
*1차 세미나 과제로 제출했던 내용을 공유하면 좋을 것 같아 포스트합니다 :)
SOLID 원칙
1️⃣ SRP 단일 책임 원칙 (Single Responsibility Principle)
하나의 클래스는 하나의 책임만 가져야 한다.
하나의 책임이라는 것은 문맥과 상황에 따라 다르므로, 변경이 있을 때 파급 효과를 적게 하는 것이 이 원칙의 핵심이다.
- 예제 [기본 과제]
파트원 정보를 클래스로 나타냈을 때, 멤버 구성 중 name(이름), dept(학과)는 고유 정보라고 할 수 있고 alcohol(주량)은 변경 가능성이 열려있다고 할 수 있다. 변화 요소로 예상되는 값에 대해, 변경이 필요한 순간에 항상 클래스를 수정해야 하는 부담이 발생할 수 있어 이를 분리하는 것이 좋다. SRP를 적용해보면 다음과 같이 수정할 수 있다.public class Member { private String name; private String dept; private double alcohol; }public class Member { private double alcohol; } class MemberSpec { private String name; private String dept; }
⇒ 각 클래스는 하나의 개념을 나타내야 하고, 각 개체 간 응집력이 있다면 병합을, 결합력이 있다면 분리를 하는 것이 순작용의 수단이 된다.
2️⃣ OCP 개방-폐쇄 원칙 (Open/Closed Principle)
소프트웨어 요소는 확장에는 열려 있으나, 변경에는 닫혀 있어야 한다.
추상화와 다형성 개념이 녹아 있는 원칙으로, 상위 클래스로 선언한 변수에 대해 하위 클래스로 변경 가능하게 열려 있어서는 안된다.
→ 객체지향의 장점을 극대화하는 중요한 원리 🌟
🔎 적용 방법-
변경(확장)될 것과 변하지 않을 것을 엄격히 구분한다.
*크기 조절에 실패하면 오히려 관계가 더 복잡해질 수 있으니 주의!
-
이 두 모듈이 만나는 지점에 인터페이스를 정의한다.
-
구현보다 정의한 인터페이스에 의존하도록 코드를 작성한다.
To 인터페이스..
인터페이스는 가능하면 변경되어서는 안 된다. ⇒ 인터페이스 설계 시 여러 경우의 수를 고려해야 하며, 적당한 추상화 레벨을 선택하는 것이 중요하다.
3️⃣ LSP 리스코프 치환 원칙 (Liskov Substitution Principle)
프로그램의 객체는 프로그램의 정확성을 깨트리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
구현체에서는 특정 기능에 대해서만 책임을 수행하고 동작해야 한다.
LSP는 규약을 준수하는 상속구조를 제공한다.
-
일반적으로 선언은 상위 클래스로, 생성은 하위 클래스를 사용하여 대입하는 방법이 좋다.
ex.
List<Member> memberList = new ArrayList<Member>();List 인터페이스 안에 ArrayList, LinkedList 등이 포함되며, 공통되는 메서드를 추출해놓고 실제 구현은 클래스 내에서 이루어진다. memberList는 List 타입으로 선언되어 있어, 필요에 따라 언제든지 ArrayList가 아닌 LinkedList로 변경가능하도록 열려 있다.
➡️ 자바의 컬렉션 프레임워크가 LSP의 적용 사례이다.
*이때 생성 시점에서 구체화한 하위 클래스를 노출시키지 않으려면 Abstract Factory 등의 패턴을 사용하여 유연성을 높일 수 있다.
📎 *Abstract Factory 패턴*서로 관련이 있는 객체들을 통째로 묶어서 Factory 클래스로 만들고, 이들을 조건에 따라 생성하도록 다시 Factory를 만들어서 객체를 생성하는 패턴
cf. Factory Method 패턴 - 조건에 따른 객체 생성을 Factory 클래스로 위임하여, Factory 클래스에서 객체를 생성하는 패턴
*Factory는 뭔데? 생성자 대신 객체를 생성해주는 코드의 도움을 받아 Bean 객체를 생성하는 것 → 즉, 자기자신이 Bean 객체로 사용되는 것이 아닌 대신 Bean 객체를 만들어주는 기능을 제공한다.
[디자인패턴] 추상 팩토리 패턴 ( Abstract Factory Pattern )
참고 자료 및 출처
-
상속을 통한 재사용은 상위 클래스와 하위 클래스 간에 IS-A 관계 있을 경우로 제한되어야 하고, 그 외는 합성을 이용한 재사용을 해야 한다.
