

Week 0 Scratch
This course is intended for students who have never coded before. The post may be elaborate due to the reason.
🧩 What I Should Learn?
- Scratch - visual programming language tool
- "Hello World" in C and Python
- Memory
- Buggy code and what causes computer crashes
- Basic data structure - hash table
🎯 What I learned today
Computational Thinking
Computer Engineering is not just coding but more of a problem-solving in a computational way.
As a programmer, computer engineers, and software developers, we can solve real-world problems that you might think of as a hassle in your life with programming languages.
Bug
A bug is a mistake in a program. The picture below is an actual bug in a computer in yesteryear.
- World’s First Computer Bug

Debugging is finding your mistakes or other's mistakes and improving that code.
Algorithm
The picture is a typical bar graph, and if we want to sort this bar in increasing or decreasing order, we can move short bars to the left and long bars to the right.
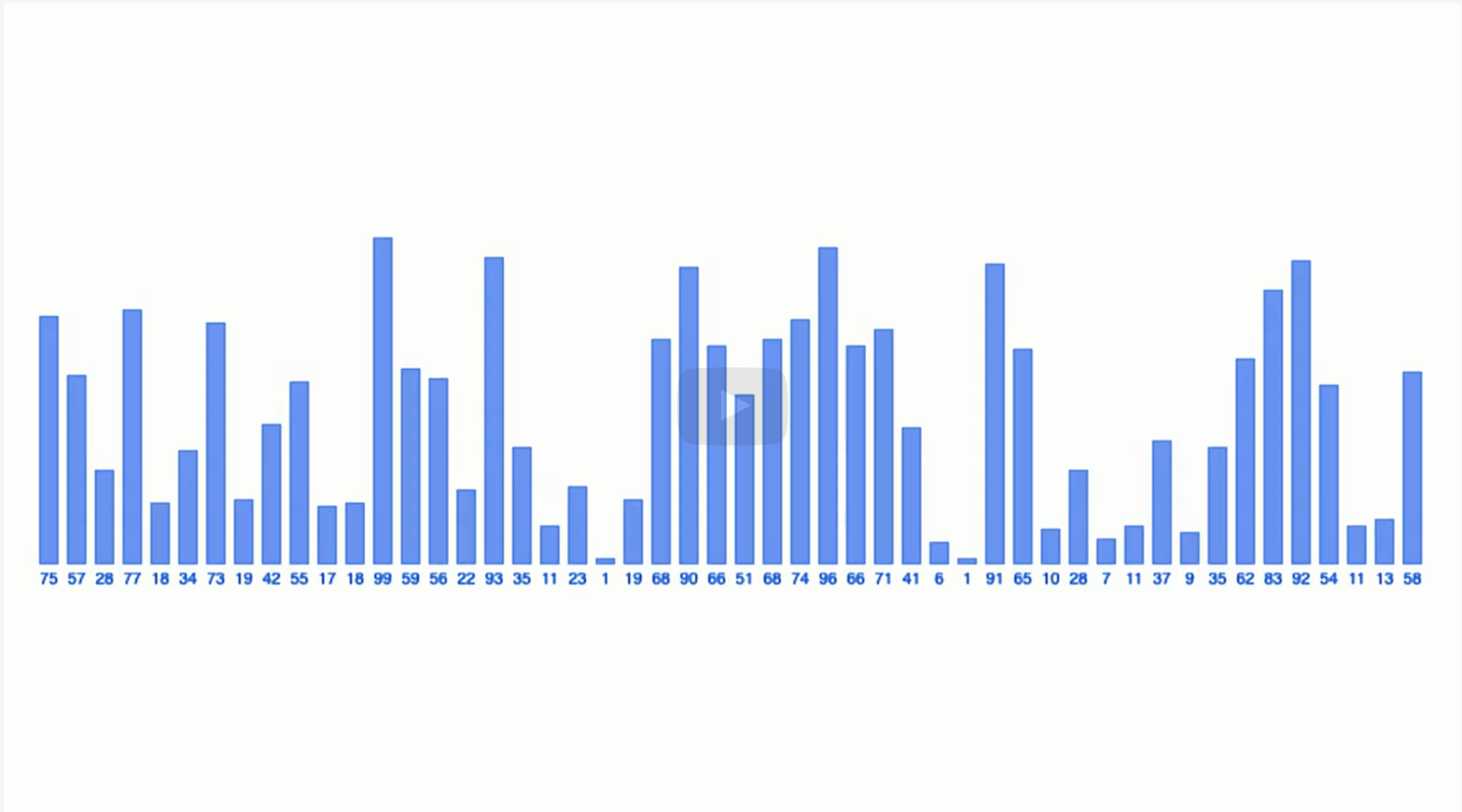
But what is the sorting algorithm there? How would you teach younger kids who don't know how to do that? How do you compel your computer to do that?
We can't just wave our hands and say move things around or figure it out yourself. We need to teach something or have some method to do so.
The problem that arises even nowadays is computer crashes. If you use a computer, phone or tablet, you must encounter spontaneous rebooting, crashing, and bluescreen and see a little gray bar spinning endlessly.
When developers from even big companies like Google, Apple, and Microsoft write buggy code, and when the computer encounters those mistakes, it doesn't know what to do, and it crashes or freezes.

The picture shows more advanced logic; later, we will learn. But to be simple, something goes down, and the other goes up, and they meet in the middle.
Let's say the heap side uses upper-side memory, and the stack side uses down-side memory. However, if they are not talking very well, that is usually what computer crash happens.
