
깊이 우선 탐색(DFS), 괄호 유효성 검사, 웹 브라우저 방문기록 등에 사용되는 stack에 대해서 간단히 정리 해보고 [Stack과 Queue를 비교 해보자 #1] 게시글에 내용과 비교 해볼 것이다.
📦 Stack
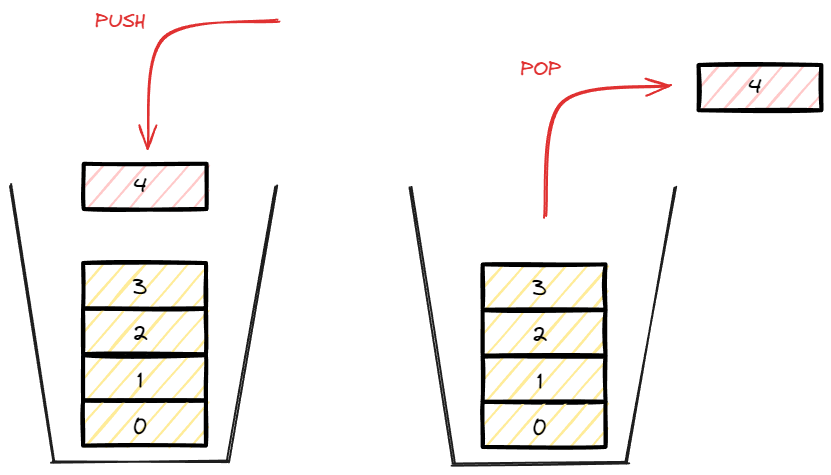
후입선출 LIFO(Last In First Out)의 형태를 가지는 자료구조 이며, 시간복잡도는 data를 push하는 경우, pop하는 경우 전부 O(1)이다.
가장 늦게 들어온 데이터가 top이 되며 top data가 가장 먼저 삭제 된다.
결국 시간 순서상 가장 최근에 추가한 데이터가 가장 먼저 나오는 형식으로 데이터를 저장하는 자료구조 이다.
stack은 queue보다 이해하기 편리하다 라고 생각한다.
📘 Stack으로 Queue구현
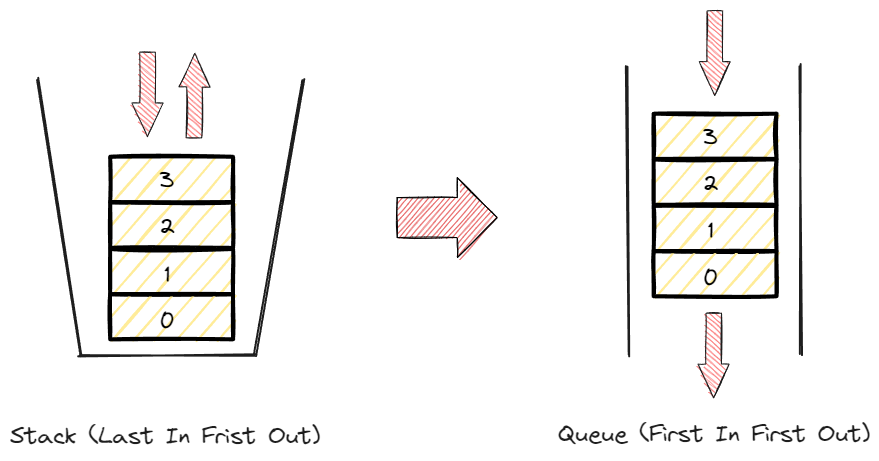
그렇다면 stack으로 queue를 구현하려면 어떻게 해야할까?
stack을 사용해서 queue를 구현 해보겠다.
