Assistant 메뉴를 선택해주세요.
Assistant 메뉴를 선택하면 화면 가운데의 스토리보드 부분이 둘로 나누어지면서 왼쪽에는 스토리보드, 오른쪽에서 소스 코드를 편집하는 영역이 나타납니다.
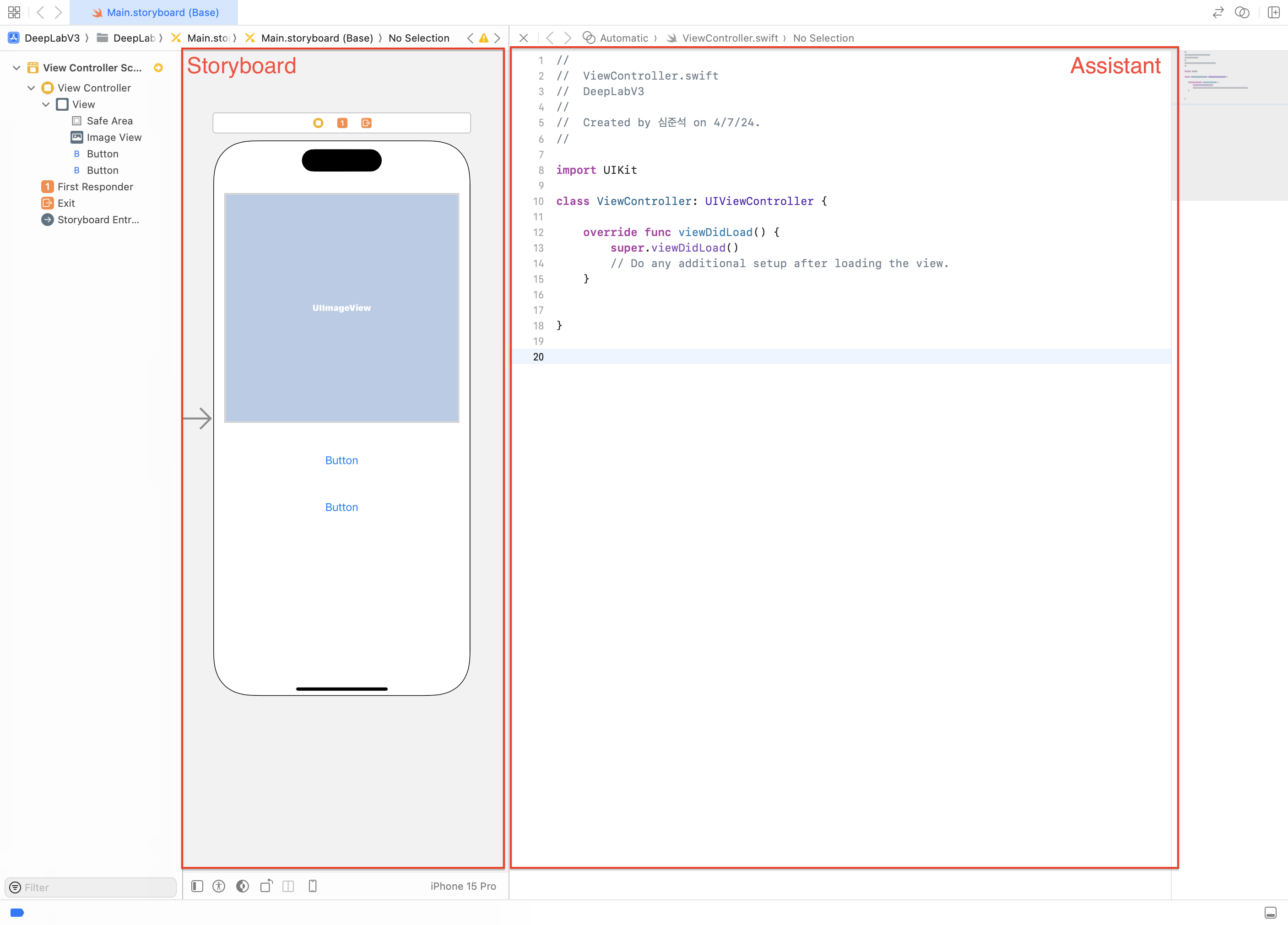
이제 아웃렛 변수를 추가해보겠습니다. 먼저 Button에 아웃렛 변수를 추가해 보겠습니다. Button을 클릭하고 control 누른 상태에서 트랙패드를 사용해 클래스 선언부 바로 아래에 추가해주세요.
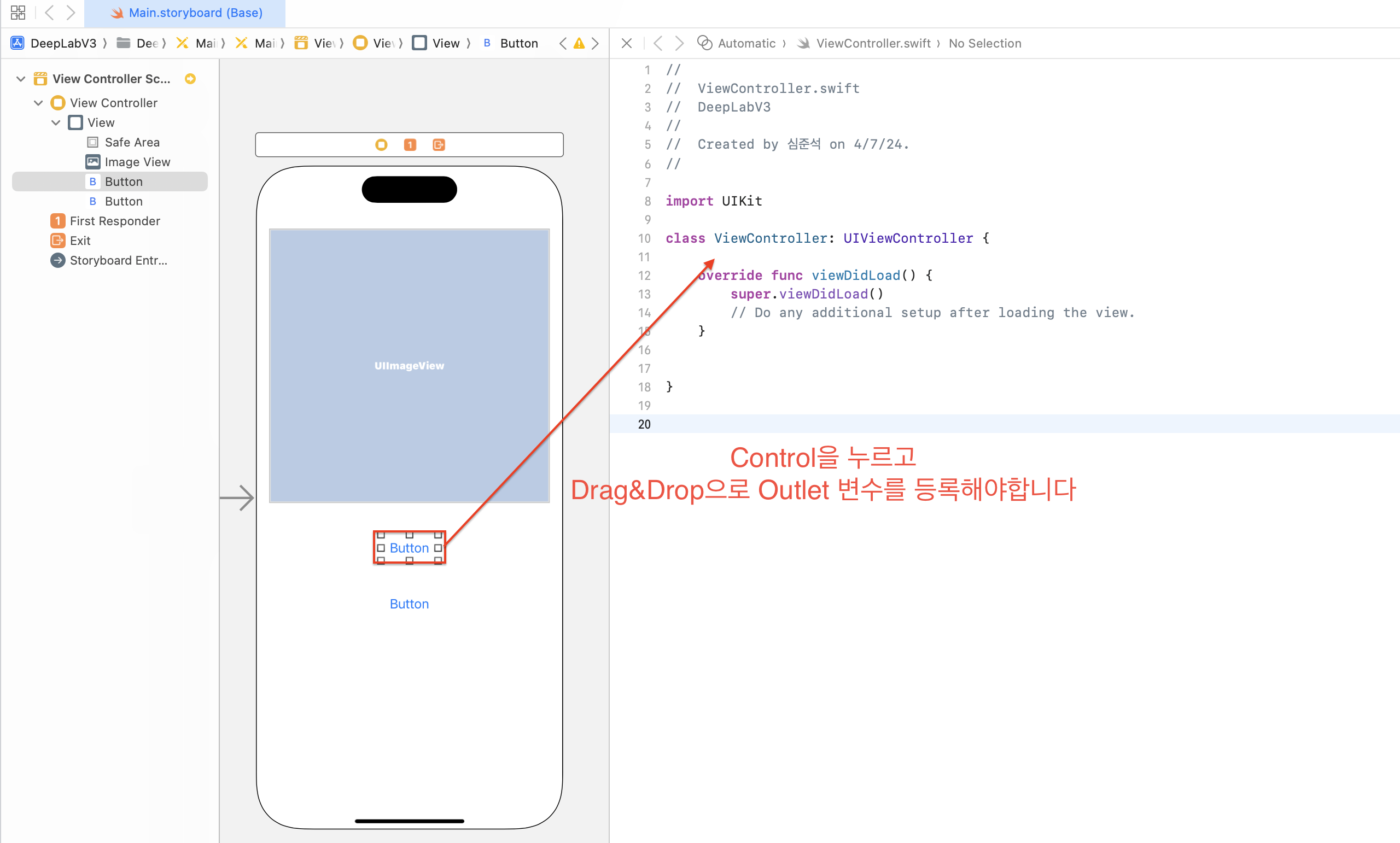
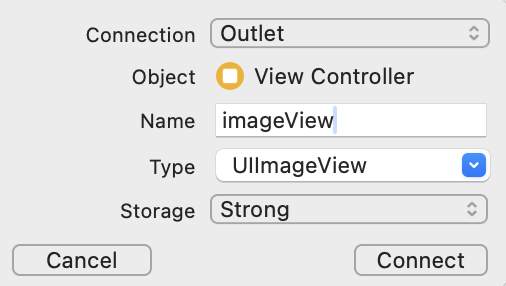
아래 연결 설정 창에서 Connection이 Outlet으로 되어 있는 것을 확인한 후 Name 입력란에 btnSegment를 입력해주세요. 그리고 Type을 UIButton로 설정하고 Storage를 Strong으로 설정한 후 connect를 클릭해주세요.
Connection : Outlet
Name : btnSegment
Type : UIButton
Storage : Strong
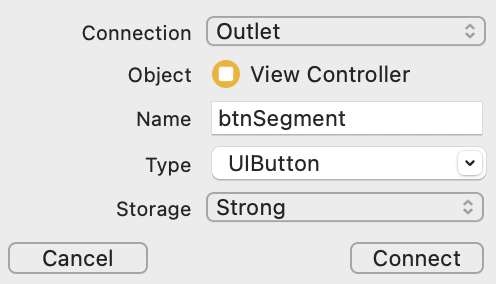
connect가 정상적으로 완료되었다면 아래와 같이
@IBOutlet var btnSegment: UIButton!가 추가된 것을 확인할 수 있습니다.
Button을 추가한것과 마찬가지로 이미지 뷰도 추가 해보겠습니다. 마찬가지로 control키를 눌러 이미지 뷰를 클래스 선언 하단부로 드래그 해주세요.
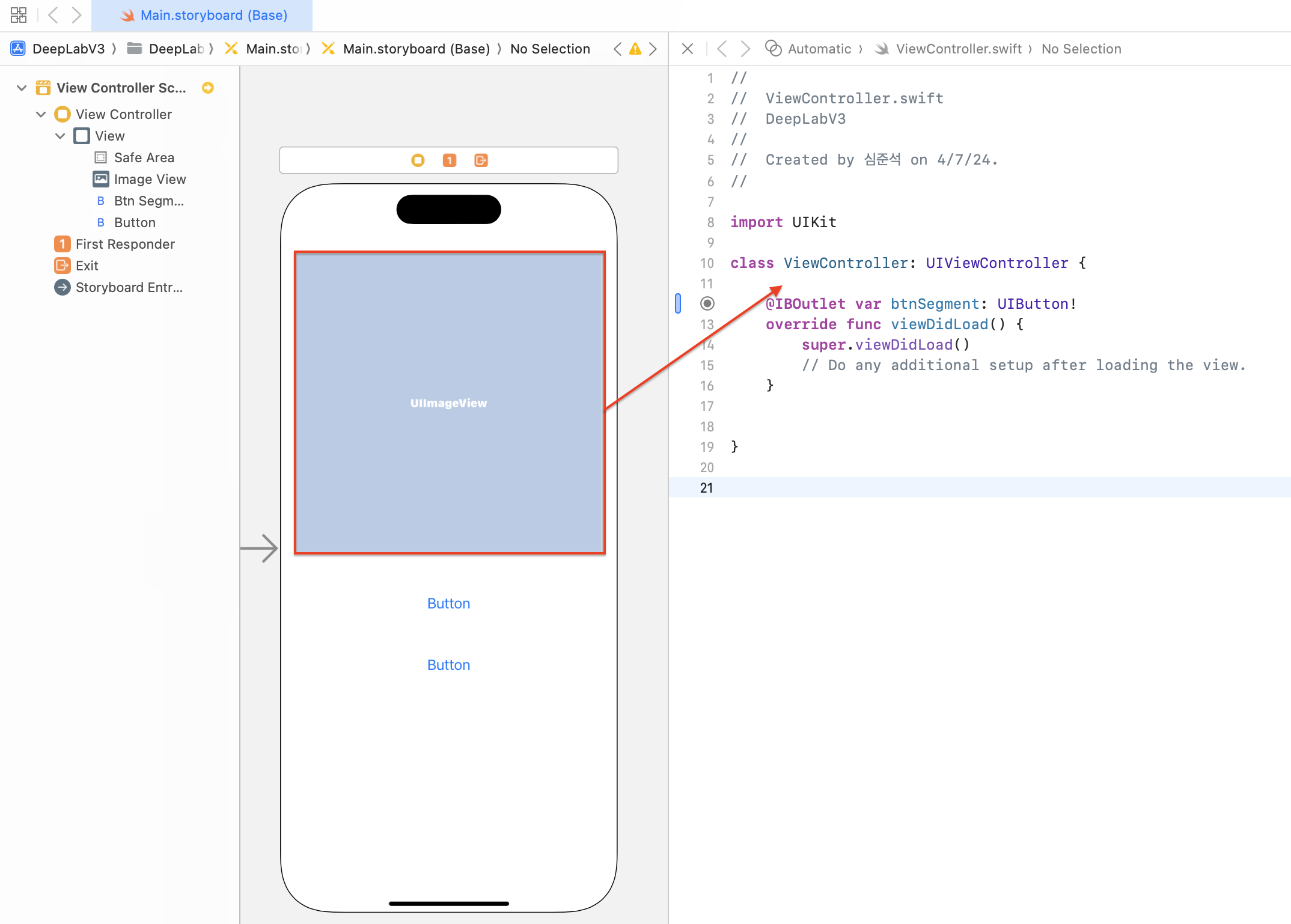
그리고 연결 상태 창에서 아래와 같이 입력하고 Connect를 클릭해주세요.
