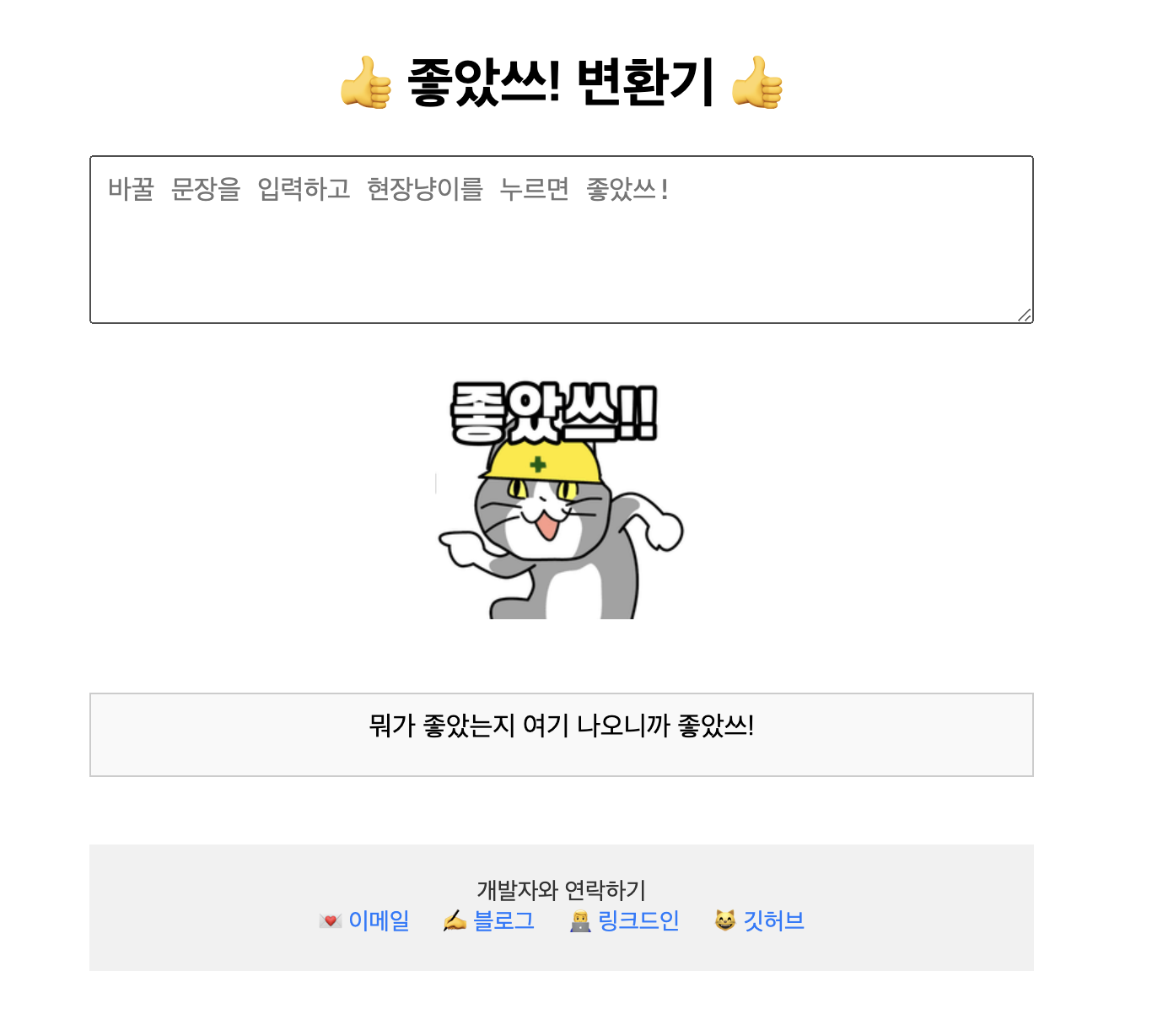
1. 밈친놈
전 밈이나 짤 같은 것들을 매우 좋아합니다. 릴스나 쇼츠는 물론이고 각종 커뮤니티에서 유행하는 밈들까지 다 섭렵(하도록 노력)하고 있습니다. 그래서 그런지 처음에 "원영적 사고 변환기"가 나왔을 때, 너무 재밌게 사용할 수 있어서 완전 럭키비키 🍀 였습니다.