-
하위 클래스가 상위 클래스와 클라이언트 간의 규약(인터페이스)를 어겨서는 안된다. FOR 다형성으로 인한 확장 효과를 얻기 위함
⇒ 결국 LSP는 OCP를 구성하는 구조가 된다.
🔎 적용 방법- 두 개체가 똑같은 일을 한다면? 둘을 하나의 클래스로 표현 + 이들을 구분할 수 있는 필드 추가
- 똑같은 연산을 제공하지만, 이들을 약간씩 다르게 한다면 공통의 인터페이스를 만들고 이를 상속(implements)하도록 하여 각각에서 구현한다.
- 공통된 연산이 없다면? 완전 별개의 클래스로 둔다.
- 만약 두 개체가 하는 일에 추가적으로 무언가를 더 한다면, 이들을 상속받은 구현 클래스를 사용한다.
4️⃣ ISP 인터페이스 분리 원칙 (Interface Segregation Principle)
클라이언트가 자신이 이용하지 않는 메서드에 의존하지 않아야 한다.
범용 인터페이스로 하나 존재하는 것보다 각각의 목적에 대한 인터페이스로 여러 개 존재하는 것이 더 좋다. 작은 단위로 분리할수록 내부 의존성을 약화시켜 리팩토링, 수정, 재배포를 쉽게 한다.
*SRP가 클래스의 단일책임을 강조한다면, ISP는 인터페이스의 단일책임을 강조한다. ISP는 SRP와 달리 클래스/인터페이스가 여러 책임을 갖는 것을 인정하지만, 인터페이스를 분리시키는 방식으로 SRP와 같은 목표에 도달한다고 볼 수 있다.
🔎 인터페이스를 분리하는 방법- 클래스의 상속을 이용하여 인터페이스 분리하기
- 객체 인터페이스를 통한 분리
5️⃣ DIP 의존관계 역전 원칙 (Dependency Inversion Principle)
프로그래머는 구체화가 아닌, 추상화에 의존해야 한다.
→ 의존성 주입은 이 원칙을 따르는 방법 중 하나!
DIP의 키워드 - #IoC, #훅 메서드, #확장성
🔎 *훅(hook) 메서드란?*상위 클래스에서 디폴트 기능을 정의해두거나 비워두었다가 하위 클래스에서 선택적으로 오버라이드할 수 있게 만들어둔 메서드
⇒ 추상 클래스의 멤버 중 추상 메서드가 아닌 이외 메서드가 훅 메서드에 해당한다.
리터럴 (Literal)
프로그램에서 직접 표현한 데이터 그 자체를 의미
정수형(int, long), 실수형(float, double), 문자열(String), 문자형(char), 논리형(boolean)의 타입을 가질 수 있다.
⇒ 기본적으로 변수의 타입 = 리터럴의 타입이 성립해야 한다!
*이때 小(리터럴) → 大(변수/상수)는 가능하지만 大(리터럴) → 小(변수/상수)는 불가능하다.
*️⃣ 변수, 상수와는 무슨 관계?
변수와 상수 모두 하나의 값을 저장하기 위한 메모리 공간의 이름을 의미한다. 이들의 차이점은 값의 재할당이 가능한지 여부이다. 상수는 변수 타입 앞에 final 키워드를 붙여서 사용하며, 값이 반드시 존재해야 하므로 선언과 동시에 초기화 해야 하고, 그 값은 변경이 불가능하다.
리터럴은 변수와 상수를 초기화할 때의 그 값 자체를 의미한다.
String name = "GO SOPT"; // "GO SOPT"는 리터럴
final int num = 32; // 32는 리터럴상수를 사용하는 이유는 리터럴에 의미 있는 이름을 지어주기 위함*이다. ⇒ 코드의 유지보수성을 높일 수 있다!
this, this() / super, super()
this는 자기자신, super은 부모를 가리키는 레퍼런스로 쓰인다. super로 메소드를 호출하면 정적 바인딩(컴파일 시간에 결정)을 실행하여 오버라이딩한 메소드가 있어도 부모 클래스의 멤버에 접근할 수 있다.