Connection : Outlet
Name : imageView
Type : UIImageView
Storage : Strong
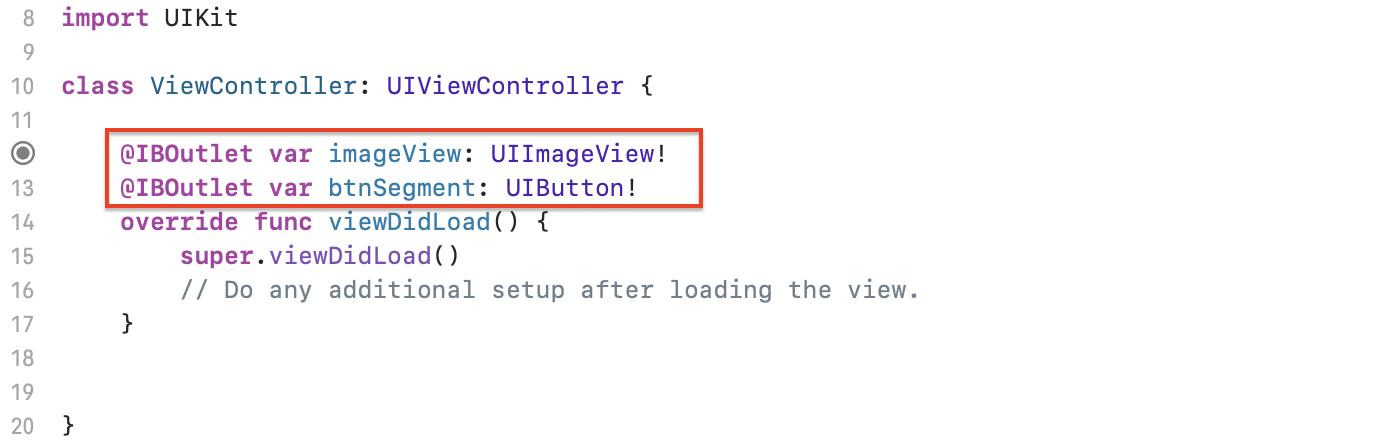
아래 그림과 같이 클래스 선언부 아래에 아웃렛 변수들이 선언되어 있다면 정상적으로 아웃렛 변수 추가가 완료되었습니다.
4-2. 이미지 로드
이미지 로딩부터 시작해보겠습니다. 왼쪽 네비게이터에서 ViewController를 먼저 클릭해 ViewController로 화면으로 이동해주세요.
image 정보를 담고있는 속성을 추가하도록 하겠습니다. 아울렛 변수를 선언한 위치 아래에 아래 코드를 추가해주세요.
private var imageName = "sample1.jpg"
private var image : UIImage?그리고 viewDidLoad() 메서드를 찾으시고, viewDidLoad() 메서드에 아래 코드를 추가해주세요.
image = UIImage(named: imageName)!
imageView.image = image중간 결과물을 한번 볼까요? 아래 캡처와 같이 연결 디바이스를 확인하고, 네비게이션 바의 우측 상단 Run 버튼을 눌러주세요.
빌드에 성공하면 아래와 같이 Build Succeeded가 화면 상에 출력됩니다.

이제 중간 결과물을 한번 볼까요?

이미지가 아주 잘 로드되네요!
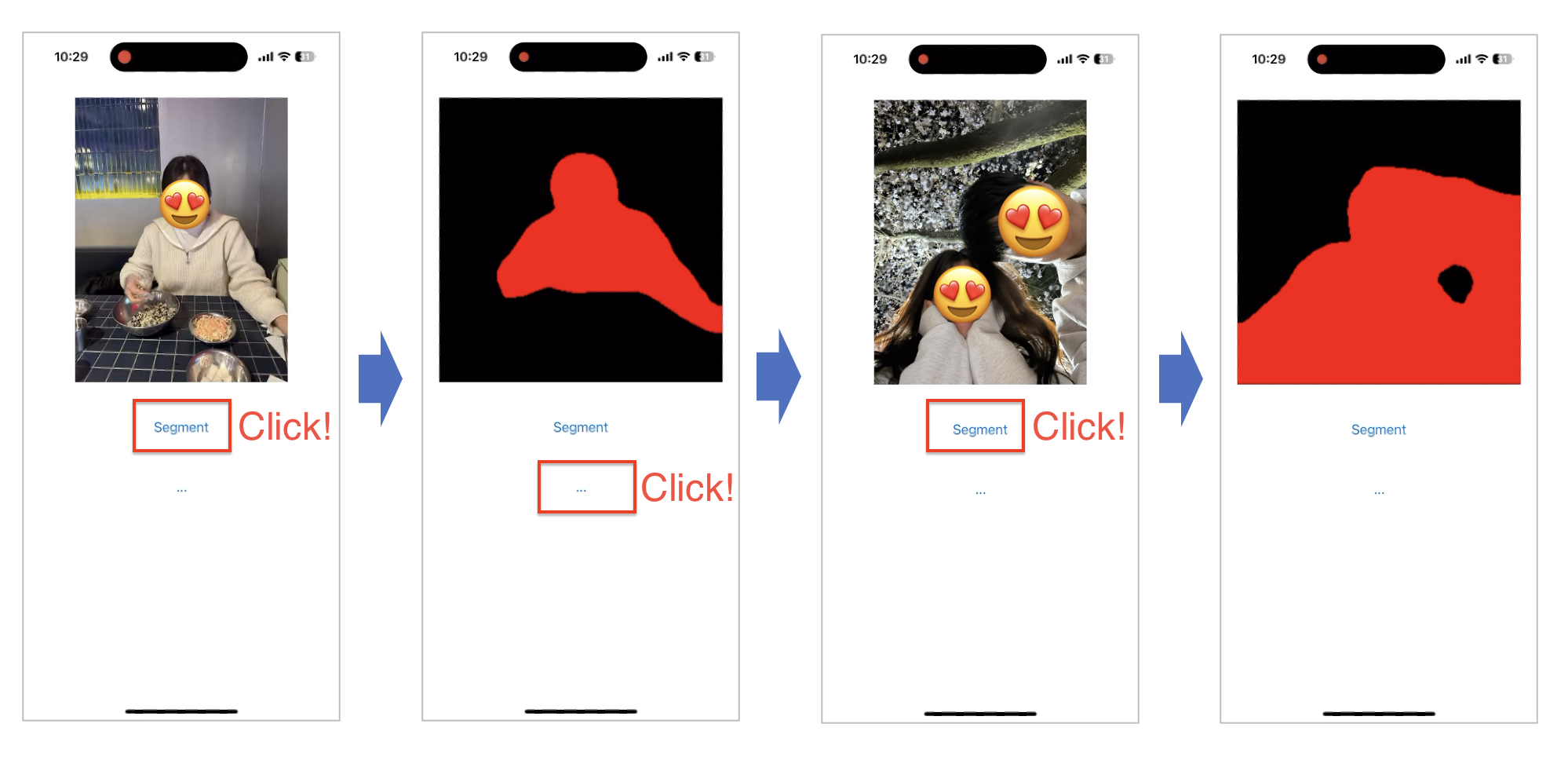
5. 이미지 세그멘테이션
이제 본격적으로 이미지 세그멘테이션 모델인 DeepLabV3 모델을 iOS에 올려보도록 하겠습니다.
먼저 이미지 세그멘테이션 실행을 위한 버튼의 이름을 수정해보겠습니다. viewDidLoad() 메서드 image 변수를 선언하는 곳 위에 다음 코드를 추가해주세요.
btnSegment.setTitle("Segment", for: .normal)Segment 버튼에 기능을 넣기위해 액션함수를 추가하도록 하겠습니다.
아웃렛 변수를 추가할 때와 마찬가지로, control키를 눌러 Button을 Drag&Drop 해주세요.
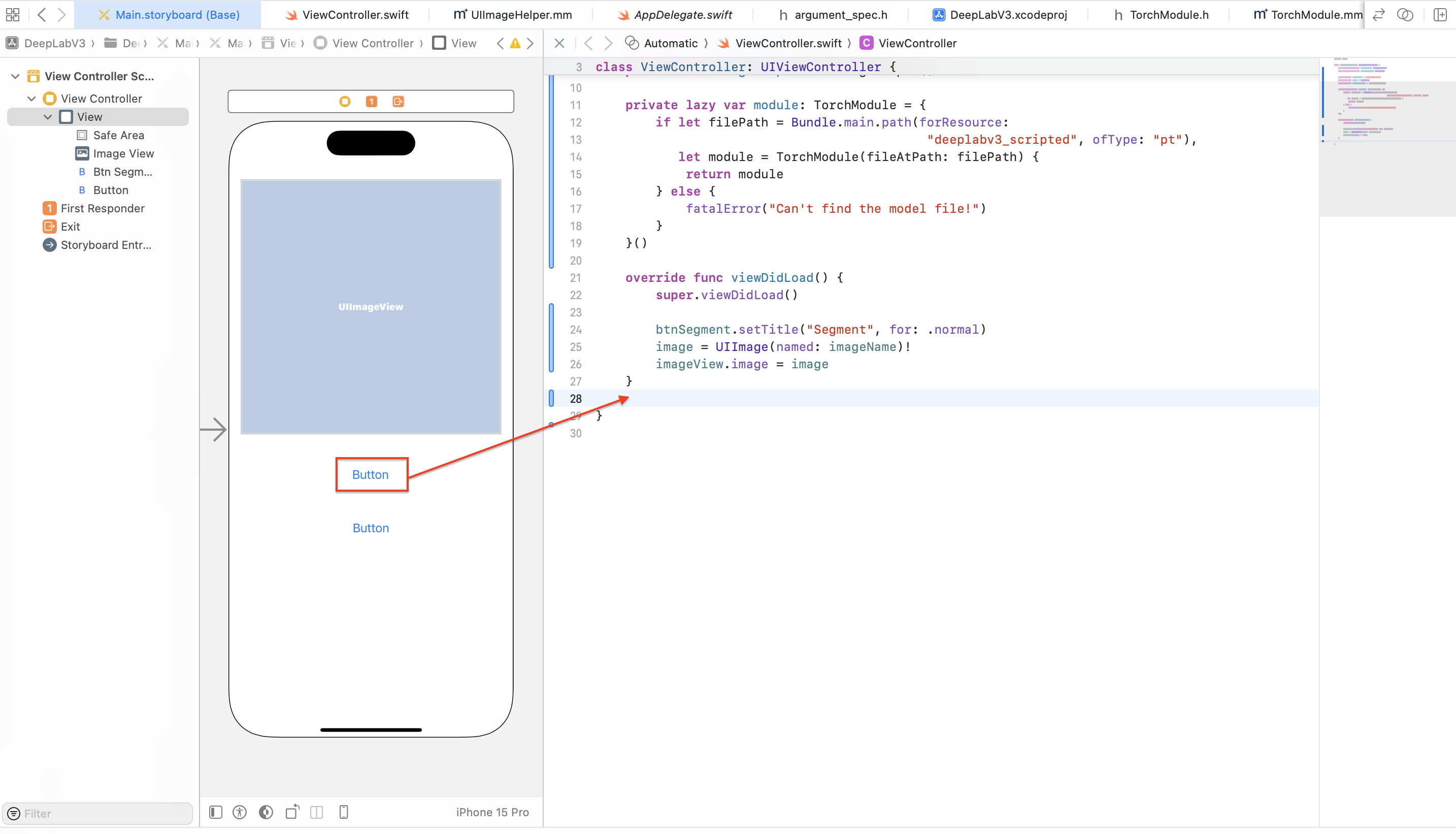
아래와 같은 팝업 화면이 나타나면, Name에는 doInfer, Type은 UIButton을 선택한 후, Connect 버튼을 클릭해 주세요.
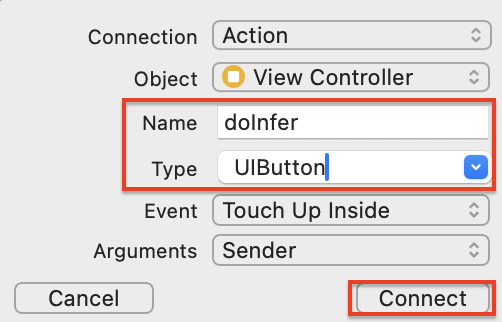
ViewController에 doInfer 메서드가 추가되었습니다!
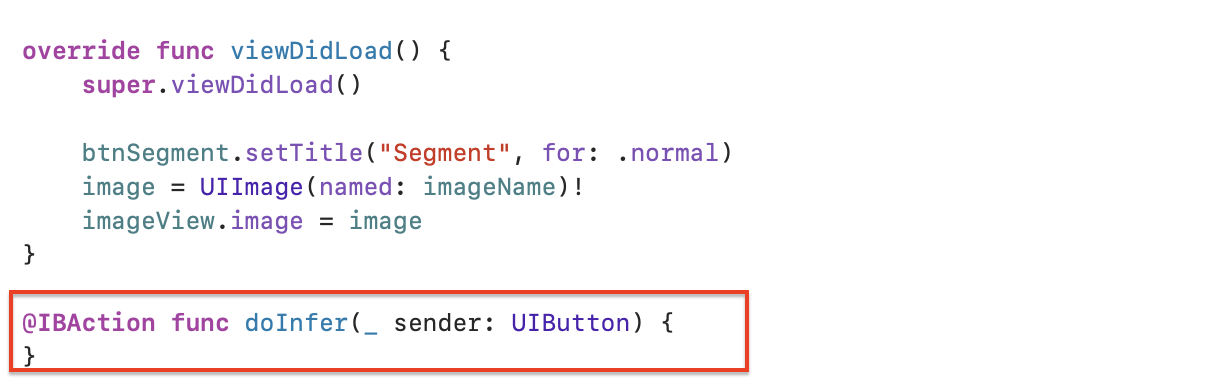
이제 doInfer 메서드를 수정해보겠습니다.
