Summary Statistics
- 데이터의 속성을 요약하는 숫자를 의미한다.
- Summarized properties include frequency, location and spread
- Examples: location - mean, spread - standard deviation
- 데이터를 계산하는 비용이 적다.
Frequency and Mode
- frequency: 데이터의 속성에서 빈도수를 알아보는 것
- ex) 코로나 증상자 data set에서 gender 속성에 대하여, 'female’ 증상자의 frequency는 54 %이다.
- mode: 해당 속성의 frequency가 가장 높은 값을 의미
- ex) 코로나 증상자 중 가장 많은 확진자 층(mode)은 50-59세 사이의
인구층으로 18.4%를 차지한다.
- ex) 코로나 증상자 중 가장 많은 확진자 층(mode)은 50-59세 사이의
- categorical data(attribute)에 대해서 frequency와 mode를 통상적으로 사용하게 된다.
Measures of Location: Mean and Median
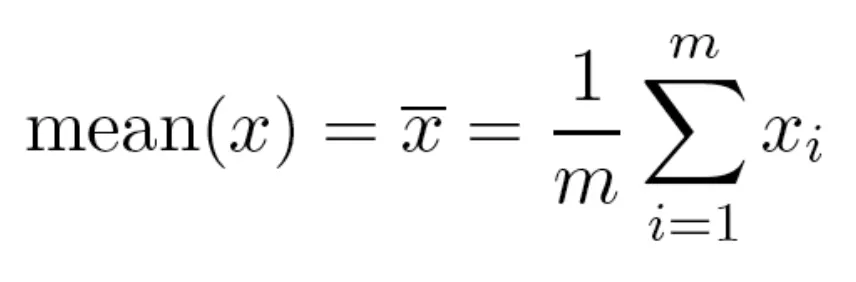
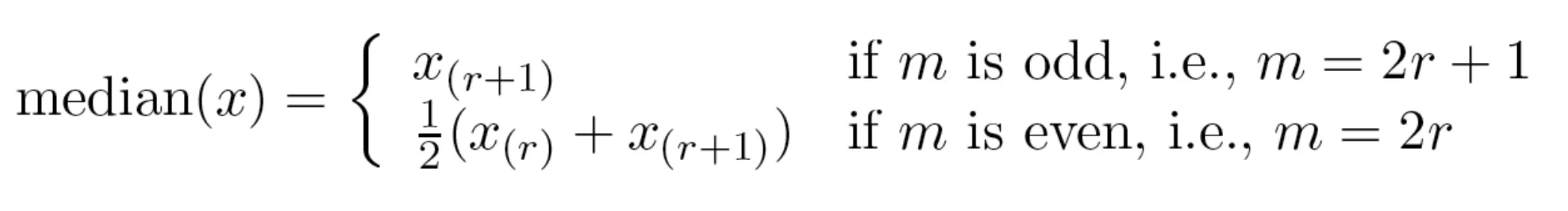
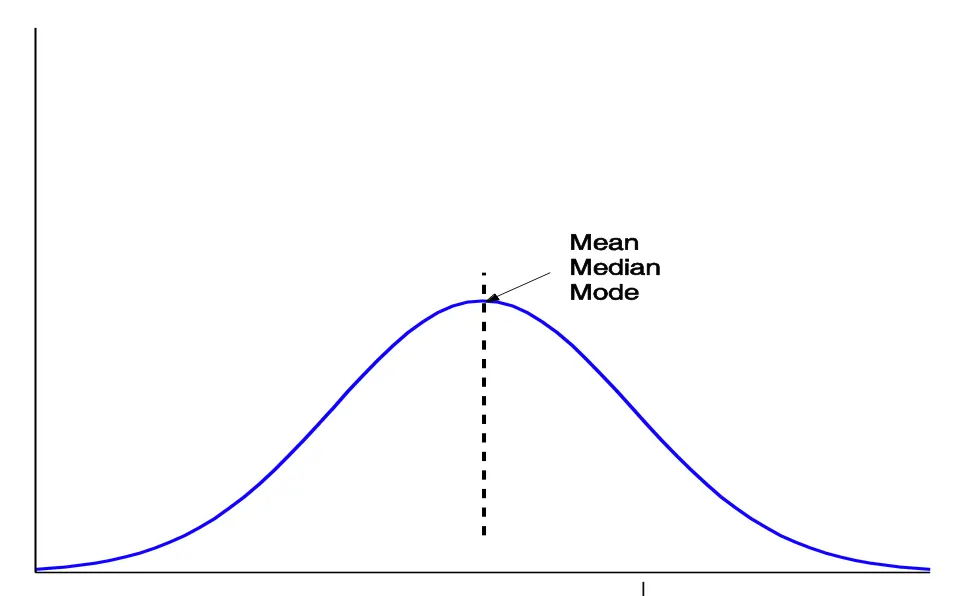
Symmetric vs Skewed Data
- Symmetric data - 좌우균형이 잘 맞은 데이터
- Skewed data - 한쪽으로 쏠린 데이터