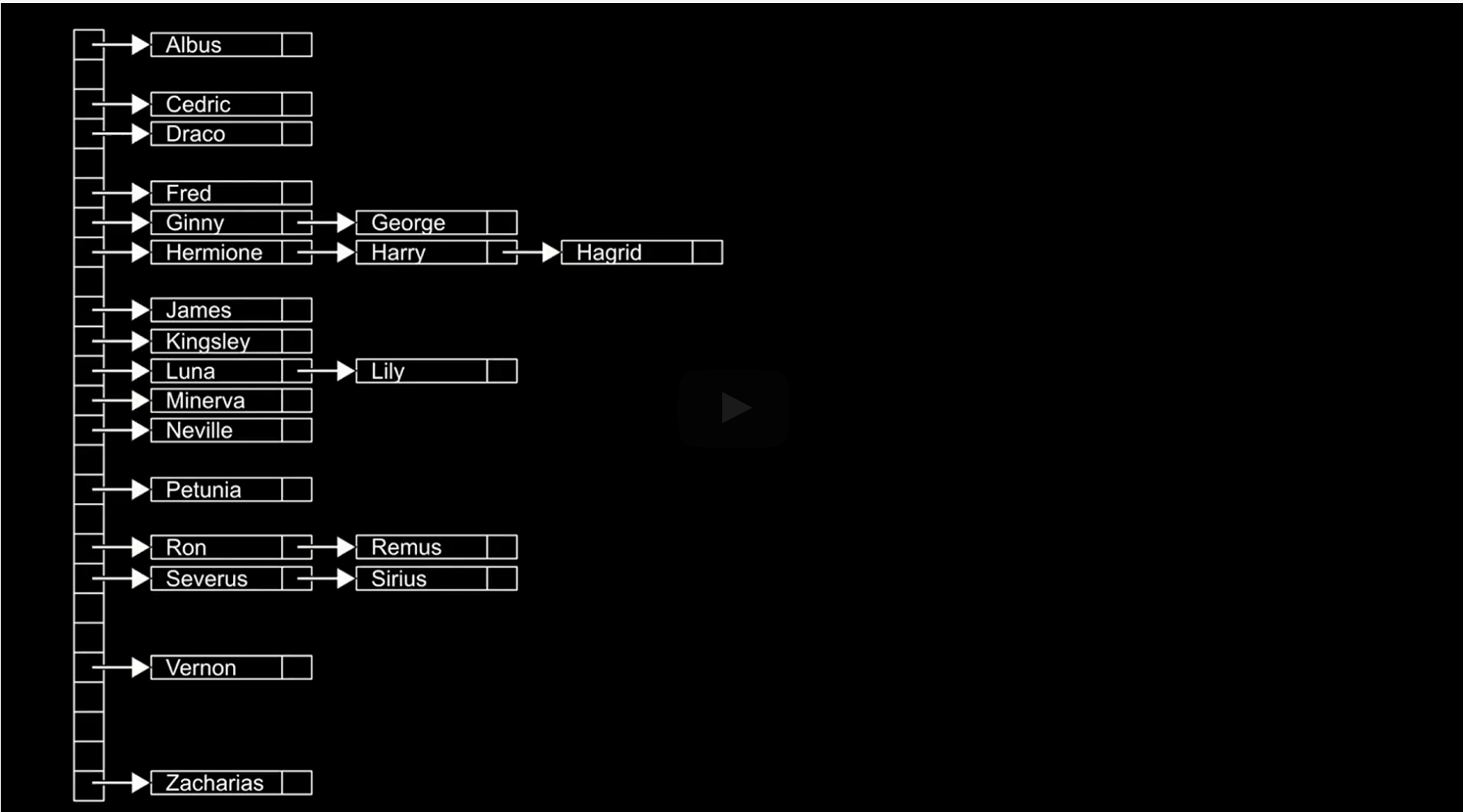
The picture above is a hash table - an amalgam of the array and linked list. We will learn this advanced topic in the middle of the course.
But in the end, this is just a fancy word for organizing information more flexibly instead of putting individual information one by one.
You might notice the names in H are from Harry Poter. If you will deliver some docs for them, how would you sort the data? They can't use the same mailbox.
It starts with the letter H, and somehow, we have to chain them in order to use the same H table. We will learn how to do that in code, which sets the data structure in a two-dimensional way.
First Code
The code below is the most famous line, and almost 99% of developers typed somewhere in their developer life - Hello world.
The below is Hello World in the programming language C.
C is a lower-level language which talks with a computer almost directly.
#include <stdio.h>
int main(void)
{
printf("Hello, World\n");
}In a few courses, we can use Python, and by using it, the three lines of code become just one line.
print("Hello, World")This is the power of higher-level language. More human-friendly and modern language, and in most cases, higher-level languages tend to slow because they interpret high to lower-level language than communicate with the computer.
Through this course, we will learn C first and then Python. It leads to a bottom-up understanding of how the bare program works under the hood.
Another thing in this course that we will learn is how we store large amounts of data. - we call this database.
Thereafter, we will transition to a familiar environment - the web.
