
*2차 세미나 과제로 제출했던 내용을 공유하면 좋을 것 같아 포스트합니다 :)
PUT과 PATCH의 차이점
두 메서드 모두 리소스의 업데이트를 수행한다는 공통점이 있지만, PUT은 지정한 데이터를 전부 수정하고, PATCH는 정보의 일부분만 변경한다는 차이점이 있다.
두 메서드 모두 메시지 바디에 원하는 내용을 실어서 보낸다.
| 게시글(Post) | 1 |
|---|---|
| title | 제목 |
| content | 내용 |
PUT
리소스를 완전히 대체[Overwrite] ⇒ 기존 필드도 사라져버림(null 값으로 변함)
PUT /posts/1
{
title: "New 제목",
}위 리소스에 대해 이와 같은 요청을 보내면? 기존 필드에 값이 존재하지만, 요청에는 포함되지 않은 content의 값이 null이 된다.
| 게시글(Post) | 1 |
|---|---|
| title | New 제목 |
| content | null |
-
해당 리소스 無? 서버로 요청된 데이터로 새로운 리소스 생성! (POST와 동일한 역할 → 똑같이 201 Created 반환)
-
멱등성 보장 O
어떤 리소스를 읽어오거나 대체하는 연산은 멱등성을 보장한다. (⇒ 결과가 같음을 보장)
요청의 리소스 자체가 변하지 않는다면 계속 Overwrite한다는 PUT의 특성에 의해 연산 수행 결과는 매번 동일할 것이다.
*GET, PUT, DELETE가 이에 해당!
PATCH
리소스의 부분 변경
→ 요청에 포함된 부분만 변경
PATCH /posts/1
{
title: "New 제목",
}PUT으로 보낸 요청을 PATCH로만 바꿔서 보내면, 이 결과는 요청을 보낸 title 필드에 대해서만 변경이 적용된다.
