최근 유튜브를 보면서 한 채널에서 AI 관련 정보를 소개하는 것을 보았다.
그 중에서 나의 눈길을 끌었던 것은 Z-image-turbo 라는 AI 모델로, Local 에서도 돌아가고 이미지 성능이 엄청나며 Apache 2.0 라이선스 인 녀석이었다.
FluxApi 를 통해 AI 이미지 생성앱을 만들어보긴 했지만 가져다 쓸 생각 뿐이었지 실제로 이 환경을 구성해볼 생각은 하지 못했었기에, 이렇게 된 김에 한 번 사용해보는게 어떨까 싶어서 사용해봤는데, 너무 이쁘게 잘 뽑혀서 놀랐다..


위 이미지들은 ComfyUi + ZIT 를 통해 생성한 이미지다.
이제 이러한 이미지를 뽑는 법을 알아보자 !!
시작하기에 앞서 그래픽카드가 NVDIA RTX 시리즈이고, VRAM 이 8GB 이상인 30xx 시리즈부터 사용하는 것을 추천한다.
또한 작성자의 그래픽카드가 2080으로 VRAM 이 많지 않아 GGUF 방식으로 설명할 예정이니 참고.
# 1. ComfyUi 설치
우선 https://www.comfy.org/ 사이트로 이동하여 Download ComfyUi 를 누르자

RTX 를 사용한다면 Windows 환경일테니, Download for Windows 를 눌러 다운하자.
설치 후 기본 설정 값은 기본 선택되어있는 것들을 모두 NEXT 하면 된다.
# 2. 모델 다운로드
모델 (일반) - https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/diffusion_models
텍스트 인코더 (일반) - https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/text_encoders
(VRAM이 16GB를 넘지 않는다면 추천)
모델 (GGUF) - https://huggingface.co/vantagewithai/Z-Image-Turbo-GGUF/tree/main
텍스트 인코더 (GGUF) - https://huggingface.co/Qwen/Qwen3-4B-GGUF/tree/main
- GGUF 에서 Q 뒤의 숫자는 비트이다. 이것이 높을수록 똑똑해지지만 VRAM 을 많이 잡아먹으니, 개인 환경에 맞춰서 다운로드하자. (2080 VRAM 8gb 인 작성자는
Q3-K-M다운)
VAE - https://huggingface.co/Comfy-Org/z_image_turbo/tree/main/split_files/vae
위의 사이트로 이동해 폴더에 존재하는 파일을 다운로드 해주자.
다운로드는 파일을 클릭하고 위의 버튼을 클릭하면 진행된다.
다운로드가 모두 완료되었다면, 내 문서 - Comfyui - models 로 이동해주자.
여기서 clip 폴더에 텍스트인코더 파일, vae 폴더에 VAE 파일, unet 폴더 에 모델 파일을 넣어준다.
이제 ComfyUi 를 실행시켜주자
# 3. 커스텀 노드 및 모델 설치
위의 Manager 버튼을 눌러주자.

ComfyUI-GGUF 라는 녀석이 있다, 얘가 있어야 GGUF 파일을 정상적으로 사용할 수 있다.
이것의 Install 버튼을 누르고 Back 을 눌러 Manager 메뉴로 다시 돌아가자.

Model Manager 를 눌러 Type 을 upscale 로 변경하고 REalESRGAN x4 를 설치한다.
이 녀석은 작은 해상도를 업스케일 시켜줘 더 좋은 화질로 변경시켜준다.
이제 ComfyUI 를 껏다가 재실행 하자.
# 4. Workflow 작성
ComfyUI 를 재실행하면 빈 워크플로우가 나올 것이다.
우리는 이곳에서 노드를 정의하여 워크플로우를 만들어야한다.
1. Unet, Clip Loader 배치
빈공간에 마우스를 올려 더블클릭 해보자

그러면 위와 같이 노드 선택이 가능해진다.
다음 두 노드를 검색하고 클릭하여 노드를 배치하자.


