니네가 이정도 받아도 된다고 생각해?
어제 경기도 어김없이 졌다.

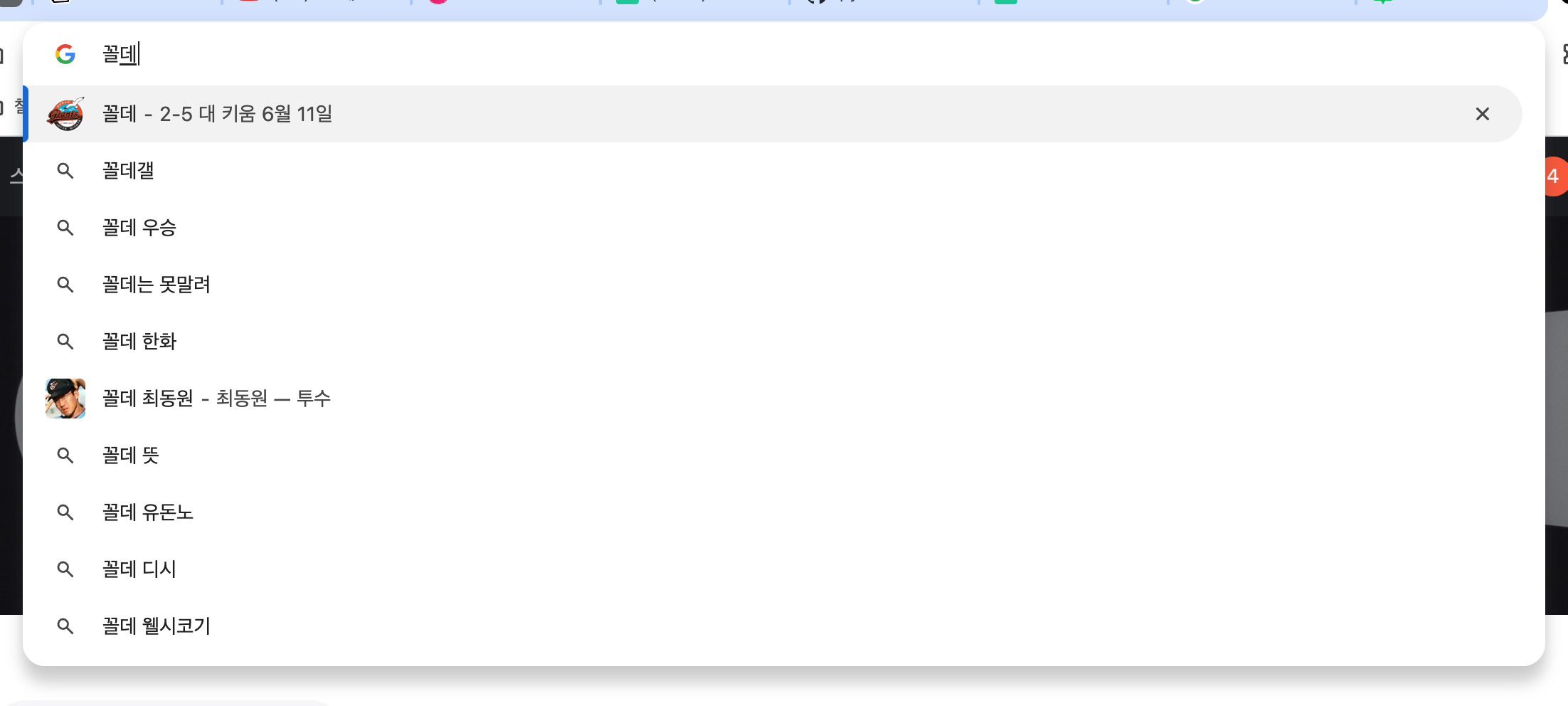
KBO 테이블 바닥 청소는 항상 롯데 담당이다.
이게맞냐?

작년에 롯데 직관을 갔을 때 상상초월 볼넷이 14개였나 그정도가 나왔다.
롯데 투수야 이거 맞냐?
오늘은 KBO 투수 작자들이 얼마나 받아갈지 예측해보도록하자.
1. KBO 연봉 데이터 둘러보기
먼저 대지피티님을 이용해 스탯티즈에서 데이터를 들고왔다.
지피티야~ https://statiz.sporki.com/ 여기서 데이터 들고와주려무나~
불러온 데이터들은 picher 라는 변수에 담았다. 그럼 어떤 컬럼들이 있는지 확인해보자.
picher.columns
쓸만한 컬럼들이 정말 많다!