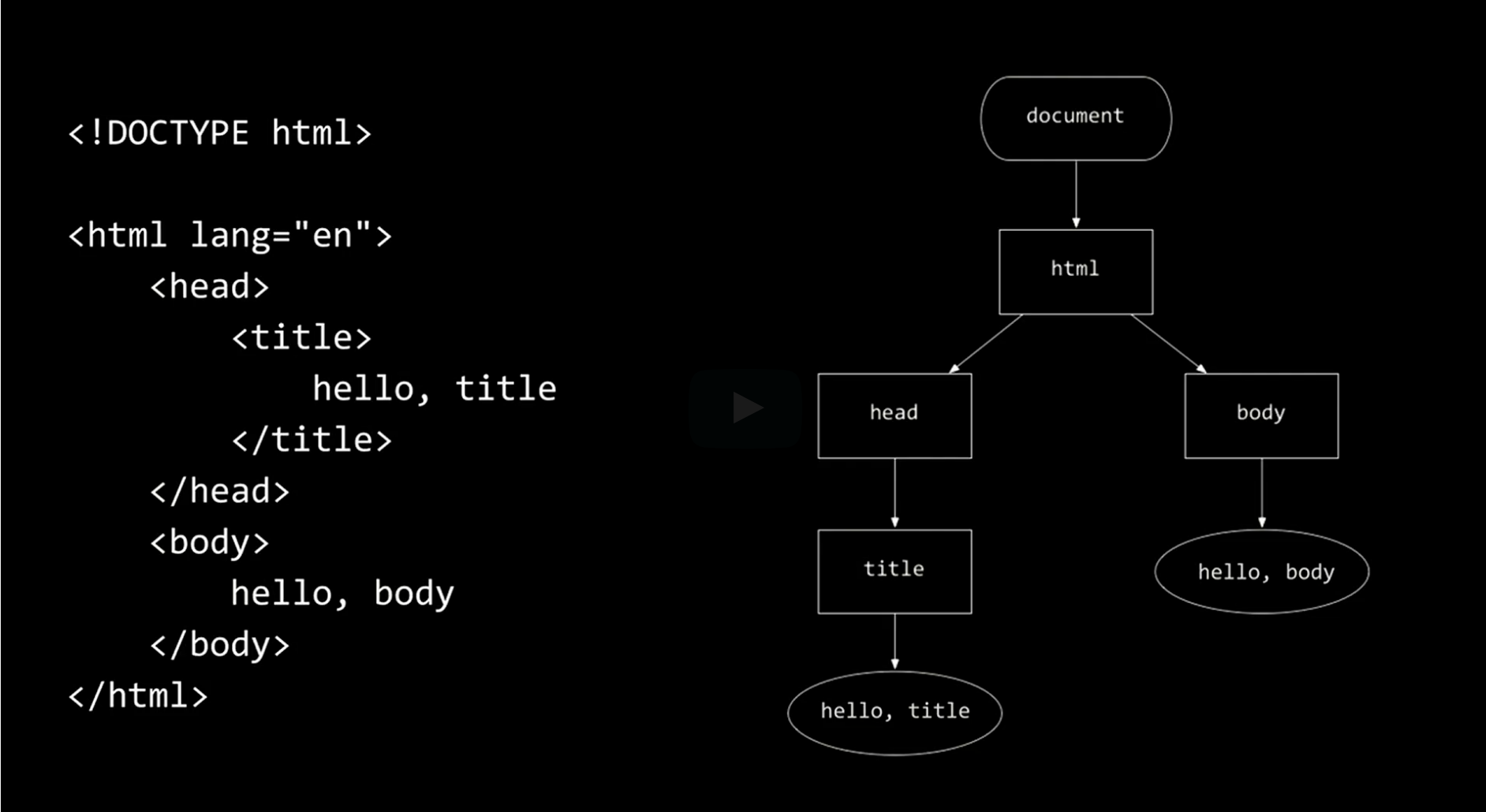
The picture is a basic structure of a language called HTML. It is not a programming language but a markup language.
We will learn how the computer sees that same code on the left and right in a tree-type structure in memory. By manipulating those trees with code, we can add more information like chat messages, etc.
Finally, we will dive into the frameworks and libraries which collaborate with all the knowledge above. Frameworks and libraries are the third-party code that makes it a lot easier to solve problems.
'''
Is computer science programming? == Somewhat
Most people who don't know about programming think that coding or programming is CS.
That is absolutely a big part of it because, with code, we can write, express ideas and solve problems.
But CS is really the study of information.
It studies how you represent and process information in computer science.
Computational Thinking == Application of ideas from CS to problems that interest you.
'''Problem Solving
So, what is problem-solving?
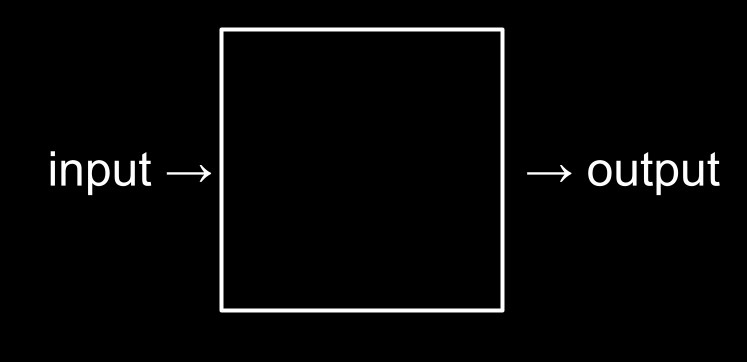
The picture above is fundamental to problem-solving. The input is the problem you want to solve, and the output is the goal.
And the black box is the secret key to getting the work done. In the next few courses, we will learn how to represent these inputs and outputs, how we code up, and how we write solutions to solve them.
Unary and Binary
Let's count the attendance for a class. We could use a system called unary, which is a fancy way of saying 1, 2, 3, 4, 5.... We can use fingers to count, maybe toes, if you want to count high numbers.
So unary is a simple system of using a single symbol, like human fingers in this case.
If we call this in more technical form, we can call it base-1.
Binary is the system that computers use, and bi- implies two.

Also, the computer often uses Bit, a smaller version of byte, which comes from Bi + t if you remove some letters from Binary digit.
Bit
A bit is just a 0 and 1. Human usually uses the decimal system, and dec- means 10, and think of the numbers we use only 0 - 9.
So, how do computers only speak in binary? How do they solve problems and represent information using only binary?
The simplest way to understand this is a lightbulb. If the lightbulb is off, it is 0, and if the lightbulb is on, it is 1.
Inside our computers, there are millions of tiny switches(think of it as a lightbulb), which, in technical terms, we call transistors.
Counting binary numbers
With only a single light bulb, we can count only 0 and 1.
How do we count more than 1? - Add more lightbulbs!