위를 모두 진행하면 다음과 같이 노드가 만들어질 것이다.
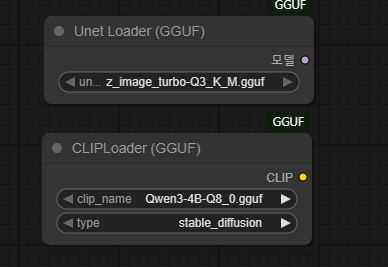
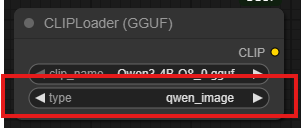
CLIP Loader 의 type 을 qwen_image 로 변경해준다.
2. Prompt 배치
변경이 완료되었다면 우리가 명령할 프롬포트 노드를 생성해줘야한다.

위의 노드를 찾아 2개를 배치해준다.
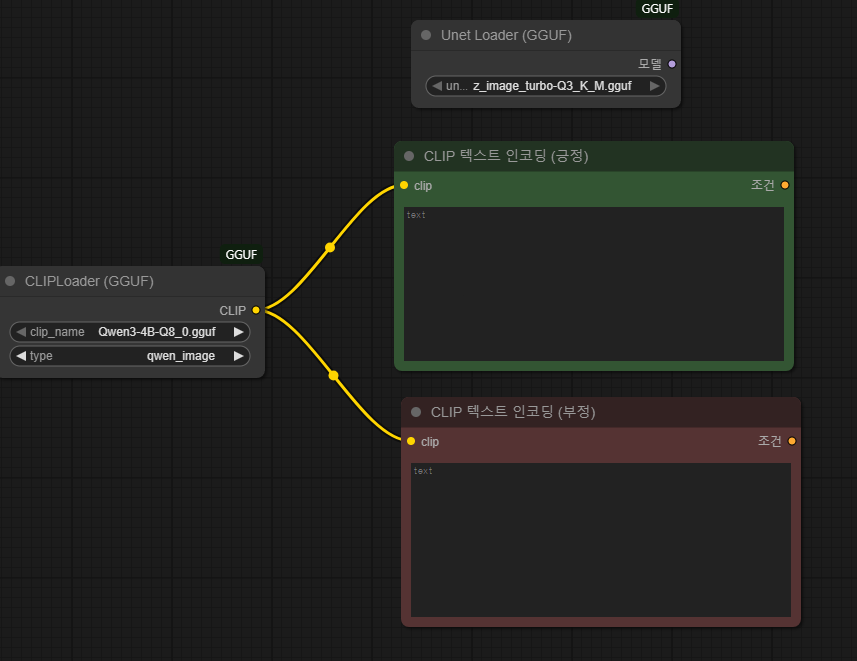
배치를 완료하면 CLIPLoader 의 CLIP 부분에 마우스 클릭을 유지한 상태로 CLIP 텍스트 인코딩의 clip 과 연결해준다.
CLIP 텍스트 인코딩의 제목과 색상은 보기좋게 내가 설정한 것이다. 1번클릭하여 동그라미 부분을 클릭하면 색상을, 더블클릭하면 제목을 수정할 수 있다.
부정의 경우 ZIT(Z-image-Turbo) 에서는 사용하지 않으므로 빈값으로 둬도 된다.
긍정의 경우 한글로 써도 대충 알아듣는 것 같지만, 영어로 써주는게 더 확실하다.
3. KSampling 배치
프롬포트 노드 배치가 모두 완료되었으면 다음 노드를 찾고 배치해주자.


