Achievement Goals
- 3 Tier Architecture 를 이해한다.
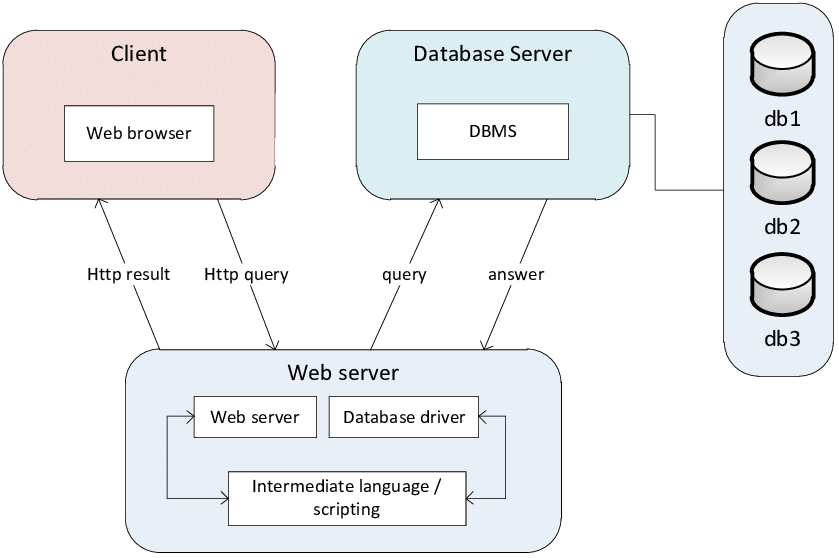
- 영속성의 개념을 이해하고, 데이터베이스의 필요성을 인지한다.
데이터를 인메모리 형태로 임시저장하거나, 파일에 저장하는 방법으로 데이터를 저장할 수 있는데, 굳이 데이터베이스를 사용하는 이유는 무엇일까?
- In-Memory
- JavaScript에서 데이터를 다룰 때, 프로그램이 실행될 때에만 데이터가 존재하게 된다. 예기치 못한 상황으로부터 데이터를 보호할 수 없고, 프로그램이 종료된 상태라면 데이터는 영원히 사라지며, 데이터의 수명은 프로그램의 수명에 의존하게 된다.
- File I/O
- 파일을 읽거나 쓰는 방식으로 데이터를 저장하는 형태. (엑셀 시트나 CSV같은 파일의 형태) 이 방식은 단점이 명확하다.
1) 파일이 손상되거나 여러 개의 파일들을 동시에 다뤄야 하거나 하는 등 복잡하고 데이터량이 많아질수록 데이터를 불러들이는 작업이 점점 힘들어 진다.
2) 데이터가 필요할 때마다 전체 파일을 매번 읽어야 한다. 파일의 크기가 커질수록 버겁고, 비효율적이다. (대표적인 단점)
- 파일을 읽거나 쓰는 방식으로 데이터를 저장하는 형태. (엑셀 시트나 CSV같은 파일의 형태) 이 방식은 단점이 명확하다.
- Database
- 하나의 CSV파일이나 엑셀 시트를 한 개의 테이블로 저장할 수 있고, 한번에 여러 개의 테이블을 가질 수 있기 때문에 버겁지 않고 효율적이다.
- In-Memory
- 데이터베이스 종류를 이해한다.
관계형(RDB, SQL), 비관계형(NoSQL)객체지향, XML, 계층형, 네트워크형 등등..
- 관계형 데이터베이스와 NoSQL의 차이를 이해한다.
- SQL(구조화 쿼리 언어)
- 관계형 데이터베이스는 SQL을 기반으로한다. 테이블의 구조와 데이터 타입 등을 사전에 정의하고, 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입할 수 있다. Row(행)과 Column(열)로 구성딘 테이블에 데이터를 저장한다. 각 열은 하나의 속성에 대한 정보를 저장하고, 행에는 각 열의 데이터 형식에 맞는 데이터가 저장된다. 특정한 형식을 지키기 때문에, 데이터를 정확히 입력했다면 데이터를 사용할 때에는 매우 수월하다. 관계형 데이터베이스에서는 SQL을 활용해 원하는 정보를 쿼리할 수 있다. 이 말은 관계형 데이터베이스에서는 스키마가 뚜렷하게 보인다는 말과 같다. 다시 말해, 테이블 간의 관계를 직관적으로 파악할 수 있다.