By adding two more light bulbs, we can start counting numbers.
We already know that one lightbulb represents 1
0 0 0 == 0
0 0 1 == 1If we want to count 2, 3, 4, 5, 6, 7
0 1 0 == 2
0 1 1 == 3
1 0 0 == 4
1 0 1 == 5
1 1 0 == 6
1 1 1 == 7These numbers represent 4, 2, 1, and we call it base-2, and this is the concept of binary.
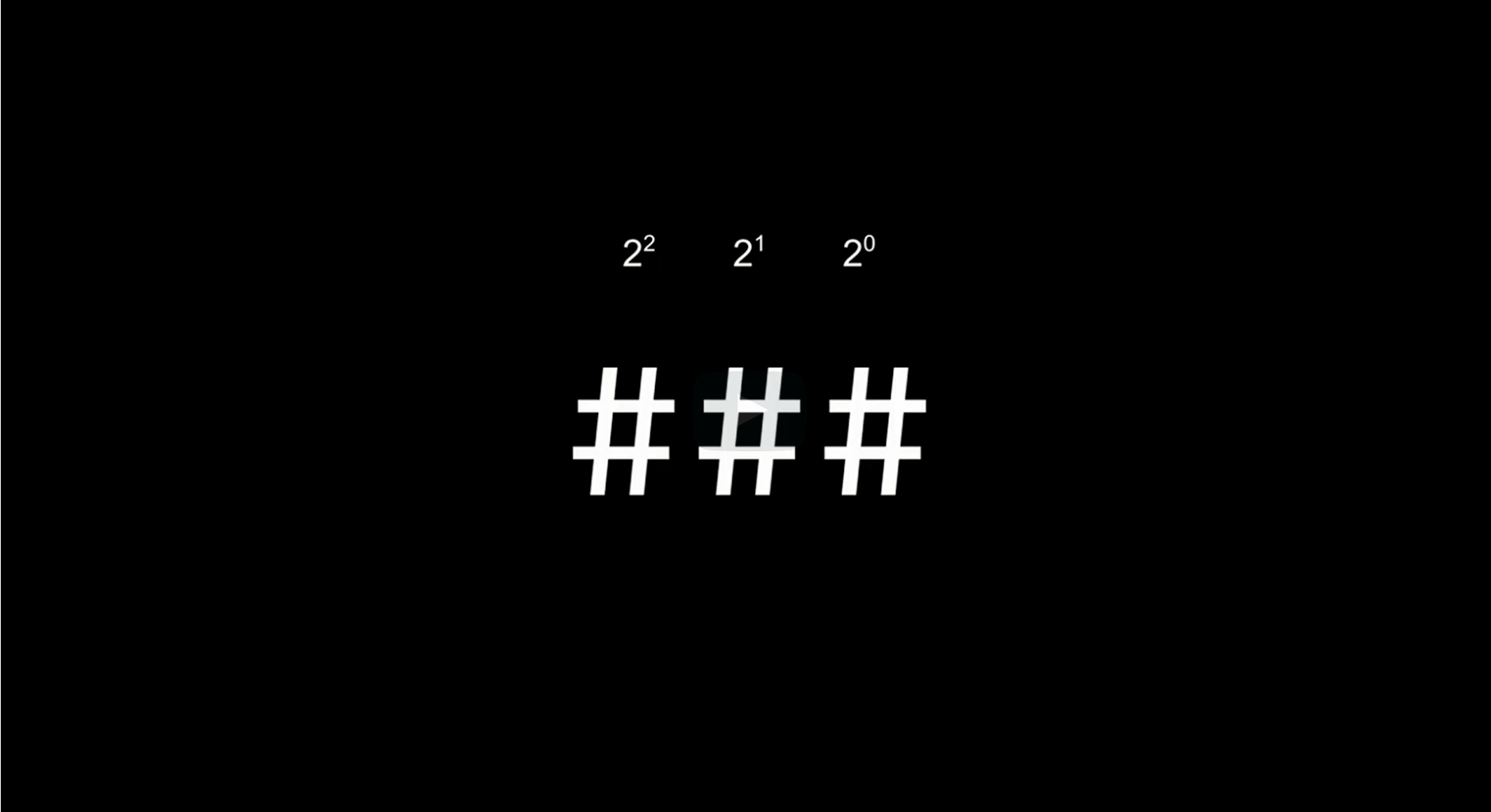
If we think of 123, that is 100 + 20 + 3 and in a more mathematical form, that can be the following:
10^2 + 2*10^1 + 3*10^0In this sense, we can think why six is 110 in binary number as the computer transistor only has on and off.
Bytes
A single byte has 8 bits, and if you ever download music, photographs or even games, those are measured in bytes.
| Measure | Bytes |
|---|---|
| Kilo- | 1000 |
| Mega- | 10^6 |
| Giga- | 1e+9 |
Computers typically use eight 0s to represent the number 0, and if the same computer uses all of those eight bits, it's a full byte, and that is the highest number that the computer can count with a byte(eight 1s), which is 255.
1 1 1 1 1 1 1 1
128+64 +32 +16 +8 +4 +2 +1 = 255
# ignores the negative numbers for nowText
ASCII
So, we learned that your Mac, PC, and mobile devices just have lots of transistors that you can use in units of 8, which are the units of bytes.
Also, we learned how to represent the numbers with ones and zeros, but how are we supposed to represent the letters like A, B, C?
We can't just steal a number's seat and declare 0 is A. In terms of solving the issue here, the Americans came up with this solution, ASCII - the American Standard Code for Information Interchange.