한번 데이터들도 확인해보자.
picher.head()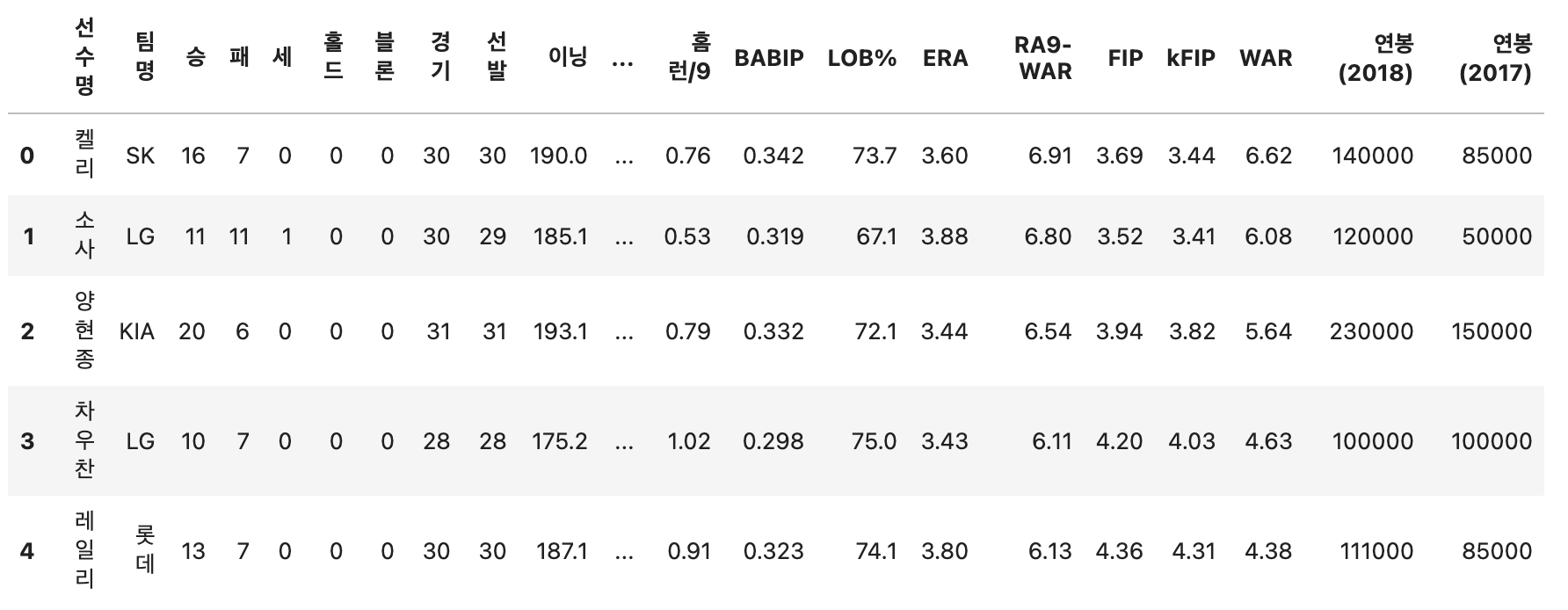
오늘은 연봉에 대해 예측을 해볼 것이기에 이제 연봉들을 다뤄보자.
우선 describe로 2018년 선수들의 연봉 데이터를 한번 알아보자.
picher['연봉(2018)'].describe()
와흥. 시각화를 해서 연봉 분포를 확인해보자.
picher.boxplot(column=['연봉(2018)'])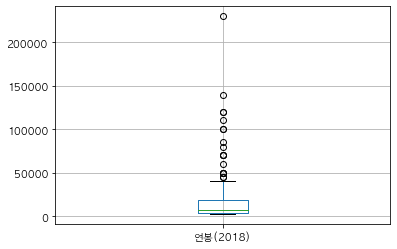
50000에서 150000사이에 많이 분포해있는 것을 확인할 수 있었다.
2. 투수 연봉 예측
이제 본격적으로 투수의 연봉을 예측해보자.
먼저 회귀분석에 사용할 피쳐들을 변수에 넣어보자. 피쳐들은 아까 columns 로 확인했던 컬럼들을 사용하자. 피쳐들은 pf_df라는 변수에 저장했다.
피처스케일링
먼저 피처 스케일링이라는 작업을 해줘야한다. 피처 스케일링은 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업인데 왜 굳이 해야하는걸까?
- 변수 값의 범위 or 단위가 달라서 발생하는 문제를 예방할 수 있다.
- 머신러닝 모델이 특정 데이터에 편향성을 가지는 것을 예방할 수 있다.