*this, super는 static 메소드에서 사용할 수 없다. 또한, 상속을 받더라도 오버라이딩과 오버로딩이 불가능하다.
this.객체 내의 멤버
super.객체 내의 부모클래스의 멤버반면에 this()와 super()은 함수, 즉 생성자(메소드)를 호출할 때 사용된다. this()는 자기 자신을 초기화하고 생성자에서 다른 생성자를 호출할 때 사용하고, super()는 부모의 속성을 생성할 때, 즉 자식 클래스의 생성자에서 부모 클래스의 생성자를 호출할 때 사용한다.
this, this(), super, super() 예제 [기본 과제]
this()를 사용하면 자기 자신의 생성자를 호출할 수 있다.// default constructor public Plan() { name = Part.PREFIX + " " + "Plan-part"; memberList = new ArrayList<Member>(); partLeader = new Leader("기팟장", 20, "컴공", "OB", 1); memberList.add(partLeader); } public Plan(String name) { this(); // default constructor 호출 -> this()에 파라미터를 따로 넘겨주지 않았으므로! this.name = name; }super()로 부모 클래스 생성자에서의 동작을 그대로 가져올 수 있다.// Leader(자식 클래스) -> Member(부모 클래스) public Member(String name, int age, String dept, String activityType, double alcohol) { this.name = name; // this.name 을 name으로 써도 무방하지만, 명확한 이해를 위해 this로 매개변수와 다름을 명시해주는 것이 좋다. this.age = age; this.dept = dept; this.activityType = ActivityType.valueOf(activityType); this.alcohol = alcohol; } public Leader(String name, int age, String dept, String activityType, double alcohol) { super(name, age, dept, activityType, alcohol); // 위의 Member 생성자가 호출된다. (파라미터도 그대로 넘겨줘야 함) role = "서팟장"; }super로 자식 클래스인 Leader에서 부모 클래스인 Member의 메서드를 호출할 수 있다.@Override public double getAlcohol() { if (super.getAlcohol() <= 3) { double realAlcohol = 4.5; setAlcohol(realAlcohol); return realAlcohol; } return super.getAlcohol(); }
정리
| this() | this |
|---|---|
