
*3차 세미나 과제로 제출했던 내용을 공유하면 좋을 것 같아 포스트합니다 :)
데이터베이스 제약조건
제약조건(Constraint)이란? 데이터의 무결성을 지키기 위해 입력받은 데이터에 대한 제한을 두는 것
→ 제약조건을 통해 검사를 진행하여 어떤 조건을 만족할 경우에만 입력이 되도록 제약할 수 있다!
| 종류 | 기능 | 설명 |
|---|---|---|
| NOT NULL | 해당 컬럼을 필수 필드화 → NULL 값을 저장할 수 없음을 명시 | |
| UNIQUE | 중복된 값을 저장할 수 없음을 명시 | |
| ⇒ 데이터의 유일성을 보장 | NULL을 허용하며, 하나의 테이블에 여러 개 올 수 있다는 것이 PRIMARY KEY와의 차이점 | |
| PRIMARY KEY | 기본키 지정 | - NOT NULL + UNIQUE의 특성을 기본적으로 가짐 |
| - 다른 테이블에서 외래키들이 참조할 수 있는 키로서의 자격을 갖춤 by 참조 무결성 | ||
| FOREIGN KEY | 한 테이블을 다른 테이블과 연결하여 외래키 지정 | - FOREIGN KEY가 붙은 해당 테이블이 다른 테이블을 의존(참조)하는 관계 |
| - ON DELETE / ON UPDATE + [CASCADE/SET NULL/DEFAULT/RESTRICT] 와 함께 참조 무결성을 위한 제약을 달 수 있음 | ||
| DEFAULT | 디폴트값 설정 | |
| CHECK | 컬럼의 값을 어떤 특정 범위로 제약 | ex. CHECK age IN 20 BETWEEN 30; |
관계형 데이터베이스의 정규화
정규화란? 관계형 데이터베이스 데이터 모델의 중복을 최소화하고 데이터의 일관성, 유연성을 확보하기 위한 목적으로 데이터를 분해 및 구조화하는 과정
목적
- 불필요하거나 중복되는 데이터(Data Redundancy)들을 제거한다.
- 이상현상(Anomaly)을 방지한다.
-
이상현상이란?
이상현상
STUDENT 학번 이름 학과명 학과코드 전화번호
학생에 필요한 정보들을 모두 하나의 테이블로 모아둔 예시이다. 위 테이블에 행을 추가하는 상황에서, 새로운 학과를 추가한다면 학생이 아무도 없기 때문에 임의의 값으로 학생 정보를 입력하여 추가해야 한다. 이는 불필요하고 무의미한 값이 들어가게 되므로 테이블을 하나로 합쳐서는 안 되는 것이다.
이를 이상현상(anomaly)이라고 하고, 이러한 현상을 해결하기 위해 정규화를 수행하여 테이블을 분리하여 관리해야 할 필요가 있다.
👻 이상현상의 종류
- 삭제 이상 : 데이터 삭제 시 의도와는 상관없이 다른 정보까지 연쇄적으로 삭제되는 현상
- 삽입 이상 : 데이터 삽입 시 의도와는 상관없이 원하지 않는 값들도 함께 삽입되는 현상
- 수정 이상 : 데이터 수정 시 의도와는 상관없이 데이터의 일부만 수정되어 일어나는 데이터 불일치 현상
-
데이터 저장을 논리적으로 한다.
-
관련이 없는 함수 종속성은 별개의 릴레이션으로 표현한다.
-
정규화 절차
정규화된 결과를 정규형이라고 하며, 정규형은 다음과 같이 나눌 수 있다.
기본 정규형 : 제1정규형, 제2정규형, 제3정규형, BCNF(보이스/코드 정규형)
고급 정규형 : 제4정규형, 제5정규형
제1정규화(1NF)
릴레이션에 속한 모든 속성의 도메인이 더 이상 분해되지 않는 원자값으로만 구성되도록 원자값이 아닌 도메인을 분해한다.