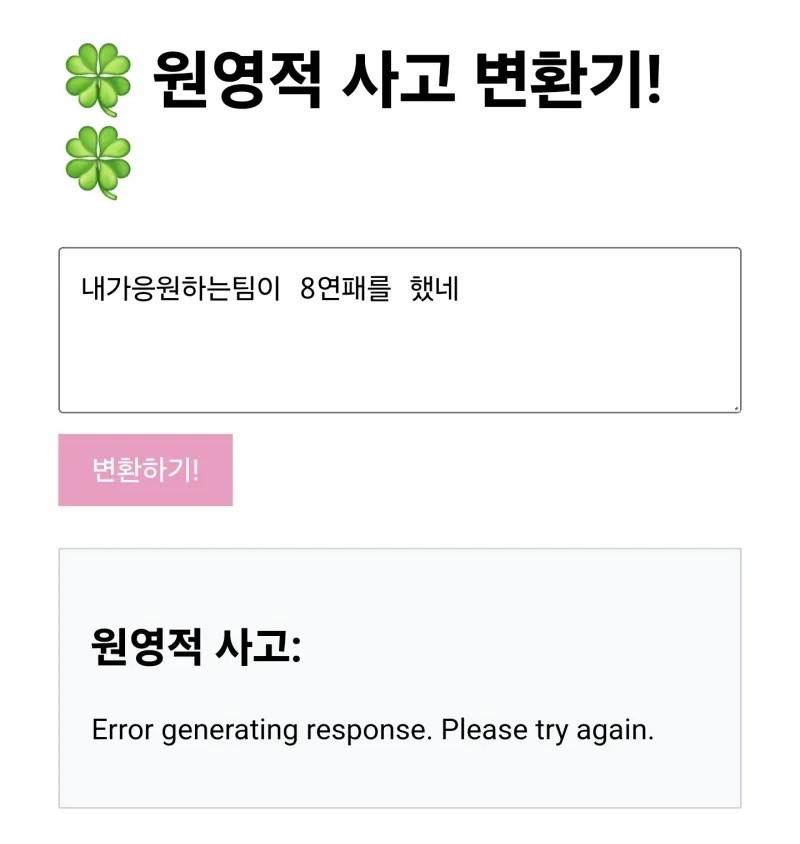
(하지만 원영적 사고도 삼성 라이온즈의 8연패를 쉴드 쳐주지 못했지...)
그렇게 여러 밈들을 즐기던 중, 최근에 유행을 하게 된 "현장냥이" 밈에 꽂히게 되었습니다. 이 밈은 일본의 한 만화가가 일본의 중소기업의 모습을 그린 만화에 나오는 캐릭터 "현장냥이"가 한국으로 수출된 케이스인데 일본의 중소기업 모습과 한국의 중소기업 모습이 별반 차이가 없어 공감과 웃음을 자아낸 케이스 입니다.

(물론 좋은 뜻은 아닙니다.)
위의 짤에서 나오듯 이 만화가 한국으로 넘어와 번역이 될 때, 현장냥이가 "좋았쓰!" 라는 추임새를 넣으며 말하는 것이 유행이 되었습니다. 이 추임새에 중독되어 밈을 즐기던 저는 불현듯 앞에서 언급한 "원영적 사고 변환기"가 떠오르게 되었습니다. 원영적 사고 변환기가 사람이 한 말을 긍정적으로 변환한 뒤, "럭키비키잖아 🍀" 라는 추임새를 덧붙이는 형식이니까 이를 벤치마킹 한다면 현장냥이 밈에도 충분히 녹일 수 있을 것이라고 생각했습니다. 이 것이 제가 "좋았쓰! 변환기"를 개발하게 된 이유입니다.