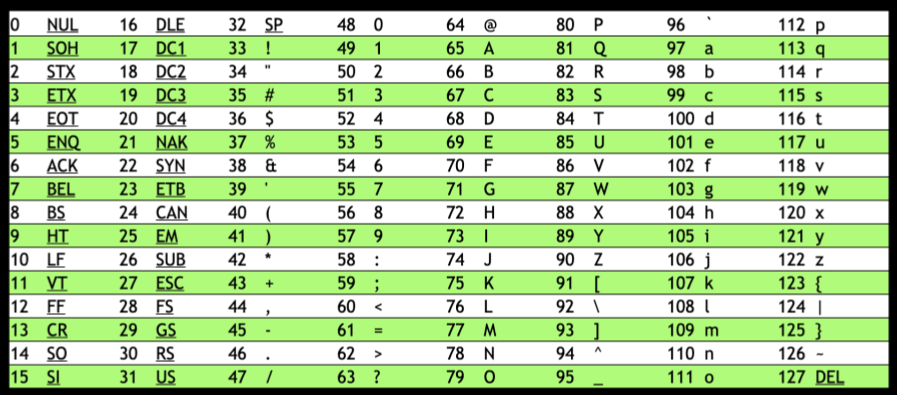
The ASCII was created to map specific letters and numbers to represent. And nowadays, all of the devices, including your PC or laptop, use this standard.
If you look at the middle of the table, the letter A is 65, which is 01000001 in binary. Imagine you received a text message, and the binary represents the numbers 72, 73, 33.
Mapping these out in ASCII, your message would be like this:
72 73 33
H I !Unicode
Is that all we need to know, and now we can start texting each other? Somewhat, but only in some cases.
If you are from a foreign country and using their languages, your precious daily languages are not in ASCII. If you are a big-time texter, we are missing one more important part these days - emojis.
But there is a problem, which is the ASCII uses roughly 8 bits to represent the letters. It means ASCII can represent as many as 256 total characters(including 255 + 1(if all turned off)).
Indeed, it is not enough letters to represent many different human languages and emojis. Since there were not enough digits in binary, the Unicode standard expanded the number of bits that can be transmitted and understood by computers.
In short, we threw hardware at the problem and used a few more bits. Instead of using 1 bit, we will use 2, 3, or 4 bits. Even though it's getting expensive, we are going to 8 to 16, 16 to 32 bits.
Thankfully, we have so much memory these days that we can spare a few to represent these things.
The Unicode is also just a mapping for numbers to letters, but it is in many different languages, including emojis.
It turns out that if we start using 32 bits to represent characters on a keyboard, that's approximately 4 billion possible permutations of 0s and 1s (2^32 == approx 4e9).
That means we have more space than we need for most human languages, and there's room for some of those playful things like emojis.

Here is our most popular emoji by many measures, and it actually looks slightly different on Android. Then, we might think the emojis are images, but they are not.
They are characters defined in Unicode. An IOS, Android and Windows just have different fonts. Yes, the fonts with English and other languages like Serif or whatnot can give you different styles of letters.
So, the same pattern of 0s and 1s might rendered slightly differently on someone's phone or another. In the same case, if you ever get a broken icon, that is square or something arbitrary. It might mean that you have not updated to the latest version of the IOS or Android, but they have updated the fonts of supported emoji.
The Unicode Consortium nowadays adds more and more features to their character set, such as skin tones and combined emojis 👪.

Here is a little question for you: how did companies like Microsoft, Apple, Google and others implement support for emojis with different skin tones?
You might have come up with five different patterns that are identical, structurally, except for the skin tone. But it's a little inefficient just to copy and paste five times.
Well, the fact is that the Unicode decided to use the first byte or bytes you receive via text or email to represent the structure of the emoji, the default yellow version.
And it's immediately followed by a certain pattern of bits that you or the user's setting. Then, the phone, the Macbook or the PC will change the default color to an apt personal human tone.
So, it uses twice as many bits, and we don't have to use five times as many bits because we don't have five distinct patterns per se.
If we come back to these emojis, 👩❤️👨 👨👧👧
These consist of one set of bits for a character in each section. Three different sets of bits are assembled to make more complicated emoji compositions by reusing those same patterns and bits.
RGB
It may sound familiar to people who are interested in art or Photoshop. RGB stands for red, green, and blue, and it is a combination of three numbers.
72 73 33
H I !Taking three numbers from the above, which was Hi! in text, would be interpreted by image readers as a dark yellow.
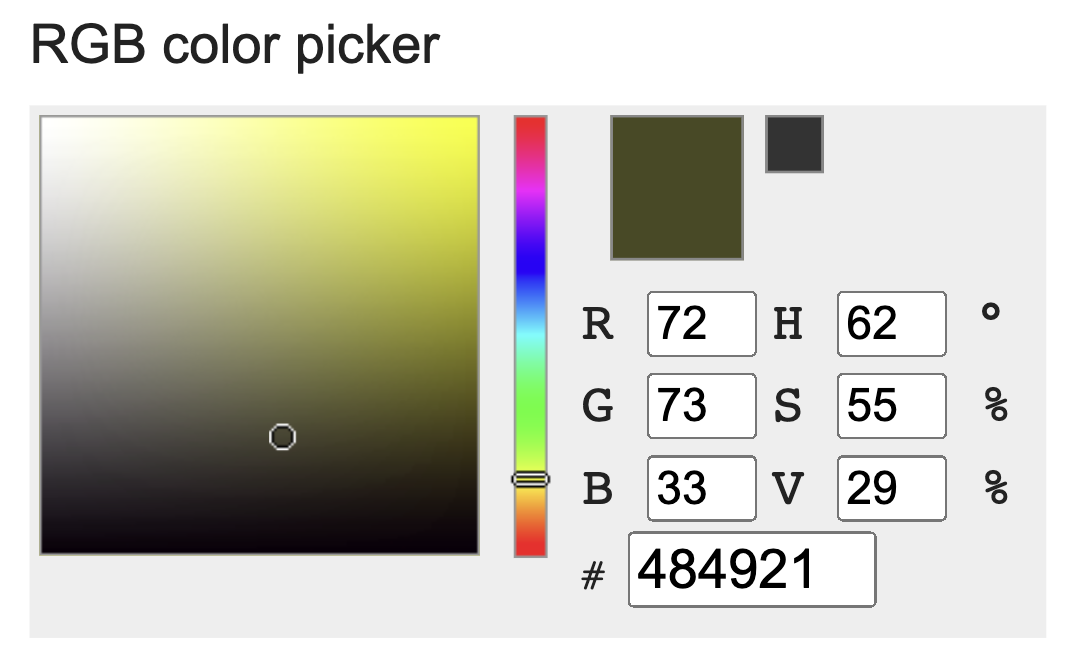
Actually, we have seen this color. Where did we see this? When we type the emoji - the face with tears of joy 😂.