| 객체 내 생성자에서 다른 생성자를 호출할 때 사용 | 현재 클래스의 인스턴스, 특정 필드를 지정할 때 사용(매개변수와 객체 자신을 구분하기 위함) |
| super() | super |
|---|---|
| 부모 클래스의 생성자를 호출할 때 사용기본적으로 자식 클래스의 생성자에 추가되어 사용 | 부모 클래스의 멤버 변수나 메소드를 사용하기 위해 변수를 호출할 때 사용 ⇒ “정적 바인딩 ” |
final, static, static final
static
static 멤버는 동일 클래스 내의 모든 객체들이 공유하는 멤버로, main()이 실행되기 전에 이미 생성이 되어 객체 생성과는 무관하게 사용이 가능하며, 클래스 당 하나만 생성할 수 있다.
즉, static으로 선언된 멤버(필드, 메소드)는 전역 변수와 같이 메모리 주소가 고정되어 사용되며, 별도의 객체 생성이 필요없이 클래스명.멤버 와 같이 해당 클래스명으로 바로 접근이 가능하다. → 전역 변수와 같은 메모리 공간에 할당
-
Java 메모리 구조
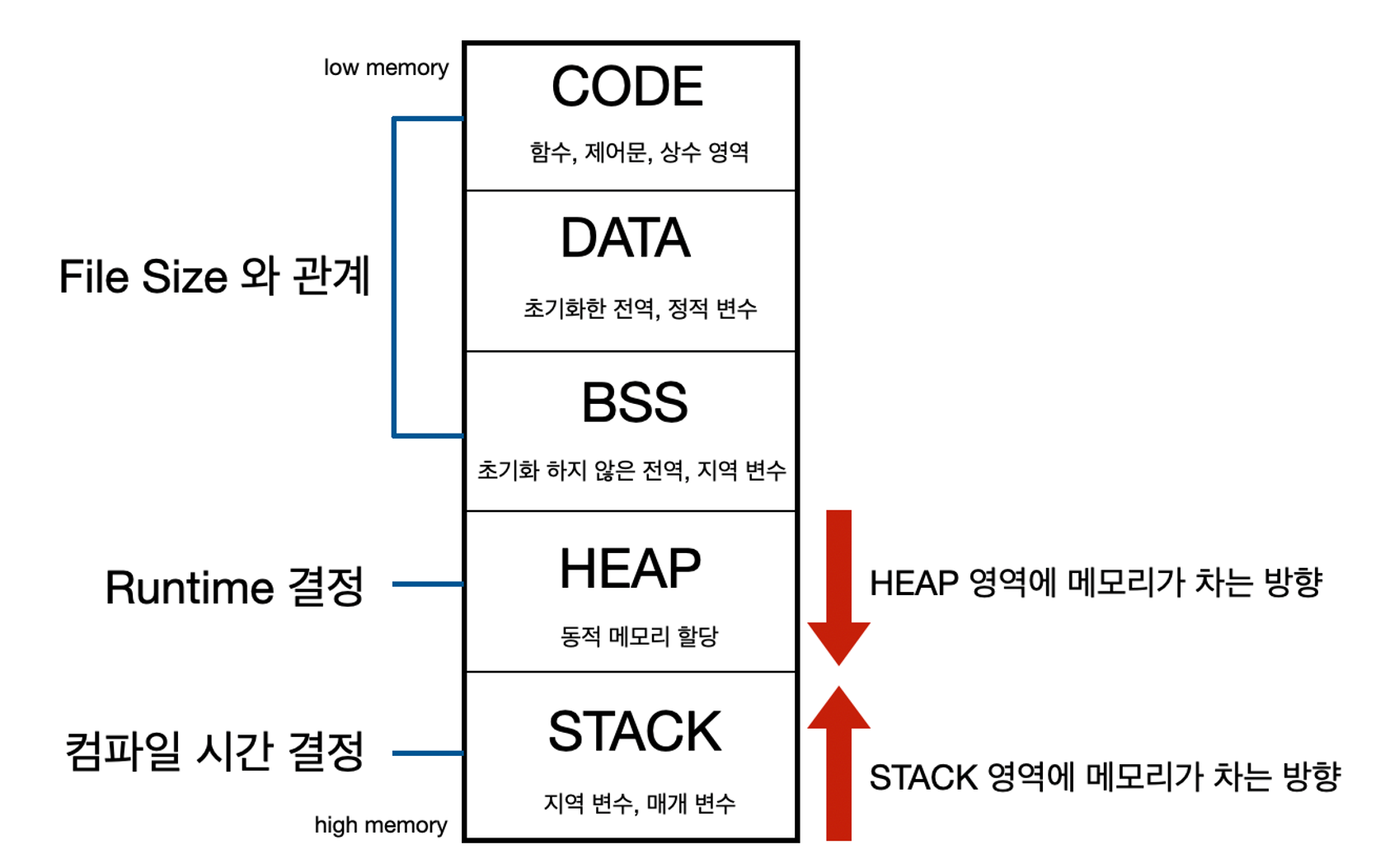
Code 영역 프로그램의 코드(명령어) 저장 → CPU는 이 명령어를 한 줄씩 읽으며 수행한다. Data 영역 전역변수와 정적(static)변수 저장 (Class는 여기에 저장) → 프로그램의 시작~종료 Stack 영역 지역변수와 매개변수 저장 → 함수의 호출(시작)~끝 Heap 영역 new로 생성한 객체 → 사용자에 의해 동적으로 할당~해제
*️⃣ non-static VS static

final
| 종류 | 기능 |
|---|---|
| final 클래스 | final로 선언된 클래스는 상속 자체가 불가능하다. ⇒ super를 써도 아무 영향을 주지 못한다. |
| final 메소드 | final을 메소드명 앞에 작성하면 오버라이딩할 수 없는 메소드임을 나타내고, 클래스 상속 시 반드시 메소드에 정의된 대로만 사용이 가능하다. |
| final 필드 | 상수로 취급된다. 한 번 초기화되면 값을 변경할 수 없는 것이다. public static final 변수명 = 값; 으로 선언하면 해당 변수는 프로그램 전체에서 사용할 수 있는 전역 변수처럼 인식된다. |
⇒ final 키워드는 사용되는 곳에 따라 의미가 달라지는데, 공통적으로 한 번 정해지면 변경이 불가능하도록 무언가를 제한하는 의미를 가진다.
static final
그럼 두 개를 합친 static final은 ..?
static (클래스 변수) + final (필드) ➡️ 객체(인스턴스)가 아닌 클래스에 존재하는 단 하나의 상수
ex. public static final String PREFIX = "GO SOPT"; [기본 과제]
인터페이스는 상수와 추상 메서드로만 이루어질 수 있다. Server 클래스와 Part 클래스에서 모두 implements 하는 Part 인터페이스에 공통으로 사용되는 상수를 static final로 선언하였다.
extends, implements

extends
상위 객체를 그대로 사용
부모의 특징을 연장해서 사용한다!