| 게시글(Post) | 1 |
|---|---|
| title | New 제목 |
| content | 내용 |
원치 않는 데이터의 초기화를 막기 위해서는 데이터를 수정하는 API 구현 시, PUT보다 PATCH를 쓰는 것을 권장한다.
BUT PUT은 멱등성을 보장하지만, PATCH는 멱등성을 보장하지 않는다는 특성을 가진다.
-
멱등성 보장 X
POST가 새로운 리소스를 매번 생성함으로써 어플리케이션의 상황을 완전히 바꿀 수도 있는 것처럼, PATCH는 API의 구현 방식에 따라 멱등성의 보장 여부가 달라진다.
리소스 일부 수정이라는 자체만으로 보면 PUT과 크게 다르지 않아 멱등성을 보장할 수 있지만, 어플리케이션을 바꿀 수 있을 만한 일부 필드의 수정이라면 연산 수행 결과가 달라지게 되므로 멱등성을 보장하지 않는 것으로 취급한다.
*POST, PATCH가 이에 해당!
- 클라이언트가 리소스의 위치를 알고 URI 지정
⇒ POST에서는 경로를 구체적으로 지정하지 않아, 서버에서 해당 리소스가 생성될 경로를 할당하지만, PUT에서는 직접 할당될 경로를 지정하여 요청을 보낸다.
- 요청을 2번 보낸다면?
POST는 2개의 새로운 리소스 생성, PUT은 리소스를 2번 수정하거나, 1개의 리소스 생성 후 1번의 수정과정을 거치게 된다.
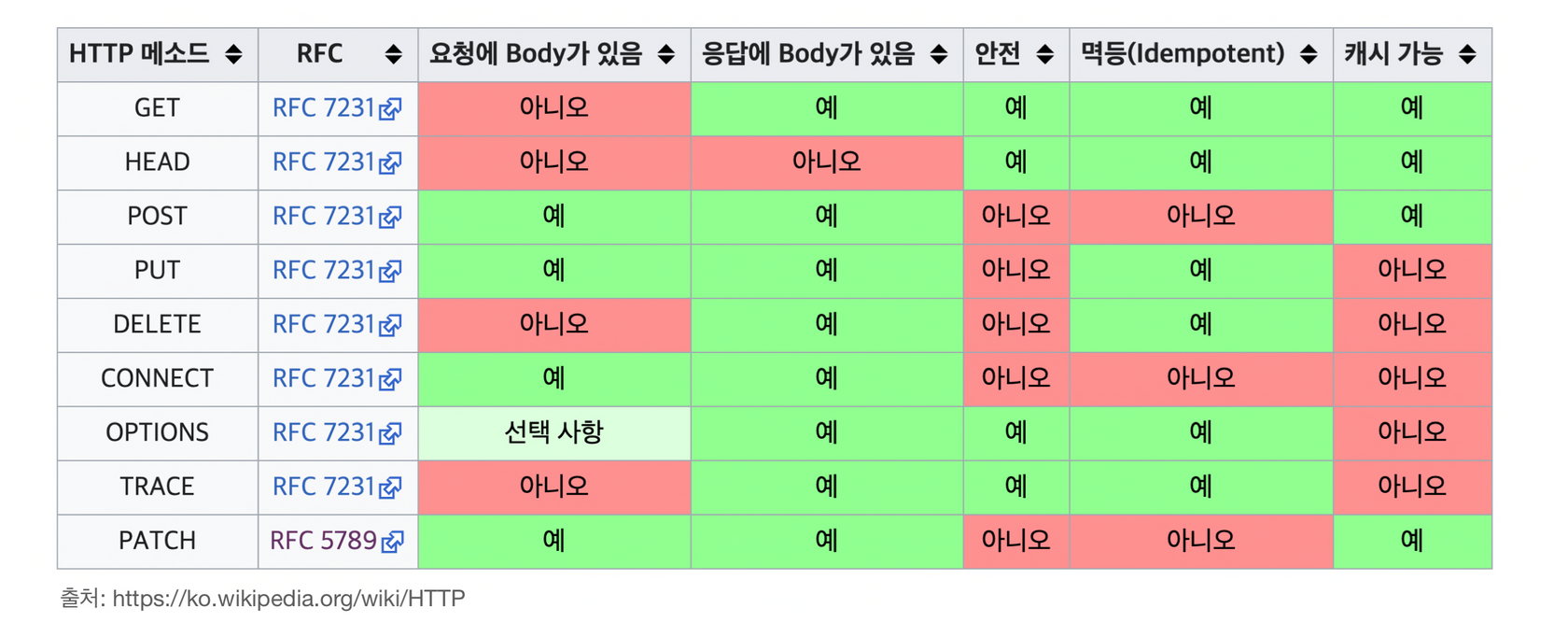
[참고] HTTP Method의 주요 특징 비교
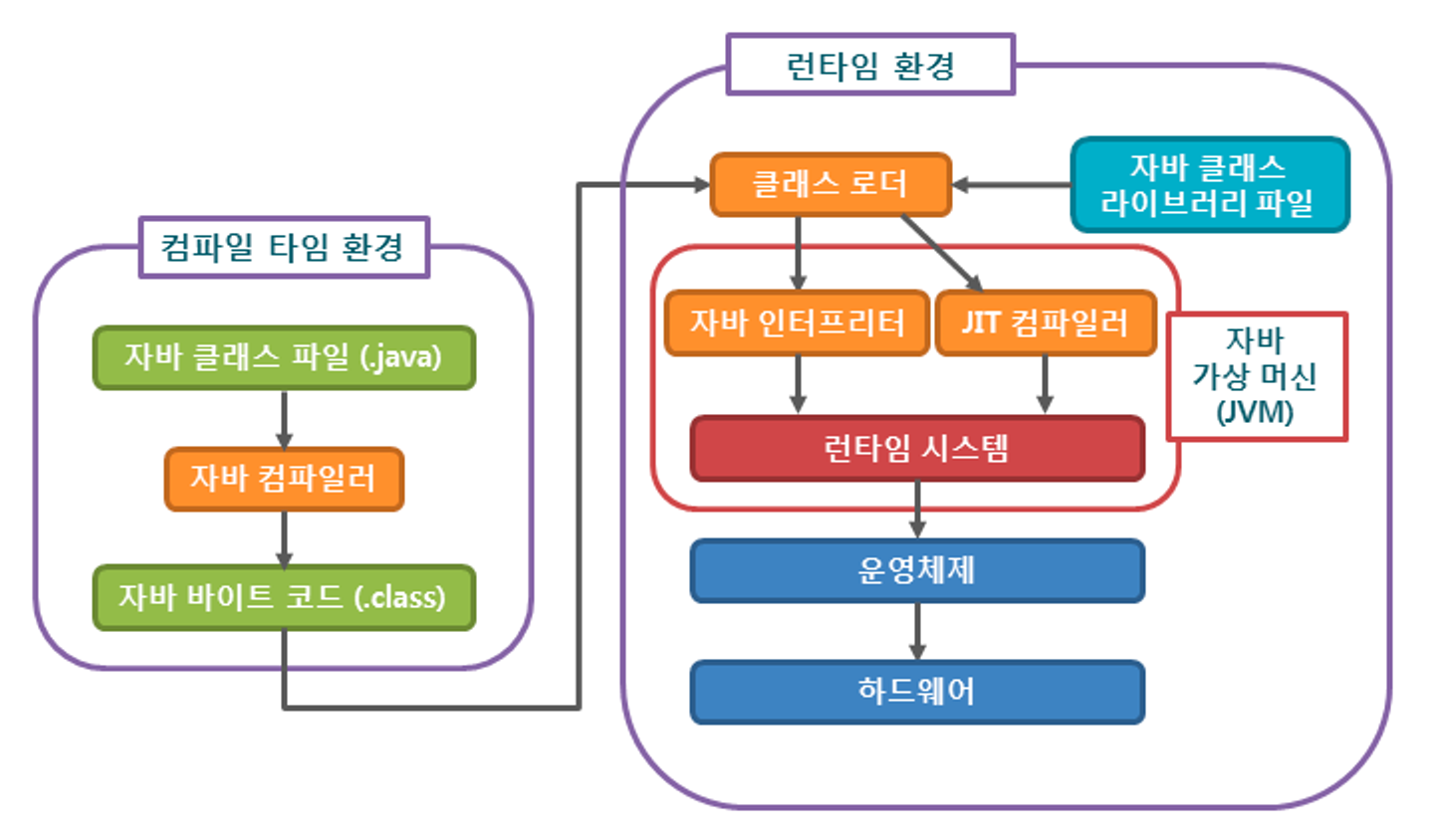
자바의 컴파일 과정
-
개발자가 자바 소스코드(.java)를 작성한다.