If we zoom in on the emoji, what do we see from the image?

It is a pixel, and we call it pixelated. A pixel is a dot on the screen, and if we zoom in, we can see all of the dots that compose an emoji.
Each dot or pixel in the image is 3 bytes(==24bits), which measures how much red, green, and blue for each dot.
Underneath the hood, this is why the images, photographs or gifs are darn big, potentially because you have a number representing every dot on the screen.
Similarly, the video is, at the end of the day, all we have is 0s and 1s, the pixels changing values over time. In other words, it is a sequence of images over time.
This video is the analog way to implement a video
In the old days, artists wrote hundreds of pieces of paper with almost identical images. But the ink from their pencil or pen is slightly moving. And if we digitize this, each of the touches is represented with dots instead.
In the real world, the film, like a Hollywood movie, is typically 24FPS, Frames Per Second. That means we are seeing 24 images per second, or on TV, it's often 30FPS. That makes things look more smooth.
It's a sequence of pictures, and our brain and mind are interpolating that as a smooth movement even though we are seeing a lot of pictures fast.
Also, the sound can be represented by each note over time as some sequence of values. There are many different ways to do this, but generally, we use MIDI, MP3, or AAC. Those are all file extensions you see on your PC, which means different forms of representation, like sound in this case.
Algorithms
Driving cars
Have you ever driven a car or been in a car? The concern you have is probably an abstraction. Most of us don't really know or care how the engine works and all the parts that are moving. For us, a car is just a transportation to get you from point A to point B.
That is an abstraction of a car, but someone, the mechanic, will have to know the lower-level implementation details. If we have to think about how the car works every time we drive, nobody will use the car.
The same happens in code. We want to think and operate at a higher level of abstraction, which is what we do when writing code and solving problems.
Again, this picture's black box means abstraction and generally what a computer scientist calls an algorithm - step-by-step instructions for solving problems.
Search Phonebook
Now, we know that problem-solving is central to computer science and computer programming. But what is the implementation detail of searching for a name in a phonebook?
Imagine an old phonebook that has some yellow pages. If we want to find a name like John Harvard, how do we approach it?
One approach could be to read from page one and page to page until we find John Harvard. We might count two pages at a time, but it's not much different.
A final and perhaps better approach could be to go to the middle and decide if the name on the page is to the left or to the right.
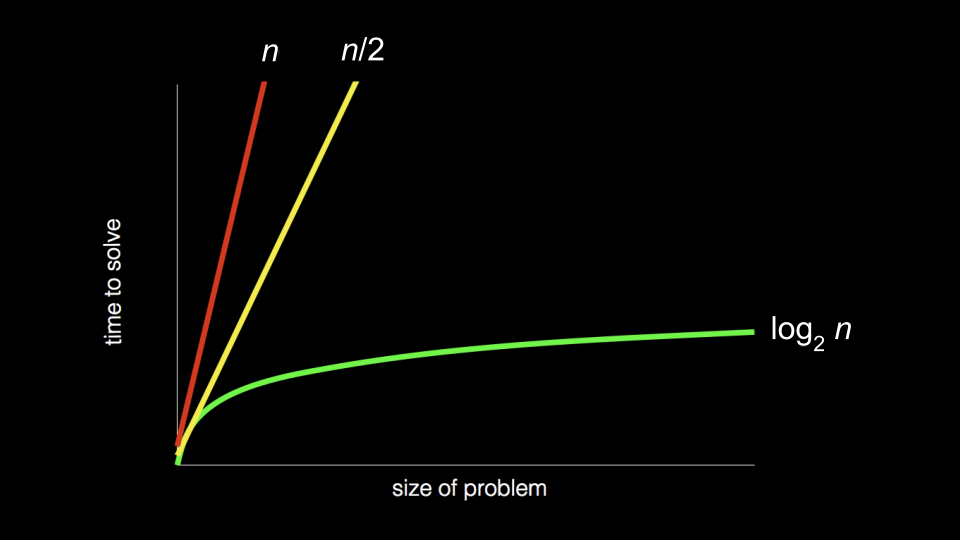
We can call each of these approaches an algorithm, and the above picture represents the speed of each algorithm. The speed of each algorithm is called big-O notation.
The first red graph has a big-O of n. If the phonebook has 1000 pages, it could take up to 1000 tries to find the correct name.
The second yellow graph has a big-O of n/2, which is twice as fast because the algorithm searches two pages simultaneously.
The final graph has a big-O of log2n. Even if the phonebook doubles the pages, the algorithm only results in one more step to solve the problem.
If the phonebook or your phone has few contacts, the choice of searching method probably doesn't matter. But think about Google or Amazon, or you are analyzing a large amount of data sets. Indeed, the previous algorithm is going to boost your speed.
Pseudocode
The algorithm is ready, but how am I supposed to write the actual code for the algorithm? In many cases, before writing the code, we translate the algorithm verbally.
The pseudocode is a human-readable language version of your code. Like, jot down the outline for the ideas.