대표적인 관계형 데이터베이스는 MySQL, Oracle, SQLite, PostgresSQL, MariaDB등이 있다.
- 관계형 데이터베이스는 SQL을 기반으로한다. 테이블의 구조와 데이터 타입 등을 사전에 정의하고, 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입할 수 있다. Row(행)과 Column(열)로 구성딘 테이블에 데이터를 저장한다. 각 열은 하나의 속성에 대한 정보를 저장하고, 행에는 각 열의 데이터 형식에 맞는 데이터가 저장된다. 특정한 형식을 지키기 때문에, 데이터를 정확히 입력했다면 데이터를 사용할 때에는 매우 수월하다. 관계형 데이터베이스에서는 SQL을 활용해 원하는 정보를 쿼리할 수 있다. 이 말은 관계형 데이터베이스에서는 스키마가 뚜렷하게 보인다는 말과 같다. 다시 말해, 테이블 간의 관계를 직관적으로 파악할 수 있다.
- NoSQL(비구조화 쿼리 언어)
- 비관계형 데이터베이스는 NoSQL을 기반으로한다. 주로 데이터가 고정되어 있지 않은 데이터베이스를 가리킨다. NoSQL이 SQL과 반대되는 개념처럼 사용된다고 해서, NoSQL에 스키마가 반드시 없는 것은 아니다. 관계형 데이터베이스에서는 데이터를 입력할 때 스키마에 맞게 입력해야 하는 반면, NoSQL에서는 데이터를 읽어올 때 스키마에 따라 데이터를 읽어 온다. 이런 방식을
schema on read라고 한다. 읽어올 때에만 스키마가 사용된다고 해서 데이터를 쓸 때 정해진 방식이 없다는 의미는 아니다. 데이터를 입력하는 방식에 따라, 데이터를 읽어올 때 영향을 미친다.
대표적인 비관계형 데이터베이스는 몽고DB, Casandra 등이 있다.
- 비관계형 데이터베이스는 NoSQL을 기반으로한다. 주로 데이터가 고정되어 있지 않은 데이터베이스를 가리킨다. NoSQL이 SQL과 반대되는 개념처럼 사용된다고 해서, NoSQL에 스키마가 반드시 없는 것은 아니다. 관계형 데이터베이스에서는 데이터를 입력할 때 스키마에 맞게 입력해야 하는 반면, NoSQL에서는 데이터를 읽어올 때 스키마에 따라 데이터를 읽어 온다. 이런 방식을
- SQL(구조화 쿼리 언어)
- 관계형 데이터베이스 및 NoSQL이 어떤 경우에 적합한지 이해한다.
SQL을 사용해야 하는 경우
- 데이터베이스의 ACID 성질을 준수해야 하는 경우
- 소프트웨어에 사용되는 데이터가 구조적이고 일관적인 경우
NoSQL을 사용해야 하는 경우
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우
- 조회, 삽입, 갱신, 삭제 구문을 자유자재로 사용할 수 있다.
조회
- Select A from B ( B테이블에 있는 A를 조회)
- DESC B ( B테이블의 구조를 조회)
삽입
- INSERT INTO table_name VALUES ('developerjhp', '테스트', '🥳');
갱신
- UPDATE table_name SET name = 'developerjhp';
삭제
- DELETE FROM table_name [WHERE 조건];
- 스키마 디자인을 할 수 있다.