-
자바 컴파일러가 자바 소스파일(.java)을 자바 바이트 코드(.class)로 컴파일한다.
*자바 바이트 코드 = JVM(자바 가상 머신)이 이해할 수 있는 코드!
-
컴파일된 바이트 코드를 JVM의 클래스 로더에게 전달한다.
-
클래스 로더는 동적 로딩을 통해 필요한 클래스들을 로딩 및 링크하여, JVM의 메모리인 런타임 데이터 영역에 올린다.
-
실행엔진은 JVM 메모리에 올라온 바이크 코드들을 명령어 단위로 하나씩 가져와서 실행한다.
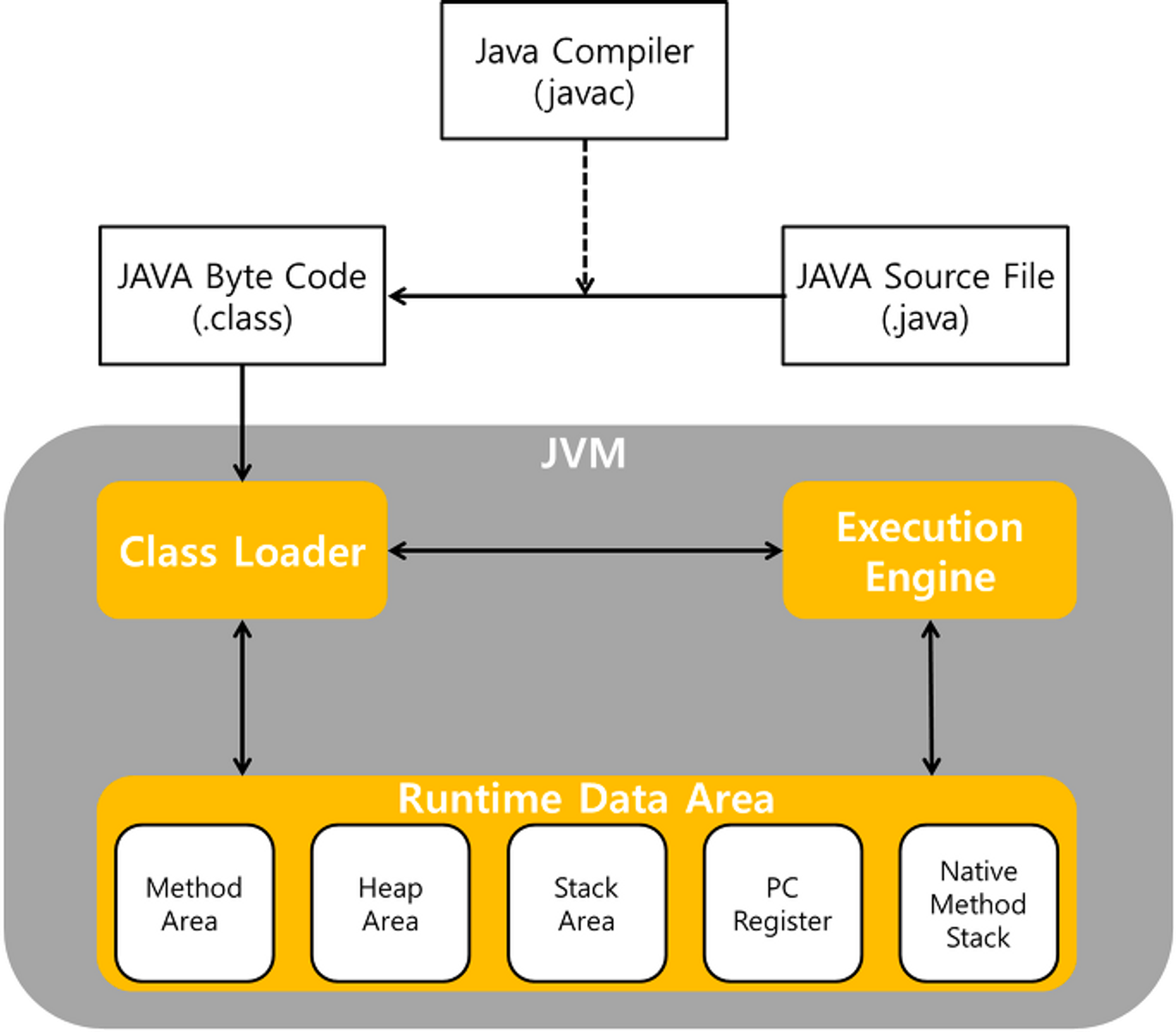
자바 가상 머신(JVM, Java Virtual Machine)
자바를 실행하기 위한 가상 기계
*가상 기계: 소프트웨어로 구현된 하드웨어
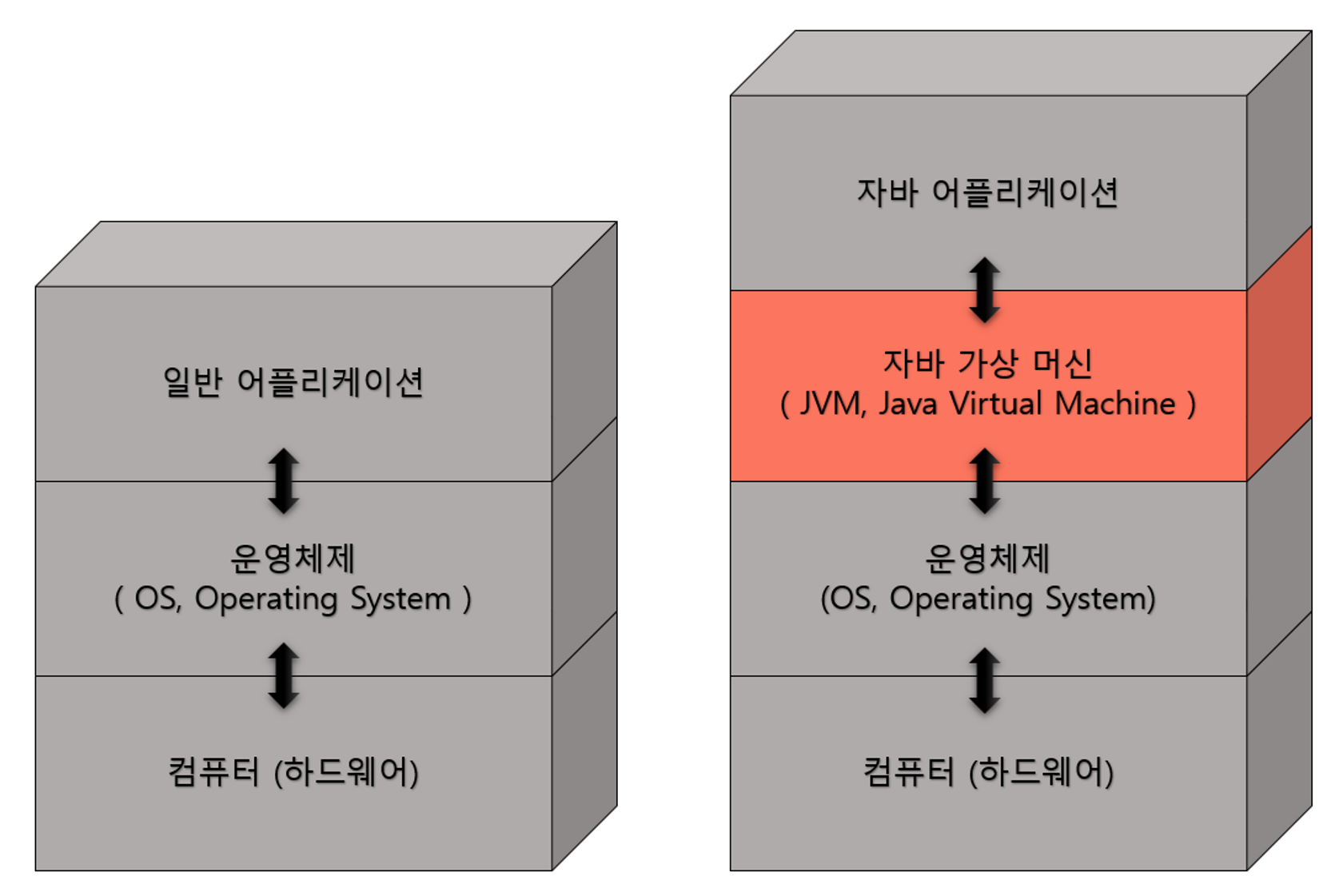
자바로 작성된 코드는 모두 JVM에서만 실행되므로, 자바 어플리케이션이 실행되려면 반드시 JVM이 필요하다. JVM은 자바만이 가지는 특징으로, 일반 어플리케이션은 바로 특정 OS를 거쳐 하드웨어로 전달되지만, 자바 어플리케이션은 JVM을 한 번 더 거침으로써 하드웨어에 맞게 완전히 컴파일된 상태가 아닌 실행 시 해석이 되는 인터프리터 형식이므로 속도가 느리기도 하다.
JVM에서는 OS로부터 메모리를 할당받아 스스로 메모리 관리를 하고, 컴파일 후 생성된 파일을 적재하므로 프로그램의 생성과 실행 모든 과정에 관여한다.
👍 GOOD
- 자바 어플리케이션은 JVM과만 상호작용 하기 때문에 일반 어플리케이션과 달리 OS와 하드웨어에 독립적이다.
⇒ “Write once, run anywhere” : 한 번 작성하면 어디서든 실행된다. - Java 컴파일러가 바이트 코드를 만들 때 클래스 단위로 생성하므로, 프로그램의 일부가 수정되더라도 전체를 컴파일할 필요가 없다.