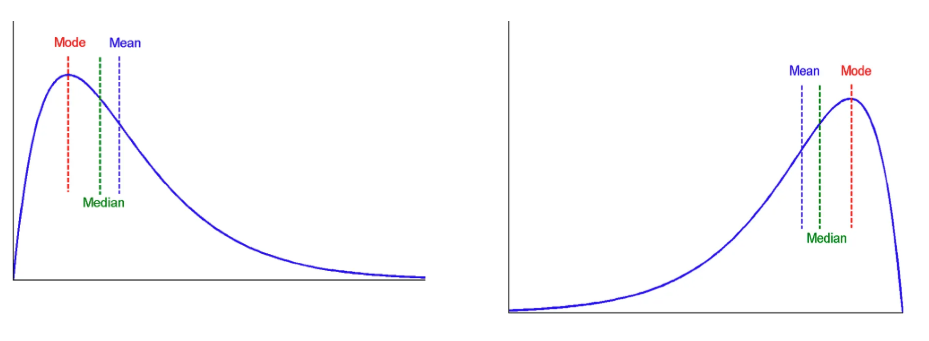
Measuring the Spread of Data
- 얼마나 퍼져있는지 알아볼 수 있다.
- Variance(분산) and standard deviation(표준편차)
- Variance: 각 data point와 data평균과의 차이를 빼서 제곱한 값을 더한 것의 평균 값
- standard deviation: 분산에 루트를 씌워 값을 줄여줌
- Percentile
- 백분위수로 알아보는 것
- ex) 하위 40%에 해당하는 값은 얼마냐
- Five number summary
- min, Q1, mean, Q2, max ← 5개의 숫자로 요약해서 spread를 알아보는 지표
- Quartiles: Q1 (25th percentile), Q3 (75th percentile)
- Outlier: 너무나 벗어나 있는 데이터를 의미
Univariate analysis (단변량 분석)
Variance
-
data point들의 spread 정도를 측정하는 가장 일반적인 방법이다.
-
분산 값도 Outlier에 의해서 약간 왜곡될 가능성이 존재한다.
→ AAD(x) - Avergae of Absolute deviation / 평균값과의 차이를 절대값을 씌워서 다 더한 후 나눔 → Outlier가 덜 작용할 수 있음
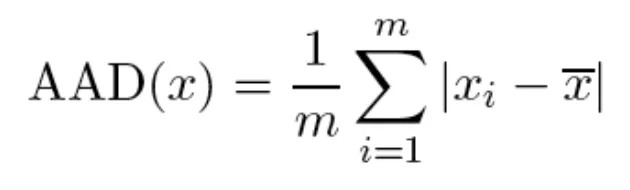
→ MAD(x) - Median of Absolute deviation / 다 더해서 1/n하는게 아니라 각각의 차이의 절대값을 순서대로 나열하고 그 중간값을 보는 방식이다.