제1정규화 이전
| 이름 | 취미 |
|---|---|
| A | 운동, 음악 |
| B | 게임 |
→ 제1정규형
| 이름 | 취미 |
|---|---|
| A | 운동 |
| A | 음악 |
| B | 게임 |
제2정규화(2NF)
기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거(분해)한다.
기본키가 아닌 모든 속성이 기본키에 완전 함수 종속되도록 하는 것이 제2정규화의 목표이다.
제2정규화 이전
| 학번 | 강좌명 | 강의실 | 성적 |
|---|---|---|---|
| 2112 | 알고리즘 | 505 | 4.5 |
| 2113 | 자료구조 | 506 | 4.0 |
→ 제2정규형
| 학번 | 강좌명 | 성적 |
|---|---|---|
| 2112 | 알고리즘 | 4.5 |
| 2113 | 자료구조 | 4.0 |
| 강좌명 | 강의실 |
|---|---|
| 알고리즘 | 505 |
| 자료구조 | 506 |
🔎 함수 종속의 개념
어떤 릴레이션 R에 존재하는 속성의 부분집합을 각각 X와 Y라고 하자. X의 값을 알면 Y의 값이 식별되는 관계에 있을 때나 X의 값에 따라 Y의 값이 달라질 때, Y는 X에 함수적 종속이다 (X→Y) 라고 한다.
완전 함수 종속이란?
어떤 속성이 기본키에만 완전히 종속. 기본키가 여러 속성으로 구성되어 있을 경우, 기본키를 구성하는 모든 속성이 포함된 키본키의 부분집합에 종속되는 것을 말한다.
| 고객ID | 주문코드 | 주문상품 | 수량 |
|---|---|---|---|
| A1 | T001 | 카메라 | 2 |
| A1 | B110 | 노트북 | 1 |
| A2 | B110 | 거치대 | 5 |
ex. 위 테이블에서 (고객ID, 주문코드)의 속성 집합이 기본키라고 할 때, ‘수량’ 속성은 기본키를 구성하는 고객ID와 주문코드를 모두 알아야만 식별이 가능하다.
부분 함수 종속이란?
어떤 속성이 기본키가 아닌 다른 속성에 종속. 기본키가 여러 속성으로 구성되어 있을 경우, 기본키를 구성하는 속성 중 일부만 종속되는 것을 말한다.
ex. 위 예시에서 ‘주문상품’ 속성은 기본키를 구성하는 속성 집합 중 주문코드만 알아도 식별이 가능하다.
+ 이행적 함수 종속
속성 집합 X, Y, Z 3개가 있을 때, X→Y, Y→Z의 종속 관계가 있을 경우, X→Z가 성립
| 상품번호 | 상품명 | 소분류 | 대분류 |
|---|---|---|---|
| A1 | 카메라 | 소형기기 | 전자제품 |
| A2 | 노트북 | 중형기기 | 전자제품 |
| A3 | 녹차 | 차/음료 | 식품 |
ex. 위 테이블에서 ‘상품번호’(X)를 알면 ‘소분류’(Y)를 알 수 있고, ‘소분류’(Y)를 알면 ‘대분류’(Z)를 알 수 있다. 즉, ‘상품번호’를 알면 ‘대분류’를 알 수 있는 관계에 있다.
*참고 - https://dodo000.tistory.com/20
제3정규화(3NF)
기본키를 제외한 컬럼 간의 종속성을 제거한다. 즉, 이행 함수 종속성을 제거한다.
제3정규화 이전
| 학번 | 강좌명 | 수강료 |
|---|---|---|
| 2112 | 알고리즘 | 30,000 |
| 2113 | 자료구조 | 20,000 |
→ 제3정규형
| 학번 | 강좌명 |
|---|---|
| 2112 | 알고리즘 |
| 2113 | 자료구조 |
| 강좌명 | 수강료 |
|---|---|
| 알고리즘 | 30,000 |
| 자료구조 | 20,000 |
BCNF
기본키를 제외하고 후보키가 있는 경우, 후보키가 기본키를 종속시키면 분해한다.