2. 프론트엔드 개발자: ChatGPT
이제 기능을 생각했으니, 어떤 기술을 사용하여 개발을 해야할지를 정해야 했습니다. 우선 결론부터 말하자면 제가 정한 기술 스택은 다음과 같습니다.
Frontend: ChatGPT
Backend: Django
Database: MySQL
LLM: Claude
다들 기술 스택 중 프론트엔드를 보고 웃거나 흠칫하셨을 겁니다. 물론 정말로 제가 ChatGPT를 프론트엔드 프레임워크로 선택한 것은 아닙니다. 그렇다면 제가 왜 프론트엔드 스택에 저렇게 작성을 하였을까요? 저는 프론트엔드 개발에 대해서 하나도 모르기 때문입니다. 예전 같으면 이런 상태인 제가 웹 페이지를 개발하기는 불가능에 가까웠을 겁니다. 하지만 세상이 발전하면서 LLM과 ChatGPT가 나오게 됐고, 이는 제가 프론트엔드 개발을 할 수 있게 해주었습니다.
(코드 짜주는 거 보고 진심 백수될 날이 얼마 남지 않았다고 느꼈습니다.)
이렇게 ChatGPT의 도움(이라 쓰고 사실상 ChatGPT의 외주 개발)을 받아 개발을 했기 때문에 저는 프론트엔드 개발 스택을 ChatGPT라 표현하게 되었습니다.
다음으로 백엔드 스택을 Django로 선택한 이유를 적어보겠습니다. 저는 토이 프로젝트의 기술 스택은 두 가지 목적 중 하나를 달성할 수 있어야 한다고 생각합니다.
- 쉽고 빠르게 개발을 할 수 있을 것
- 평소에 공부하고 관심이 있던 기술을 써보며 손에 익힐 수 있을 것
이 중 저는 해당 프로젝트의 목표를 "빠르게 개발해 출시해보자!"로 잡고 있었기 때문에 1번 목적에 가까운 Django를 선택하게 되었습니다. 제가 Django가 1번에 가깝다고 생각한 이유는 다음과 같습니다.
- 많이 써봤습니다.
저는 학창 시절 백엔드를 처음 시작할 때 부터 취업 후 약 2년 간의 커리어를 Django로 이어왔습니다. 이에 Django가 가장 손에 익고 빠르게 개발을 할 수 있을 거라 생각했습니다. - 제공하는 기능이 많습니다.
Django는 파이썬 웹 프레임워크이기 때문에 파이썬의 풍부한 생태계를 누리며 개발을 할 수 있습니다. 또한 자체적으로 DB 커넥션 관리, ORM 및 JSON Serializing(물론 이건 조금 더 많은 기능을 누리려면 DRF를 쓰긴 해야합니다.)를 제공하기 때문에 비즈니스 로직 외적으로 크게 신경 쓸 것들이 없습니다.
이러한 이유로 저는 Django를 백엔드 기술 스택으로 사용하였고 이는 저에게 꽤나 큰 이득으로 다가왔습니다.
세번째로 DB를 MySQL을 사용하게 된 이유입니다. 현대에 와서 DBMS는 정말 많은 종류가 생기게 되었습니다. RDBMS로는 Oracle, MySQL, PostgreSQL 등등이 있고 NoSQL로는 MongoDB, Redis(In-Memory DB) 등등이 있습니다. 이 중 MongoDB는 제가 사용하지 못할 뿐더러 Redis는 In-Memory DB의 특성에 맞게 속도가 매우 빠르지만 장기적인 데이터를 저장할 경우에는 적합하지 않다고 생각하여 NoSQL은 후보에서 제외하였습니다.
그렇다면 수 많은 RDBMS 중에서 왜 하필 MySQL을 골랐는지 이유를 설명 드리겠습니다. 이걸 여기서 상세히 설명하기에는 RDBMS 관련 칼럼을 작성하는 꼴이 될 테니 간단하게 세 줄 요약하고 가겠습니다.