- 데이터 범위 크기에 따라 모델이 학습하는 데 있어서 바이어스가 달라질 수 있으므로 하나의 범위 크기로 통일해주는 작업이 필요하다.
그럼 각각의 피처에 대해 스케일링을 하는 함수를 작성해보자.
def features_scaling(df, scale_columns):
for col in scale_columns:
series_mean = df[col].mean()
series_std = df[col].std()
df[col] = df[col].apply(lambda x: (x-series_mean)/series_std)
return dffeatures_scaling 를 이용하여 picher의 모든 컬럼을 스케일링 해줬다.
picher_df = standard_scaling(picher, scale_columns)picher_df 를 한번 확인해보자.
잘된 것 같죠잉?
이어서 one-hot-encoding을 통해 피처들의 단위까지 맞춰보자.
team_encoding = pd.get_dummies(picher_df['팀명'])
picher_df = picher_df.drop('팀명', axis=1)
picher_df = picher_df.join(team_encoding)
team_encoding.head(5)
단위까지 맞춰줬다. 이제 본격적으로 회귀분석을 해보자.
먼저 학습 데이터와 테스트 데이터를 분리시켰다.
X = picher_df[picher_df.columns.difference(['선수명', 'y'])]
y = picher_df['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)이제 회귀분석 계수를 학습시키고 코이피션트를 확인해보자.
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
print(lr.coef)
3. 시각화
먼저 어떤 피쳐들이 영향이 높은지 확인을 해보자.
X_train = sm.add_constant(X_train)
model = sm.OLS(y_train, X_train).fit()
model.summary()실행 결과 FIP, WAR, 볼넷, 삼진 정도가 영향이 높다고 볼 수 있을 것 같다.
2018년 연봉을 예측하여 데이터프레임의 column으로 생성하자.
X = picher_df[['FIP', 'WAR', '볼넷/9', '삼진/9', '연봉(2017)']]
predict_2018_salary = lr.predict(X)
picher_df['예측연봉(2018)'] = pd.Series(predict_2018_salary)이제 예측한 연봉이 어느정도 맞는지 실제 데이터와 비교해보자.
2017년도의 데이터를 먼저 가져와서 picher에 넣어주고
picher = pd.read_csv(picher_file_path)
picher = picher[['선수명', '연봉(2017)']]원래의 데이터 프레임에 2018년 연봉 정보를 합치자.
result_df = picher_df.sort_values(by=['y'], ascending=False)
result_df.drop(['연봉(2017)'], axis=1, inplace=True, errors='ignore')
result_df = result_df.merge(picher, on=['선수명'], how='left')
result_df = result_df[['선수명', 'y', '예측연봉(2018)', '연봉(2017)']]
result_df.columns = ['선수명', '실제연봉(2018)', '예측연봉(2018)', '작년연봉(2017)']재계약하여 연봉이 변화한 선수만을 대상으로만 보자.
result_df = result_df[result_df['작년연봉(2017)'] != result_df['실제연봉(2018)']]
result_df = result_df.reset_index()
result_df = result_df.iloc[:10, :]
result_df.head(10)확인해보면?
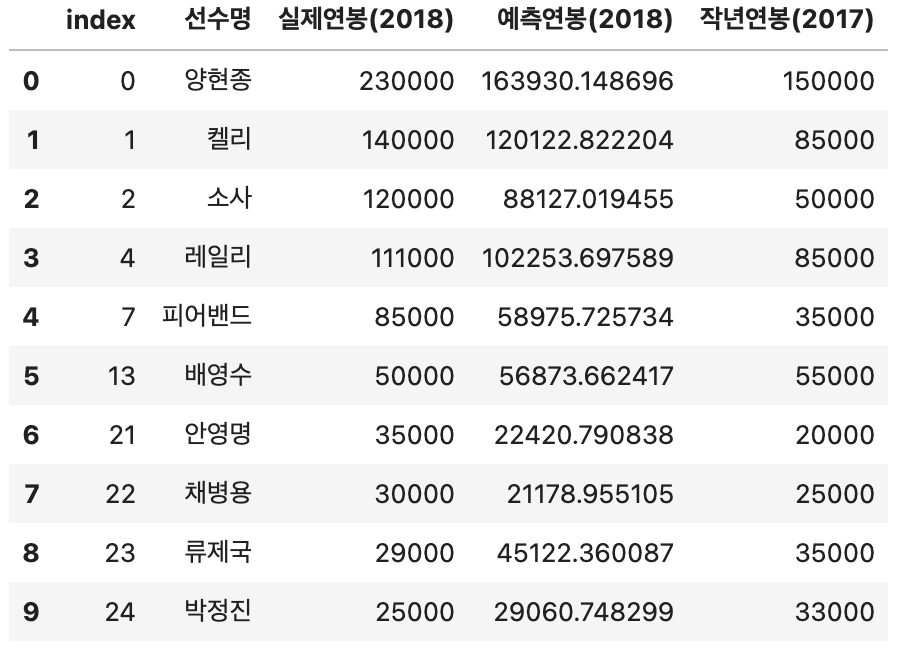
보기 더 쉽도록 그래프로 시각화를 하자.