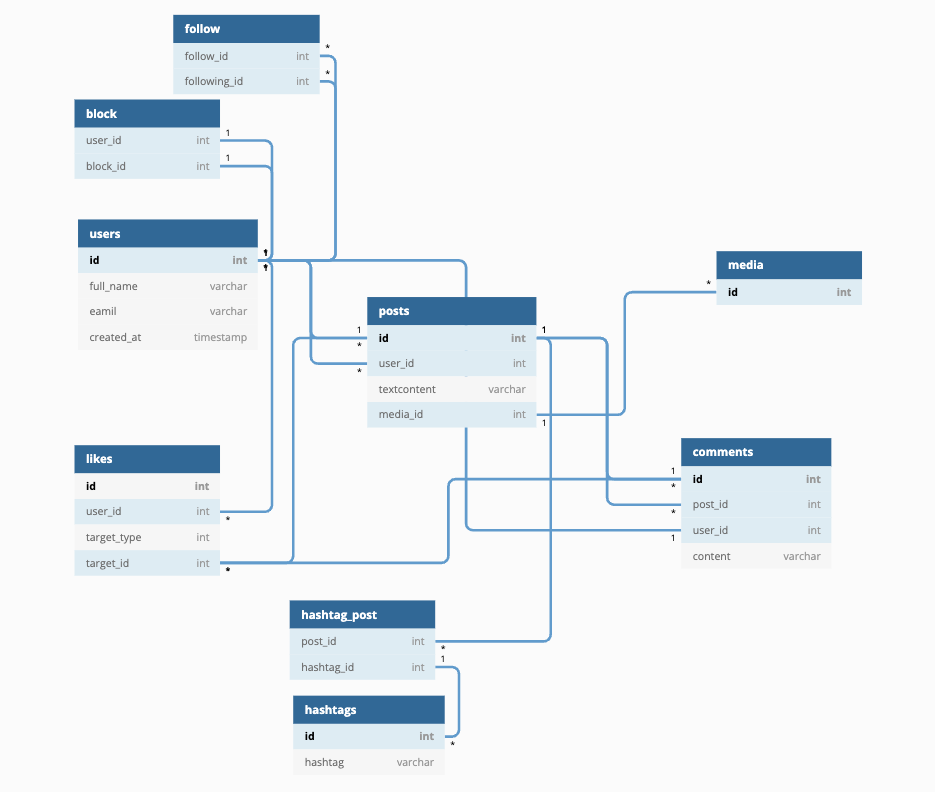
직접 만들어본 인스타그램 게시글 스키마 디자인 - 앱에 필요한 테이블과 필드, 그리고 관계를 부여할 수 있다.
yes 🙌
- 1:N, N:N 관계를 이해하고, 데이터베이스에서 테이블을 조작할 수
있다.1:N 관계를 맺은 엔티티 쪽의 여러 객체를 가질 수 있는 것 (1:N 관계는 N:M 관계처럼 새로운 테이블을 만들지 않는다.)
N:N (또는 N:M) 양쪽 엔티티 모두에서 1:N 관계를 가지는 것, 서로가 서로를 1:N 관계로 보고 있는 것 (일반적으로 N:M 관계는 두 테이블의 대표키를 컬럼으로 갖는 또 다른 테이블을 생성해서 관리한다.) N:M 관계는 서로가 서로를 1:N 관계, 1:M 관계로 갖고 있기 때문에, 서로의 PK를 자신의 외래키 컬럼으로 갖고 있으면 된다.
- Foreign Key, Primary Key에 대해 이해할 수 있다.
PK(Primary Key) : 각 엔티티를 식별할 수 있는 대표키, 테이블에서 중복되지 않는(Unique) 값, Null일 수 없다.
FK(Foreign Key : 다른 테이블의 기본키를 참조, 모든 필드는 참조하는 기본키와 동일한 도메인(값의 종류&범위)을 갖는다.
정말 오랜만에 TIL을 써본다. 마침 힘들어서 휴식이 필요했을때 42서울 피신을 했고 충분히 쉬다온 것 같다. 이제 다시 열심히 달려봐야지!ㅎㅎ.. 근데 백엔드 좀 재밌다..

Product Manager (ex-Frontend Developer)