무료입니다. (vs Oracle)
간단한 데이터 조회를 할 때 MySQL은 빠른 성능을 보입니다. (vs Oracle, PostgreSQL)
해당 서비스에는 복잡한 transaction이 발생하지 않아 철저한 ACID 관리가 필요 없었습니다. (vs Oracle)
마지막으로 LLM 프롬프팅을 위한 서비스로 왜 Claude를 사용했는지 입니다. 사실 저도 원래 Claude를 쓸 생각이 없었습니다. 앞에서도 말씀 드렸듯이 저는 이번 프로젝트 모든 프론트엔드 개발에 ChatGPT를 사용할 정도로 OpenAI의 충성 고객입니다. 그런 저의 마음을 Claude로 돌리게 된 가장 큰 이유는, 이 프로젝트를 개발하기 위해 ChatGPT의 credit이 필요했고 이를 결제하려 했는데 그 당시 OpenAI에서 제 카드로 결제가 안됐습니다. 그래서 저는 ChatGPT처럼 Python SDK를 제공하는 LLM 서비스를 찾게 됐고 Claude를 사용하게 되었습니다.
3. 이제 설계를 해보자
기획도, 개발 스택 선정도 끝났으니 이제 아키텍쳐를 설계 할 시간 입니다. 저는 제 프로젝트의 아키텍쳐를 다음과 같이 잡았습니다.
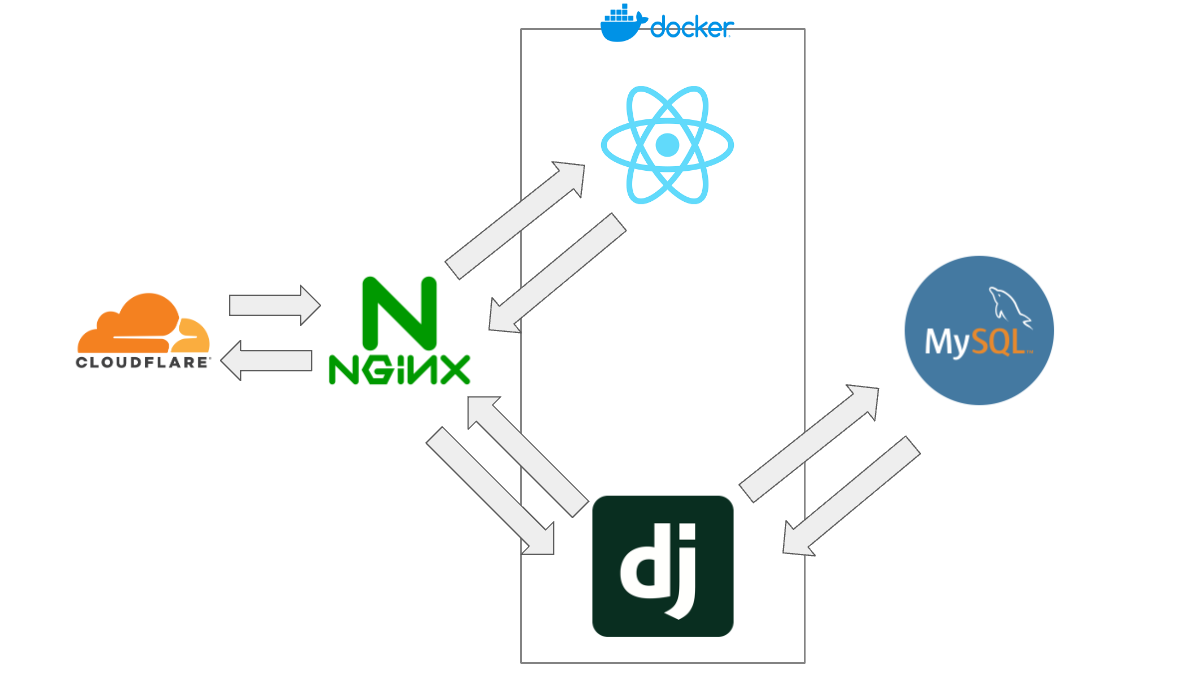
이 그림을 간략히 설명하면 다음과 같습니다.
- 사용자는 제 도메인과 연결된 클라우드 플레어에 요청을 보냅니다.
- 클라우드 플레어는 제 Nginx에 요청을 다시 보냅니다.