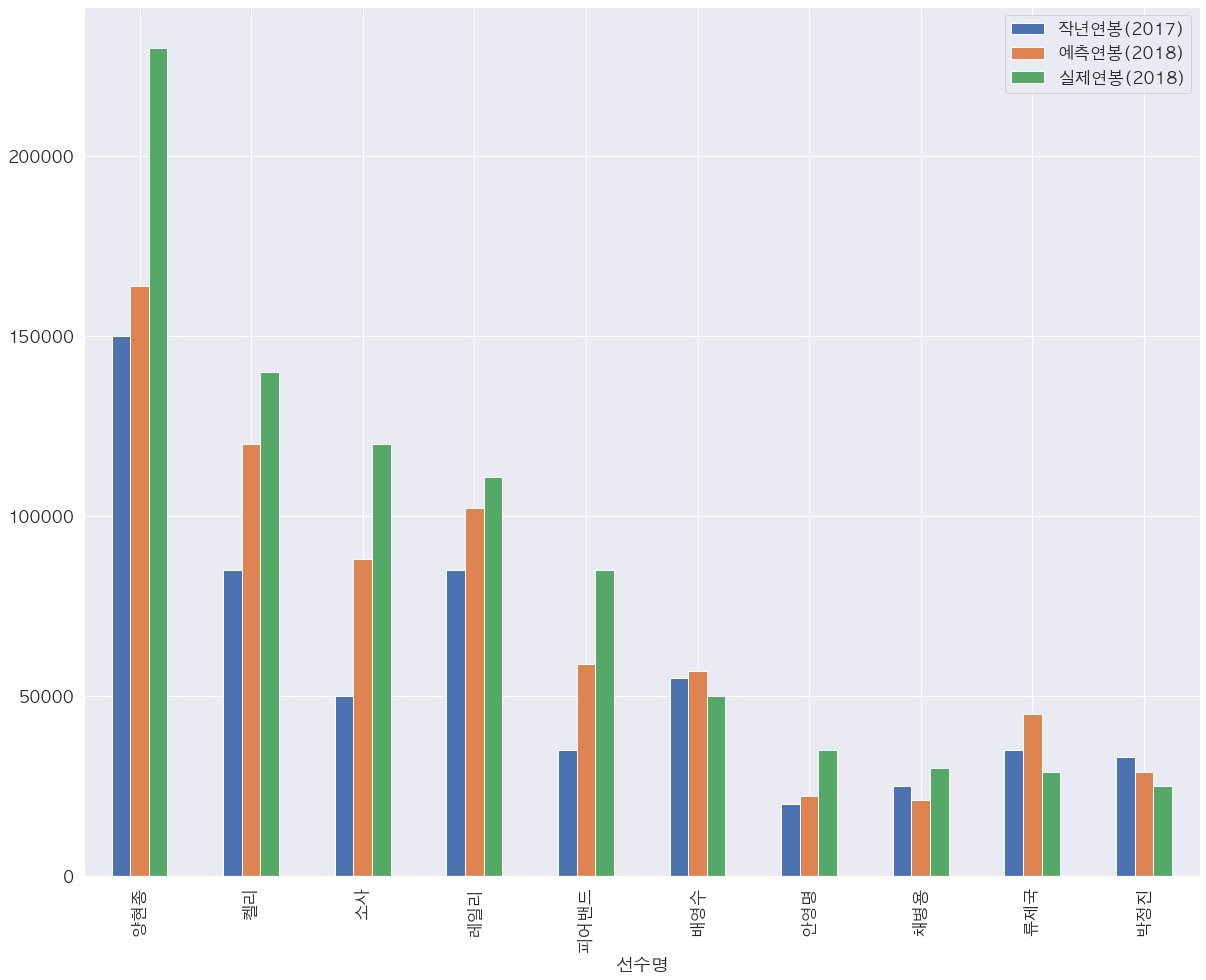
대 현 종. 데이터로는 예측할 수 없는 퍼포먼스를 보여주셨는지 더 많이 가져가 버리셨다. 다른 선수들도 예측보다는 조금 더 많은 연봉을 가져갔다. 아무래도 데이터에 없었던 또다른 어떤 피쳐가 영향을 줘서 조금의 오차가 생겼던 것 같다. 대충 예측값의 + 20000 ~ 30000 정도가 실제 연봉이면 나쁘지 않다고 할 수 있다.?