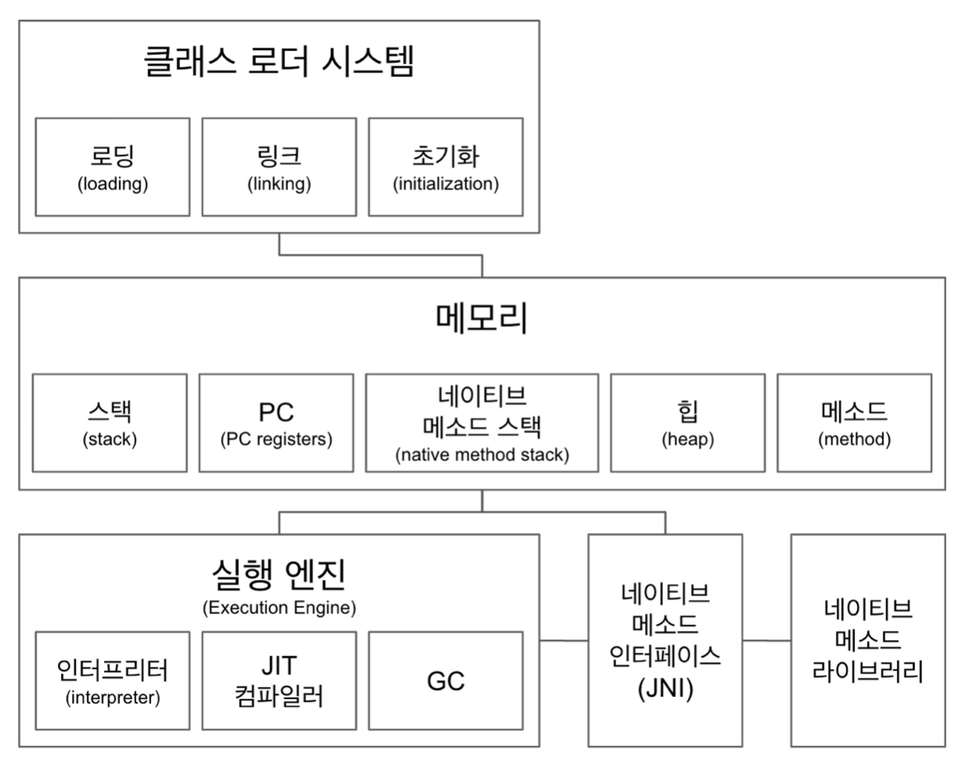
클래스 로더(Class Loader)
🔍 클래스 로더의 세부 동작자바 클래스를 자바 가상 머신으로 동적 로드하는 자바 런타임 환경(JRE)의 일부
- 런타임 중 동적으로 저장된 클래스 → JVM 위에 탑재
- 사용하지 않는 클래스 → 메모리에서 삭제
- 로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드
- 검증 : 자바 언어 명세 및 JVM 명세에 명시된대로 구성되어 있는지 검사
- 준비 : 클래스가 필요로 하는 메모리를 할당(필드, 메서드, 인터페이스 등)
- 분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스 → 다이렉트 레퍼런스로 변경
- 초기화 : 클래스 변수(static 필드) 적절한 값으로 초기화
실행엔진(Execution Engine)
🔍 실행엔진의 해석 방식클래스의 바이트 코드 → 바이너리 코드로 변환하여 기계가 수행할 수 있는 형태로 해석한다.
-
인터프리터
바이트 코드 명령어를 하나씩 읽어서 해석하고 실행
→ 👍 하나하나의 실행은 빠르나, 👎 전체적인 실행 속도가 느림
-
JIT(Just-In-Time) 컴파일러
바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고, 이후에는 해당 메서드를 더이상 인터프리팅하지 않고 바이너리 코드로 직접 실행하는 방식 → 아래 두 방식을 결합한 형태로 동작
- Compile-Behavior 방식
컴파일 시 필요한 변수와 공간 확보 by malloc() ;동적 메모리 할당 함수 - Run-time Behavior 방식
실제로 실행되면서 필요한 변수와 공간 확보
HEAP AREA(동적 메모리) ←new 예약어로 객체생성할 때
→ 👍 인터프리터의 단점 보완 ⇒ 전체적인 실행 속도가 빠름
- Compile-Behavior 방식
런타임 데이터 공간(Runtime Data Area)
JVM의 메모리 영역
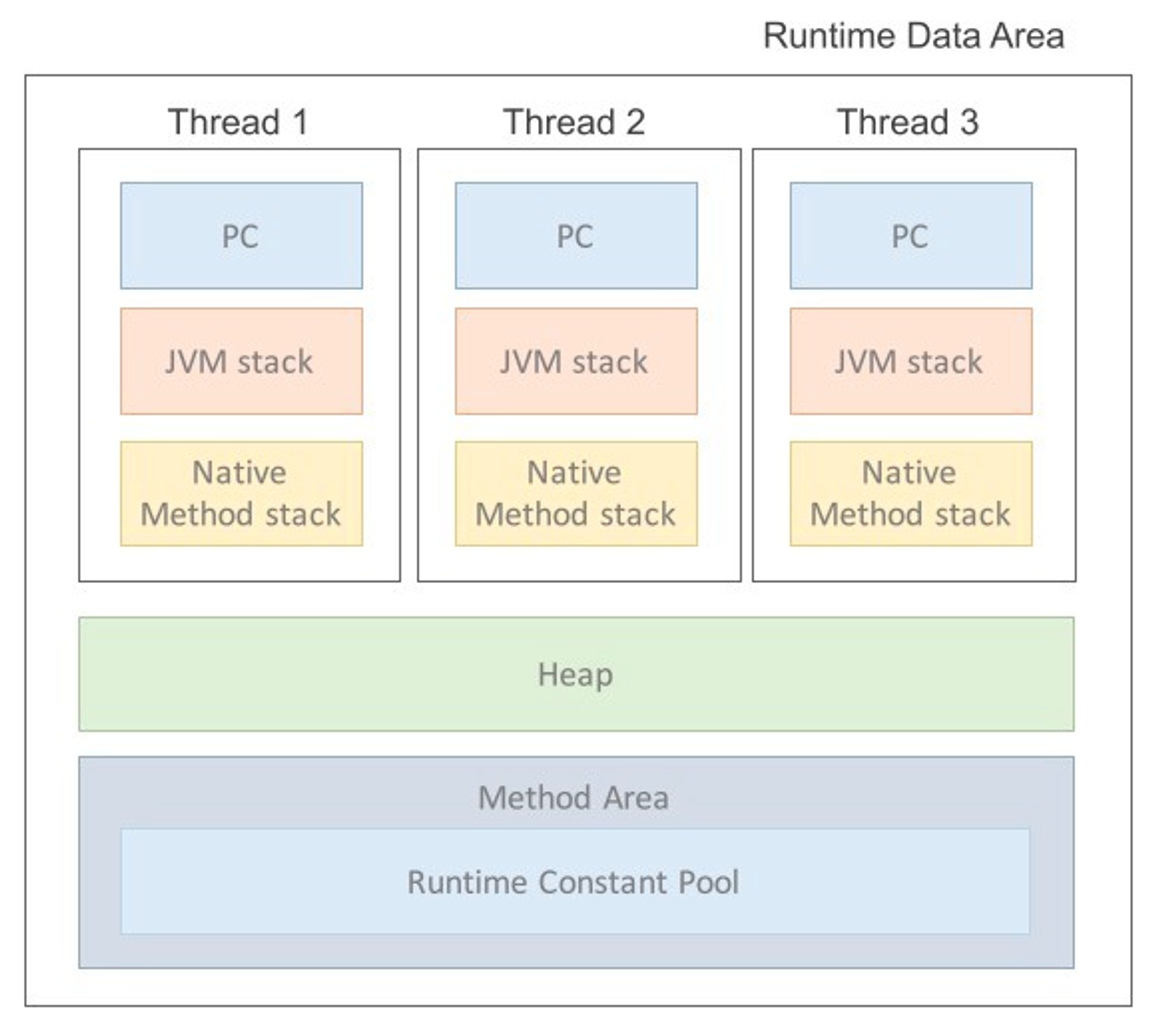
| 종류 | 기능 |
|---|---|