빈 잠재 이미지는 Text to Image 시 사용되며, 생성될 이미지 사이즈를 결정한다.
Ksampler 는 이미지 생성에 수행할 작업 수, 변환, 시드 등을 정의한다.
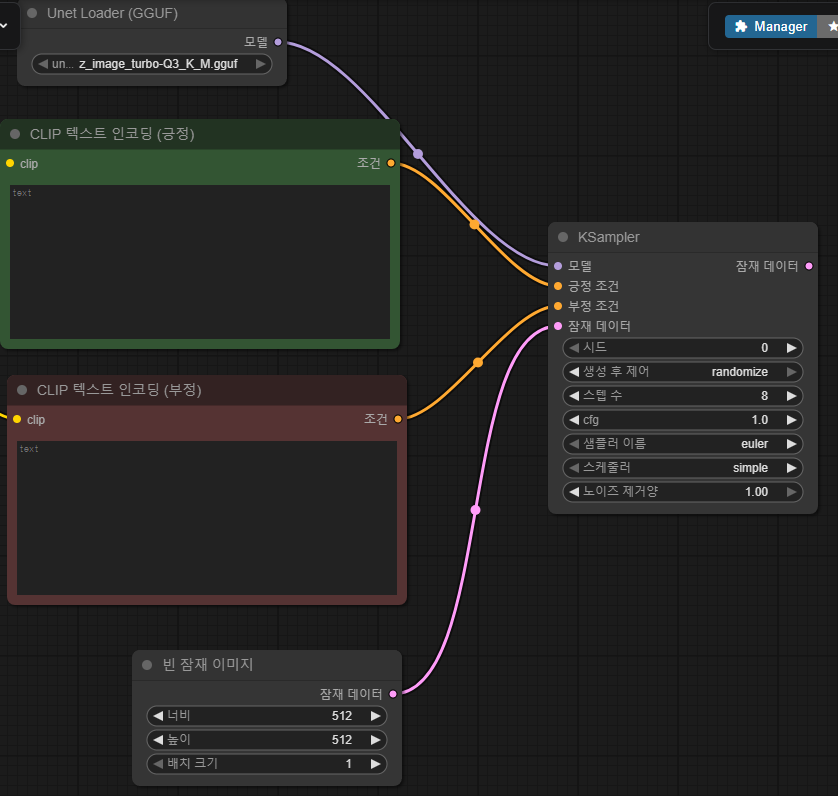
위처럼 만들어주자.
ZIT 는 스텝을 6 ~ 9 로, cfg 는 1.0 으로 하는것을 권장한다.
4. VAE 배치


위의 노드들을 배치하여 아래처럼 연결해준다.
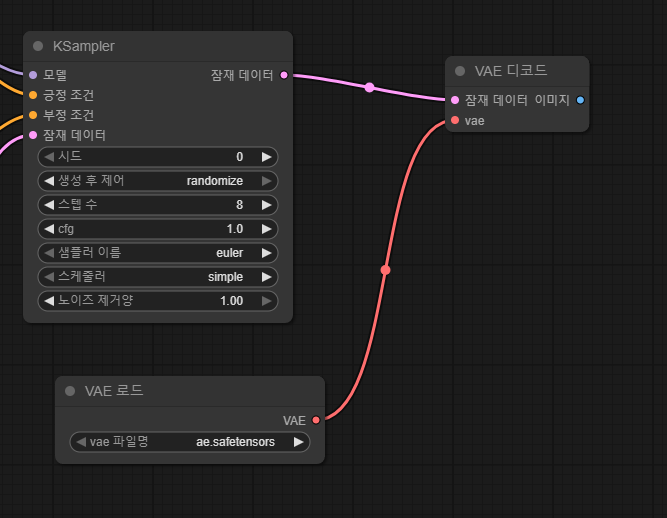
5. 업스케일 모델 적용 (필수아님)
위의 과정까지가 필수요소이고, 마지막 노드로 이미지 저장 노드만 배치하면 끝나지만 저대로 작동시킨다면 화질이 나쁠 수 있다.
그렇기에 나는 업스케일 모델을 적용시킬 예정이다.


위 두 개의 노드를 배치하자.
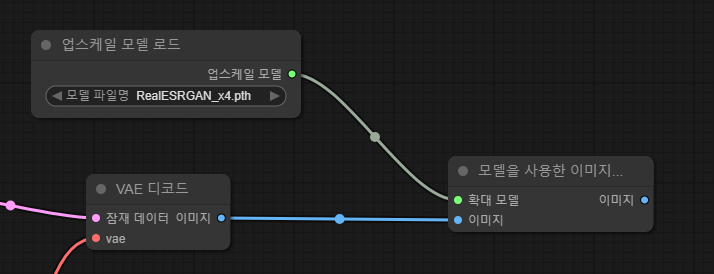
이후 업스케일 모델 로드 - 확대 모델 , VAE 디코드 이미지 - 모델을 사용한 .. 이미지 로 각각 연결한다.
6. 최종 저장