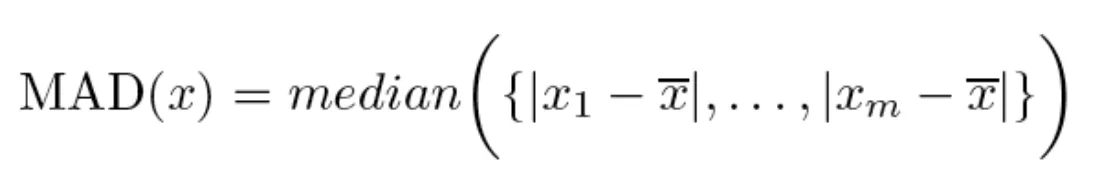
→interquartile range(x) - 해당 값이 클 수록 25%~75%인 값들이 넓게 퍼져있는 것이고 작다면 밀집되어 있는 것이다.
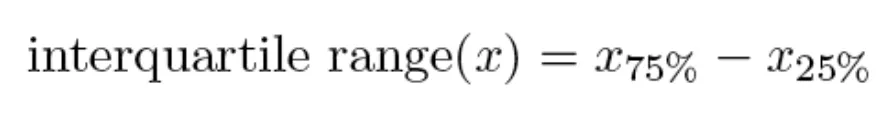
Percentile (백분위수)
- Continuous data가 분포되어 있을 때 백분위수를 많이 쓰게 된다.
- 순서형(ordinal) 또는 연속형(continuous)속성 x가 주어졌다고 하자. 그리고 0에서 100 사이의 어떤 수 p가 있을 때, p번째 백분위수(percentile)란 라는 값으로, 전체 데이터에서 p%의 관측값들이 보다 작은 값이 되도록 하는 기준값을 의미한다.
- 데이터를 크기 순으로 나열했을 때, 맨 아래부터 40% 지점에 해당하는 값이 이다. ← 하위 40%를 의미함 / 은 median 값을 의미 / 은 가장 높은 값을 의미