| PC 레지스터 영역 | 각 스레드마다 하나씩 생성되는 영역 → 현재 수행 중인 JVM 명령의 주소값을 저장 (JVM 명령 = 스레드가 어떤 부분을 어떤 명령으로 실행해야 하니?) |
| 스택 영역 | 메소드 내에서 사용되는 매개변수, 지역변수, 리턴값 등 지역적인 값이나 스레드나 메소드 그 자체에 대한 정보 저장 → LIFO 방식 |
| Native Method Stack | 다른 프로그램들처럼 커널이 독자적으로 Java 프로그램 실행 → 다른 언어의 메소드 호출을 위해 할당되는 구역 언어에 맞게 스택이 형성됨 ⇒ 기계어로 번역된 프로그램이 실행되는 곳 |
| 메소드 영역 | = 클래스 영역, 스태틱 영역 |
| 메소드 정보, 클래스 정보, static으로 선언된 변수 정보, 상수 정보 저장 (초기화하고자 하는 정보) → 거의 대부분의 바이트 코드가 여기에 저장! | |
| 힙 영역 | 객체를 저장하는 가상 메모리 공간으로, new로 생성한 모든 인스턴스와 객체들이 여기에 저장 (자동으로 메모리 관리 담당하는 “가비지 컬렉션 이슈”가 이 영역에서 이루어짐) |
🔍 가비지 컬렉션(Garbage Collection, GC)
JVM이 불필요한 메모리를 정리해주는 기능
어떤 인스턴스가 생성되어 메모리 공간을 차지한 상태에서 해당 인스턴스가 프로그램에서 사용되지 않는다면, 해당 인스턴스는 Garbage된다.
- null 처리가 된 경우
- 해당 인스턴스를 참조하는 부분이 없는 경우
[자바 기초] 3. 자바의 동작원리 : Garbage Collection
*참고 자료
https://velog.io/@raejoonee/about-jvm
https://gyoogle.dev/blog/computer-language/Java/컴파일 과정.html
Builder Pattern
복잡한 객체를 생성하는 방법을 정의하는 클래스와 표현하는 방법을 정의하는 클래스를 별도로 분리하여, 동일한 생성 절차에서 서로 다른 표현 결과를 제공하는 패턴
- 생성자의 인자가 너무 많은 경우, 어떤 인자가 어떤 값을 나타내는지 확인하기 어려운 경우
- 인스턴스 중 특정 인자만으로 생성해야 하는 경우
- 특정 인자에 해당하는 값을 null로 전달해야 하는 경우
위와 같은 문제들을 해결하기 위해 Builder Pattern을 사용할 수 있다.