- Nginx는 해당 요청을 프론트엔드에 전달합니다.
- 프론트엔드는 백엔드에 전달할 요청을 다시 Nginx에 보냅니다.
- Nginx는 해당 요청을 백엔드에 전달합니다.
- 백엔드는 이 때 필요한 데이터의 생성이나 조회를 MySQL 커넥션을 통해 수행하고 결과를 응답 받습니다.
- 해당 결과에 따라 적절한 응답을 Nginx에 전달합니다.
- Nginx는 해당 응답을 프론트엔드에 전달합니다.
- 응답에 따른 페이지 랜더링 진행 후, 이를 Nginx에 전달합니다.
- Nginx는 이 응답을 클라우드 플레어에 전달 후, 클라우드 플레어가 사용자에게 응답을 전송합니다.
해당 요약을 보시고 왜 이렇게 설계했는지 이해가 안가는 부분은 두가지일 것이라고 생각됩니다. 첫 번째는 클라우드 플레어는 왜 사용했는가? 두 번째는 어차피 같은 도커 네트워크에 묶여 있을텐데 왜 굳이 Nginx를 통해서 패킷을 주고 받는가? 입니다.
우선 첫 번째 부터 말씀 드리면 해당 프로젝트를 운영하는 서버가 저희 집에 있기 때문입니다. 단순히 Nginx에 도메인 및 SSL 설정을 해서 운영을 할 수도 있겠지만 이 경우, 정말 간단한 명령어 한 줄에 저희 집의 실제 ip가 노출될 수 있습니다. 만약 공격자가 저희 집 실제 ip를 알아내어 공격을 할 경우에 보안성 우려, 인터넷 속도의 저하 및 심할 경우 공유기가 물리적으로 손상될 수 있습니다. 따라서 저는 클라우드 플레어를 사용해 실제 저희 집 ip를 숨기기로 결정 했습니다.
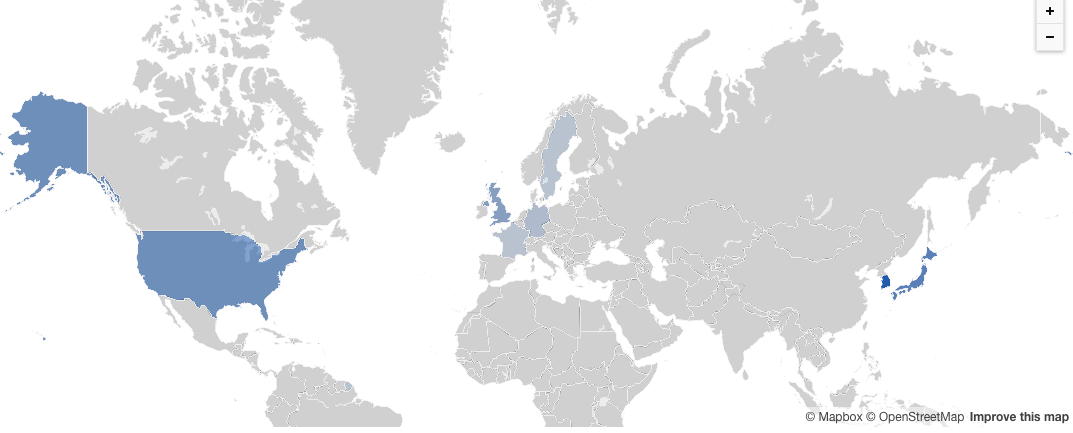
(제 조그마한 홈서버에 24시간 동안 정말 많은 나라에서 요청을 보내고 있습니다 🫠)
두 번째로 같은 도커 네트워크에 묶여 있을텐데 굳이 Nginx를 통해 패킷을 주고 받는 이유입니다. 이는 Nginx와 같은 리버스 프록시를 통해 패킷을 주고 받는 것이 조금 더 확장성 있고 보안에 좋을 것 같다는 판단이 들었기 때문입니다. 이 역시 자세하게 쓰면 리버스 프록시 칼럼을 쓰는 꼴이 되기에 3줄 요약하고 넘어가겠습니다.