롯데 투수인 레일리도 예상보다 많은 연봉을 받아갔다. 더 많은 연봉을 받았으면 더 잘해야 했었는데 놀랍게도 2018년 KBO 롯데의 순위는...
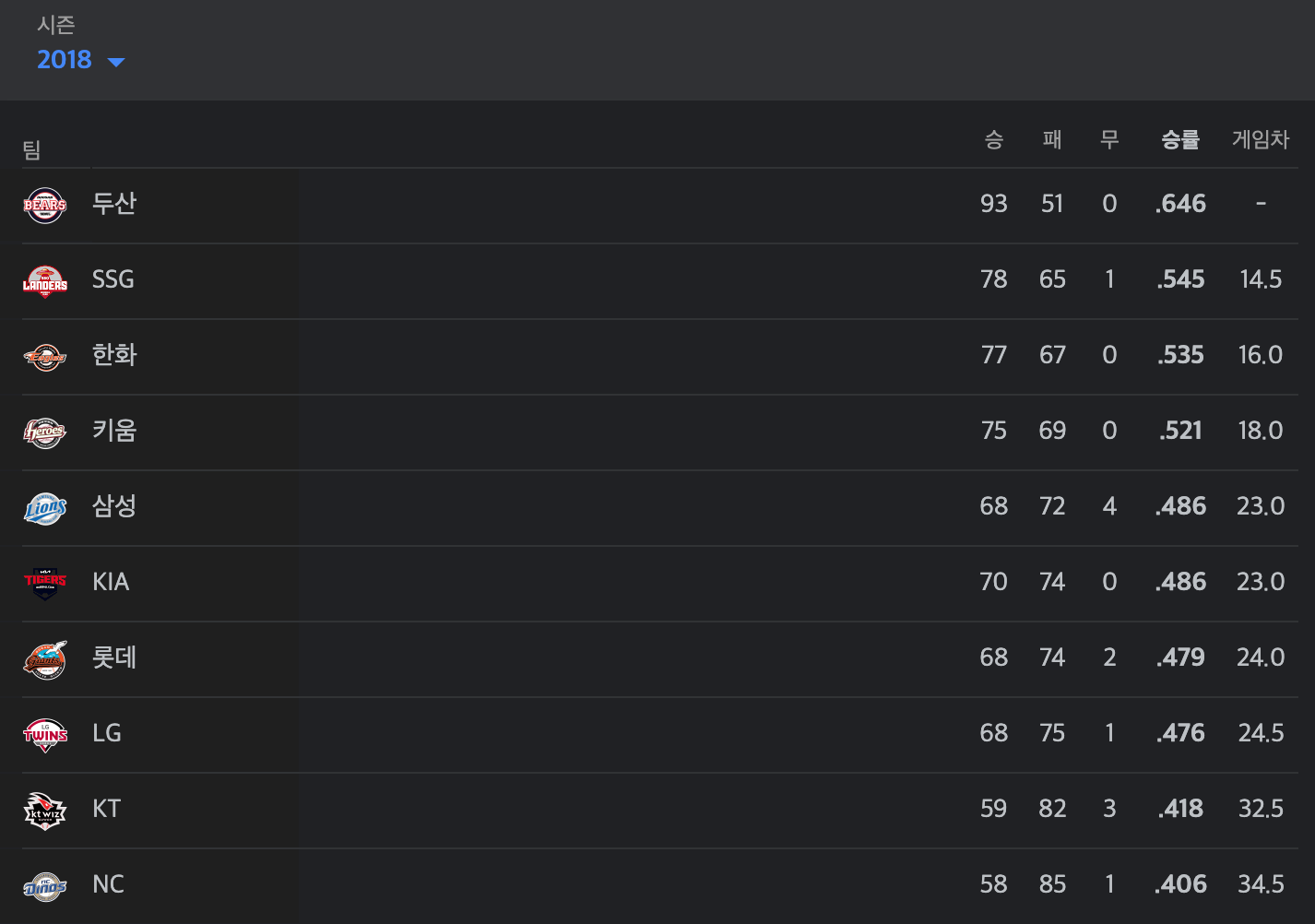
엄.