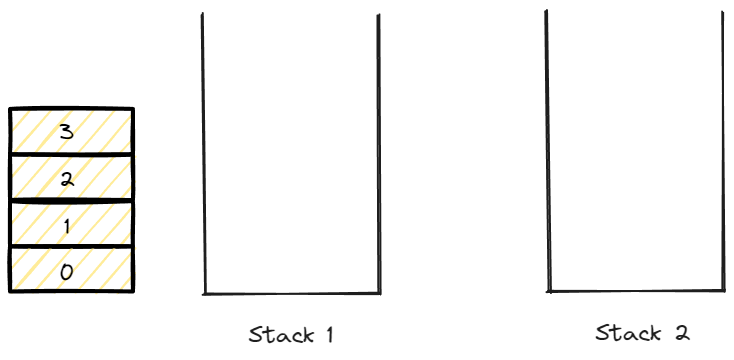
data가 0 ~ 3까지 있다고 가정했을때 데이터를 넣는 enqueue는 0부터 순서대로 넣어주면 된다.
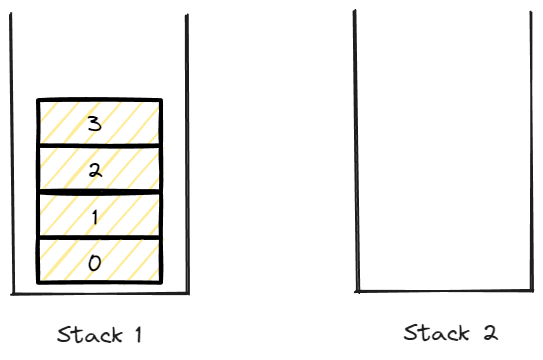
0부터 순서대로 stack 1에 넣어줬을 경우 그림이다.
그렇다면 넣어준 data를 dequeue하려면 queue의 성격에 따라 FIFO 즉 선입선출이 되어야 할 것이다.
그림과 같은 상황에서 dequeue를 하게 된다면?
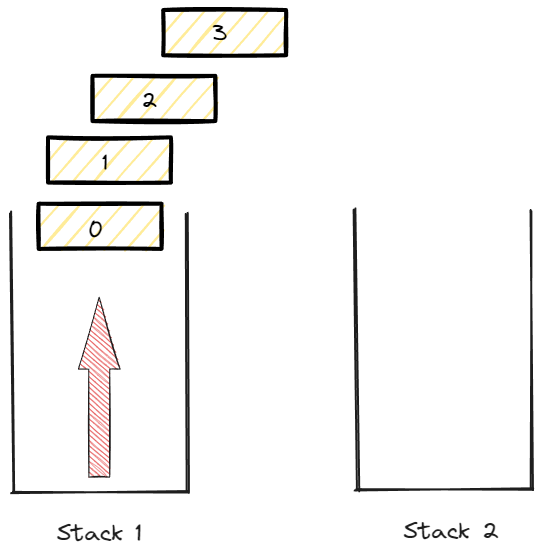
stack 1에서 data를 pop한다면 3 -> 2 -> 1 -> 0 순으로 데이터가 출력 될 것이다.
0 -> 1 -> 2 -> 3순서로 data를 넣어줬는데 역순으로 pop 된다면 의도와는 맞지 않는 결과이다.
이때 stack2에 반환된 데이터를 순서대로 저장한다.
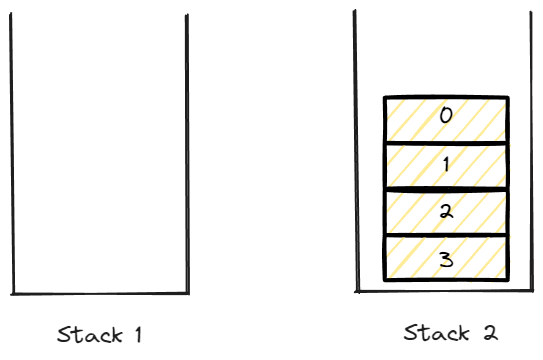
stack2에는 top이 0으로 저장 되어있을 것 이다.
stack2에 저장된 data를 pop한다면 data의 순서는 0 -> 1 -> 2 -> 3이 될 것이다.