- 적절한 로드 벨런싱이 가능합니다.
- SSL 인증서를 중앙 집중 식으로 관리할 수 있습니다.
- HTTP/2, SSL/TLS 버전 제어, 암호화 스위트 설정 등 다양한 보안 관련 기능을 제공합니다.
4. (드디어) 개발 시작...인데
"좋았쓰! 변환기"의 기능은 단순합니다. (프론트엔드 개발은 제가 한 것이 거의 없는데다 누군가에게 구조를 설명할 만큼 잘 안다고 생각하지 않아서 백엔드를 중점으로 작성하겠습니다.)
- 사용자가 입력한 문장을 request로 받아서
- 이를 프롬프팅 한 뒤,
- AI가 return한 답변을 response로 돌려주면 됩니다.
이를 위해서 저는 사용자의 요청을 받는 View, 요청 및 응답을 직렬화 할 수 있는 Serializer, 예외 처리 및 비즈니스 로직을 수행하는 Service, DB에 정보를 저장하거나 불러오는 Repository, DB와 직접적으로 커넥션을 맺고 DB 테이블 전체의 정보를 저장하는 Model 및 Anthropic API와 요청 및 응답을 주고받는 객체가 있는 Processor로 프로젝트 구조를 잡았습니다.
우선 1번을 위해 View와 Serializer에 각각 JoatssView 및 JoatssRequestSerializer를 추가해줬습니다. 이를 통해 요청을 View에서 받은 요청을 적절하게 직렬화 하고 유효성 검사까지 수행할 수 있었습니다.
그리고 2번을 위해서 Service와 Processor에 각각 JoatssService 및 AnthropicProcessor를 추가해줬습니다. 이를 통해 Service에서는 단순한 비즈니스 로직 수행과 이에 따른 적절한 예외 처리만을 수행할 수 있었고 AnthropicProcessor를 통해 복잡한 Anthropic SDK를 조금 더 간단하게 사용할 수 있도록 캡슐화를 할 수 있었습니다.
마지막으로 3번을 위해서 Service의 결과를 View에 전달할 Dto가 필요했고 이를 위해서 간단한 클래스를 빠르게 선언할 수 있는 Python의 dataclass를 사용했습니다. 이렇게 Service의 응답값을 Dto로 만든 뒤 View로 넘기고 해당 Dto를 Serializer를 통해 직렬화 하여 응답을 보낼 수 있었습니다.
이 모든 과정을 보면서 의문점이 총 2개 드실 거라 생각합니다. 첫 번째로 Repository와 Model은 사용되지 않았다는 점이고 두 번째로는 Dto를 통해 응답 객체가 이미 직렬화 됐을텐데 왜 다시 Serializer를 통해 직렬화 했냐는 점일 것 입니다.
우선 첫 번째 부터 설명 드리자면 이는 제 아키텍쳐와 기획에서의 실수입니다. DB가 필요 없는 서비스라는 걸 빠르게 파악하고 스택에서 제외했어야 했는데 이미 스택에 다 포함되어 버렸습니다. 따라서 저는 울며 겨자먹기로 비즈니스 로직에는 전혀 연관되지 않은 로깅용 테이블을 만들어 Service에서 이를 호출해 ip 로그를 남기는 용도로 사용하였습니다.
두 번째는 dataclass는 DRF Serialzer에 있는 기능이 많이 부재하기 때문입니다. 이것 또한 너무 자세하게 기술하면 dataclass 관련 컬럼을 쓰는 꼴이 될 테니 간략하게 세줄 요약하고 넘어가겠습니다.
- dataclass는 type에 대한 유효성 검사를 수행해주지 않습니다.
- 그럼 Pydantic을 사용하면 되지 않냐? 라고 할 수 있는데 Pydantic은 dataclass 보다 느립니다.
- 물론 DRF Serializer 보다는 빠르긴 합니다만, 이 경우 Pydantic의 유효성 겸사 결과를 다시 예외 처리 해주어야 한다는 불편함이 있습니다.