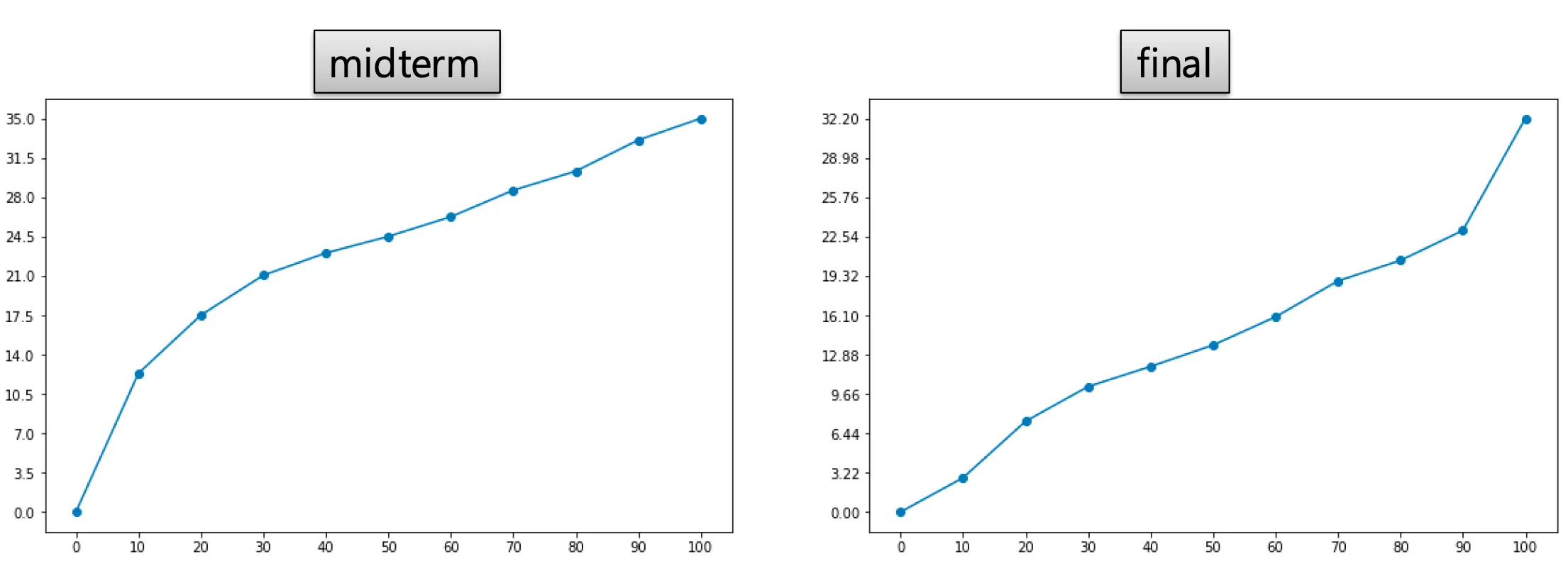
→ midterm 그래프 해석: 대부분의 학생들의 점수가 최상단까지 빈도수가 linear하게 퍼져있다.
→ final 그래프 해석: 하위권은 점수는 linear하게 퍼져있다가 상위권 학생들의 점수만 갑자기 상승해있다.
Boxplot Analysis
- Five-number summary of a distribution
- Minimum, Q1, Median, Q3, Maximum
- Quartiles: Q1 (25th percentile), Q3 (75th percentile)
- Inter-quartile range(사분범위): IQR = Q3 – Q1
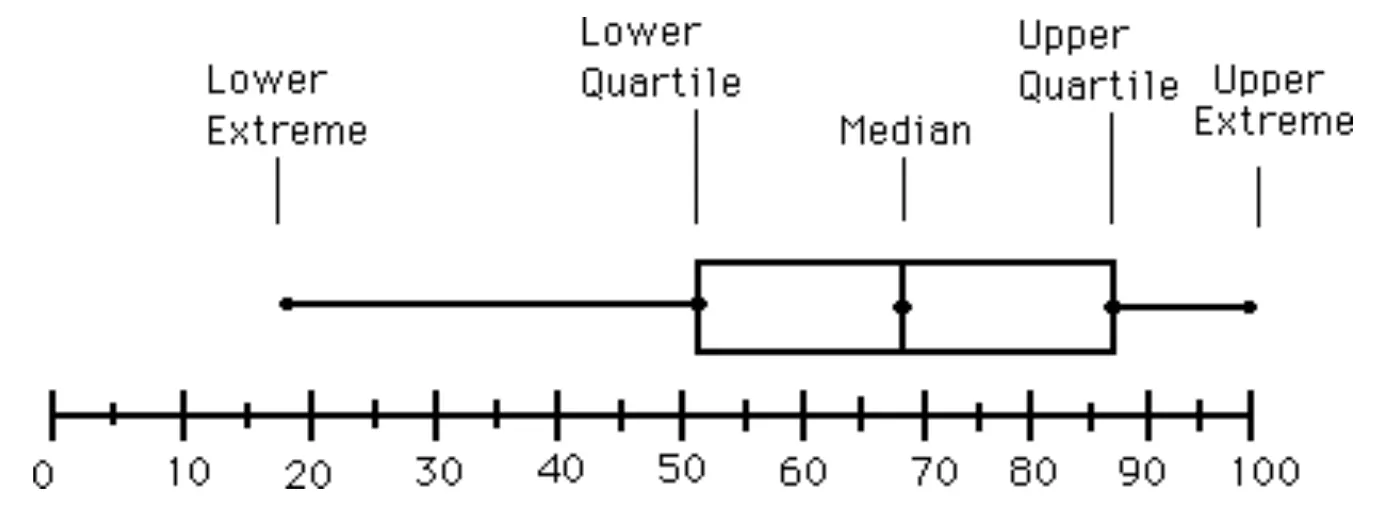
→ Box가 넓으면 넓을 수록 데이터가 퍼져있는 것, 작으면 데이터가 촘촘히 있는 것이다.