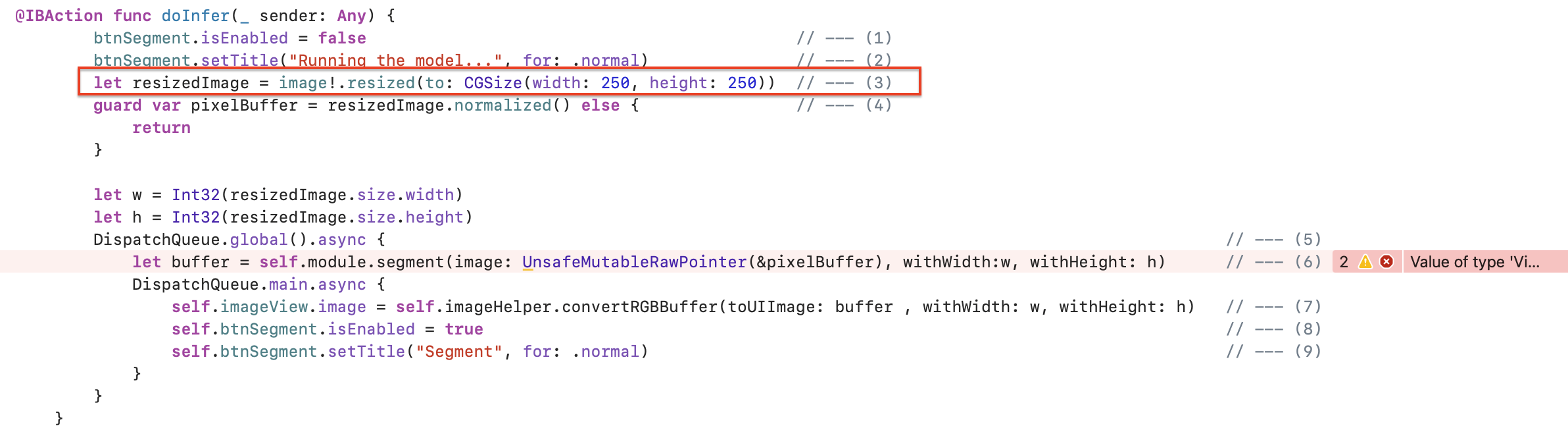
@IBAction func doInfer(_ sender: Any) {
btnSegment.isEnabled = false // --- (1)
btnSegment.setTitle("Running the model...", for: .normal) // --- (2)
let resizedImage = image!.resized(to: CGSize(width: 250, height: 250)) // --- (3)
guard var pixelBuffer = resizedImage.normalized() else { // --- (4)
return
}
let w = Int32(resizedImage.size.width)
let h = Int32(resizedImage.size.height)
DispatchQueue.global().async { // --- (5)
let buffer = self.module.segment(image: UnsafeMutableRawPointer(&pixelBuffer), withWidth:w, withHeight: h) // --- (6)
DispatchQueue.main.async {
self.imageView.image = self.imageHelper.convertRGBBuffer(toUIImage: buffer , withWidth: w, withHeight: h) // --- (7)
self.btnSegment.isEnabled = true // --- (8)
self.btnSegment.setTitle("Segment", for: .normal) // --- (9)
}
}
}아마 아래 캡처와 같이 엄청 에러가 엄청 많이 생길텐데, 걱정하지 않으셔도 됩니다!
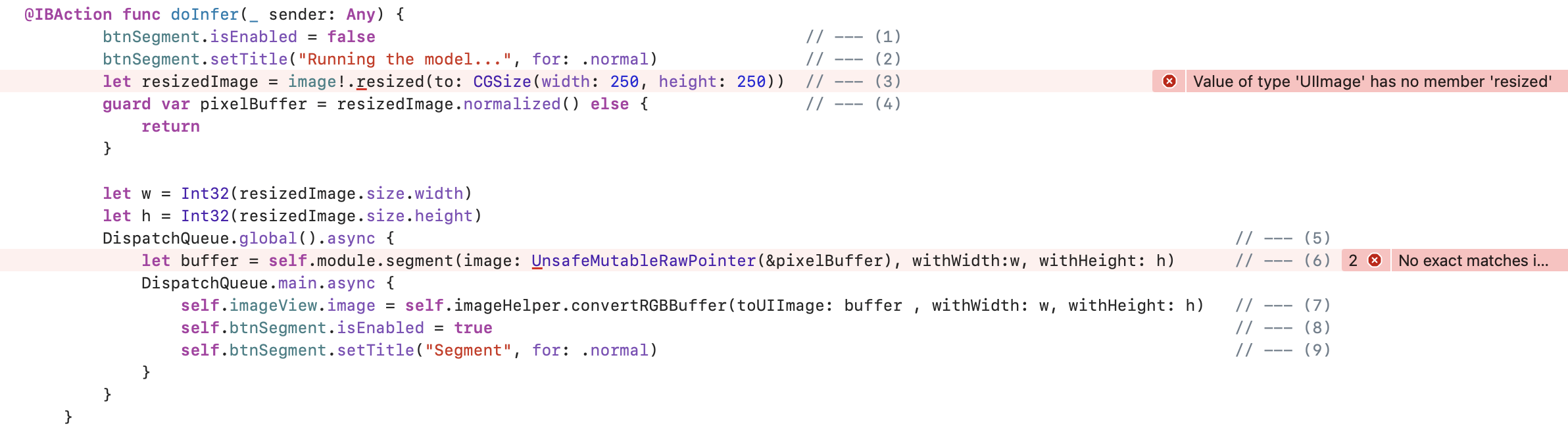
doInter() 메서드를 분석해보겠습니다. doInfer() 메서드는 다음과 같은 프로세스로 진행됩니다.

이미지 로드는 이미 했고, (3), (4) 과정에서 전처리 resize 및 normalizaion이 수행됩니다. 그 다음 비동기 방식(5)으로 UI View와 이미지 세그멘테이션(6)이 실행되게 됩니다.
자세한 과정을 살펴보도록 할까요?
5-1. 이미지 전처리
doInfer() 메서드에서 이미지 전처리를 수행하는 부분은 (3), (4)입니다.
let resizedImage = image!.resized(to: CGSize(width: 250, height: 250)) // --- (3)
guard var pixelBuffer = resizedImage.normalized() else { // --- (4)
return
}
하지만 UIImage 클래스에는 resized()와 normalized() 메서드가 따로 없습니다. 그래서 UIImage 클래스에 extension을 수행해야합니다.
extension?
Swift에서 extension은 기존의 클래스, 구조체, 열거형, 또는 프로토콜 타입에 새로운 기능을 추가할 수 있는 기능입니다. extension을 사용하면 원본 소스 코드를 수정하지 않고도 타입에 메서드, 계산 속성, 초기화 함수, 서브스크립트, 중첩 타입 등을 추가할 수 있습니다.
Xcode의 네비게이션 바에서 UIImage+Helper.swift 파일을 추가해야합니다.
네비게이션 바에서 우클릭 후 New File... 을 클릭하고, 아래와 같은 팝업이 나오면 Swift File을 선택하고 Next 버튼을 클릭해주세요.
Save As에 UIImage+Helper.swift를 입력하고 create 버튼을 클릭하시면, DeepLabV3 프로젝트에 UIImage 클래스 extension을 위한 UIImge+Helper.swift 파일이 추가됩니다.
UIImage+Heler.swift 파일에 아래 코드를 입력하고, 저장해주세요.
import UIKit
extension UIImage { // --- (1)
func resized(to newSize: CGSize, scale: CGFloat = 1) -> UIImage { // --- (2)
let format = UIGraphicsImageRendererFormat.default() // --- (3)
format.scale = scale // --- (4)
let renderer = UIGraphicsImageRenderer(size: newSize, format: format) // --- (5)
let image = renderer.image { _ in // --- (6)
draw(in: CGRect(origin: .zero, size: newSize)) // --- (7)
}
return image // --- (8)
}
func normalized() -> [Float32]? { // --- (9)
guard let cgImage = self.cgImage else { // --- (10)
return nil // --- (11)
}
let w = cgImage.width // --- (12)
let h = cgImage.height // --- (13)
let bytesPerPixel = 4 // --- (14)
let bytesPerRow = bytesPerPixel * w // --- (15)
let bitsPerComponent = 8 // --- (16)
var rawBytes: [UInt8] = [UInt8](repeating: 0, count: w * h * 4) // --- (17)
rawBytes.withUnsafeMutableBytes { ptr in // --- (18)
if let cgImage = self.cgImage, // --- (19)
let context = CGContext(data: ptr.baseAddress, // --- (20)
width: w, // --- (21)
height: h, // --- (22)
bitsPerComponent: bitsPerComponent, // --- (23)
bytesPerRow: bytesPerRow, // --- (24)
space: CGColorSpaceCreateDeviceRGB(), // --- (25)
bitmapInfo: CGImageAlphaInfo.premultipliedLast.rawValue) { // --- (26)
let rect = CGRect(x: 0, y: 0, width: w, height: h) // --- (27)
context.draw(cgImage, in: rect) // --- (28)
}
}
var normalizedBuffer: [Float32] = [Float32](repeating: 0, count: w * h * 3) // --- (29)
for i in 0 ..< w * h { // --- (30)
normalizedBuffer[i] = (Float32(rawBytes[i * 4 + 0]) / 255.0 - 0.485) / 0.229 // R // --- (31)
normalizedBuffer[w * h + i] = (Float32(rawBytes[i * 4 + 1]) / 255.0 - 0.456) / 0.224 // G // --- (32)
normalizedBuffer[w * h * 2 + i] = (Float32(rawBytes[i * 4 + 2]) / 255.0 - 0.406) / 0.225 // B // --- (33)
}
return normalizedBuffer // --- (34)
}
}
코드를 디테일하게 보도록 하겠습니다.
(1)
UIImage클래스에 대한 확장을 시작합니다. 이를 통해UIImage인스턴스에 추가 메서드를 제공할 수 있습니다.
(2)resized(to:newSize:scale:)메서드를 정의합니다. 이 메서드는 새 크기(newSize)와 선택적 스케일(scale, 기본값은 1)을 받아 이미지의 크기를 조정합니다.
(3) 기본UIGraphicsImageRendererFormat인스턴스를 생성합니다. 이 포맷은 이미지 렌더링에 사용될 설정을 정의합니다.
(4) 렌더링 포맷의 스케일을 설정합니다. 이는 이미지의 픽셀 밀도를 조정합니다.
(5) 지정된 크기(newSize)와 포맷(format)으로UIGraphicsImageRenderer인스턴스를 생성합니다. 이 렌더러는 이미지 조정 작업을 수행합니다.
(6) 렌더러를 사용하여 새 이미지를 생성합니다. 이 과정은 클로저 내부에서 수행되며, 클로저는 렌더링 컨텍스트를 제공합니다.
(7) 현재 이미지(self)를 새 크기의 사각형(CGRect) 안에 그립니다. 이 작업은 이미지의 크기를 조정합니다.
(8) 조정된 이미지를 반환합니다.
(9)normalized()메서드를 정의합니다. 이 메서드는 이미지를 정규화된 플로트 배열로 변환합니다.
(10)UIImage의CGImage를 안전하게 얻습니다. 이것이 실패하면nil을 반환합니다.
(11)CGImage가 없으면nil을 반환하여 메서드 실행을 종료합니다.
(12,13)CGImage의 너비와 높이를 가져옵니다.
(14) 각 픽셀당 바이트 수를 정의합니다. RGBA 각 채널은 1바이트씩 사용합니다.
(15) 한 줄당 바이트 수를 계산합니다.
(16) 각 컴포넌트(색상 채널)의 비트 수를 정의합니다.
(17) 원본 이미지 데이터를 저장할 바이트 배열을 초기화합니다.
(18)rawBytes배열에 안전하게 접근하여 메모리를 할당합니다.
(19)self.cgImage를 다시 확인하는 것은 중복 체크합니다.
(26)CGContext를 생성하여 이미지 데이터를 그리는데 사용합니다. 이 컨텍스트는 정의된 너비, 높이, 비트 당 컴포넌트 수, 바이트 수, 색상 공간 및 알파 정보를 바탕으로 설정됩니다.
(27) 이미지 데이터를 그릴 사각형을 정의합니다.
(28)CGContext를 사용하여cgImage에서rawBytes로 픽셀 데이터를 그립니다.
(29) 정규화된 픽셀 값을 저장할 플로트 배열을 초기화합니다.
(33) 모든 픽셀을 순회하면서 RGB 값을 정규화합니다. 정규화 공식은 (픽셀값 / 255.0 - 평균) / 표준편차입니다. 이는 PyTorch에서 권장하는 이미지 전처리 방식에 따릅니다.
(34) 정규화된 픽셀 데이터 배열을 반환합니다.
다시 ViewController.swift로 돌아가볼까요? (3)에서 발생하던 에러가 사라진 것이 보입니다!
extension이 잘 적용된것 같네요!
왜 전처리 과정이 필요할까?
이미지 전처리는 컴퓨터 비전, 기계 학습, 딥 러닝 프로젝트에서 중요한 단계입니다. 다음과 같은 여러 이유로 이미지 전처리를 수행합니다:
- 데이터 품질 향상: 이미지에서 노이즈를 제거하거나 대비를 조정하는 등의 전처리 과정은 데이터의 품질을 향상시킵니다. 이는 모델이 이미지의 주요 특징을 더 잘 인식하고 학습하는 데 도움이 됩니다.
- 피쳐 강조: 전처리 과정을 통해 관심 있는 특징을 강조하거나 불필요한 정보를 제거함으로써, 모델이 중요한 특성에 더 집중할 수 있게 합니다.
- 표준화 및 정규화: 다양한 소스에서 수집한 이미지는 크기, 해상도, 색상 깊이 등에서 차이가 날 수 있습니다. 이러한 이미지를 모델에 입력하기 전에 일정한 크기나 스케일로 표준화하고 정규화하여, 모델이 동일한 기준으로 이미지를 처리하도록 합니다.
- 성능 향상: 적절한 전처리를 통해 모델의 학습 속도를 높이고, 추론 시간을 단축시킬 수 있습니다. 또한, 전처리 과정을 통해 모델의 성능(예: 정확도, 정밀도)을 향상시킬 수 있습니다.
- 데이터 증강: 이미지 회전, 반전, 스케일 조정과 같은 전처리 기법을 사용하여 데이터 셋의 다양성을 증가시키고, 모델의 일반화 능력을 향상시킬 수 있습니다.
- 컴퓨팅 자원 최적화: 이미지 크기를 줄이거나 불필요한 부분을 제거함으로써, 필요한 컴퓨팅 자원의 양을 줄일 수 있습니다. 이는 특히 모바일 기기나 리소스가 제한적인 환경에서 중요합니다.
