
AutoEncoder란
- Unsupervised Learning
- Representation Learning
- Dimensionality Reduction
- Generative Model Learning
What is AutoEncoder?
- 입력과 출력이 같은 구조
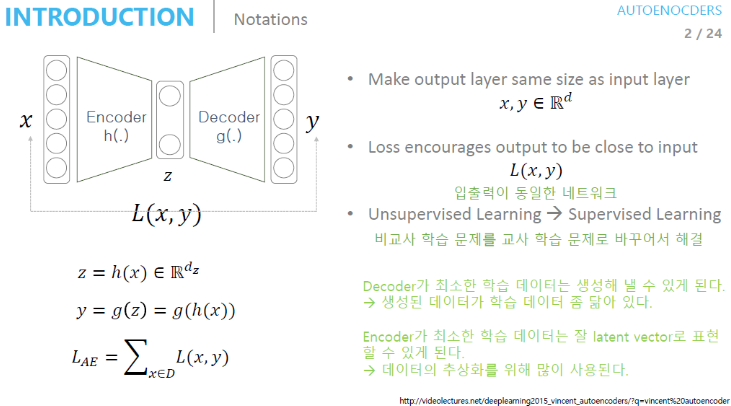
AutoEncoder의 수식과 학습 방법
- 수식
- Input Data를 Encoder Network에 통과시켜 압축된 z 값을 얻는다.
- 압축된 z vector로부터 Input Data와 같은 크기의 출력 값을 생성한다.
- 이때 loss 값은 입력값 x와 Decoder를 통과한 y 값의 차이이다.
- 학습 방법
- Decoder Network를 통과한 Output layer의 출력 값은 Input 값의 크기와 같아야 한다.
(=같은 이미지를 복원한다고 생각) - 이때 학습을 위해서는 출력값과 입력값이 같아져야 한다.
AutoEncoder 학습 후 얻을 수 있는 직관
- Encoder 관점
- 적어도 input data를 잘 복원한다.
- 최소한의 성능을 보장한다.
- Decoder 관점
- 최소한 training data를 만들어줄 수 있다.
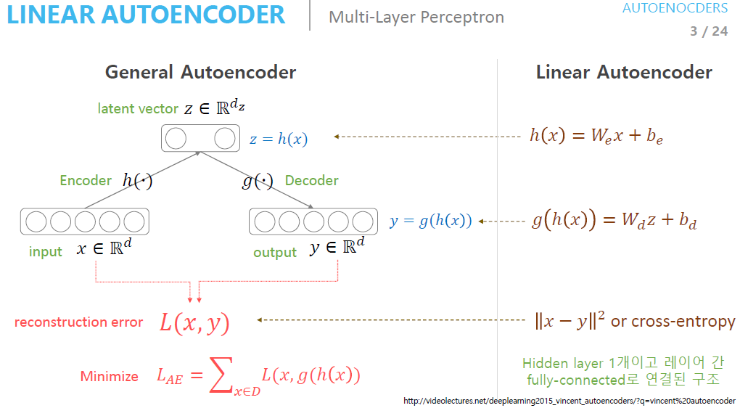
Activation Function 없이 사용하는 AutoEncoder를 Linear AutoEncoder라고 부른다.
AutoEncoder 활용 예시
- AutoEncoder는 실제로 Input Data의 feature를 추출할 때 많이 사용한다.
- 주로 Dimension Reduction에 사용한다.
- Network parameter 초기화, pre-training에 많이 사용된다.
Stacking AutoEncoder for pre-training
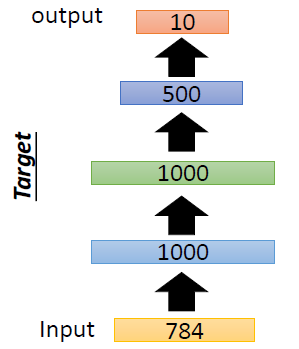
위의 AutoEncoder를 학습시키고자 한다.
AutoEncoder는 Input Data에 대해서는 적어도 복원을 잘하는 특징을 가지고 있다. 따라서 이러한 특징을 활용해 Training DB에 있는 Input Data를 잘 표현하는 weight를 학습할 수 있다.
AutoEncoder를 쌓아가며 학습을 한다고 해서 Stacking AutoEncoder라고 한다.
- 그림의 왼쪽은 학습에 사용할 AutoEncoder, 오른쪽은 pre-training을 위해 weight를 학습하는 과정
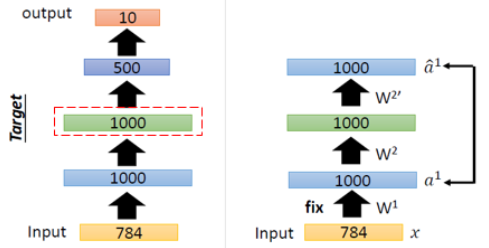
Step1
Training DB에 있는 Input Data를 잘 표현하는 1번째 layer의 1000개에 대한 weight를 학습하고자 한다. 1000개의 weight를 가진 layer를 지나 다시 Input Data를 복원하는 과정에서 데이터의 특징을 가지고 있는 weight를 학습하게 된다.