→ Lower Extreme과 Upper Extreme을 벗어난 것은 Outliers
Histogram Analysis
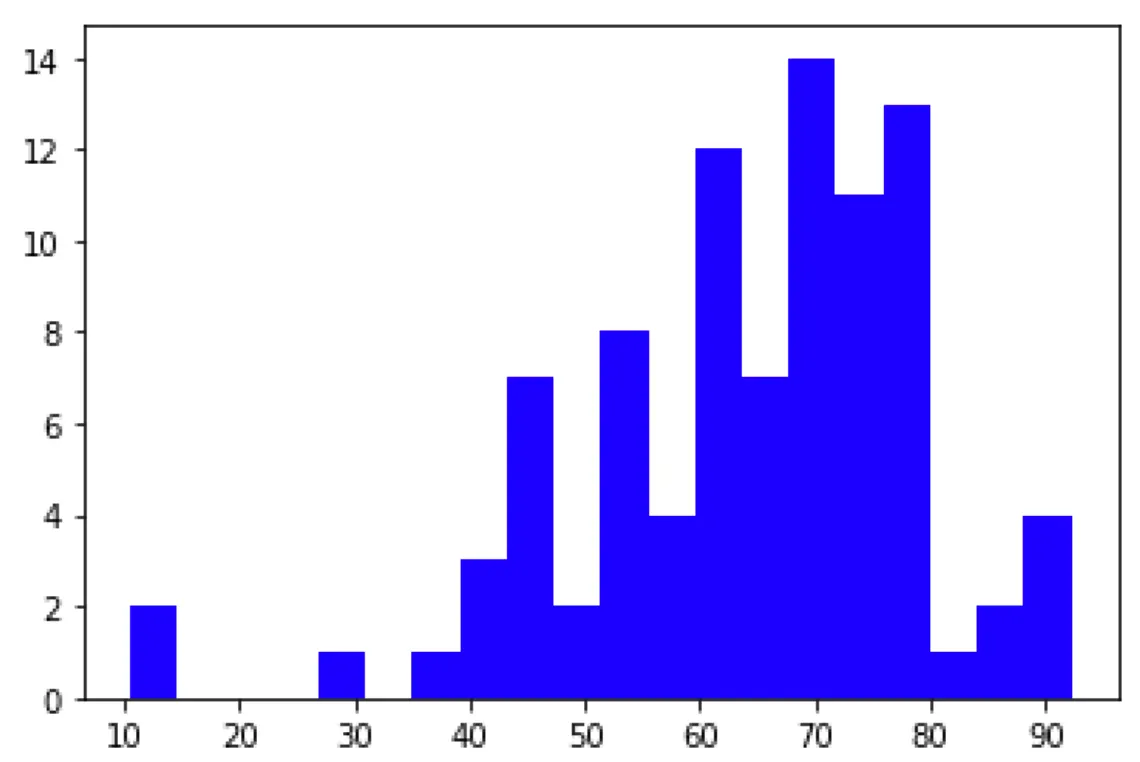
→ 데이터의 실제적인 분포를 알 수 있다.
→ 위 그래프에서 mode = 70
→ continuous data를 구간별로 잘라서 categorical data로도 변환이 가능하다.
Bivariate analysis (이변량 분석)
- 두 개의 변수 관계를 보여줄 수 있다.