전체적으로, 이미지 전처리는 데이터의 일관성을 보장하고, 모델의 학습과 성능을 최적화하는 데 필수적인 과정입니다.
5-2. 이미지 후처리 준비
이미지 세그멘테이션에 들어가기전, 이미지 후처리에 사용될 모듈인 UIImageHelper를 만들어주도록 하겠습니다.
UIImageHelper는 Objective-C++ 기반의 모듈로, 먼저 헤더 파일을 생성해주도록 하겠습니다.
New File 팝업에서 Header File을 선택한 후 Next를 클릭해주세요.
Save As에 UIImageHelper를 입력해주고, Create버튼을 눌러주세요.
UIImageHelper.h 에서 선언되는 클래스와 메서드입니다. UIImageHelper는
#import <Foundation/Foundation.h>
#import <UIKit/UIKit.h>
@interface UIImageHelper : NSObject
- (UIImage *) convertRGBBufferToUIImage:(unsigned char *) buffer withWidth:(int)width withHeight:(int)height;
@end이제 Objective-C 기반의 UIImageHelper.mm 파일을 만들어주겠습니다. 마찬가지로 DeebLabV3에서 New File을 클릭해 파일을 생성하는 팝업으로 이동해주세요.
이번에는 Objective-C File을 클릭한 후, Next 버튼을 클릭해 주세요
아래와 같은 팝업으로 이동하면, 저장할 프로젝트(폴더)를 선택한 후 Create 버튼을 클릭해 주세요.
그 다음 아래와 같은 팝업이 나타나면, Create Bridging Header 버튼을 클릭하시면 됩니다.
그럼 아래 캡처화면과 같이 DeepLabV3-Bridging-Header.h 파일이 생성됩니다.

네비게이션 바에서 생성된 Objective-C 파일을 볼까요? 확장자가 .m입니다. Swift는 Objective-C++을 브릿지로 사용하기 때문에, UIImageHelper.m의 확장자를 .mm으로 확장해줘야합니다.(.m 파일의 경우 컴파일러가 표준 C++ 헤더 파일을 추가시키지 않기 때문)
(1)UIImageHelper.m 에서 우클릭 후, (2)Save file inspector를 클릭해주세요. 그리고 (3) Name에서 확장자를 m에서 mm으로 변경해주시면 됩니다.
UIImageHelper.mm 파일에 아래 내용을 추가해주세요. 이미지 후처리에 대한 내용은 다른 포스팅에서 소개하도록 하겠습니다. 다른 포스팅을 참고해주세요.
#import <UIKit/UIKit.h>
@implementation UIImageHelper : NSObject
- (UIImage*)convertRGBBufferToUIImage:(unsigned char*)buffer
withWidth:(int)width
withHeight:(int)height {
char* rgba = (char*)malloc(width * height * 4);
for (int i = 0; i < width * height; ++i) {
rgba[4 * i] = buffer[3 * i];
rgba[4 * i + 1] = buffer[3 * i + 1];
rgba[4 * i + 2] = buffer[3 * i + 2];
rgba[4 * i + 3] = 255;
}
size_t bufferLength = width * height * 4;
CGDataProviderRef provider = CGDataProviderCreateWithData(NULL, rgba, bufferLength, NULL);
size_t bitsPerComponent = 8;
size_t bitsPerPixel = 32;
size_t bytesPerRow = 4 * width;
CGColorSpaceRef colorSpaceRef = CGColorSpaceCreateDeviceRGB();
if (colorSpaceRef == NULL) {
NSLog(@"Error allocating color space");
CGDataProviderRelease(provider);
return nil;
}
CGBitmapInfo bitmapInfo = kCGBitmapByteOrderDefault | kCGImageAlphaPremultipliedLast;
CGColorRenderingIntent renderingIntent = kCGRenderingIntentDefault;
CGImageRef iref = CGImageCreate(width,
height,
bitsPerComponent,
bitsPerPixel,
bytesPerRow,
colorSpaceRef,
bitmapInfo,
provider,
NULL,
YES,
renderingIntent);
uint32_t* pixels = (uint32_t*)malloc(bufferLength);
if (pixels == NULL) {
NSLog(@"Error: Memory not allocated for bitmap");
CGDataProviderRelease(provider);
CGColorSpaceRelease(colorSpaceRef);
CGImageRelease(iref);
return nil;
}
CGContextRef context = CGBitmapContextCreate(pixels,
width,
height,
bitsPerComponent,
bytesPerRow,
colorSpaceRef,
bitmapInfo);
if (context == NULL) {
NSLog(@"Error context not created");
free(pixels);
}
UIImage* image = nil;
if (context) {
CGContextDrawImage(context, CGRectMake(0.0f, 0.0f, width, height), iref);
CGImageRef imageRef = CGBitmapContextCreateImage(context);
if ([UIImage respondsToSelector:@selector(imageWithCGImage:scale:orientation:)]) {
float scale = [[UIScreen mainScreen] scale];
image = [UIImage imageWithCGImage:imageRef scale:scale orientation:UIImageOrientationUp];
} else {
image = [UIImage imageWithCGImage:imageRef];
}
CGImageRelease(imageRef);
CGContextRelease(context);
}
CGColorSpaceRelease(colorSpaceRef);
CGImageRelease(iref);
CGDataProviderRelease(provider);
if (pixels) {
free(pixels);
}
return image;
}
@endUIImageHelper 모듈을 ViewController()에 추가하도록 하겠습니다.
@IBOutlet var btnSegment: UIButton!아래에 다음 코드를 추가해주세요.
private let imageHelper = UIImageHelper()5-3. 이미지 세그멘테이션 추론
이제 미리 만들어뒀던 deeplabv3_scripted.pt 파일을 통해 전처리된 이미지를 세그멘테이션 결과를 얻어보도록 하겠습니다.
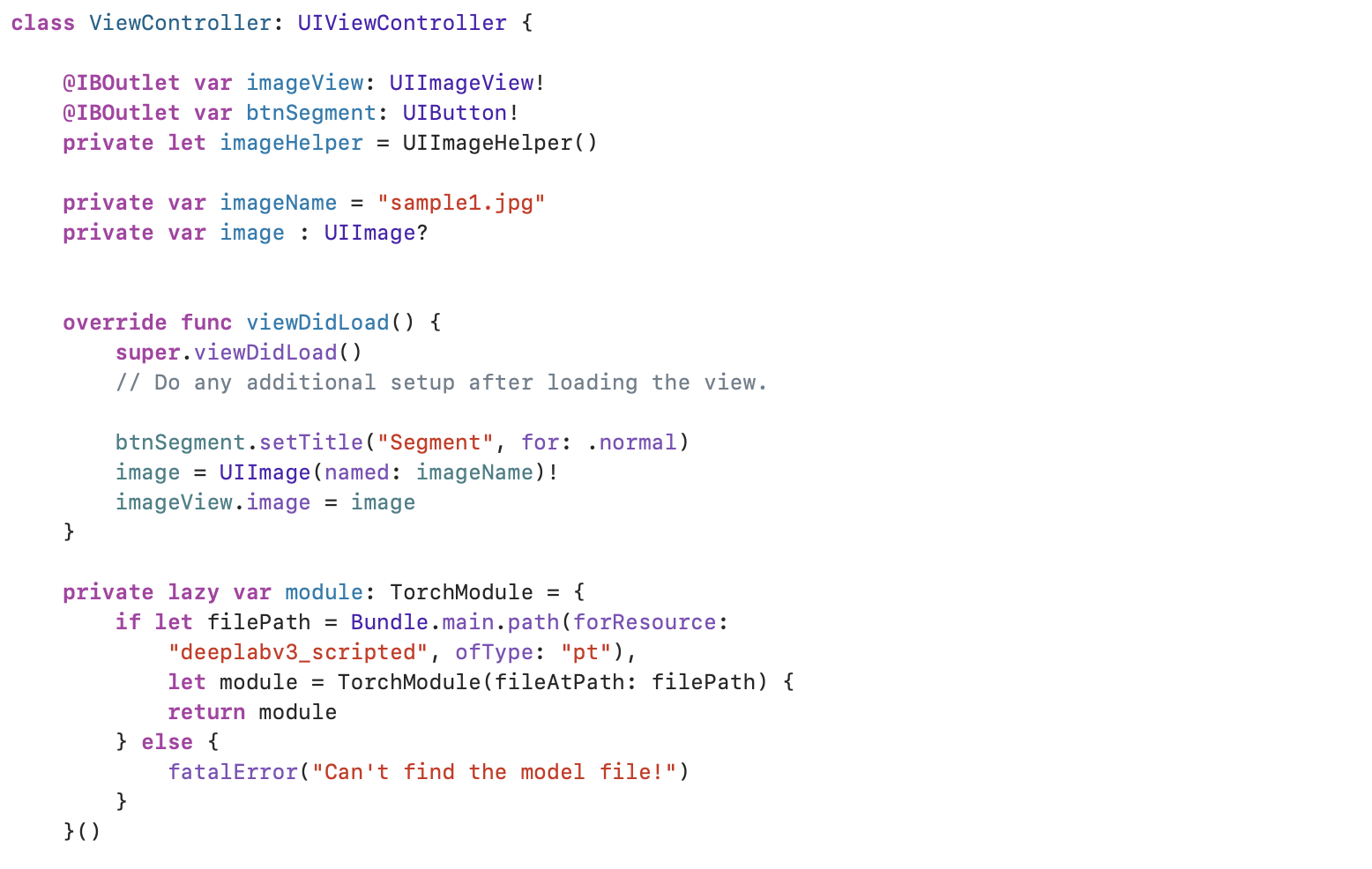
잠시 doInfer() 메서드에서 나와 module 변수를 먼저 선언해주도록 하겠습니다. 아래는 module 변수를 선언하는 부분입니다. 위치는 크게 상관없지만 viewDidLoad() 메서드 아래에 module 변수를 선언해 주세요.
private lazy var module: TorchModule = {
if let filePath = Bundle.main.path(forResource:
"deeplabv3_scripted", ofType: "pt"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
}()아마도 Cannot find type 'TorchModule' in scope 라는 에러가 발생할 것입니다. 해당 에러를 해결하기 위해선, 모델 deeplabv3_scripted.pt와 Swift를 이어주는 브릿지 TorchModule을 만들어야 합니다.
Objective-C 기반의 브리지인 TorchModule을 만들어볼까요? UIImageHelper를 만들 때와 동일하게, DeepLabV3 프로젝트에서 우클릭하여 New File을 클릭해 파일 생성 팝업으로 이동해주세요.
New File 팝업에서 Header File을 선택한 후 Next를 클릭해주세요.
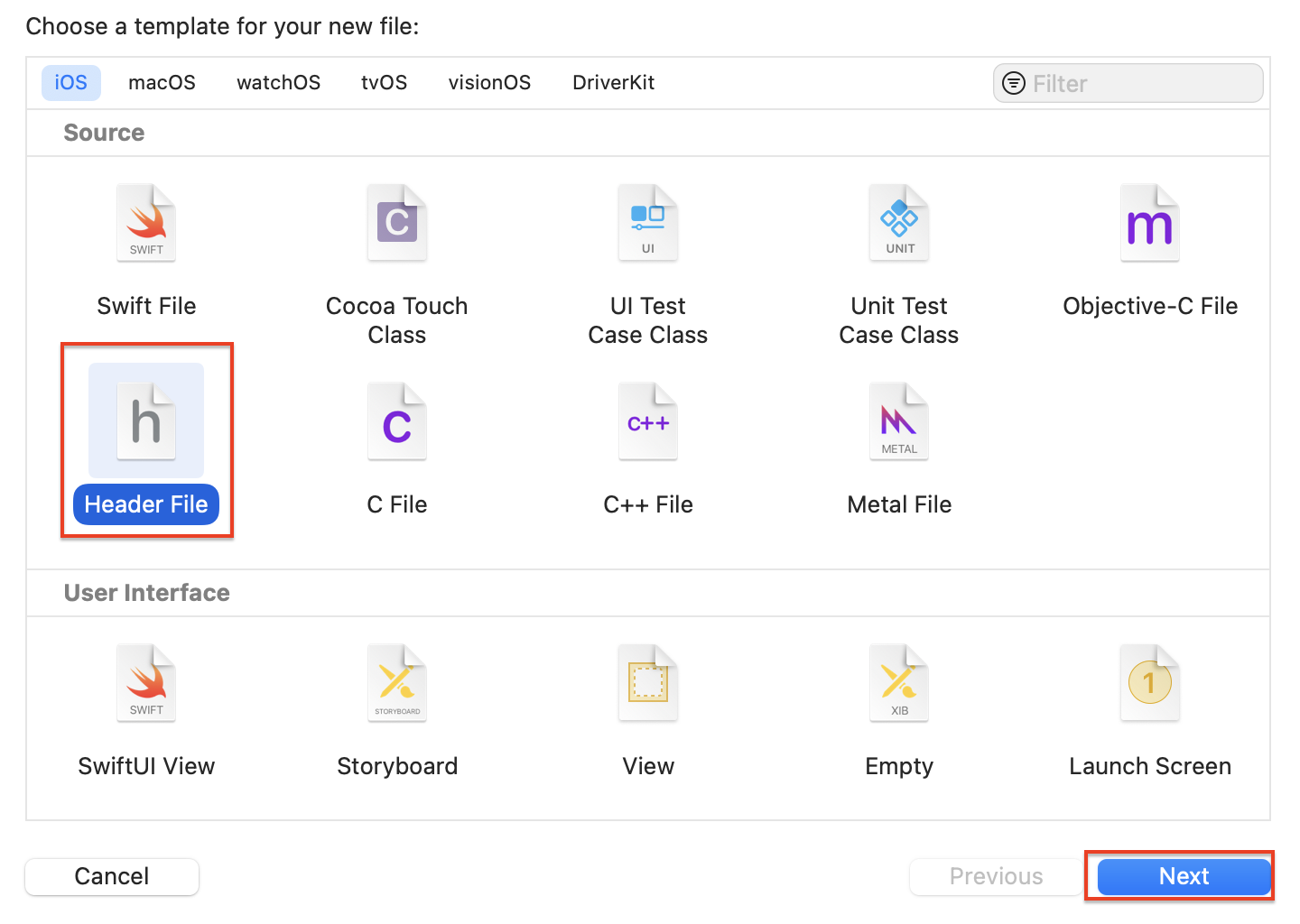
Save As에 TorchModule.h를 입력해주고, Create버튼을 눌러주세요.