부모 클래스에서의 선언/정의를 그대로 가져와서 사용이 가능하고, 다형성 특성에 따라 자식 클래스에서는 원하는 부분만 오버라이딩하여 입맛대로 구현하면 된다.
implements
상위 객체를 새롭게 구현
부모의 특징을 도구로 사용해 새로운 특징을 만들어 사용한다!
부모는 선언만 하며, 자식이 오버라이딩하여 사용한다. 이는 구현의 강제성을 부여하는 것으로도 볼 수 있다.
- 예제 [기본 과제]
Part 인터페이스의 추상 메서드는 Server 클래스와 Plan 클래스에서 각각 필수로 구현해야 한다.public interface Part { /** * 인터페이스의 메소드는 public abstract final 로만 선언 가능(생략 OK) * *생략이 가능하여 아래 3가지 모두 가능한 표현이다. */ public abstract void participate(); public void study(); void communicate(); } // Server와 Plan 클래스 모두 아래 3개의 메서드를 구현해야만 한다. public class Server implements Part { @Override public void participate() { } @Override public void study() { } @Override public void communicate() { } }
abstract
extends와 implements가 가진 의미를 혼합한 개념으로, abstract로 정의된 메서드를 하나라도 가지면 추상 클래스라고 한다. 이는 부모의 특징을 연장해서 사용하는 동시에 몇 개는 새롭게 만들어 사용하는 것으로 생각하면 된다.
*️⃣ 추상 클래스와 인터페이스의 차이는?
| 추상 클래스 | 인터페이스 | |
|---|---|---|
| 사용 키워드 | abstract | interface |
| 사용 가능 변수 | 제한 X | static final(상수) |
| 사용 가능 접근 제어자 | 제한 X (public, private, protected, default) | public |
| 사용 가능 메서드 | 제한 X | abstract method, default method, static method, private method |
| 상속 키워드 | extends | implements |
| 다중상속 가능 여부 | 불가능 | 가능 |
- 클래스에 다중 구현
- 인터페이스끼리 다중 상속 |
인터페이스를 극단적인 추상 클래스로 볼 수 있지만, 이를 굳이 구분하는 이유는 다음과 같다.
-
사용 의도
클래스 상속의 기본은 의미있는 연관 관계를 구축하고자 함에 있다. 즉, 구현의 강제화 외에 추상 클래스의 목적에는 클래스 간 명확한 계층 구조를 필요로 한다는 점에서도 찾을 수 있다.
- IS-A 관계 (”~이다”) ✅ 상속 일반적인 개념 - 구체적인 개념의 관계로, 자식 클래스가 부모 클래스에 종속되는 관계에서만 사용하는 것이 좋다. ex. 사과는 과일이다. 강아지는 동물이다.
- HAS-A 관계 (”~을 할 수 있는”) 일반적인 포함 개념의 관계로, 다른 클래스의 기능(멤버)을 받아들여 사용한다. ex. 차는 엔진을 가지고 있다.
인터페이스는 상속에 구애 받지 않는 상속이 가능하다는 특징이 있다. 타입끼리 묶이는 것이 자유로워 서로 논리적이지 않고 관련이 적은 클래스끼리 부모-자식의 관계가 아닌, 형제 관계처럼 묶을 수 있다. 즉, 인터페이스를 사용하는 이유는 자유로운 타임 묶음을 통한 추상화를 이루는 것에 있다!
- IS-A 관계 (”~이다”) ✅ 상속 일반적인 개념 - 구체적인 개념의 관계로, 자식 클래스가 부모 클래스에 종속되는 관계에서만 사용하는 것이 좋다. ex. 사과는 과일이다. 강아지는 동물이다.
-
공통 기능 사용 여부
모든 클래스가 인터페이스로만 구현이 가능하다면, 같은 기능을 하는 여러 클래스에 똑같은 코드를 반복해서 작성하는 번거로움이 따를 것이다. 공통된 기능을 가진 메서드나 멤버가 있는 경우에는 추상 클래스를 이용하여 일반 메서드로 구현한 후, 구현의 의무를 부여할 메서드만 abstract로 선언해주면 된다.
*참고 자료 - https://inpa.tistory.com/entry/JAVA-☕-인터페이스-vs-추상클래스-차이점-완벽-이해하기
자바의 원시 타입, 참조 타입
원시 타입(Primitive Type)
정수, 실수, 문자, 논리 리터럴 등의 실제 데이터 값을 저장하는 타입
→ 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double)
- 스택 영역에 저장된다.
