코딩테스트
1.시간 복잡도

일반적으로 수행 시간은 1억 번의 연산을 1초의 시간으로 간주하여 예측실제 시간 복잡도를 정의하는 3가지 유형빅-오메가: 최선빅-세타: 보통빅-오: 최악코테에서는 빅-오 기준으로 수행 시간 계산하는 것이 좋다예로 시간 제한이 2초이면 2억 번 이하 연산 횟수로 문제를
2.자료구조
메모리의 연속 공간에 값이 채워져 있는 형태인덱스를 통해 참조 가능새로운 값을 삽입하거나 특정 인덱스에 있는 값을 삭제하기 어렵다 값을 삽입하거나 삭제하면 해당 인덱스 주변 에 있는 값을 이동 시키는 과정 필요배열의 크기는 선언할 때 지정할 수 있으며, 한 번 선언하면
3.숫자의 합 구하기
char\[] cNum = sNum.toCharArray() String을 Char 배열로 변환
4.구간 합 구하기
인덱스 0 1 2 3 4 5배열A 15 13 10 7 3 12합배열S 15 28 38 45 48 60i에서 j까지 구간 합을 구할 때Sj - Si-13에서 5까지 구간 합을 구할 때S5 - S2전체 인덱스 0~5S5 = A0 + A1 + A2 + A3 +A4 +A5인덱
5.조합 (Combination) nCr

여기서 !는 팩토리얼을 의미합니다. 예를 들어, 5!은 5 4 3 2 1입니다.Java에서 nCr 계산하기nCr을 계산하기 위해 팩토리얼을 구하는 함수와 이를 이용한 조합 계산 함수를 작성할 수 있습니다. 다음은 Java에서 이를 구현한 예제입니다:
6.스택과 큐
Last - in , first -out후입선출은 삽입과 삭제가 한쪽에서만 일어난다push : top 위치에 새로운 데이터를 삽입하는 연산pop : top 위치에 현재 있는 데이터를 삭제하고 확인하는 연산peek : top 위치에 현재 있는 데이터를 단순 확인하는 연산
7.log
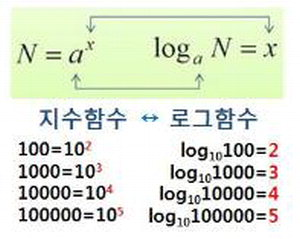
8.우선순위 큐 (Priority Queue)
일반적인 큐(Queue)는 먼저 집어넣은 데이터가 먼저 나오는 FIFO (First In First Out) 구조로 저장하는 선형 자료구조입니다. 우선순위 큐(Priority Queue)는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 것을 말합니다.우선
9.버블 정렬
두 인접한 데이터의 크기를 비교해 정렬하는 방법시간 복잡도는 o(n^2)으로 다른 정렬 알고리즘보다 속도가 느린편다음 그림과 같이 루프를 돌면서 인접한 데이터 간의 swap연산으로 정렬루프 1번을 돌때마다 1개의 정렬이 픽스됨1번 돌 때 N의시간이 걸리는 정렬을 N번
10.팩토리얼
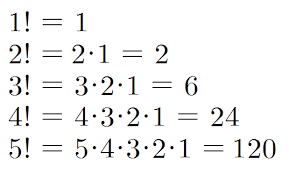
수학에서, 자연수의 계승 또는 팩토리얼(階乘, 문화어: 차례곱, 영어: factorial)은 그 수보다 작거나 같은 모든 양의 정수의 곱이다. n이 하나의 자연수일 때, 1에서 n까지의 모든 자연수의 곱을 n에 상대하여 이르는 말이다. 기호는 느낌표(!) 를 쓰며 팩토
11.선택 정렬
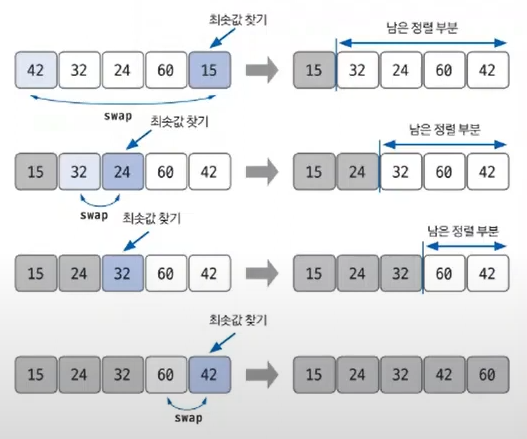