For example, in the above phonebook algorithm, we could compose pseudocode as follows:
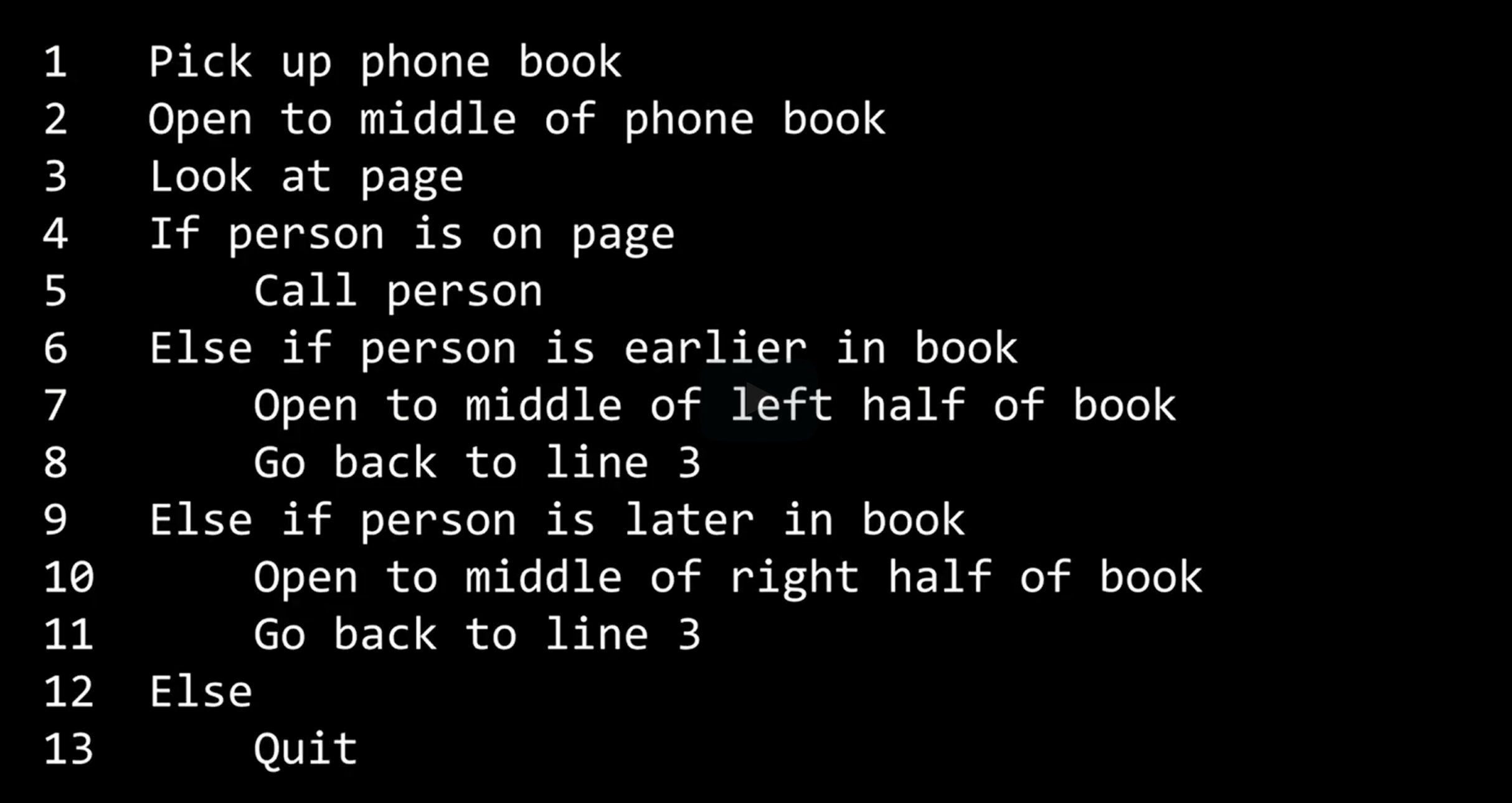
Notice that the language within our pseudocode has some unique features and patterns.
First, some of these lines begin with verbs like Pick up, Open, Look at, Call. Later, we will call those verbs functions.
When you program or write code, and you want that program or computer to do some action, we will refer to those actions or verbs as functions.
Second, the lines include statements like if or Else if or Else. These are called conditionals - A proverbial fork in the road where you can either go this way or that way.
Third, notice how there are expressions that can be answered as Yes or No or True or False, such as Person is earlier in the book. We call these Boolean expressions.
The Boolean expression is named by mathematician Boole, and it is just a question with a Yes/No, True/False, 0/1 answer.
The indentation is important in this case. For example, the indented line 5 implies, by convention in programming, that the program only should do line 5 if the answer to line 4 is a Yes or True.