하나의 릴레이션에 여러 개의 후보키가 존재할 수 있는데, 이런 경우에 제3정규형까지 모두 만족하더라도 이상현상이 발생할 수 있다. 이를 해결하기 위해 제3정규형보다 엄격한 제약조건을 제시한 절차이다. BCNF의 목표는 모든 결정자가 후보키가 되도록 하는 것(=후보키가 아닌 결정자가 존재하지 않도록 하는 것)이다.
BCNF 이전
| 학번 | 강좌명 | 교수명 |
|---|---|---|
| 2112 | 알고리즘 | 김교수 |
| 2113 | 자료구조 | 박교수 |
| 2114 | 자료구조 | 박교수 |
→ BCNF
| 학번 | 교수명 |
|---|---|
| 2112 | 김교수 |
| 2113 | 박교수 |
| 2114 | 박교수 |
학번-교수 릴레이션을 함수 종속이 성립하지 않는 동등한 속성으로 구성하면, (학번, 교수명)이 기본키의 역할을 하게 된다.
| 교수명 | 강좌명 |
|---|---|
| 김교수 | 알고리즘 |
| 박교수 | 자료구조 |
교수-강좌 릴레이션은 함수 종속 관계를 가지며, 교수가 유일한 후보키이자 기본키이다.
제4정규화(4NF)
여러 컬럼들이 하나의 컬럼을 종속시키는 경우 분해하여 다중값 종속성을 제거한다.
제5정규화(5NF)
조인에 의해서 종속성이 발생하는 경우 분해한다.
*참고 자료 - https://hongcoding.tistory.com/147
정규표현식
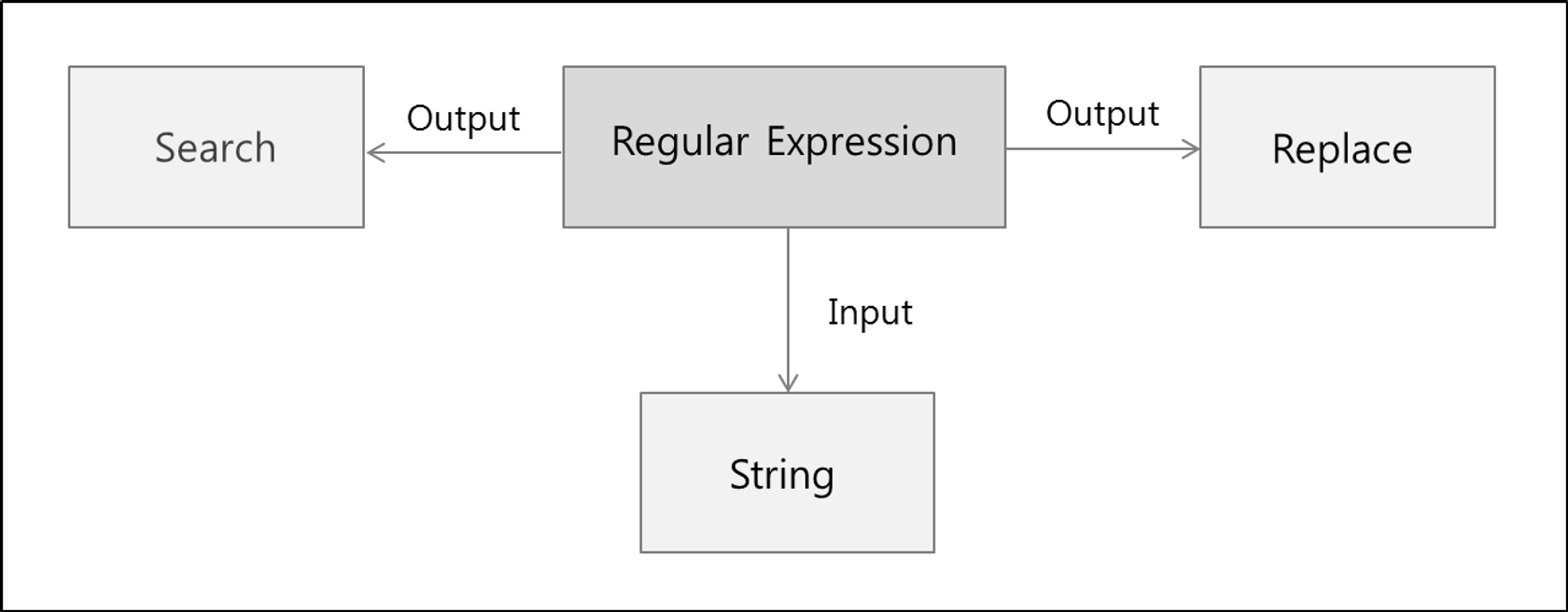
정규표현식이란 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어로, 개발 시에 사용자로부터 제한된 조건으로 입력을 받아야 하는 상황 등에서 사용할 수 있다.