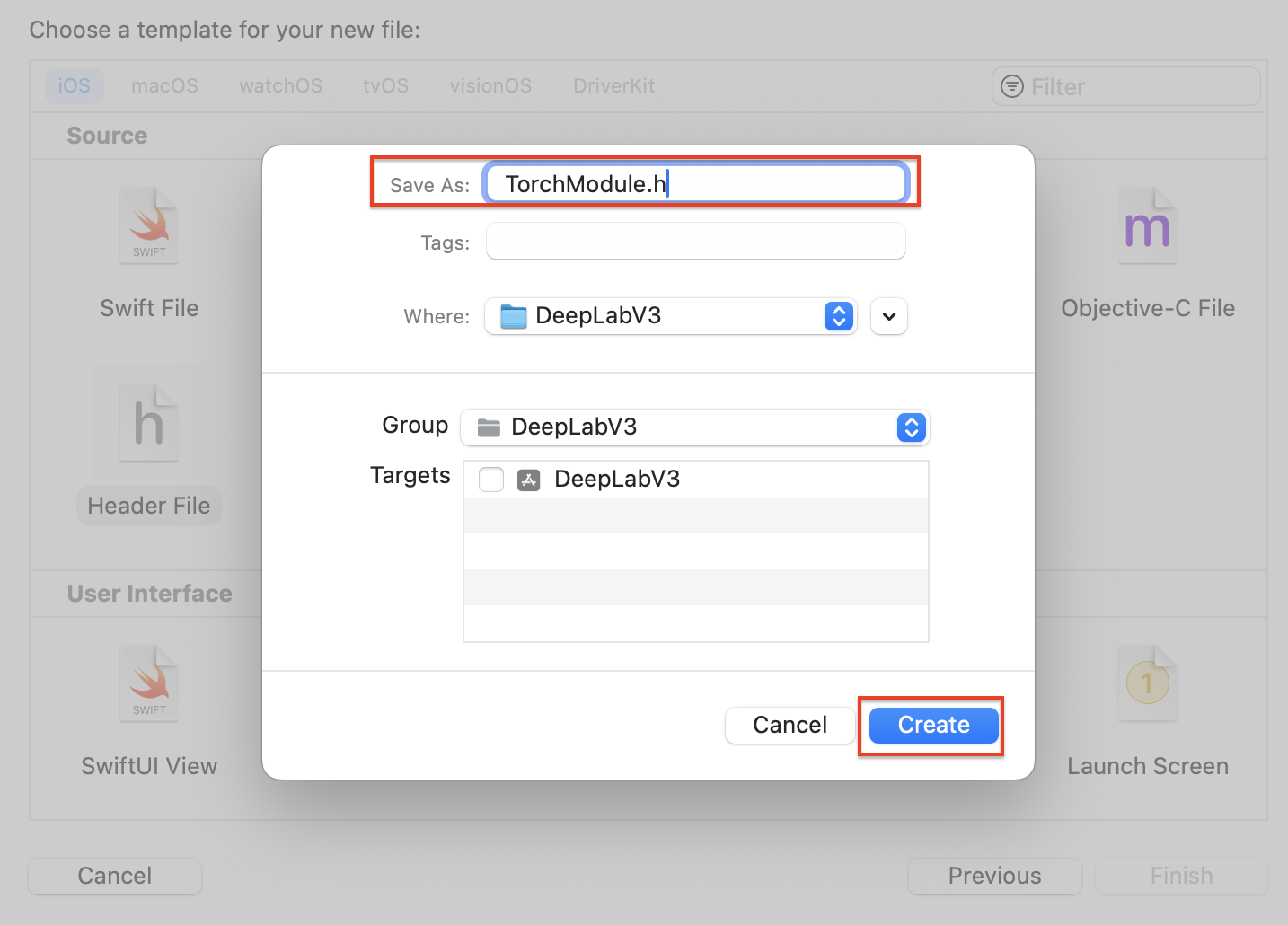
그럼 아래와 같이 TorchModule.h 파일이 생성된 것을 확인할 수 있습니다.
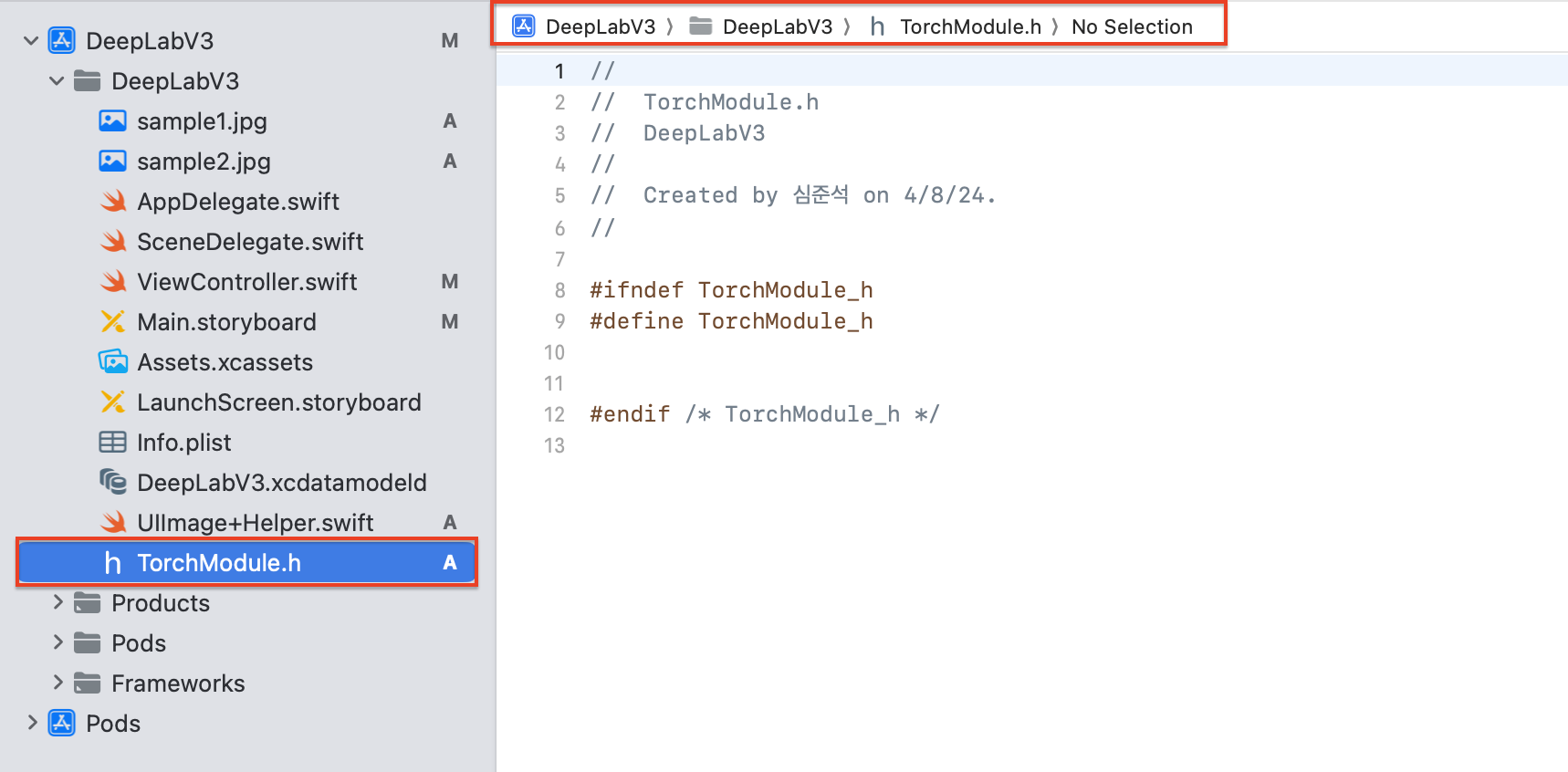
이제 TorchModule.h에서 사용할 클래스 및 메서드, 속성들을 선언해주도록 하겠습니다.
#import <Foundation/Foundation.h>
#import <UIKit/UIKit.h>
NS_ASSUME_NONNULL_BEGIN
@interface TorchModule : NSObject
- (nullable instancetype)initWithFileAtPath:(NSString*)filePath
NS_SWIFT_NAME(init(fileAtPath:))NS_DESIGNATED_INITIALIZER;
+ (instancetype)new NS_UNAVAILABLE;
- (instancetype)init NS_UNAVAILABLE;
- (unsigned char*)segmentImage:(void*)imageBuffer withWidth:(int)width withHeight:(int)height NS_SWIFT_NAME(segment(image:withWidth:withHeight:));
@end
NS_ASSUME_NONNULL_END
각 메서드 별로 자세히 알아보도록 하겠습니다.
-
initWithFileAtPath : 모델 파일의 경로를 입력받아
TorchModule인스턴스를 생성합니다.NS_SWIFT_NAME매크로를 사용해 Swift에서 이 메서드를 호출할 때 사용할 이름을init(fileAtPath:)로 지정합니다.NS_DESIGNATED_INITIALIZER매크로는 이 메서드가 클래스의 지정 초기화 메서드임을 나타냅니다. 이는 서브클래스에서 상속 및 재정의할 때 초기화 프로세스의 일관성을 유지하는 데 중요합니다. -
생성자 제한 :
+new와-init메서드는NS_UNAVAILABLE매크로를 사용하여, 이 클래스의 인스턴스가 기본 생성자로 생성되는 것을 방지합니다. 이는 사용자가 반드시initWithFileAtPath:를 통해 인스턴스를 초기화하도록 강제화 합니다. -
segmentImage:withWidth:withHeight: : 이미지 데이터를 포함하는 버퍼와 이미지늬 너비 및 높이를 입력으로 받습니다. 세그멘테이션 작업을 수행한 후, 세그멘테이션 결과를 나타내는 새로운 이미지 버퍼를 반환합니다.
NS_SWIFT_NAME매크로를 통해 Swift에서segment(image::withWidth:withHeight:)로 호출할 수 있도록 이름을 지정합니다.
이제 Objective-C 기반의 TorchModule.mm 파일을 만들어주겠습니다. 마찬가지로 DeebLabV3에서 New File을 클릭해 파일을 생성하는 팝업으로 이동해주세요.
Objective-C File을 클릭한 후, Next 버튼을 클릭해주세요.
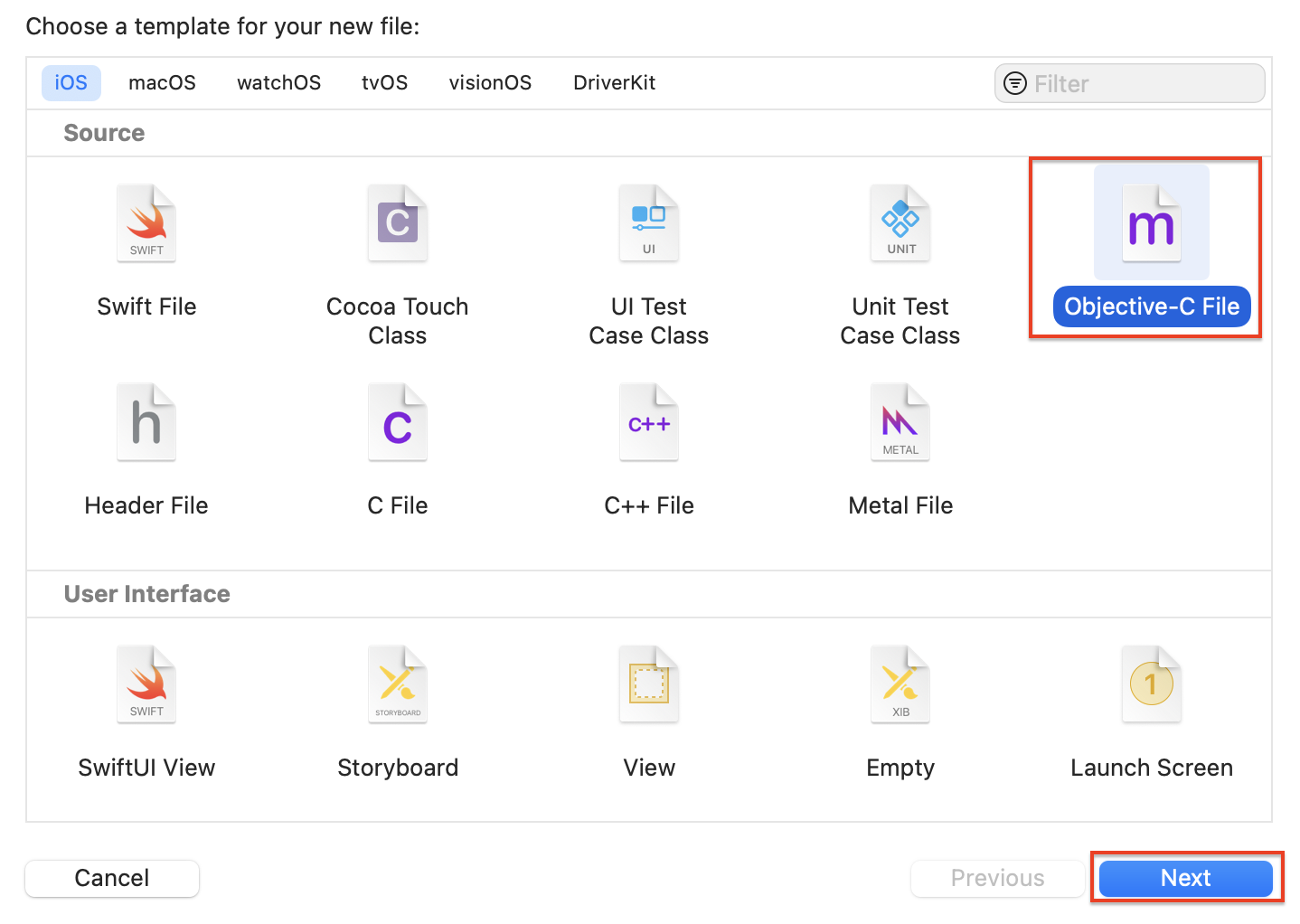
File에 TorchModule을 입력하고 Next 버튼을 클릭해주세요.