참조 타입(Reference Type)
메모리 주소 값을 통해 객체를 참조하는 타입 (=하나의 인스턴스)
→ 원시 타입을 제외한 모든 타입 (문자열, 배열, 열거형, 클래스, 인터페이스 등)
- new로 생성한 객체는 힙 영역에 저장되며, 이들을 참조할 수 있는 변수는 스택 영역에 주소로 저장된다.
-
Null 포함 가능 여부
원시타입은 null을 담을 수 없다. 반드시 리터럴이 저장되어야 하는 타입이다. 반면, 참조타입은
Integer num = null;과 같은 선언이 가능하다. -
제너릭 타입에서 사용 가능 여부
참조타입만 가능!
List<int> list는 불가능하지만,List<Integer> list는 가능한 것이 대표적인 예시이다. -
참조 타입은 사용하는 메모리 양이 많다!
스택 영역만 사용하는 원시타입과 달리, 참조타입은 참조 값은 스택 영역에, 실제 값은 힙 영역에 존재하여 값을 필요로 할 때마다 거쳐서 가는 과정이 따른다.
*원시 타입보다 참조 타입이 사용하는 메모리 양이 압도적으로 높은 것을 볼 수 있다.

원시 타입보다 참조 타입이 사용하는 메모리 양이 압도적으로 높은 것을 볼 수 있다.
Spring의 4가지 특징
1. POJO 프로그래밍 지향 (Plane Old Java Object)
본래 자바의 장점을 살리는 순수 자바로만 이루어진 객체를 만드는 것을 지향한다.
자바 코드가 특정 기술과 환경에 종속되어 의존하게 되면서, 안정성과 확장성이 떨어지는 단점이 있었다. 이에 자바가 가진 객체지향적 설계의 장점들을 살리기 위한 POJO 개념이 등장하였다.
by 토비의 스프링 “진정한 POJO란 객체지향적인 원리에 충실하면서, 환경과 기술에 종속되지 않고 필요에 따라 재활용될 수 있는 방식으로 설계된 오브젝트를 말한다.”
💡 POJO에 기반하는 Spring의 특징- 특정 인터페이스를 구현하거나, 클래스를 상속하지 않는 일반 자바 객체 지원
- 스프링 컨테이너에 저장되는 자바 객체는 특정 인터페이스, 클래스의 상속 없이 사용 가능
2. IoC / DI (Inversion of Control & Dependency Injection)
-
IoC
제어의 역전이라는 의미로, 메서드나 객체의 호출 작업을 개발자가 아닌 외부에서 결정되는 것을 의미한다.
객체의 의존성을 역전시켜 객체 간의 결합도를 줄이고, 유연한 코드를 작성할 수 있게 하여 가독성 및 코드 중복, 유지보수를 편하게 할 수 있게 한다.
📍 “제어의 흐름을 바꾼다.”
기존에는 ①객체 생성 → ②의존성 객체 생성 → ③의존성 객체 메서드 호출 의 순서로 객체를 만들고 실행한다면?
IN 스프링, ①객체 생성 → ②의존성 객체 주입 (제어권을 스프링에 위임하여 스프링이 만들어놓은 객체를 주입 *직접 만들 필요X) → ③의존성 객체 메서드 호출 의 순서로 실행된다.스프링이 모든 의존성 객체에 대해 실행 시에 만들어주고 필요한 곳에 주입시켜줌으로써, 기본적으로 싱글톤 패턴으로 동작하는 Bean들의 작업이 스프링에 의해 처리될 수 있다.
*싱글톤 패턴이란? 클래스의 인스턴스가 딱 한 개만 생성되는 것을 보장하는 디자인 패턴
-
DI
객체를 직접 생성하지 않고, 외부에서 생성하여 주입 시켜주는 방식이다. 즉, 클래스 간의 의존성을 스프링이 자동으로 연결해준다!
스프링은 DI라는 방식으로 모듈 간의 결합도를 낮춰준다. 이는 IoC 컨테이너가 Bean 객체를 대신 생성하여 의존성을 주입해주는 스프링의 동작 원리 덕분인데, 개발자는 그럼 무얼 해야하는가?