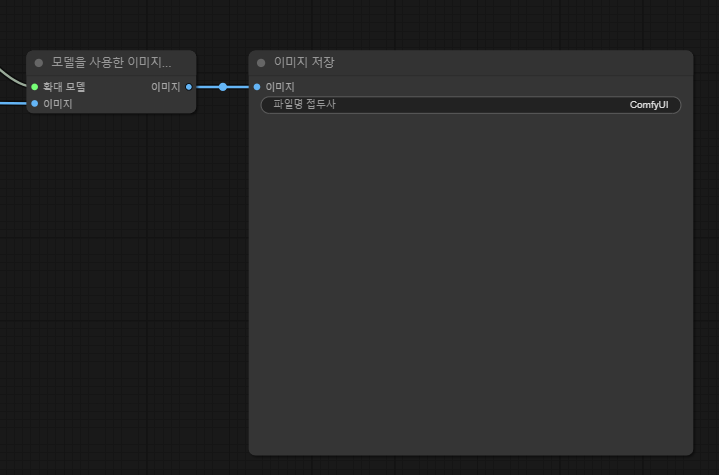
위처럼 적용하면 된다.
만약 업스케일을 적용하지 않는 경우 VAE 디코드 이미지를 이미지 저장 의 이미지와 연결한다.
7. 실행
나의 경우 아름다운 한국 20대 여자 아이돌의 라이브 모습, 얼굴 클로즈업 을 번역하여 A live performance of a beautiful Korean girl idol in her 20s, a close-up of her face 를 긍정 프롬포트에 넣어주고 실행하였다.
8. 결과
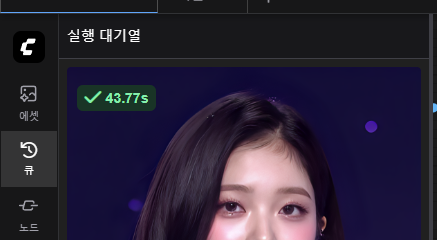
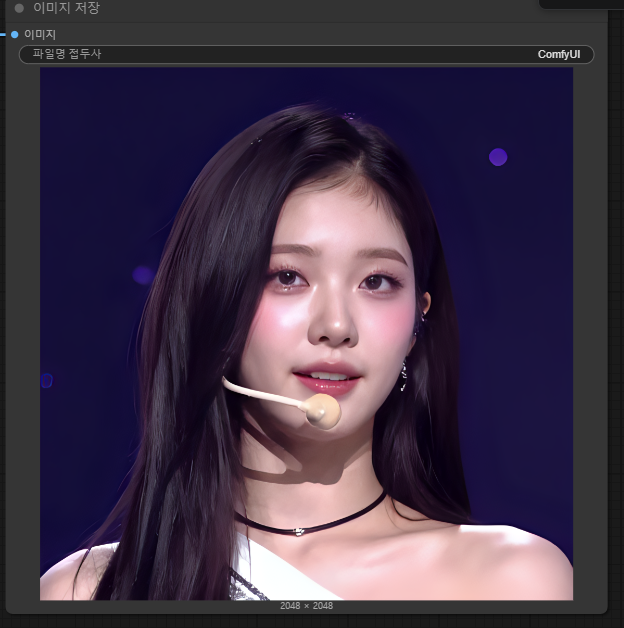
총 실행시간 44초가 걸리며 이미지 생성이 완료되었다.
이미지 저장 경로는 내 문서 - ComfyUI - output 에 존재하므로 이곳을 확인하면 된다.
추가 주의점
-
빈 잠재 이미지의 이미지 사이즈가 작은 경우 전신 사진으로 나타내면 얼굴이 깨지는 경우가 있다. 이 경우FACE Detailer라는 노드를 쓰면 된다고 하는데, 나는 사용하지 않았다. -
이미지 사이즈를 크게 생성하는 경우 그에 맞춰 생성 시간이 오래걸린다.
나의 경우 2080 을 사용하고 있는데, 이게 AI 를 활용하기엔 오래된 녀석이라 1920, 1080 정도로 하면 2~3분이 소요되어 512 x 512 로 하고 업스케일을 적용하였다. -
이미지가 깨지거나 어색한 부분이 있다면 이미지 사이즈를 늘려주자
만드는데 생각보다 재미있었지만, 이상한 vae 나 text Encoder 를 사용하여 속도가 엄청 느려져서 자료들을 찾는데 시간이 꽤나 걸렸었다.
근데 재밌긴한데, 이걸 어디에 쓰지...?
참고