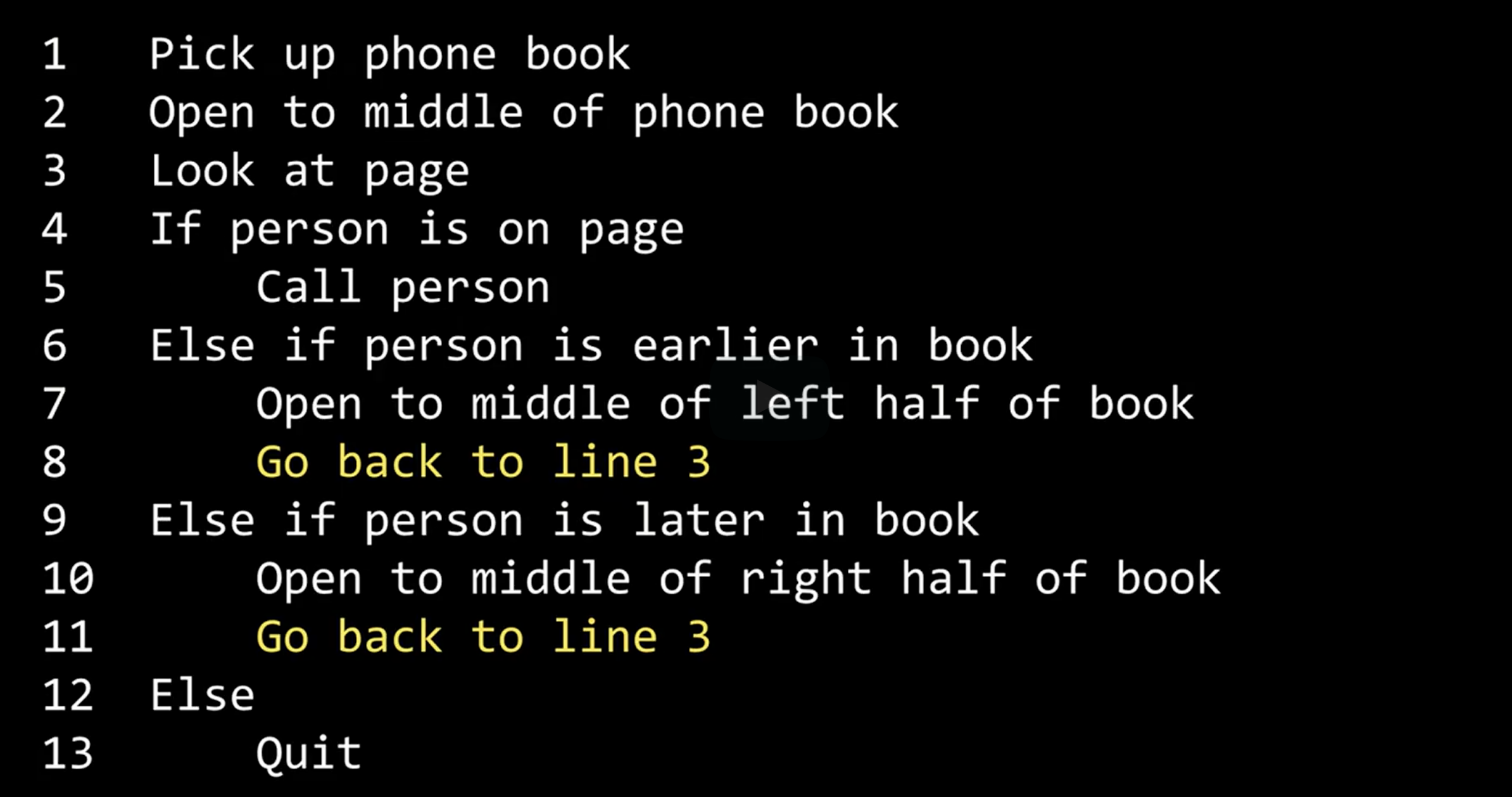
Finally, the highlighted "Go back to line 3" is some cycle that results in the behaviour repeatedly. We call these loops.
Even though there is a loop, this function eventually stops because the name we seek will be on the page or doesn't exist.
The ability to create pseudocode is crucial to one's success in computer programming. It allows us to think through the logic of the problem in advance, and we can later reference this information to those who are seeking to understand how our code works and to understand our decisions.
We will see the same ideas like functions, arguments, conditionals, Boolean expressions, loops, variables and much more.
And ultimately convert those ideas into the code in the image somehow.

Don't panic or disappoint, and this is just a hello world! And baked into all of these 0s and 1s are not just the letters but also the verbs, the action of printing something to the screen and the others.
Thankfully, we are never going to write all those 0s and 1s ourselves, but we'll be using much higher language like C.
📌 Takeaway
- Computer engineering is not just coding. A computer engineer is a problem solver who tackles daily problems with programming languages.
- A bug is a mistake in a program, and debugging is finding those mistakes to fix or improve those mistakes.
- In a pixel(or each dot), in the image is 3 bytes, 24 bits that measure the amount of red, green, and blue.
- The verbs in pseudocode are called a
function. - The letters and functions are converted into 0s and 1s, and at the bottom of the computer language like C or Python, it is composed of 0s and 1s.
💻 Solution
- None
🔖 Review
- Problem-solving is essentially creating solutions, and programmers are focusing on what happens between inputs and outputs.
- A computer uses the binary system to represent all sorts of things, from numbers to videos.
- A bit is the origin term of a binary digit and is the smaller version of byte. It is a 0 and 1.
- Counting a bit is like turning the lightbulb on and off. In technical terms, it is a transistor.
- A byte has 8 bits, and with the full byte, the computer can count up to 255.
- Nowadays, computer files are measured in bytes and have a prefix of mega or giga.
- ASCII stands for the American Standard Code for Information Interchange.
- ASCII is a mapping to specific characters and numbers to represent.
- But since it is too American-centralized and can't represent all human languages, the computer scientist created Unicode by adding bytes together.
- Unicode is the same mapping numbers to letters, but the complicated logic is handled by hardware.
- Nowadays, computers have so much memory and can use 32-bit, 64-bit. Hence, there is some room for playful things like emojis.
- The emoji is not an image but a font, which is the reason for different styles of emojis on different OS.
- RGB stands for red, green, and blue, and the combination of three numbers represents the color in a dot on the screen.
- If the picture is zoomed in, there are plenty of dots consisting of a picture, and this is a pixel.
- A video is a sequence of images over time, and if the fps, frame per second, is high, the human brain understands it as a smooth video.
- The phonebook algorithm represents how the engineer approaches the problem.
- As the engineer, the goal is to create efficient algorithms to boost the speed of algorithms for correct consequences.
- The pseudocode is a human-readable version of the code. It is a central skill for computer programmers.
- It helps to think of the code logic before the formal code creation and allows the sharing of code logic and decisions.