-
Bean 클래스 작성
-
주입을 위한
📍 의존성이란?xml 파일 기술또는@어노테이션 사용을 이용한 설정public class Server { private Leader partLeader; public Server() { partLeader = new Leader(); } }위와 같이 구성된 Server 클래스는 Leader 클래스의 메서드를 호출하고자 할 때 “Server 클래스가 Leader 클래스에 의존성을 가지고 있다(의존하고 있다)” 고 한다.
이렇게 생성자 내에서 객체를 직접 생성해버리면 유지보수가 매우 어려워진다. 이는 의존성을 주입하지 않는 경우라고 볼 수 있다!
그렇다면.. 의존성을 주입하는 방식으로는 무엇이 있을까?
-
생성자 주입
public class Server { private Leader partLeader; public Server(Leader leader) { this.partLeader = leader; } } -
setter 주입
public void setPartLeader(Leader leader) { this.partLeader = leader; }이와 같은 방식을 사용하면, 한 클래스를 수정할 때 다른 클래스까지 수정하지 않아도 된다는 장점이 있다. 즉, 의존성을 주입하지 않았을 때보다 코드의 수정이 용이하다.
-
@Autowired ✅ Spring 사용
→ 변수, 생성자, setter 메서드, 일반 메서드 등에 적용 가능
스프링에서 Bean 인스턴스가 생성된 이후,
@Autowired로 설정된 메서드가 자동으로 호출되고, 인스턴스가 자동으로 주입된다. 즉, 스프링이 관리하는 Bean을 해당 변수와 메서드에 자동으로 매핑해주는 역할을 한다.
-
3. AOP (Aspect Oriented Programming)
📍 스프링 AOP가 사용하는 방법 : 프록시 패턴관점 지향 프로그래밍. 어떤 로직을 기준으로 Aspect(핵심적인 관점, 부가적인 관점)를 분리하고 그 관점을 기준으로 각각 모듈화하여 객체지향의 가치를 지킬 수 있도록 도와준다.
공통 모듈을 프록시로 만들어 DI로 연결된 Bean들 사이에 적용한다. → Aspect(모듈화)가 적용된 Target의 메서드 호출 과정에 참여하여 공통 모듈을 제공해주는 방식이다.
독립적으로 개발한 부가기능 모듈을 다양한 Target 객체의 메서드에 동적으로 적용할 수 있도록 하는 것이 프록시이고, 스프링 AOP는 이 프록시 방식의 AOP라고 할 수 있다.
4. PSA (Portable Service Abstraction)
어느 환경이든 복잡한 기술을 추상화하여 사용할 수 있다.
환경의 변화와 세부 기술의 변경과 관계없이, 일관된 방식으로 기술에 접근할 수 있게 해주는 설계 원칙으로, 복잡한 기술을 내부에 숨기고 개발자에게 편의성을 제공하고자 하는 목적에 있다.
스프링에서 DB에 접근할 때, Jdbc를 통해 접근할 수도 있고, ORM 기술을 사용하고자 한다면 표준 인터페이스로 정해둔 ‘JPA’를 바탕으로 구현하여 접근할 수도 있다.
→ 이때 어떤 방식으로 구현하든 트랜잭션 기능을 이용하기 위해 @Transactional 어노테이션을 사용하는 것에는 변함이 없다.