빈번하게 나오는 알고리즘은 아님.대상 데이터에서 최대나 최소 데이터를 데이터가 나열된 순으로 찾아가며 선택하는 방법입니다.구현 방법이 복잡하고 시간 복잡도도 O(n^2)으로 효율적이지 않다.최솟값 또는 최댓값을 찾고 남은 정렬 부분의 가장 앞에 있는 데이터와 swap하
12.삽입정렬
삽입 정렬은 이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식시간 복잡도 O(n^2)로 느린편이지만 구현이 쉽다.선택 데이터를 현재 정렬된 데이터 범위 내에서 적절한 위체 삽입과정현재 index에 있는 데이터 값 선택현재 선택한 데
13.퀵 정렬
퀵 정렬은 기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘기준 값이 어떻게 선정되는지가 시간 복잡도에 많은 영향을 미치고, 평균 시간 복잡도는 O(nlogn)이며 최악의 경우 시간 복잡도 O(n^2)이 됩니다.
14.기수 정렬
기수정렬 radix sort은 값은 비교하지 않는 특이한 정렬입니다. 기수 정렬은 값을 놓고 비교할 자릿수를 정한 다음 해당 자릿수만 비교합니다.기수 정렬의 시간 복잡도는 O(Kn)으로, 여기서 k는 데이터의자릿수를 말합니다예를 들어 234, 123 비교시 2와1 3과
15.깊이 우선 탐색 DFS Detpth First Search
깊이 우선 탐색은 그래프 완전 탐색 기법 중 하나그래프의 시작 노드에서 출발해서 탐색할 한 쪽 분기를 정하여 최대 깊이까지 탐색을 마치고 다른 쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘재귀 함수로 구현스택 자료구조 기용(노드 수: V, 에지 수: E)O(V+E)
16.BFS 너비 우선 탐색
너비 우선 탐색 Breadth-first search도 그래프를 완전 탐색하는 방법 중 하나, 시작 노드에서 출발해 시작 노드를 기준으로 가까운 노드를 먼저 방문하면서 탐색하는 알고리즘특징FIFO탐색Queue 자료구조 이용시간 복잡도0(V+E)너비 우선 탐색은 선입선출
17.이진 탐색
데이터가 정렬돼 있는 상태에서 원하는 값을 찾아내는 알고리즘입니다.대상 데이터의 중앙값과 찾고자 하는 값을 비교해 데이터의 크기를 절반씩 줄이면서 대상을 찾습니다.시간 복잡도 O(logN)이진 탐색은 오름차순으로 정렬된 데이터에서 다음 4가지 과정을 반복\*\* 내림차
18.오일러피
거의 안나온다오일러 피 함수 PN의 정의는 1부터 N까지 범위에서 N과 서로소인 자연수의 개수를 뜻합니다.서로소 공약수가 1 이외에 없음정답은 1, 5로 2개이다.2는 6과 1이외에 2라는 공약수가 있다.구하고자 하는 오일러 피의 범위만큼 배열을 초기화2부터 시작해 현
19.유클리드 호제법
유클리드 호제법은 두 수의 최대 공약수를 구하는 알고리즘일반적으로 최대 공약수를 구하는 방법은 소인수 분해를 이용한 공통된 소수들의 곱으로 표현할 수 있지만 유클리드 호제법은 좀 더 간단한 방법을 제시합니다.유클리드 호제법의 핵심 이론MOD 연산을 이해하고 있어야 한다
20.확장 유클리드 호제법
유클리드 호제법의 목적 - 두 수의 최대 공약수 구하기확장 유클리드 호제법의 목적 - 방정식의 해를 구하기확장 유클리드 호제법에서 해를 구하고자 하는 방정식ax + by = c(a,b,c,x,y는 정수)이때 위 방정식은 c % gcd(a,b) = 0인 경우에만 정수해