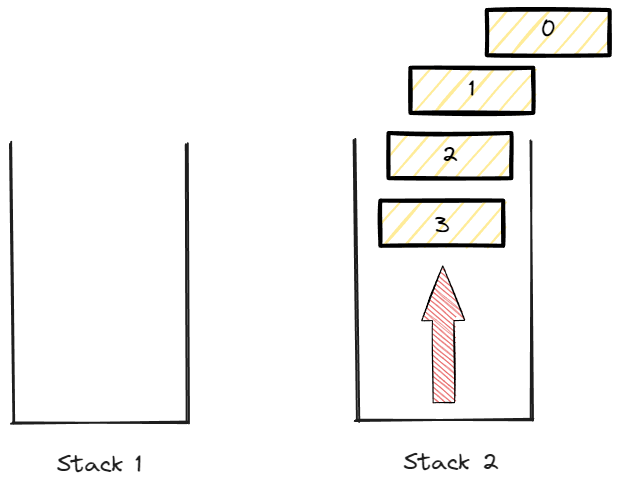
데이터 push와 pop할때의 순서가 동일하게 출력이 된다.
이는 queue의 FIFO의 특성을 띄며 의도와 같게 작동 하는 것이라고 볼 수 있다.
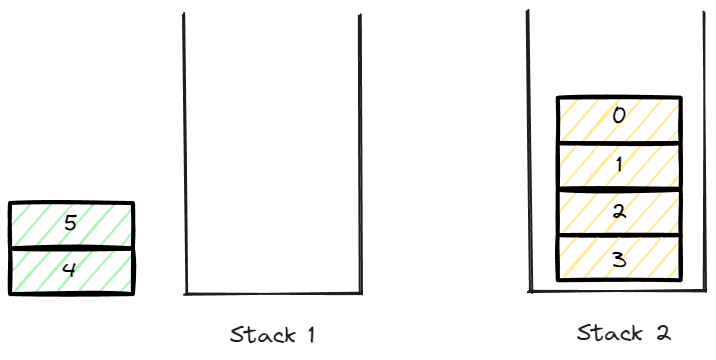
그렇다면 위와 같은 그림에서 새로운 데이터 4, 5가 Push된다고 가정해보자.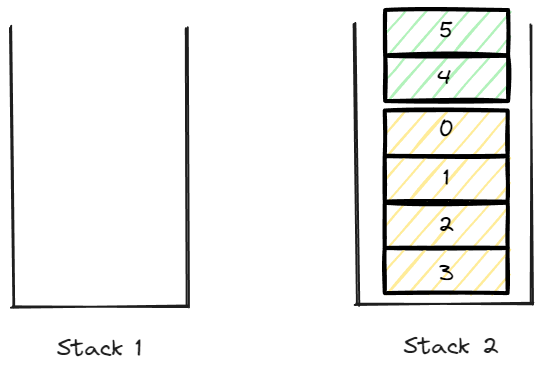
stack2에 data가 push된다면 pop했을때의 순번이 꼬이게 된다.
따라서 data의 push는 stack 1에서 이루어 져야 하고 pop는 stack 2에서 이루어 진다.
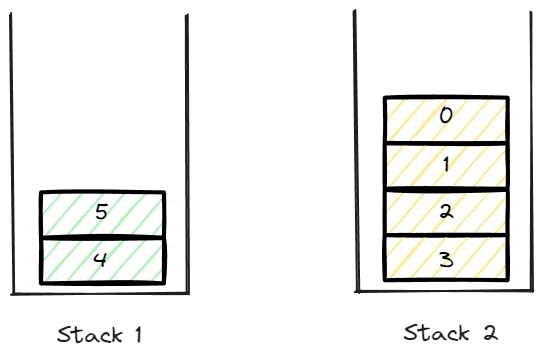
📌 data push이후 전체 데이터 pop
pop을 담당하는 stack을 확인 해야하며 여기서는 stack 2가 될 것이다.
stack2를 확인하고 만약 data가 존재한다면 먼저 stack 2를 비워준다.