정규표현식 정리
*️⃣ 유효성 검사
-
논리적 Validation
중복된 이메일인지, 아이디에 대한 비밀번호가 DB에 존재하는지 등 DB에서 값의 유효성을 검증해야 하는 로직에 대한 예외처리→ Provider나 Service에서 처리
-
형식적 Validation
이메일, 전화번호 등 폼 작성 시 빈 값이 존재하는지 등 값, 길이 (양식), 부적절합 타입 등의 형식을 체크해야 하는 부분을 처리하는 것 ✅ 정규표현식(RegEx) 검사→ Controller에서 처리
정규표현식(Regular Expression) 사이트 및 팁
프록시
프록시(Proxy)란?
프록시(Proxy) 서버는 내부 네트워크에서 인터넷 접속을 할 때 빠른 액세스나 안전한 통신 등을 확보하기 위한 중계 서버로, 클라이언트와 웹 서버의 중간에 위치하여 대신 통신을 받아주는 역할을 한다.
-
Forward proxy
#Client의 설정
클라이언트 대신 프록시 서버가 목적 서버에 통신해주는 구성
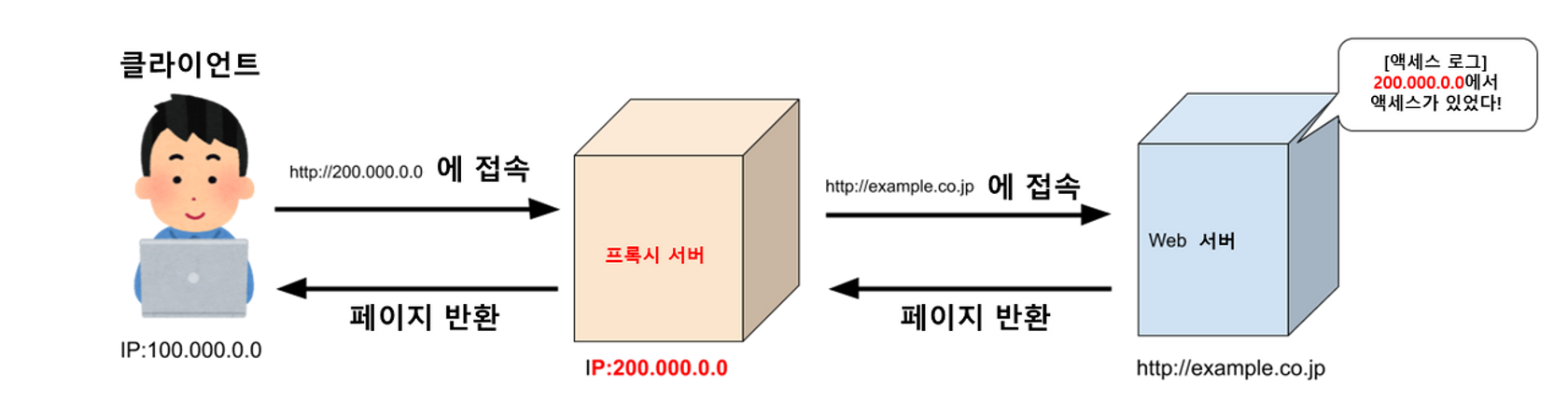
프록시 서버가 외부 Web 서버와 통신하여 클라이언트는 프록시 서버만을 통해서 정보를 얻게 된다. 따라서 Web 서버 쪽에는 프록시 서버를 통한 액세스 로그가 남는다.
