[openCV] 선형회귀와 CNN, 그리고 미디어파이프 써보기
Linear Regression
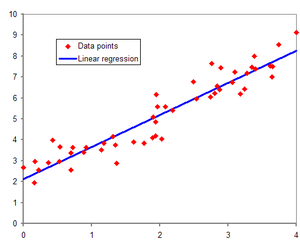
선형 회귀는 데이터 포인트들 사이의 관계를 모델링하는 통계적 방법 중 하나다. 주로 입력 변수와 출력 변수 사이의 관계를 이해하고 예측하기 위해 사용된다.
여기서 선형이란 말은 모델이 직선 형태의 관계를 나타낸다는 것을 의미합니다. 즉, 하나 이상의 입력 변수들과 하나의 출력 변수 간의 선형 관계를 나타내는 모델이다.
선형 회귀 모델은 입력 변수의 선형 조합을 사용하여 출력 변수를 예측한다. 이 선형 조합은 각 입력 변수와 해당 변수의 가중치(coefficients)를 곱한 후, 상수항(intercept)을 더하여 구성됩니다. 모델은 이러한 가중치와 상수항을 학습하여 데이터에 가장 잘 맞는 예측을 할 수 있도록 한다.
선형 회귀는 주어진 데이터에 대해 가장 적합한 직선을 찾아내는 방법 중 하나로, 데이터를 통해 이러한 직선의 방정식을 찾아내고, 새로운 입력 값이 주어졌을 때 출력 값을 예측할 수 있다.
선형회귀의 기본 원리
선형 회귀의 기본 원리는 데이터를 가장 잘 설명하는 선형 관계를 찾는 것입니다. 이것은 주어진 입력 변수와 출력 변수 간의 관계를 모델링하는 것을 의미합니다.
기본적으로 선형 회귀는 다음과 같은 단계로 이루어진다:
1. 데이터 수집
우선, 연구나 문제 해결을 위해 관련 데이터를 수집한다. 이 데이터에는 입력 변수와 출력 변수이 포함된다.
2. 모델 정의
선형 회귀 모델을 선택한다. 이 모델은 입력 변수들의 선형 조합으로 출력 변수를 예측하는 방법을 나타낸다. 보통은 다음과 같은 형태로 표현된다.
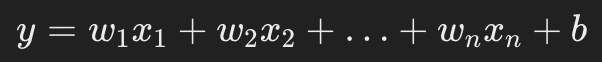
여기서 각각의 변수들은 아래와 같다.

3. 손실 함수 정의
선형 회귀에서는 일반적으로 최소 제곱 오차를 사용하여 모델의 예측값과 실제값 사이의 차이를 측정한다. 이 오차를 최소화하기 위해 손실 함수를 정의한다.
4. 모델 학습
주어진 데이터를 사용하여 모델의 가중치와 상수항을 조정하여 손실 함수를 최소화하는 방향으로 모델을 학습시킨다. 이는 일반적으로 경사 하강법(Gradient Descent) 또는 최적화 알고리즘을 사용하여 수행된다.
5. 모델 평가
학습된 모델을 평가하여 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지 확인한다. 이것은 예측 성능 지표를 사용하여 수행된다.
6. 예측
마지막으로, 학습된 모델을 사용하여 새로운 입력 변수에 대한 출력 변수 값을 예측한다.