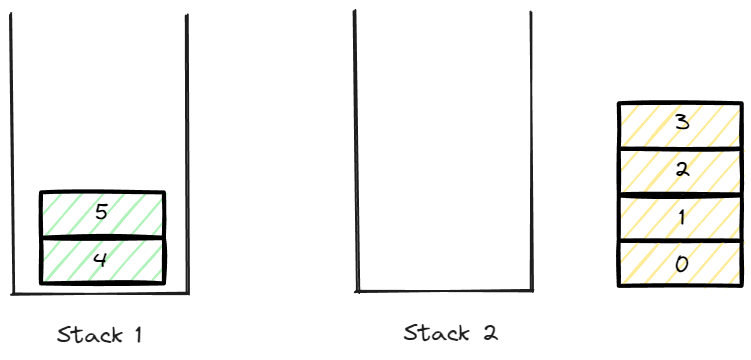
현재까지의 pop된 data는 0 ~ 3까지 일 것이다.
이후 push를 담당하는 data를 전부 pop하여 stack 2로 옮겨준다.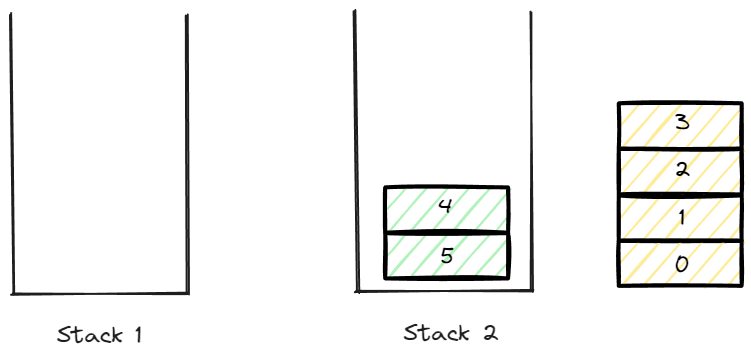
이후 stack2를 전부 pop하여 비워주면 0 ~ 5까지의 순번을 가진 데이터의 전체 반환이 완료 된다.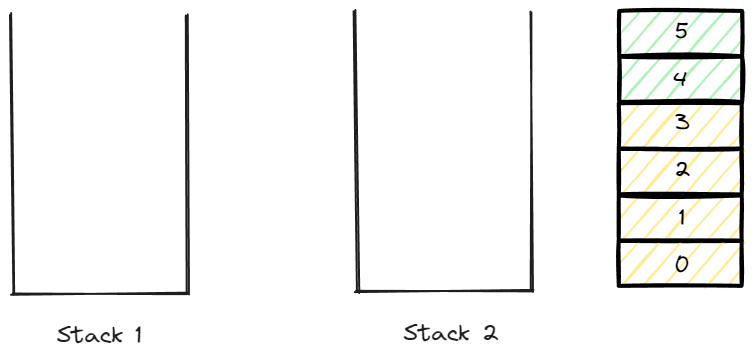
📘 Queue로 Stack구현
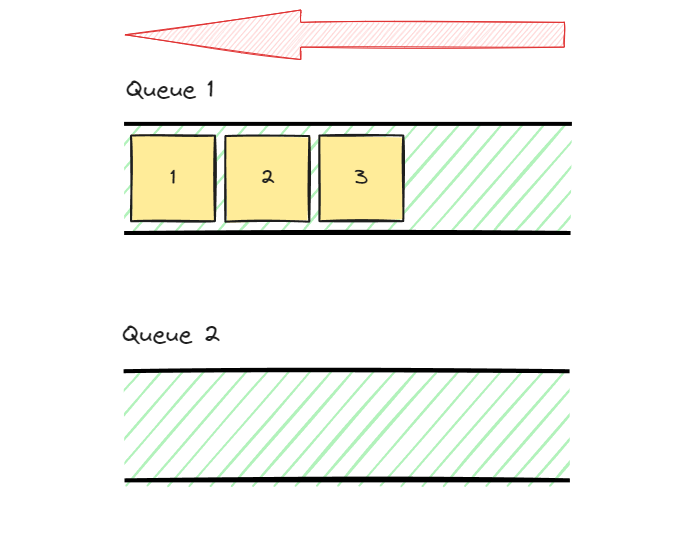
data가 1, 2, 3의 순서대로 enqueue되었다고 가정해보자.