또한, 포워드 프록시의 경우, 어떤 프록시 서버를 경유하도록 할지 클라이언트가 설정할 수 있다.
*Windows10 -
[Winodws 메뉴] > [설정] > [네트워크와 인터넷] > [프록시]에서 설정👍 장점
-
캐시 저장(액세스 고속화)
프록시 서버에 캐시를 저장하여 다시 동일한 페이지를 요청한 경우에 캐시에 남아 있는 정보를 클라이언트에 줌으로써 시간을 절약할 수 있다.
-
URL 필터링
외부의 액세스는 프록시 서버를 경유하므로 사용자 전원의 외부 웹 사이트로의 액세스를 필터링할 수 있다. 접근이 제한된 페이지로 요청을 시도할 때 에러용 페이지가 표시되는 등 설정에 따른 화면이 표시되고 요청에 실패한다.
-
-
Reverse proxy
#Server의 설정
Web Server 쪽에 위치하여 클라이언트의 접근을 최초로 받아 Request에 해당하는 Web Server에 배분해주는 역할
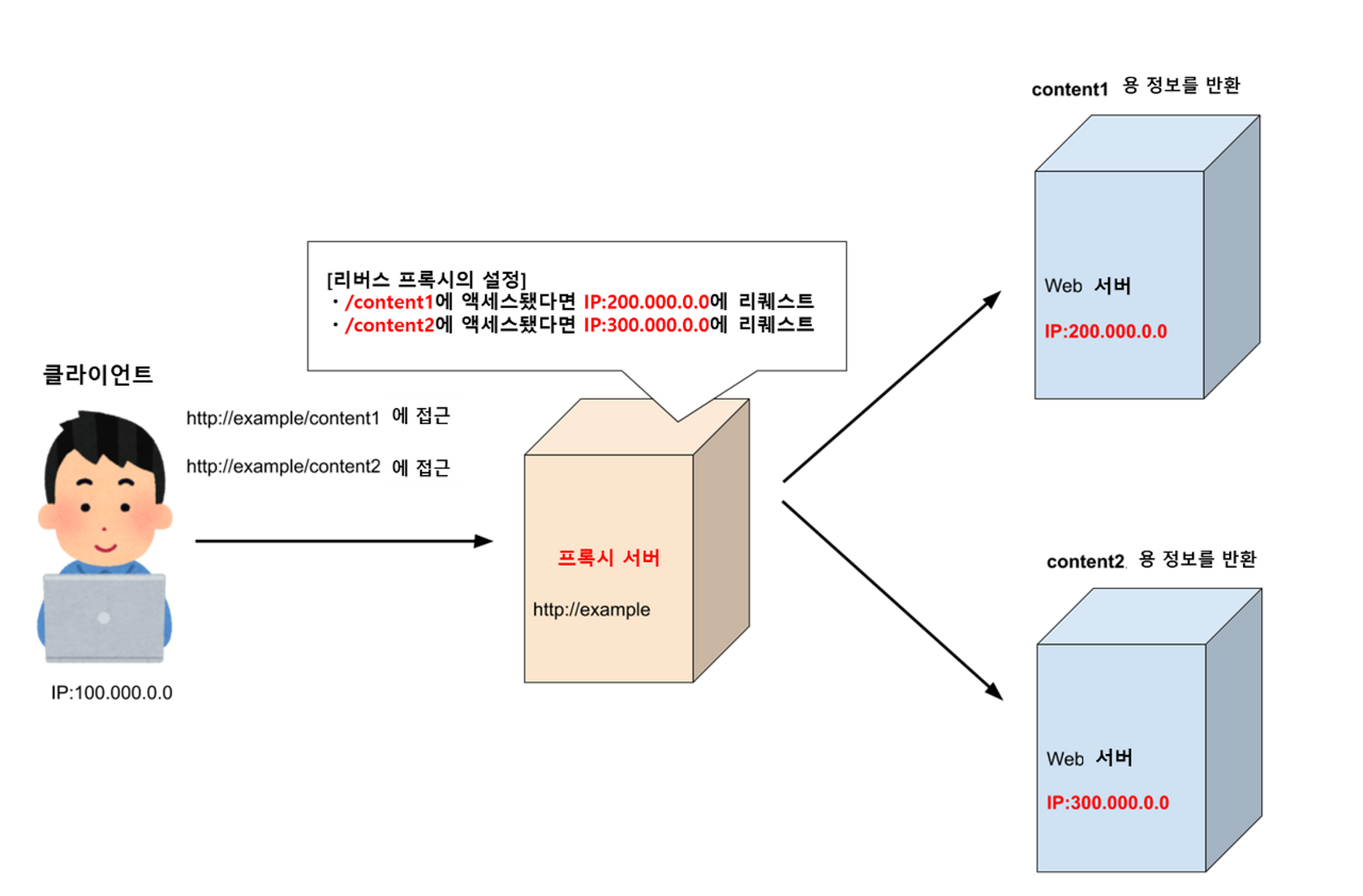
클라이언트에서 액세스를 프록시 서버에 집약해서 URL에 따라 Request를 받을 Web Server가 바뀌도록 설정한다. 클라이언트의 입장에서는 프록시 서버가 Web 서버와 같은 동작을 하므로 여러 개의 서버가 존재한다는 것을 알지 못한다.
👍 장점
-
부담 분산
설정으로 정적 콘텐츠와 동적 콘텐츠의 보는 곳을 나눔으로써 메모리 사용량의 효율화를 할 수 있다.