Spring의 동작과정
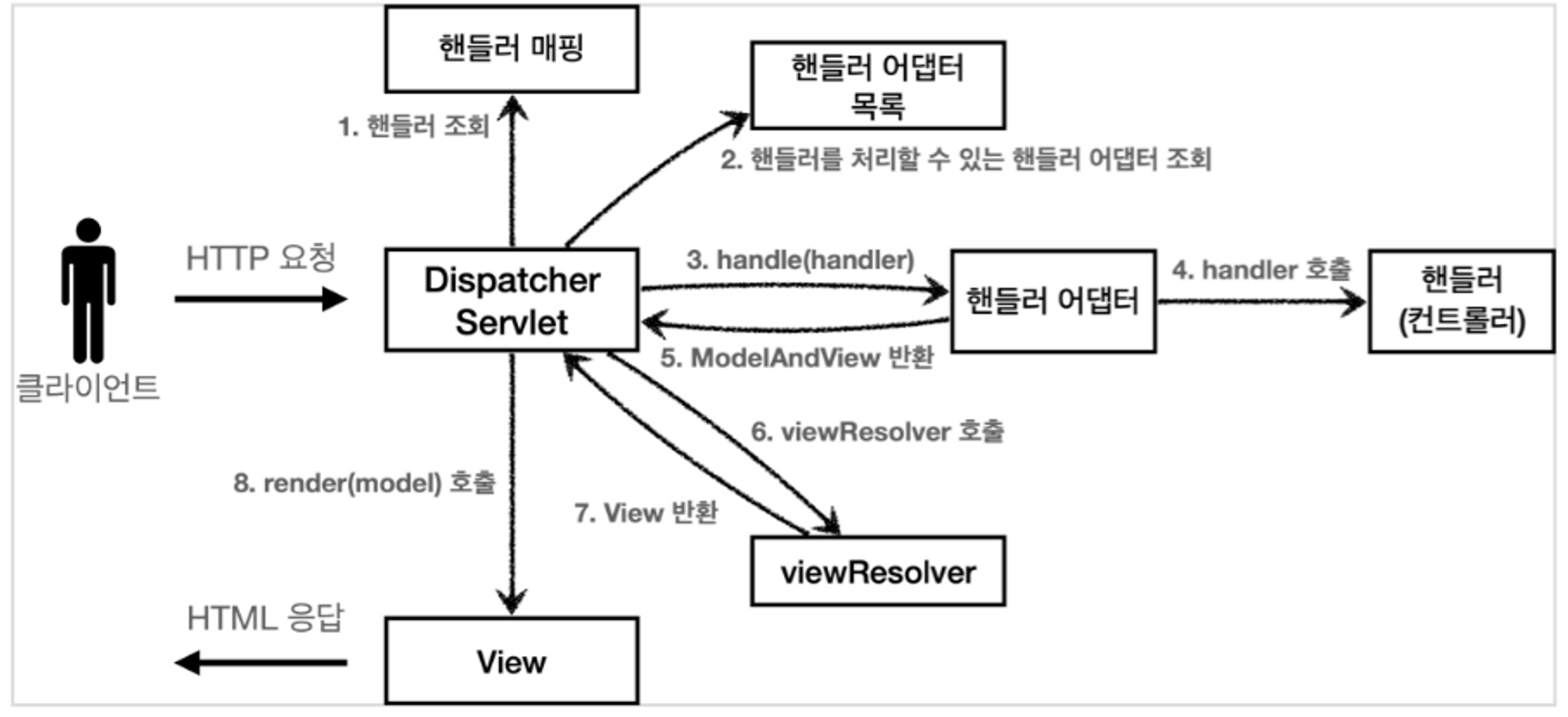
0. HTTP 요청
DispatcherServlet이 모든 웹 브라우저로부터의 요청을 받는다.
*DispatcherServlet은 가장 앞단의 FrontController 역할을 하며 가장 핵심적인 역할을 한다.
1. 핸들러 조회
DispatcherServlet은 요청된 URL을 HandlerMapping 객체로 넘기고, 주어진 request를 처리할 수 있는 Handler객체를 가져온다.
→ 이때 Handler 객체는 호출해야 할 Controller 메소드 정보를 가지고 있다.
2. 핸들러 어댑터 조회
가져온 Handler 객체를 실행시킬 수 있는 HandlerAdapter 객체를 가져온다.
*만약 해당 Controller를 처리할 Handler 객체에 적용할 interceptor가 존재한다면 모든 interceptor 객체의 preHandle 메서드를 호출한다.
3. 핸들러 어댑터 실행
HandlerAdapter 객체를 실행시킨다.
4. 핸들러 실행
HandlerAdapter 객체는 Handler객체를 실행시킨다.
5. ModelAndView 반환
실행된 Handler 객체는 실제 컨트롤러의 메서드를 실행한 후, Handler가 반환하는 정보를 ModelAndView로 변환하여 얻는다.
6. viewResolver 호출
viewResolver를 찾아 ModelAndView를 통해 얻은 view의 이름을 전달하여 실행시킨다.
*viewResolver는 실행할 view를 찾으며, ModelAndView 객체를 View 영역으로 전달하기 위해 알맞은 View 정보를 설정하는 역할을 한다.
7. View 반환
viewResolver는 view의 논리 이름을 물리 이름으로 바꾸고, 렌더링 역할을 담당하는 View 객체로 반환한다.
8. 뷰 렌더링
View 객체에 ModelAndView 객체의 Model을 파라미터로 넘겨 render()를 호출하면 페이지 렌더링을 수행한다.
→ 이는 DispatcherServlet에 의해 사용자에게 response로 리턴된다.