CNN(Convolutional Neural Networks)
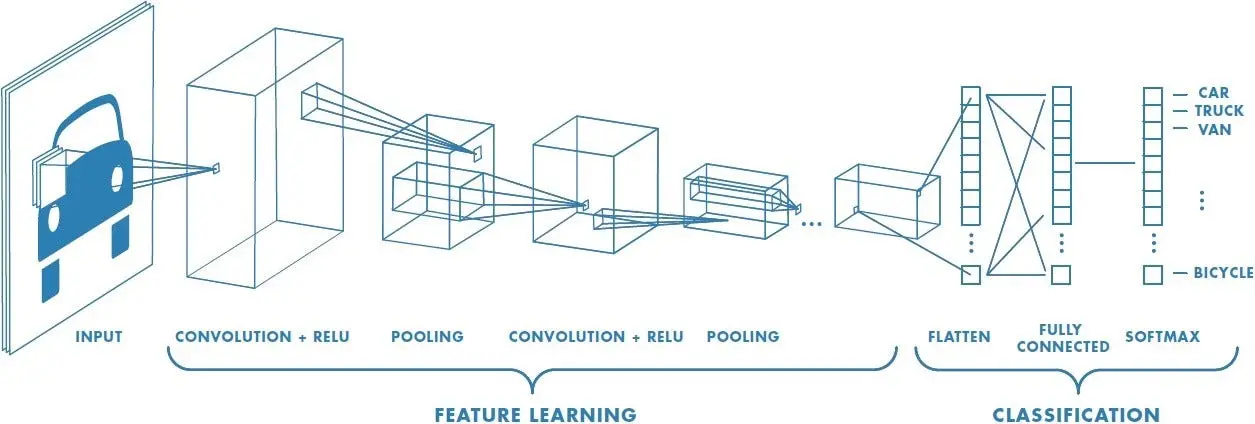
CNN은 인간의 시신경을 모방하여 만든 딥러닝 구조 중 하나다. 특히 convolution 연산을 이용하여 이미지의 공간적인 정보를 유지하고, Fully connected Neural Network 대비 연산량을 획기적으로 줄였으며, 이미지 분류에서 좋은 성능을 보이는 것으로 알려져있다.
CNN의 원리
CNN은 이미지 처리에 특화된 딥러닝 모델의 한 종류로, 이미지의 특징을 자동으로 추출하고 이를 기반으로 이미지를 분류한다. 기존의 신경망과는 다르게, CNN은 이미지의 공간 정보를 유지하면서 학습이 가능하도록 설계되었다. 이는 CNN이 이미지 내의 작은 부분에 집중하여 패턴을 인식할 수 있게 해준다.
CNN의 주요 구성 요소
합성곱 계층(Convolutional Layer)
이 계층은 이미지에서 특징을 추출하는 역할을 합니다. 여러 개의 필터(커널)를 사용하여 이미지를 스캔하고, 각 필터가 이미지의 특정 특징을 활성화시키는 방식으로 작동합니다.
활성화 함수(Activation Function)
대부분의 CNN에서는 ReLU(Rectified Linear Unit) 활성화 함수가 사용된다. 이 함수는 비선형성을 도입하여 네트워크가 복잡한 패턴을 학습할 수 있게 도와준다.
풀링 계층(Pooling Layer)
풀링 계층은 이미지의 차원을 축소하여 계산량을 줄이는 동시에 중요한 정보를 유지한다. 가장 흔히 사용되는 방법은 맥스 풀링(Max Pooling)으로, 지정된 영역 내에서 가장 큰 값을 선택하는 방식이다.
완전 연결 계층(Fully Connected Layer)
이 계층은 합성곱 계층과 풀링 계층을 거친 후의 정보를 바탕으로 최종 분류를 수행한다. 이미지가 속할 클래스에 대한 확률을 출력하기 위해 사용된다.
전의학습

전이 학습(Transfer Learning)은 딥러닝에서 기존에 학습된 모델의 지식을 새로운 관련 작업에 활용하는 기술이다.
기존의 대규모 데이터셋에서 사전에 학습된 모델을 가져와서, 이 모델의 가중치를 새로운 작업에 적용하여 성능을 개선하거나 학습 시간을 단축하는 것이 전이 학습의 핵심 아이디어다.
전의학습의 주요 단계
사전 학습된 모델 선택
일반적으로 대규모 이미지 데이터셋(예: ImageNet)에서 사전에 학습된 모델을 선택한다. 이 모델은 보통 많은 계층(layer)으로 구성된 딥러닝 아키텍쳐다.
모델 파인 튜닝(Fine-tuning)
선택한 사전 학습된 모델을 가져와서, 새로운 작업에 맞게 일부 계층을 고정하고 나머지 계층의 가중치를 조정한다. 새로운 작업에 더 적합하도록 네트워크를 조정하는 과정이다.
새로운 데이터셋에 대한 학습
파인 튜닝된 모델을 새로운 작업에 맞는 데이터셋으로 학습시킨다. 이 과정에서 적은 양의 데이터로도 높은 성능을 달성할 수 있다.