- 로드 밸런스와 병용하면 더욱 부담을 분산할 수 있다.
cf. 로드 밸런싱이란? 서버가 처리해야 할 업무, 요청을 여러 대의 서버로 나누어 처리하는 것 → 라운드로빈, IP 해시 방식, 최소 연결, 최소 응답시간 방식 등으로 구현 가능
- 로드 밸런스와 병용하면 더욱 부담을 분산할 수 있다.
-
캐시의 저장
포워드 프록시와 마찬가지로 동일한 데이터를 얻을 때 프록시 서버가 저장했던 내용을 돌려준다.
-
Security&Virus 대책
통신 시 프록시 서버에 집약되므로 프록시 서버 내에 Security 대책과 Virus 대책을 구현하여 Web 서버로의 부정 액세스 및 사용을 방지할 수 있다.
*참고 자료
프록시(Proxy)란? -
JPA의 프록시 객체
프록시는 ‘대신하다’의 의미로, 동작을 대신해주는 가짜 객체의 개념으로 볼 수 있다. 스프링에서는 초기화를 지연 시켜주거나 트랜잭션을 적용하는 등의 부분에서 프록시 기술을 사용한다.
가장 많이 사용하는 JPA 구현체인 하이버네이트(Hibernate)는 프록시 객체를 통해 지연로딩을 구현하는데, 이를 통해 불필요한 데이터 조회를 방지할 수 있다. 지연로딩이란 연관된 엔티티의 객체를 실제 사용하는 시점까지 데이터베이스 조회를 미루는 것을 말한다. 지연시키는 과정에서 불필요하고 무의미한 값을 넣어서는 안되므로 하이버네이트는 지연 로딩을 사용하는 연관관계 자리에 프록시 객체를 주입하여 실제 객체가 들어있는 것처럼 동작하도록 한다.