빌더 패턴 적용 예제
public class Board {
private final String title;
private final String content;
private final String writer;
public Board(Builder builder) {
this.title = builder.title;
this.content = builder.content;
this.writer = builder.writer;
}
}public static class Builder {
private final String title;
private final String content;
private String writer;
public Builder(String title, String content) {
this.title = title;
this.content = content;
}
public Builder withWriter(String writer) {
this.writer = writer;
return this;
}
public Board build() {
return new Board(this);
}
}빌더 패턴으로 생성자 클래스를 생성하려면 아래와 같이 작성할 수 있다,
// 빌더 패턴으로 생성자 생성
Board board = new Board
.Builder("제목", "내용")
.withWriter("작성자")
.build();Lombok을 이용한 빌더 패턴 적용
이는 코드가 굉장히 길고, 실제 프로그램 개발 시 일일이 작성하기에 불편하다. 따라서 SpringBoot에서는 Lombok을 이용하여 더 편리하게 생성할 수 있도록 기능을 제공하고 있다.
@Builder 어노테이션을 사용하여 따로 Builder 클래스를 생성하지 않고도 빌더 패턴을 적용할 수 있다.
@Builder(builderMethodMame="BoardBuilder")
public class Board {
private final String title;
private final String content;
private final String writer;
public Board(Builder builder) {
this.title = builder.title;
this.content = builder.content;
this.writer = builder.writer;
}
}
// main에서 객체 생성 시
Board board = Board.builder()
.title("제목")
.content("내용")
.writer("작성자")
.build();- 클래스 내부 builder 메소드 빌더 메소드는 null값이 아닌 경우에만 생성하는 등 필수로 들어가야 하는 필드들을 검증하고자 할 때 사용한다. builderMethod로 정한 “BoardBuilder” 이름의 메소드에서 이를 처리할 수 있다. → 보통 PK를 지정
- 기본적으로
@Builder어노테이션이 붙으면 모든 요소를 받는 package-private 생성자가 자동으로 생성되며, 이 생성자에@Builder어노테이션을 붙인 것과 동일하게 동작한다.
빌더 패턴의 장점
-
필요한 데이터만 설정 가능 - 필요한 데이터가 달라질 때마다 생성자를 수정해야 하는 수고를 덜고 동적으로 쉽게 처리할 수 있다.
-
유연성 확보 - 새로운 변수가 추가되는 상황에서 기존의 코드에 영향을 주지 않는다.
-
가독성을 높일 수 있음 - 매개변수가 많은 경우에, 생성자보다 훨씬 높은 가독성을 가진다. 또한, 직관적으로 어떤 데이터에 어떤 값이 설정되는지 쉽게 파악할 수 있다.
-
불변성 확보 - setter(수정자) 패턴을 사용하지 않고도 빌더를 통한 수정이 적용될 수 있다.
*setter 구현 방식은 불필요한 확장 가능성을 열어두며, Open-Closed 법칙에 위배되어 사용을 지양한다.
설계자들이 올바른 설계를 빨리 만들 수 있도록 도와주기 위해, 기존 환경 내에서 반복적으로 일어나는 문제들을 어떻게 풀어나갈 것인가에 대한 일종의 솔루션을 제공하는 것
| 생성(Creational) 패턴 | 구조(Structural) 패턴 | 행동(Behavioral) 패턴 |
|---|---|---|
| Singleton | Adapter | Command |
| Abstract Factory | Composite | Interpreter |
| Factory Method | Decorator | Iterator |
| Builder | Facade | Mediator |
| Prototype | Flyweight | Memento |
| Proxy | Observer | |
| State | ||
| Strategy | ||
| Template Method |
인스턴스를 만드는 절차를 추상화 하는 생성 패턴(Creational Pattern)의 일종으로, 여기서는 객체를 생성 및 합성하는 방법이나 객체의 표현 방법을 시스템과 분리해준다.
→ 시스템이 상속보다 복합 방법을 사용하는 방향으로 진화하며 중요성이 더욱 커지고 있다!
오늘 사용한 모든 Annotation
🔍 Annotation in JAVA코드 사이에 주석처럼 쓰여서 특별한 의미, 기능을 수행하도록 프로그램에 추가 정보를 제공해주는 메타 데이터
📍목적 ?
- 컴파일러에게 코드 작성 문법 에러를 체크하도록
- 소프트웨어 개발 툴이 빌드나 배치 시 코드를 자동 생성할 수 있도록
- 실행(런타임) 시 특정 기능을 실행 하도록
@RestController
Controller VS RestController
가장 큰 차이점 - HTTP Response Body가 생성되는 방식
📌 Controller
view기술을 사용하고- 주로 view(화면)를 return한다.
@ResponseBody어노테이션을 사용하면 Controller에서 직접 Data를 return 할 수 있다. form 태그를 이용해서 데이터를 전송받을 때와 같이 클라이언트가 보내는 HTTP 요청 본문(JSON 및 XML 등)을 Java 오브젝트로 변환하는 역할을 수행
📌 RestController
- 객체를 반환하기만 하면 객체 데이터는 Json형식의 HTTP응답을 직접 작성한다.