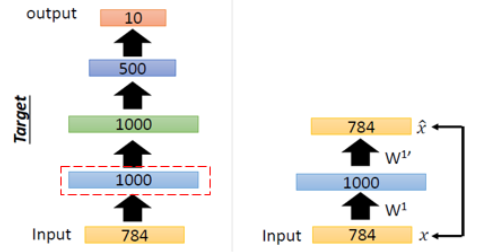
Step2
다음 layer의 weight를 학습하려면 마찬가지로 layer의 weight를 복원하는 AutoEncoder를 구성하여 Input Data를 잘 표현하는 weight를 학습할 수 있게 된다.
Step3
동일한 방식으로 마지막 layer의 weight도 학습을 할 수 있게 된다.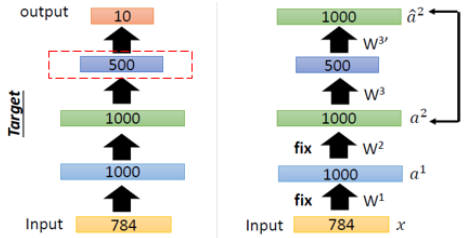
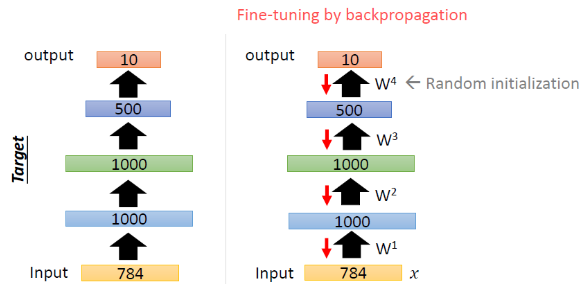
Step4
이렇게 학습이 끝난 AutoEncoder로 weight를 Initialization 해주고 모델의 학습을 위해 Backprop을 진행하면 된다.
Denoising AutoEncoder
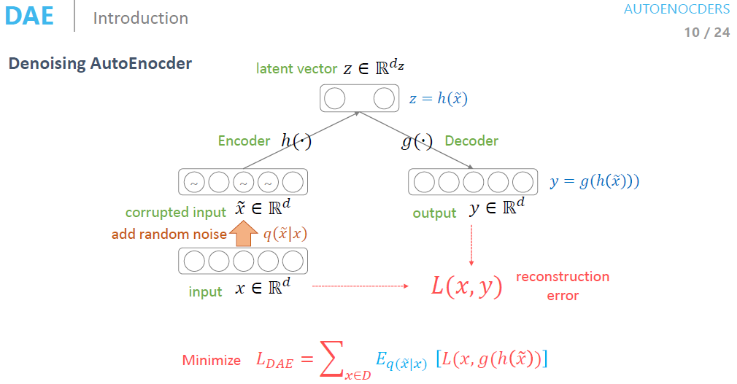
Denoising AutoEncoder에서는 Input Data에 random noise를 추가해준다. 이때 random noise라 하면 사람이 데이터에 대해 같다고 생각할 만큼의 noise를 추가해주는 것이다. 이런 noise를 추가하더라도 manifold 상에서는 똑같은 곳에 분포된다는 가정이 있다.
즉, manifold 상에서는 똑같지만 원본 데이터와는 다른 데이터로 Encoder와 Decoder를 학습하는 네트워크를 Denoising AutoEncoder라고 한다.
Denoising AutoEncoder가 AutoEncoder에 비해 Filter가 Edge를 더 잘 탐지하는 모습을 보여준다. 이를 통해 Denoising AutoEncoder가 AutoEncoder에 비해 성능이 더 뛰어나다고 할 수 있다.
Stacked Denoising Auto-Encoder
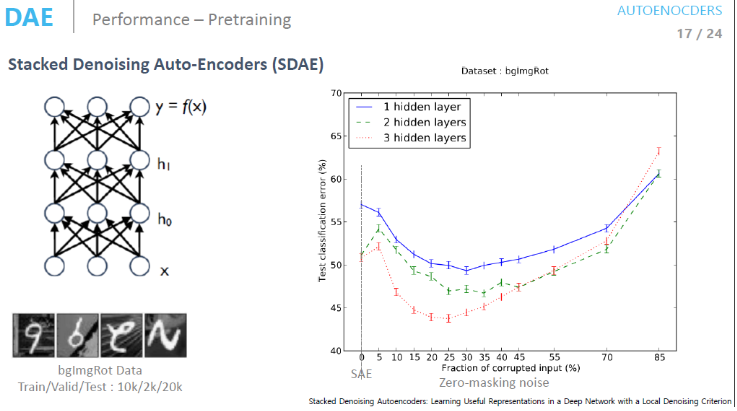
Zero-masking noise를 변경시켜가면서 학습을 해보면 noise를 더해주는 것이 Network의 성능을 얼마나 향상해주는지 알 수 있다.
그래프를 통해 알 수 있듯이 noise를 추가해주면 약 25% input에 대해 noise를 추가해 줬을 때 Loss 값이 가장 낮은 것을 확인할 수 있다.