🧐 실제 엔티티 객체 VS 프록시 객체의 차이점
- [예시] User Entity Class
import lombok.AccessLevel; import lombok.Builder; import lombok.Getter; import lombok.NoArgsConstructor; import javax.persistence.*; @Entity @Getter @NoArgsConstructor(access = AccessLevel.PROTECTED) public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; @Column(nullable = false) private String nickname; @Column(nullable = false) private String email; @Column(nullable = false) private String password; @Builder public User(String nickname, String email, String password) { this.nickname = nickname; this.email = email; this.password = password; } } em.find(): 실제 엔티티 객체 조회
em.find()로 User를 조회하면 아래와 같은 쿼리가 데이터베이스로 바로 나가게 된다.User user = new User(); em.persist(user); // DB에 새로 생성한 User 객체 저장 User user = em.find(User.class, user.getId()); // 저장된 객체 조회Hibernate: /* insert sopt.org.User */ insert into User (id, nickname, email, password) values (null, ?, ?, ?) Hibernate: select user0_.id as id1_4_0_, user0_.nickname as nickname2_4_0_, user0_.email as email3_4_0_, user0_.password as password4_4_0_, from User user0_ user0_.id=? findUser.id = 1em.getReference(): 가짜(프록시) 엔티티 객체 조회 하지만, 이 메서드로 User를 조회하면, 바로 쿼리가 나가는 게 아니라 실제 필요한 시점에 데이터베이스로 쿼리가 나가게 된다. 또한, 실제 User 클래스 타입이 아닌 하이버네이트가 강제로 만든 가짜 클래스인 HibernateProxy 객체로 저장된다.
*엔티티 간 연관관계 조회에 대해 즉시로딩으로 지정해주려면?Hibernate: /* insert sopt.org.User */ insert into User (id, nickname, email, password) values (null, ?, ?, ?) **findUser = class sopt.org.User$HibernateProxy$usdlsOwE findUser.id = 1** Hibernate: select user0_.id as id1_4_0_, user0_.nickname as nickname2_4_0_, user0_.email as email3_4_0_, user0_.password as password4_4_0_, from User user0_ user0_.id=?fetch=FetchType.EAGER붙이기
프록시 객체의 초기화
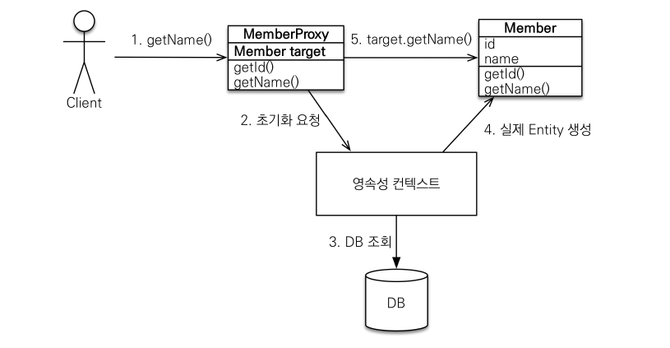
- em.getReference()로 프록시 객체를 가져온 다음, getNickname() 메서드를 호출하면 UserProxy 객체에는 처음에 target 값이 존재하지 않는다.
- JPA가 영속성 컨텍스트에 초기화 요청을 보낸다.
- 영속성 컨텍스트가 DB에서 조회를 하여
- 실제 Entity를 생성해준다.
- 프록시 객체가 참조값으로 가진 target(실제 User)의 getNickname()을 호출하여 결국 user.getNickname()을 호출한 결과를 얻을 수 있다.
- 프록시 객체에 target이 할당되고 나면, 더 이상 프록시 객체의 초기화 동작은 없어도 된다. 💡 프록시 객체는 처음 사용할 때 한 번만 초기화되며, 프록시 객체가 실제 엔티티로 바뀌는 것이 아니라 target에 값이 채워져 접근이 가능해지는 것이다.
프록시의 특징
- 실제 클래스를 상속 받아서 만들어진다. (하이버네이트가 내부적으로 상속을 받음)
- ➡️ 프록시 객체의 타입 ≠ 원본 객체의 타입
- 타입 비교를 하려면
instanceOf를 사용해야 한다. * == 비교는 false를 반환!