Scatter plot
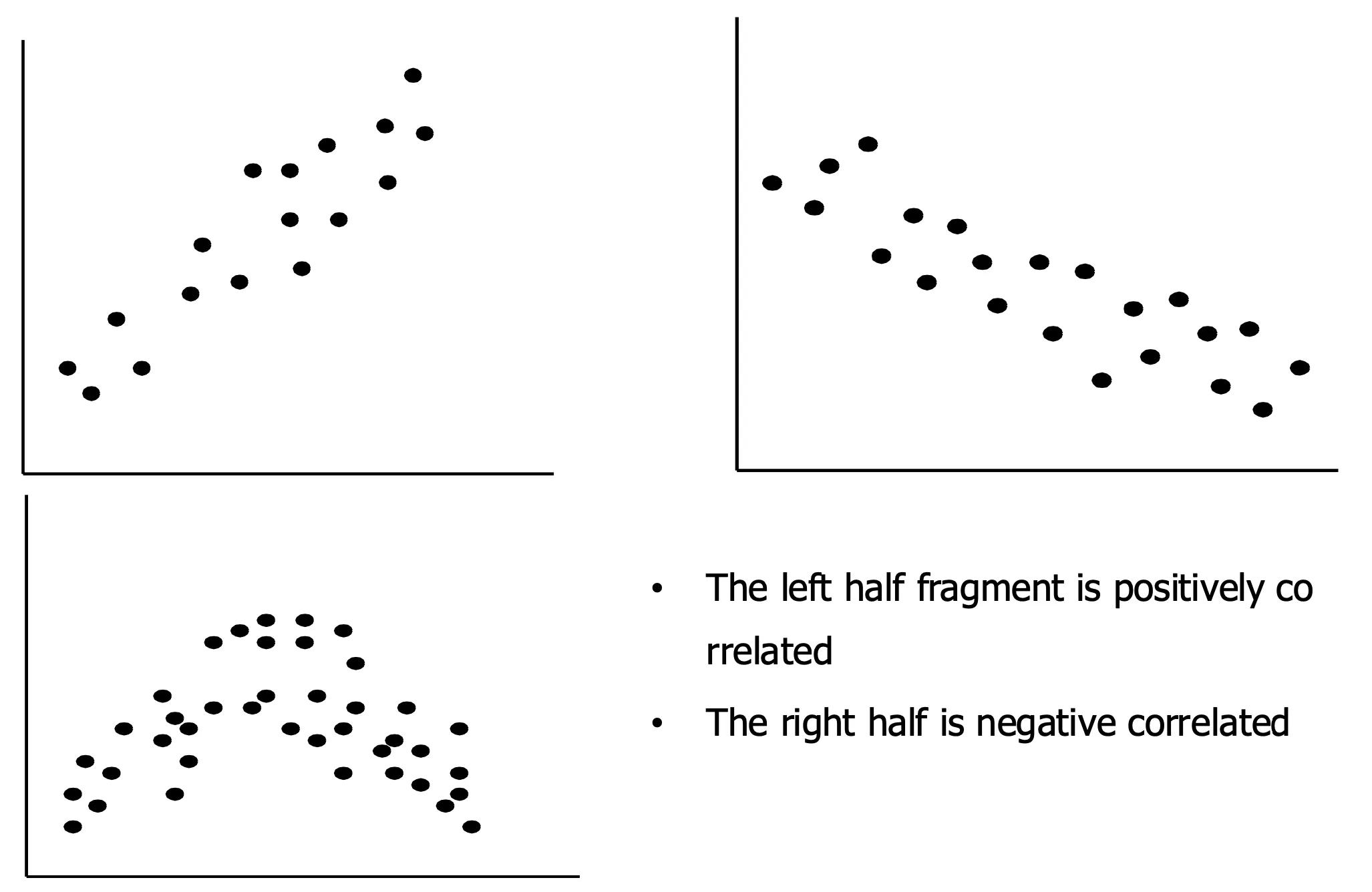
→ 왼쪽 상단부터 차례로 1,2,3번
- 1번: Positively Correlated data
- 2번: Negatively Correlated data
Python for Data Visualization
- Percentile
- Numpy.percentile()
- Boxplot
- Dataframe.boxplot()
- Histogram
- Dataframe.hist()
- Scatter plot
- Matplotlib.pyplot.scatter()

코딩하는 그로밋