아래와 같은 팝업으로 이동하면, 저장할 프로젝트(폴더)를 선택한 후 Create 버튼을 클릭해 주세요.
TorchModule.m이 생성되었네요. 이제 확장자를 .mm으로 확장해줘야합니다.
UIImageHelper 모듈에서 확장자를 변경한 방법과 동일하게 진행하시면 됩니다.
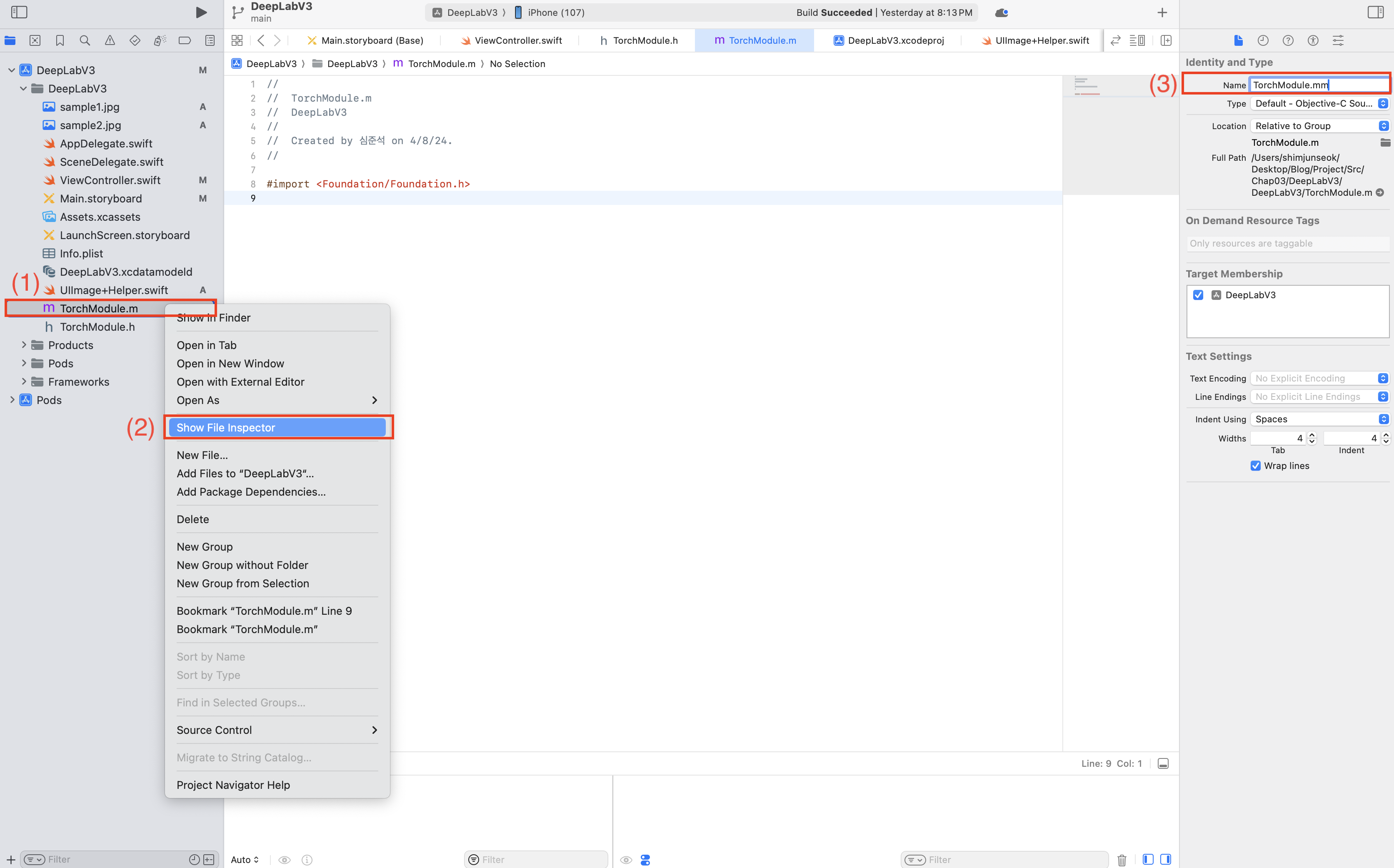
(.m에서 .mm으로 확장자 변경 완료)
이제 TorchModule.h에 선언했던 메서드들을 작성해주도록 하겠습니다.
먼저 라이브러리들을 호출해주고, 클래스 및 모델의 인스턴스를 선언해주도록 하겠습니다.
#import "TorchModule.h"
#import "UIImageHelper.h"
#import <CoreImage/CoreImage.h>
#import <ImageIO/ImageIO.h>
#import <Libtorch/Libtorch.h>
@implementation TorchModule {
@protected
torch::jit::script::Module _impl;
}@implementation TorchModule : TorchModule이라는 이름의 클래스를 구현하겠다는 것을 나타냅니다. 이것은 Objective-C에서 클래스의 메서드들을 정의할 때 사용하는 지시어입니다.
torch::jit::script::Module _impl; C++의 PyTorch 라이브러리에 정의된 torch::jit::script::Module 타입의 인스턴스 변수 _impl을 선언합니다. 이 변수는 JIT(Just-In-Time) 컴파일된 PyTorch 모델을 나타내며, 모델 로딩, 실행 등 PyTorch 관련 작업을 수행하는 데 사용됩니다.
클래스 및 모델의 인스턴스를 생성했으니, 초기화 메서드인 initWithFileAtPath를 만들어보도록 하겠습니다.
initWithFileAtPath
- (nullable instancetype)initWithFileAtPath:(NSString*)filePath { // --- (1)
self = [super init]; // --- (2)
if (self) {
try {
_impl = torch::jit::load(filePath.UTF8String); // --- (3)
_impl.eval(); // --- (4)
} catch (const std::exception& exception) { // --- (5)
NSLog(@"%s", exception.what()); // --- (6)
return nil; // --- (7)
}
}
return self; // --- (8)
}(1) : 초기화 메서드인
initWithFileAtPath를 선언합니다.NSString타입의filePath를 입력으로 받으며,filePath가nullable키워드가 아니라면instancetype을 반환합니다.
(2) : 상위 클래스의 초기화 메서드를 호출하여 현재 인스턴스(self)를 초기화합니다. 초기화가 성공하면self에 초기화된 객체가 할당됩니다.
(3) :filePath의 문자열을 UTF-8 C 스트링으로 변환하고, 이 경로에서 PyTorch 모델을 로드하기 위해 PyTorch C++ API의torch::jit::load함수를 호출합니다. 로드된 모델은_impl인스턴스 변수에 저장됩니다.
(4) : 로드된 모델을 평가 모드로 설정합니다. 이는 모델을 추론에 사용할 준비가 되었음을 의미하며, 학습 시에만 필요한 동작(예: 드롭아웃)이 비활성화됩니다.
(5) : C++의 예외 처리 구문입니다.torch::jit::load함수 또는_impl.eval();호출에서 예외가 발생하면 이 블록이 실행됩니다.
(6) : 예외가 발생한 경우, 예외 메시지를 로그로 출력합니다.exception.what()는 발생한 예외의 설명을 반환하는 C++ 표준 예외 클래스의 메서드입니다.
(7) : 예외가 발생하면 초기화가 실패한 것으로 간주하고,nil을 반환하여 이를 호출한 코드에 알립니다. 이는 객체의 생성을 중단하고 메모리 할당을 방지합니다.
(8) : 초기화 과정이 성공적으로 완료되면, 초기화된 객체(self)를 반환합니다. 이는 메서드 호출자가 초기화된 인스턴스를 사용할 수 있도록 합니다.
이제 세그멘테이션을 직접적으로 수행하는 segmentImage:withWidth:withHeight: 메서드입니다. 전체 코드는 아래와 같습니다.
segmentImage:withWidth:withHeight:
- (unsigned char*)segmentImage:(void *)imageBuffer withWidth:(int)width withHeight:(int)height {
try {
// see http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2007/segexamples/index.html for the list of classes with indexes
const int CLASSNUM = 21;
const int DOG = 12;
const int PERSON = 15;
const int SHEEP = 17;
at::Tensor tensor = torch::from_blob(imageBuffer, { 1, 3, width, height }, at::kFloat);
float* floatInput = tensor.data_ptr<float>();
if (!floatInput) {
return nil;
}
NSMutableArray* inputs = [[NSMutableArray alloc] init];
for (int i = 0; i < 3 * width * height; i++) {
[inputs addObject:@(floatInput[i])];
}
c10::InferenceMode guard;
CFTimeInterval startTime = CACurrentMediaTime();
auto outputDict = _impl.forward({ tensor }).toGenericDict();
CFTimeInterval elapsedTime = CACurrentMediaTime() - startTime;
NSLog(@"inference time:%f", elapsedTime);
auto outputTensor = outputDict.at("out").toTensor();
float* floatBuffer = outputTensor.data_ptr<float>();
if (!floatBuffer) {
return nil;
}
NSMutableArray* results = [[NSMutableArray alloc] init];
for (int i = 0; i < CLASSNUM * width * height; i++) {
[results addObject:@(floatBuffer[i])];
}
NSMutableData* data = [NSMutableData dataWithLength:sizeof(unsigned char) * 3 * width * height];
unsigned char* buffer = (unsigned char*)[data mutableBytes];
// go through each element in the output of size [WIDTH, HEIGHT] and
// set different color for different classnum
for (int j = 0; j < width; j++) {
for (int k = 0; k < height; k++) {
int maxi = 0, maxj = 0, maxk = 0;
float maxnum = -100000.0;
for (int i = 0; i < CLASSNUM; i++) {
if ([results[i * (width * height) + j * width + k] floatValue] > maxnum) {
maxnum = [results[i * (width * height) + j * width + k] floatValue];
maxi = i; maxj = j; maxk = k;
}
}
int n = 3 * (maxj * width + maxk);
// color coding for person (red), dog (green), sheep (blue)
// black color for background and other classes
buffer[n] = 0; buffer[n+1] = 0; buffer[n+2] = 0;
if (maxi == PERSON) buffer[n] = 255;
else if (maxi == DOG) buffer[n+1] = 255;
else if (maxi == SHEEP) buffer[n+2] = 255;
}
}
return buffer;
} catch (const std::exception& exception) {
NSLog(@"%s", exception.what());
}
return nil;
}
@end코드가 많으니 부분적으로 보도록 하겠습니다
const int CLASSNUM = 21;
const int DOG = 12;
const int PERSON = 15;
const int SHEEP = 17;이미지 세그멘테이션을 수행할 때 사용되는 클래스(카테고리)의 수와 특정 클래스에 할당된 고유한 인덱스를 정의한 부분입니다.
- CLASSNUM = 21; : 이미지 세그멘테이션 모델이 구분할 수 있는 전체 클래스(카테고리)의 수입니다. 예를 들어, 이 숫자는 모델이 인식할 수 있는 다양한 객체 유형(사람, 동물, 차량 등)의 총 수를 의미합니다.
- DOG = 12; : "개" 클래스에 할당된 고유 인덱스입니다. 세그멘테이션 모델이 이미지 내에서 개를 인식할 때 이 인덱스를 사용하여 해당 객체를 구분합니다.
- PERSON = 15; : "사람" 클래스에 할당된 고유 인덱스입니다. 모델이 이미지에서 사람을 인식하는 경우, 이 인덱스를 통해 사람 객체를 식별합니다.
- SHEEP = 17; : "양" 클래스에 할당된 고유 인덱스입니다. 이는 모델이 이미지 내에서 양을 검출할 때 사용됩니다.
at::Tensor tensor = torch::from_blob(imageBuffer, { 1, 3, width, height }, at::kFloat);Pytorch C++ API를 사용하여 메모리 버퍼로부터 텐서를 생성하는 과정입니다. torch::from_blob 함수는 주어진 메모리 버퍼에 대한 텐서를 생성하는 데 사용되며, 이 텐서는 특정 차원과 데이터 타입을 가집니다.
at::Tensor tensor : 생성된 텐서를 저장하기 위한 변수 선언입니다. at::Tensor는 PyTorch에서 텐서를 나타내는 기본 데이터 타입입니다.
torch::from_blob : 주어진 메모리 버퍼(imageBuffer)로부터 텐서를 생성합니다. 이 함수는 다음 매개변수를 받습니다:
- imageBuffer: 이미지 데이터를 포함하고 있는 메모리 버퍼의 포인터입니다. 이 버퍼는 이미지의 원시 픽셀 값들을 포함합니다.
- { 1, 3, width, height }: 생성할 텐서의 차원을 나타냅니다. 여기서 1은 배치 크기(이 경우 단일 이미지 처리를 가정), 3은 채널 수(RGB 이미지를 가정), width와 height는 이미지의 너비와 높이를 의미합니다.
at::kFloat: 텐서의 데이터 타입을 나타냅니다. at::kFloat은 32비트 부동소수점 숫자(float)를 의미합니다.
float* floatInput = tensor.data_ptr<float>();PyTorch의 텐서에서 데이터 포인터를 추출하고, 그 포인터의 유효성을 검증하는 과정입니다.
float* floatInput = tensor.data_ptr<float>():tensor라는 이름의 PyTorch 텐서에서 실수 데이터를 가리키는 포인터를 얻습니다.data_ptr<float>()메서드는 텐서가 저장하고 있는 데이터의 첫 번째 원소를 가리키는float타입의 포인터를 반환합니다. 이때 이 포인터는 텐서의 모든 원소에 접근하기 위해 사용될 수 있습니다.