이때 stack을 구현하려면 LIFO 즉 후입선출이 되어야 할 것이다.
하지만 queue 1에 enqueue되어있는 데이터를 차례로 dequeue한다면 FIFO 형태가 될 것이다.
따라서 마지막 data인 3을 우선적으로 dequeue해야 한다.
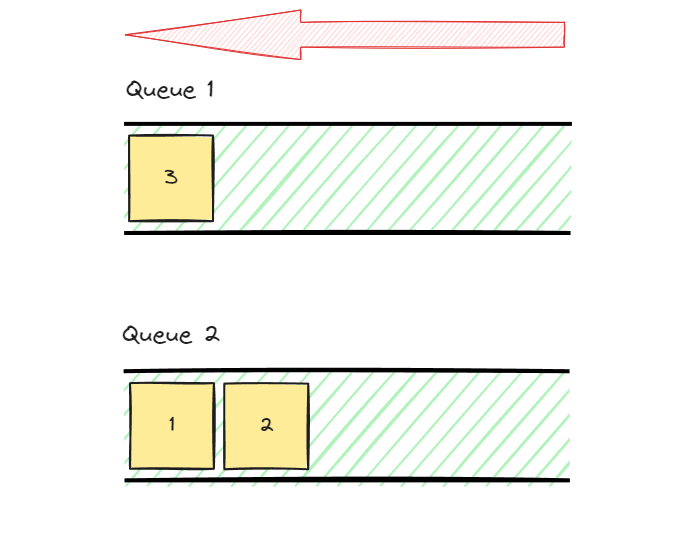
마지막 data인 3을 제외한 모든 data를 나머지 queue로 옮겨준다.
이후 queue 1에 있는 data를 출력한다.
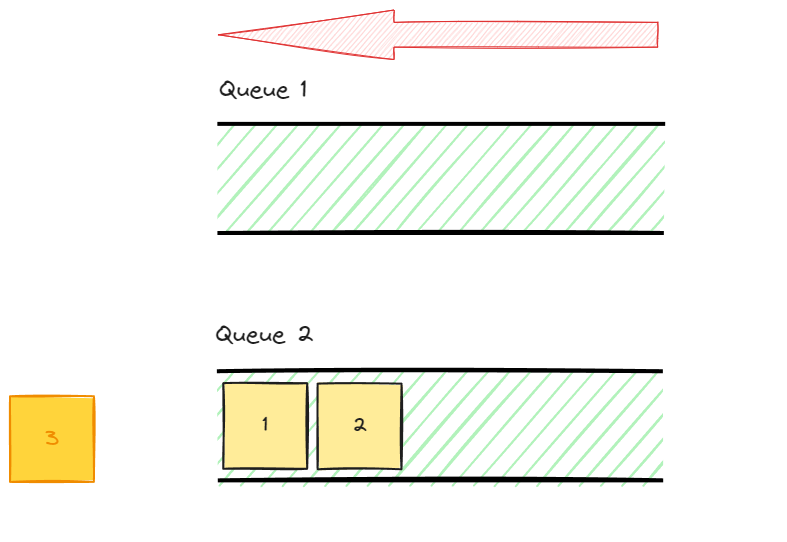
다음 data인 2를 출력해줘야 한다.