Data를 return하는 것이 주 용도이다.@RestController는 크게@Controller+@ResponseBody두 개의 어노테이션의 조합으로 볼 수 있다.-
@Controller- @Component로 스프링이 이 클래스의 오브젝트를 알아서 생성하고 다른 오브젝트들과의 의존성을 연결한다는 의미 -
@ResponseBody- 이 클래스의 메서드가 리턴하는 것이 웹 서비스의 ResponseBody라는 의미⇒ 이 어노테이션을 사용하면 각 메소드마다
@ResponseBody설정 할 필요 X
-
REST API 요청에 관한 어노테이션
@RequestBody
직렬화(serialization) : 스프링이 오브젝트를 JSON으로 바꾸는 것 → 오브젝트 저장 및 네트워크를 통해 전달하기 위한 변환 작업
역직렬화(deserialization) : 직렬화의 반대의 작업
DTO를 넘겨줬을 때의 동작은 다음과 같다.
RequestBodyDto 객체 → JSON 문자열 변환 → POST 요청 본문에 담아서 전송 → 다시 응답 본문으로 전달
- @RequestBody를 사용하면 요청 본문의 JSON, XML, Text 등의 데이터가 적합한 HttpMessageConverter를 통해 파싱되어 Java 객체로 변환 된다.
- @RequestBody를 사용할 객체는 필드를 바인딩할 생성자나 setter 메서드가 필요없다.
- 다만 직렬화를 위해 기본 생성자는 필수다.
- 또한 데이터 바인딩을 위한 필드명을 알아내기 위해 getter나 setter 중 1가지는 정의되어 있어야 한다. *만약 getter나 setter 메서드가 모두 정의되어 있지 않으면, 실행 시 HttpMessageNotWritableException 예외가 발생한다.
- @RequestBody로 보내오는 JSON을 DTO 오브젝트로 변환하여 가져온다.
- ResponseEntity를 사용하는 이유 - HTTP 응답의 바디뿐만 아니라 여러 다른 매개변수(status, header)를 조작하고 싶을 때 사용
*@RequestParam과의 차이?
@RequestBody 로 데이터를 받을 때는 메서드의 변수명이 상관 없었지만, @RequestParam 으로 데이터를 받을 때는 데이터를 저장하는 이름으로 메서드의 변수명을 일일이 지정해줘야 한다.
| @RequestBody | @RequestParam | |
|---|---|---|
| 객체 생성 | 가능 | 불가능 |
| 각 변수별로 데이터 저장 | 불가능 | 가능 |
@RequestParam
Request의 Parameter를 가져오는, 즉 쿼리 파라미터를 파싱하는 역할을 한다. 키와 값의 쌍으로 전송되는 단순 데이터에 유용하다.
HTTP GET 요청에서 URL 뒤에 붙는 parameter 값에 대해 자동으로 매칭되어 처리할 수 있다. → ex. ?name=jun&age=21에서, @RequestParam String name, @RequestParam int age로 넘겨받은 값을 바인딩할 수 있다.
IN Form-data
GET 요청이 아닌 경우에도 이를 사용할 수 있는데, 이때 Converter 역할이 추가되어야 한다. DTO로 form-data를 다룬다면 DTO는 json 데이터 상에서 key에 해당하고, 입력받은 값이 value에 해당하게 된다.
또한, json 형태의 String 타입이 DTO엔티티에 바인딩되려면 String→DTO의 변환 과정이 필요한데, 이는 Converter로 처리할 수 있다.
cf) @RequestPart
MultipartFile 타입을 바인딩해주는 역할
컨트롤러 역할의 메서드에 파라미터로 @RequestPart 를 붙여준 인스턴스를 통해 MultipartFile 타입을 바인딩할 수 있다.
@PathVariable
REST API 개발 시 URI에 변수가 들어간 형태를 많이 볼 수 있는데, 이와 같은 상황에서 @PathVariable로 처리할 수 있다.
메소드 정의 시 맵핑한 URI의 변수명을 그대로 @PathVariable(”변수명”)으로 작성해서 사용한다. (이때 타입은 무관)
즉, @RequestParam 이 전송된 데이터를 실어서 사용할 수 있다면, 경로에서 사용되는 변수에 직접적으로 접근하고자 할 때 @PathVariable 을 사용한다고 볼 수 있다.
ETC ..
| 어노테이션 | 기능 |
|---|---|
| @RequiredArgsConstructor | 선언된 모든 final 필드가 포함된 생성자를 자동 생성 |
| @AllArgsConstructor | 전체 인자를 갖는 생성자를 private의 접근자로 만들어 외부에서 접근하지 못하도록 한다. |
| @Getter | 선언된 모든 필드의 get 메소드를 생성(getter, setter을 일일이 구현하는 부분을 @Getter , @Setter 어노테이션 한 줄로 구현 가능) |
| @Service | 스프링 컨테이너에 빈 객체로 생성해주는 어노테이션 → 비즈니스 로직을 처리하는 서비스 레이어의 클래스에 붙여서 사용 (@Component 로 써도 동작!) |
| @PostMapping | HTTP Method인 POST의 요청을 받을 수 있는 API 생성 |
| @GetMapping | HTTP Method인 GET의 요청을 받을 수 있는 API 생성 @GetMapping(”요청 주소”) → http://localhost:8080/"요청주소" 로 접속할 시에 작성한 API가 실행됨. |