NSMutableArray* inputs = [[NSMutableArray alloc] init];
for (int i = 0; i < 3 * width * height; i++) {
[inputs addObject:@(floatInput[i])];
}NSMutableArray* inputs = [[NSMutableArray alloc] init] :
NSMutableArray의 새 인스턴스를 생성하고 초기화합니다. 이 배열은 텐서의 모든 데이터 포인트를 저장하기 위해 사용됩니다.
for (int i = 0; i < 3 width height; i++) { : 텐서의 각 데이터 포인트를 순회하기 위한 반봅문입니다.
[inputs addObject:@(floatInput[i])] : 반복문 내에서, 각 반복마다floatInput포인터가 가리키는 텐서의i번째 원소를 가져와NSNumber객체로 변환한 후,inputs배열에 추가합니다.@(floatInput[i])구문은floatInput[i]값을NSNumber로 감싸는 Objective-C의 박싱문법입니다. 이렇게 함으로써, C++의 원시float데이터 타입을 Objective-C의 객체 타입으로 변환하여,NSMutableArray에 저장할 수 있게 됩니다.
CFTimeInterval startTime = CACurrentMediaTime();
auto outputDict = _impl.forward({ tensor }).toGenericDict();
CFTimeInterval elapsedTime = CACurrentMediaTime() - startTime;
NSLog(@"inference time:%f", elapsedTime);Objective-C++에서 PyTorch 모델을 사용하여 이미지에 대한 추론(inference)을 수행하고, 추론에 소요된 시간을 측정하는 과정입니다.
- CFTimeInterval startTime = CACurrentMediaTime() : 추론 시작 시간 측정
- auto outputDict = _impl.forward({ tensor }).toGenericDict() :
_impl객체의forward메서드를 호출하여, 입력 텐서(tensor)에 대한 모델의 추론을 수행합니다.forward메소드는 모델의 출력을 반환하며, 반환 경과를 일반적인 딕셔너리 형태로 변환하기 위해toGenericDict()메서드를 호출합니다.outputDict변수는 모델의 출력을 저장하며,auto키워드는 변수의 타입을 컴파일러에 의해 자동으로 추론하도록 합니다.- CFTimeInterval elapsedTime = CACurrentMediaTime() - startTime : 추론 종료 시간 측정 및 소요 시간을 계산합니다.
- NSLog(@"inference time:%f", elapsedTime) :
NSLog함수를 사용하여 추론 시간을 로그로 출력합니다.
auto outputTensor = outputDict.at("out").toTensor();PyTorch 모델의 추론 결과로 얻은 일반 딕셔너리(outputDict)에서 특정 키("out")에 해당하는 값을 조회하고, 그 값을 텐서(outputTensor)로 변환하는 과정입니다.
float* floatBuffer = outputTensor.data_ptr<float>();PyTorch의 텐서(outputTensor)에서 실제 데이터를 가리키는 포인터(float*를 얻는 과정을 보여줍니다. 여기서 사용된 data_ptr<float>() 메서드는 텐서에 저장된 데이터의 메모리 주소를 반환합니다. 반환된 포인터는 float 타입의 데이터를 가리키며, 이는 텐서가 float 타입의 데이터를 저장하고 있음을 의미합니다.
NSMutableArray* results = [[NSMutableArray alloc] init];Objective-C에서 NSMutableArray의 새 인스턴스를 생성하고 초기화하는 과정을 나타냅니다. NSMutableArray는 가변 배열을 구현하는 클래스로, 배열에 저장된 객체들의 목록을 변경할 수 있습니다. 이는 배열에 동적으로 객체를 추가하거나 제거할 수 있게 해줍니다.
NSMutableData* data = [NSMutableData dataWithLength:sizeof(unsigned char) * 3 * width * height];
unsigned char* buffer = (unsigned char*)[data mutableBytes];
// go through each element in the output of size [WIDTH, HEIGHT] and
// set different color for different classnum
for (int j = 0; j < width; j++) {
for (int k = 0; k < height; k++) {
int maxi = 0, maxj = 0, maxk = 0;
float maxnum = -100000.0;
for (int i = 0; i < CLASSNUM; i++) {
if ([results[i * (width * height) + j * width + k] floatValue] > maxnum) {
maxnum = [results[i * (width * height) + j * width + k] floatValue];
maxi = i; maxj = j; maxk = k;
}
}
int n = 3 * (maxj * width + maxk);
// color coding for person (red), dog (green), sheep (blue)
// black color for background and other classes
buffer[n] = 0; buffer[n+1] = 0; buffer[n+2] = 0;
if (maxi == PERSON) buffer[n] = 255;
else if (maxi == DOG) buffer[n+1] = 255;
else if (maxi == SHEEP) buffer[n+2] = 255;
}
}이미지 세그멘테이션 결과를 기반으로 색상 코딩을 적용하여 이미지 데이터를 수정하는 과정입니다.
메모리 공간 준비:
NSMutableData data = [NSMutableData dataWithLength:sizeof(unsigned char) 3 width height]; 이 줄은 width와 height를 기반으로 한 이미지 크기에 대응하는 메모리 공간을 할당합니다. 각 픽셀에 대해 RGB 각각의 컬러 채널을 저장할 수 있도록 3 width height 만큼의 공간을 할당합니다. sizeof(unsigned char)는 각 채널의 데이터 크기를 나타냅니다.메모리 포인터 획득:
unsigned char buffer = (unsigned char)[data mutableBytes]; 이 코드는 할당된 NSMutableData 객체의 실제 데이터를 가리키는 포인터를 얻습니다. 이 포인터를 통해 데이터를 직접 수정할 수 있습니다.색상 코딩 적용:
반복문을 사용하여 이미지의 모든 픽셀을 순회합니다. 각 픽셀 위치에 대해, 모델의 출력 결과(results)에서 해당 위치의 픽셀이 가장 높은 확률을 가진 클래스를 찾습니다.
찾은 클래스(maxi)에 따라 해당 픽셀의 RGB 값을 설정합니다. 사람(PERSON)은 빨간색, 개(DOG)는 초록색, 양(SHEEP)은 파란색으로 설정합니다. 그 외 클래스에 속하는 픽셀은 모두 검정색으로 처리됩니다.색상 값 설정:
buffer[n] = 0; buffer[n+1] = 0; buffer[n+2] = 0;로 시작하여 모든 픽셀을 기본적으로 검정색으로 설정합니다.
이후 조건문을 사용하여 특정 클래스에 해당하는 픽셀의 색상을 변경합니다. 예를 들어, if (maxi == PERSON) buffer[n] = 255;는 해당 픽셀이 사람일 경우 빨간색으로 설정합니다.
이제 다시 ViewController()를 볼까요?

그래도 아직 Swift에서 TorchModule을 인식하지 못하고 있네요. DeepLabV3-Bridging-Header.h로 가서 다음 코드를 추가해주세요.
#import "TorchModule.h"
#import "UIImageHelper.h"다시 ViewController()를 보면, 에러들이 깔끔하게 사라진 것을 확인할 수 있습니다!
5-4. 실행
이제 중간 빌드를 한번 해보도록 하겠습니다.
빌드를 하기전, 현재 프로젝트에 이전에 생성했던 deeplabv3_scripted.pt파일을 추가해주도록 하겠습니다.
(1)-(2)-(3) 순서대로 클릭 후 (4) + 버튼을 클릭해주세요.
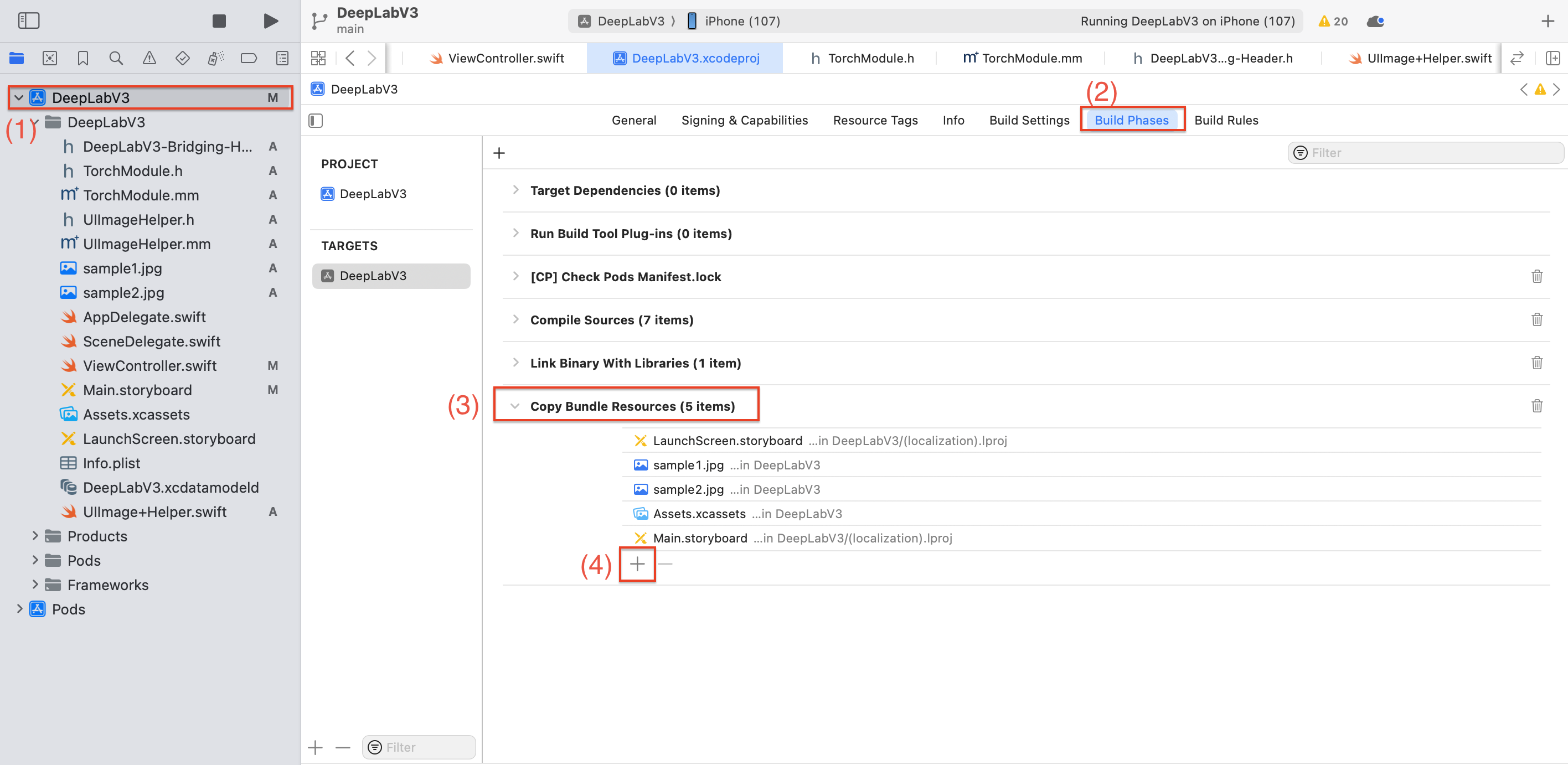
Add other을 클릭해주고
DeepLabV3 프로젝트에서 deeplabv3_scripted.pt를 선택한 후, Open 버튼을 클릭해주세요.
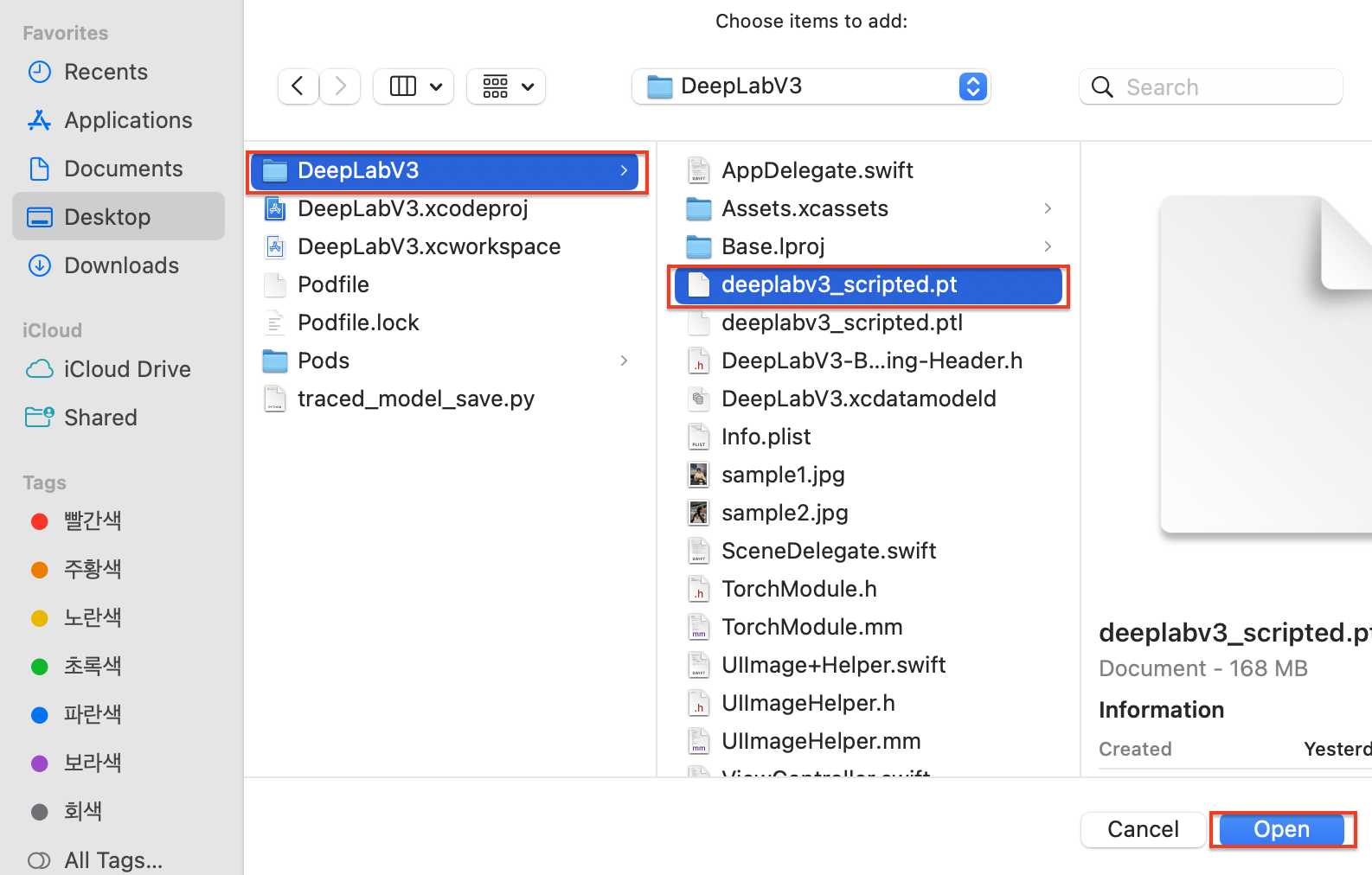
다음 팝업으로 넘어가면 Destination은 Copy items if needed, Added folders는 Create folder references를 선택한 후 Finish 버튼을 클릭해 주세요.