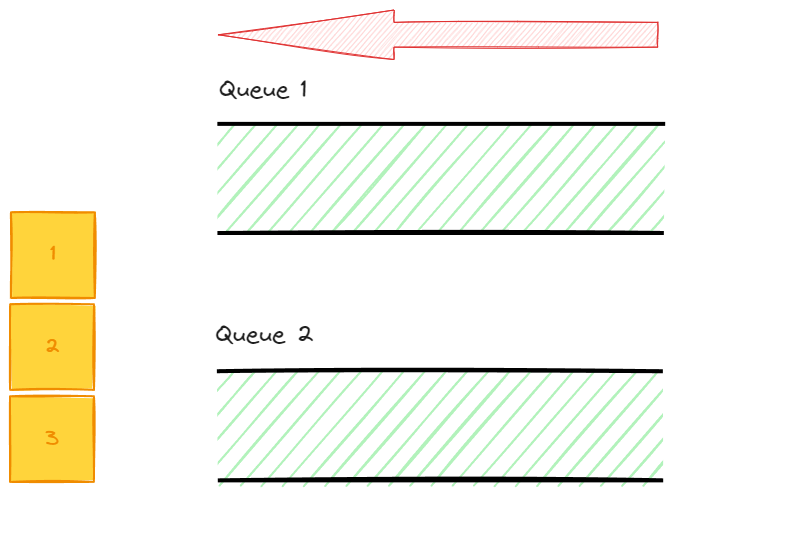
2를 출력해주기 위해서 앞선 모든 data를 나머지 queue에 옮겨준다.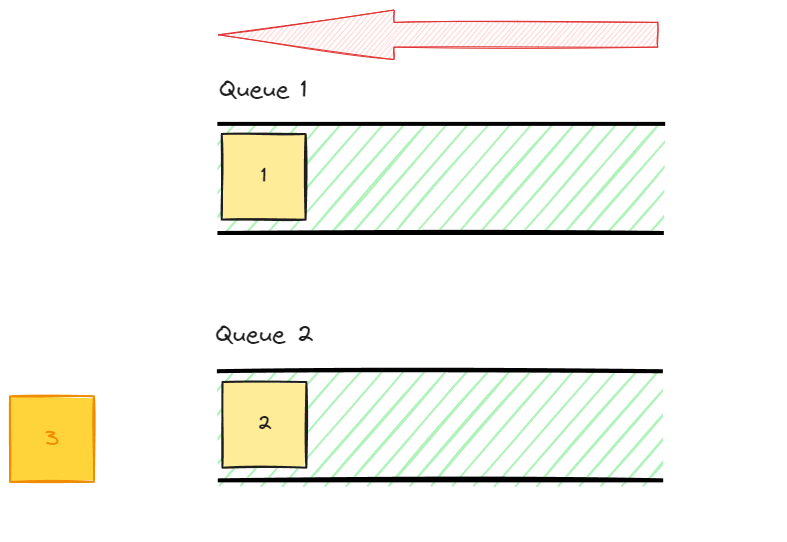
이후 옮겨지지 않은 data 2를 출력 해준다.
위와 같은 상황을 모든 data가 출력 될 때 까지 반복해서 실행하면 stack의 LIFO 즉 후입선출은 완료가 된다.
📗 정리
stack에 대한 간단한 정리와 stack을 이용한 queue구현, queue를 이용한 stack구현을 해보았다.
queue로 stack을 구현시에 모든 n - 1개의 data가 enqueue와 dequeue를 반복 해야 하기 때문에 O(n)의 시간복잡도를 갖게 될 것이다.
시간복잡도를 고려하지 않고 구현을 목적으로 진행 했기 때문에 성능이 좋지 않았다.
추가적인 성능 개선이 필요하다 생각 된다.
다음 게시글은 우선순위 큐에 대해 알아보려고 한다.
당시 가지고 있던 기술 개념으로 작성된 글 이므로 정확하지 않을 수 있으며 문제가 발견 된다면 수정 하겠습니다.