해보자
먼저 openCV를 활용해 동물을 구분해보자.
import sys
import numpy as np
import cv2
# 이미지 파일 경로 지정
filename = 'data/리트리버.webp'
# 이미지 파일 읽어오기
img = cv2.imread(filename)
# 이미지 파일이 제대로 읽혔는지 확인
if img is None:
print('Image load failed!')
exit()
# 신경망 모델 불러오기
net = cv2.dnn.readNet('data/bvlc_googlenet.caffemodel', 'data/deploy.prototxt')
# 신경망 모델이 제대로 불러와졌는지 확인
if net.empty():
print('Network load failed!')
exit()
# 클래스 이름 불러오기
classNames = None
with open('data/classification_classes_ILSVRC2012.txt', 'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
# 이미지 전처리 (크기 조정 및 평균값 제거)
inputBlob = cv2.dnn.blobFromImage(img, 1, (224, 224), (104, 117, 123))
net.setInput(inputBlob)
# 이미지를 신경망에 전달하고 예측 수행
prob = net.forward()
# 예측 결과 확인 및 출력
out = prob.flatten()
classId = np.argmax(out)
confidence = out[classId]
# 클래스 이름과 해당 클래스의 신뢰도를 텍스트로 생성
text = '%s (%4.2f%%)' % (classNames[classId], confidence * 100)
# 이미지에 텍스트 출력
# 수정된 부분: 폰트 스케일을 2로 크게 조정하여 텍스트 크기를 키움
cv2.putText(img, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 2, cv2.LINE_AA)
# 이미지 창에 이미지 출력
cv2.imshow('img', img)
# 키 입력 대기
cv2.waitKey()
# 모든 창 닫기
cv2.destroyAllWindows()
이렇게 귀여운 리트리버인 것을 확인할 수 있다.

욕 모자이크하기
mediapipe를 활용해서 미들핑거를 모자이크해서 어린이들을 지켜보자.
import cv2
import mediapipe as mp
mp_hands = mp.solutions.hands
# 최대 손 갯수를 1개로 설정하여 손을 감지.
hands = mp_hands.Hands(static_image_mode=False, max_num_hands=1)
# 모자이크 함수를 정의합니다.
def mosaic(img, x, y, w, h, size=30):
if x < 0 or y < 0 or x + w >= img.shape[1] or y + h >= img.shape[0]:
return
for i in range(int(w / size)):
for j in range(int(h / size)):
xi = x + i * size
yi = y + j * size
if xi < 0 or yi < 0 or xi + size >= img.shape[1] or yi + size >= img.shape[0]:
continue
# 해당 영역을 블러 처리하여 모자이크 효과 생성
img[yi:yi + size, xi:xi + size] = cv2.blur(img[yi:yi + size, xi:xi + size], (23, 23))
# 웹캠
cap = cv2.VideoCapture(0)
while cap.isOpened():
# 프레임을 읽어옵니다.
ret, frame = cap.read()
if not ret:
continue
frame = cv2.flip(frame, 1)
# 프레임을 RGB 형식으로 변환한다.
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 손 감지 결과를 얻습니다.
results = hands.process(rgb_frame)
# 손 감지 결과가 있을 경우
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 검지 손가락 끝과 중지 손가락 끝의 y 좌표를 얻는다.
index_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.INDEX_FINGER_TIP].y * frame.shape[0]
middle_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.MIDDLE_FINGER_TIP].y * frame.shape[0]
# 검지 손가락 끝이 중지 손가락 끝보다 아래에 있을 경우
if index_finger_tip_y > middle_finger_tip_y:
# 손가락들의 최소 x, y 좌표와 최대 x, y 좌표를 구함
x_min, y_min = int(min(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(min(l.y * frame.shape[0] for l in hand_landmarks.landmark))
x_max, y_max = int(max(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(max(l.y * frame.shape[0] for l in hand_landmarks.landmark))
mosaic(frame, x_min, y_min, x_max - x_min, y_max - y_min)
# 모자이크가 적용된 프레임 보여줌
cv2.imshow('Mosaic hand', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()

도중에 오류가 발생했었는데 mediapipe 버전문제였다. 원래 0.10.11이었던 버전을 0.10.9 버전으로 다운그레이드하니 오류가 해결됬다.
pip uninstall mediapipe미디어파이프를 삭제했다가 낮은 버전으로 다시 설치하자.
pip install mediapipe == 0.10.9오늘은 선형회귀와 CNN을 알아보았다. ai를 공부할 수록 흥미로워 져서 더 파볼려고 생각중이다.
mediapipe도 가지고 놀아봤는데 다음 글엔 더 재밌는 걸로 돌아오겠다.