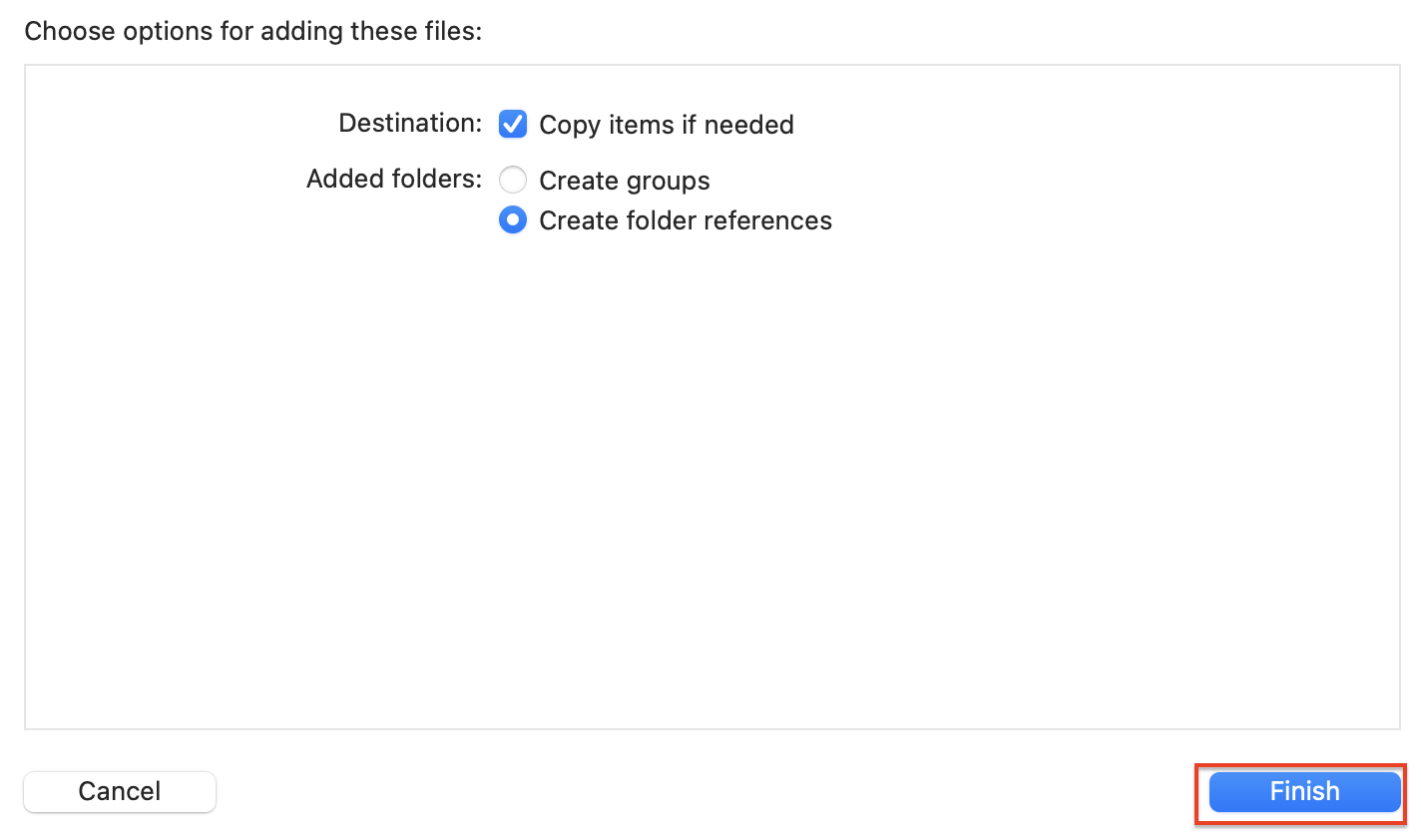
이제 프로젝트에 deeplabv3_scripted.pt 파일이 추가되었습니다!

빌드 및 실행
중간 빌드 후, 한번 실행해보도록 하겠습니다.
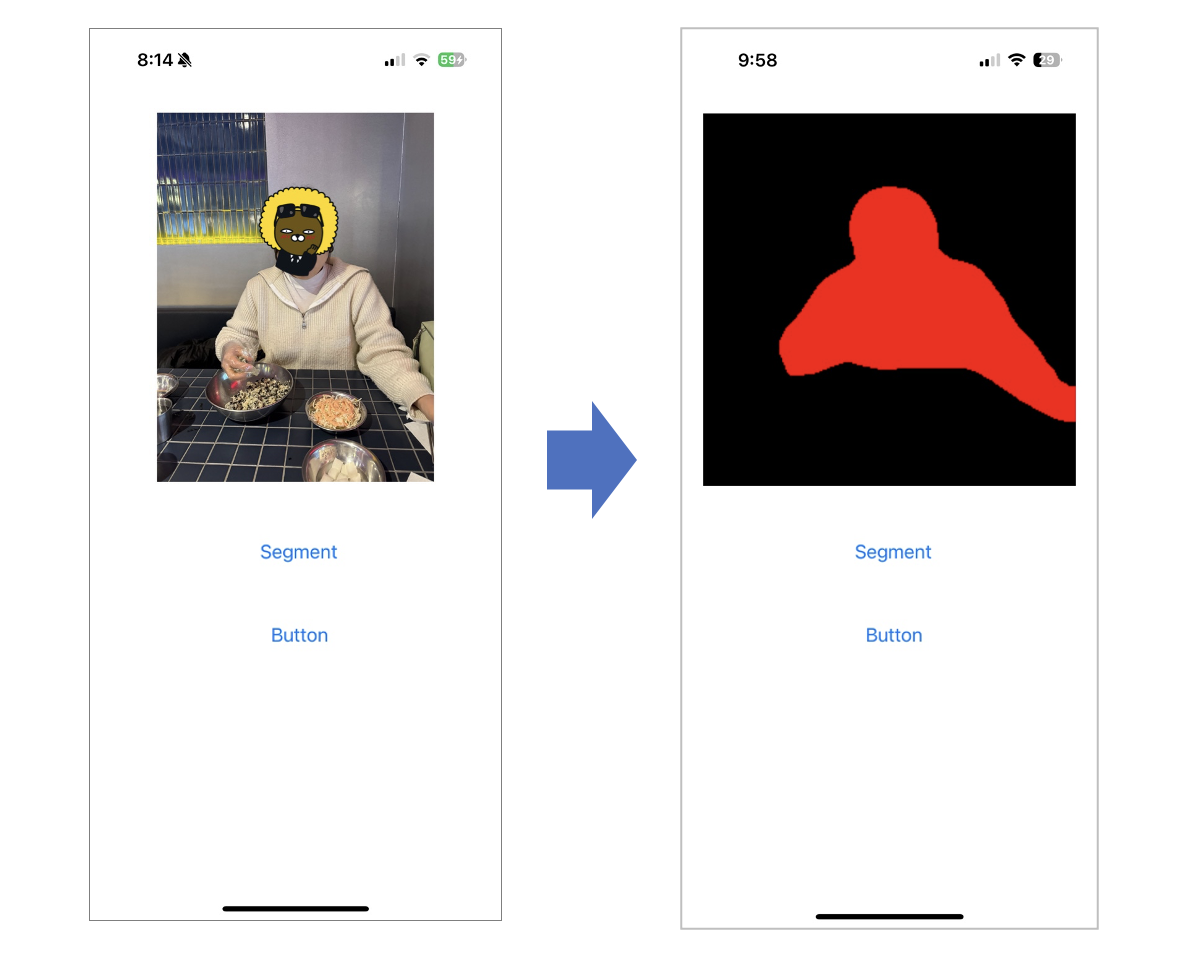
아래 캡처와 같이 Segmentation이 잘 실행되네요!
6. 다른 이미지 추가하기
다른 이미지 sample2.jpg도 DeepLabV3 애플리케이션에 추가해보도록 하겠습니다.
아래 Button에도 액션함수를 추가해, 버튼을 클릭시 다른 이미지로 넘어가도록 하겠습니다.
doInfer에서 액션함수를 생성한 것과 동일하게 doRestart 메서드를 추가해주도록 하겠습니다.

그리고 아래와 같이 doRestart를 수정해주세요.
@IBAction func doRestart(_ sender: UIButton) {
if imageName == "sample1.jpg" {
imageName = "sample2.jpg"
}
else {
imageName = "sample1.jpg"
}
image = UIImage(named: imageName)!
imageView.image = image
} 다시 한번 빌드후 실행해보겠습니다!!
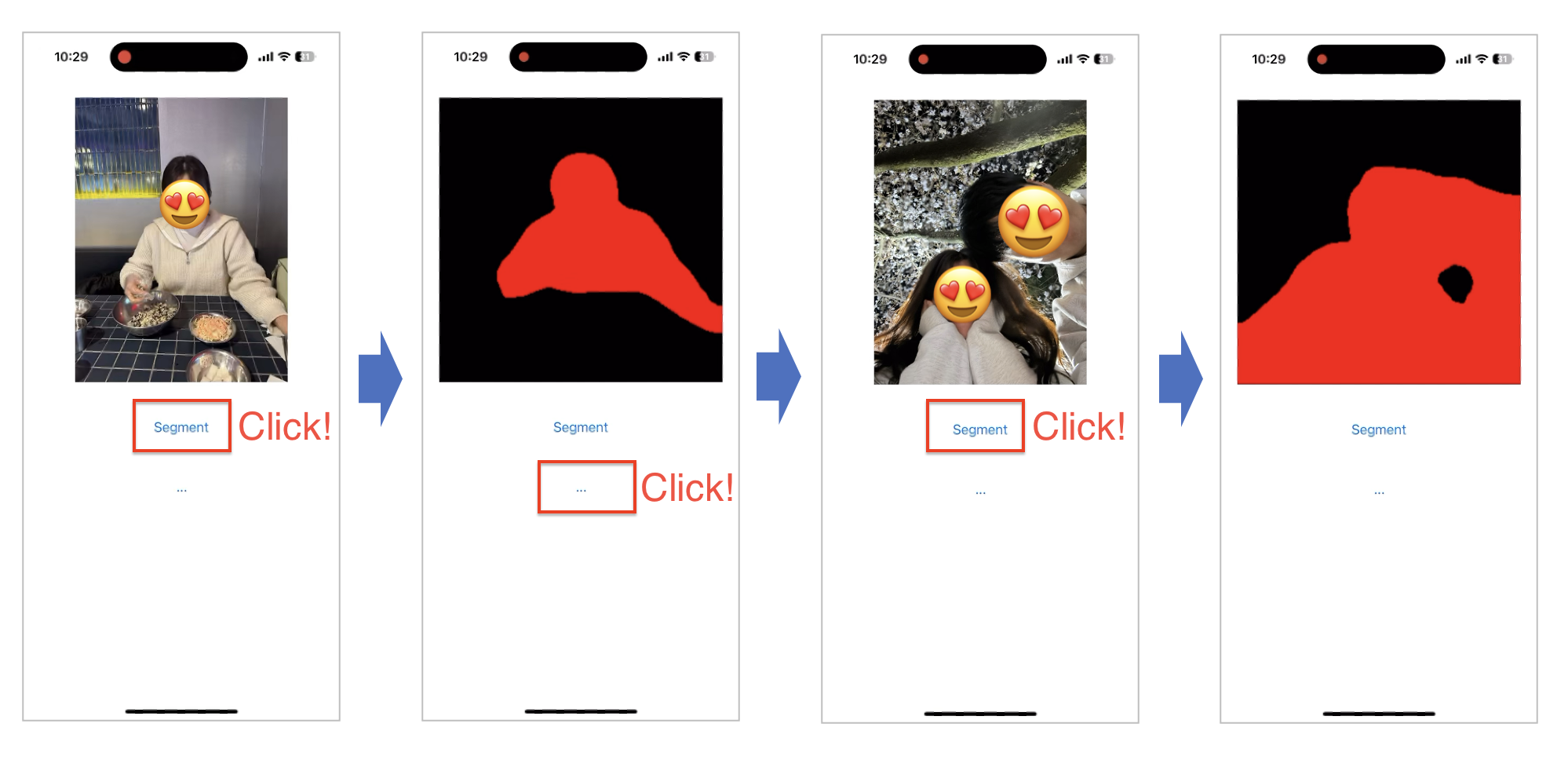
아주 잘 실행되네요!
7. 마무리
이번 장을 진행하면서 iOS, Swift, Objective-C++ 등등 익숙하지 않은 분야에 도전해가며 어렵지만 이렇게 결과물이 나오니 너무 뿌듯하다는 생각이 듭니다!
너무 내용이 길기도 하고, 두서없이 정리를 하지않았나 싶어요. 다음 포스팅은 아이폰 카메라에 Object Detection 모델을 올려보도록 하겠습니다!
파이썬이나 임베디드만 해오던 저에게는 쉽지 않은 도전이겠지만, 또 이 과정을 거쳐가며 성장하리라 생각합니다!
다음 포스팅에서 뵙겠습니다 !! 😊