- 실제 클래스와 겉모양이 같다. ⇒ 사용하는 입장에서는 진짜 객체와 프록시 객체를 구분하지 않고 사용하면 된다.
- 프록시 객체는 실제 객체의 참조(target)를 보관한다.

- 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드를 호출한다.
*참고 자료
ORM의 장단점
ORM이란?
Object-Relational Mapping
객체와 관계형 데이터베이스 간의 매핑을 지원해주는 도구로, 관계형 데이터베이스와 객체 사이의 패러다임 불일치 문제를 개발자 대신 해결해주는 역할을 하여 보다 정교한 객체지향 프로그램을 개발할 수 있도록 한다.
👍🏻 장점
- 완벽한 객체 지향적인 코드 ⇒ 직관적인 이해가 쉽고 비즈니스 로직에 집중할 수 있도록 도와준다. 기존의 객체지향적 접근+SQL의 절차적/순차적 접근이 혼재된 방식보다 오직 객체지향적 접근만 고려하면 되는 방식이 생산성이 높고, 객체지향의 특징을 가져와 코드의 가독성도 높아진다.
- 재사용 및 유지보수의 편리성이 증가한다. (∵ ORM을 통해 작성한 객체의 재활용 가능)
- DBMS에 대한 종속성이 줄어든다. 객체 간의 관계를 바탕으로 SQL문을 자동으로 생성하고, 객체의 자료형 타입까지 사용할 수 있기 때문에 오직 객체에만 집중할 수 있고 자바의 기능을 자유롭게 이용할 수 있으며, DBMS를 교체하는 등의 작업에 드는 시간이 줄어든다.
👎🏻 단점
- 완벽한 ORM으로만 서비스를 구현하기가 어렵다. → 적절히 SQL문을 사용할 수 있어야 한다.
- 프로시저가 많은 시스템에서는 ORM의 객체 지향적인 장점을 활용하기 어렵다. → 쿼리문이 복잡해질수록 오히려 SQL문의 사용이 직관적이면서 효율적일 수 있다.
*참고 자료
@DynamicUpdate
실제 값이 변경된 컬럼으로만 update 쿼리를 만드는 기능의 어노테이션
필요성
JPA를 사용하면 엔티티의 상태를 변경해주는 것만으로 update 쿼리를 실행시키게 되는데, 이때 발생하는 update 쿼리는 모든 컬럼을 대상으로 한다. 즉, 위 User 클래스에서 nickname만 수정하고 싶은데 쿼리 상으로는 password, email 필드까지 모두 날아가는 것이다. 이는 더티체킹이 이루어졌기 때문이다.
Hibernate: update user set nickname=?, password=?, email=? where user_id=?상태 변경 검사. Transaction 안에서 엔티티의 변경이 일어나면 변경 내용을 자동으로 데이터베이스에 반영하는 JPA의 특징이다.
JPA는 엔티티 매니저가 엔티티를 저장(persist)/조회(find)/수정(?)/삭제(delete)를 하는 기능을 제공한다. 이때 수정(?)에 해당하는 것이 바로 더티 체킹을 지원하는 부분이다.
- ‘변화가 있다’의 기준 - 최초 조회 상태
- 데이터베이스에 변경 데이터를 저장하는 시점: ①Transaction commit 시점 ②EntityManager flush 시점 ③jpql 사용 시점
*참고 자료
이때 @DynamicUpdate 어노테이션을 달아주면 정상적으로 변경 컬럼에 대한 update 쿼리만 날린다. 이는 JPA 스펙이 아닌 하이버네이트 기능으로, 필드 수준의 추적이 필요하므로 엔티티 객체의 변경에 대한 추적에서 더 나아간 것이다.
언제 사용?
- 컬럼이 많을 때
- 테이블에 인덱스가 많을 때
- 데이터베이스가 컬럼 락을 지원할 때
- 데이터베이스가 컬럼 버저닝을 지원할 때
- 다양한 컬럼에 대해 동시성 이슈가 발생할 때
*참고 자료