5. Github Action은 신이다.
모든 개발이 완료가 되었으니 이제 배포를 할 차례입니다. 저는 프로젝트를 도커 이미지로 말아 홈서버에 띄울 거기 때문에 프론트엔드와 백엔드에 Dockerfile을 만들어 줬습니다. 그리고 해당 파일을 직접 빌드 시키면 빌드 시간도 오래 걸리고 소스 코드 또한 모두 서버에 들어 있어야 한다는 단점이 있어 해당 이미지를 미리 빌드 시켜 Docker hub에 저장해놓기로 했습니다.
그렇다면 해당 이미지를 빌드 시켜 도커 허브에 저장해놓는 CI가 필요한데 저는 이를 위해서 Github Action을 선택했습니다. 제가 사용하는 git 저장소가 Github기도 하고 러닝 커브도 적은 편이라고 생각해서 모르는 기능이 있으면 하나하나 공부하면서 하면 되겠다고 생각했습니다.
하지만 유일한 걱정은 제 레포지토리들이 private이었는데 (지금은 frontend만 private입니다. 이유는 코드에 자신이 없어서..) private 레포지토리일 경우에는 Github Action이 과금을 해야지만 사용할 수 있는 줄 알았기 때문입니다.
"에이 돈 좀 내지 뭐"라는 마인드로 일단 workflows yaml을 작성해서 레포지토리에 push를 했는데 예상과는 다르게 잘 동작하는 것입니다! 나중에 찾아보니 private repository에 대한 Github Action의 과금 정책은 계정의 플랜에 따라 GitHub 호스팅 러너에서 사용할 수 있는 일정량의 무료 분과 스토리지를 제공해준다고 합니다. 이를 통해서 저는 성공적으로 제 도커 이미지를 빌드해 Docker hub에 저장하는 CI를 만들 수 있었고, 무사히 배포까지 진행해 드디어 "좋았쓰! 변환기"가 세상에 탄생하게 됩니다.
(사랑해요 Github Action)
6. 팩트는 실력이 건강해지고 있다는 거임.
이렇게 프로젝트가 성황리에 마무리 되었습니다. 사실 고백하자면, 저는 토이 프로젝트를 처음부터 끝까지 제 손으로 만들어 출시를 한 적이 처음입니다. 그러나 이렇게 처음으로 프로젝트를 만들어 출시까지 경험해보니 다음과 같은 점을 배울 수 있었습니다.
1. 등잔 밑 개어두웠네.
사람들은 생각보다 가까이 있는 것을 쉽게 발견하지 못하곤 합니다. 이는 저 역시도 그랬는데, 이 프로젝트를 하기 전의 저는 "아 토이 프로젝트 하고 싶은데 누구 좋은 아이디 있는 사람 없나~" 이 말을 입에 달고 살았습니다.

(이게 저였어요.)
(출처: insta @waterglasstoon)
그렇지만 이렇게 제가 일상 속에서 즐기고 있었던 곳에서 간단하게 아이디어를 얻은 만큼, 앞으로도 어디서든 아이디어를 발견해 즐겁게 개발 및 프로젝트를 진행할 수 있을 것이라는 자신감이 생겼습니다.
2. 스택! 정하기 전에 생각했나요?
앞의 제 글을 꼼꼼히 읽으신 분들이라면 제가 잘 정했고 잘 못 정한 스택이 각각 하나씩 있다는 것을 아실 겁니다. (모른다면 실망입니다.) 바로 잘 정한 것은 Django, 못 정한 것은 MySQL이었습니다. 이 두 스택을 꼽은 이유는 여러가지가 있지만 이를 한 줄로 요약하면 "목적에 따른 기술을 골라야 하는 이유"가 될 것 같습니다.
우선 Django는 예상대로 앞에서 서술한 Django 특유의 장점이 저의 빠른 개발에 큰 도움을 주었습니다. 다만 MySQL은 막상 도입하니 정말 사용도가 없었습니다. 제가 직접 LLM을 개발해 고도화된 결과를 위해서 학습 데이터로 쓴다면 좋은 선택일 수 있었겠지만 이는 저의 목적에 크게 어긋나는 결과입니다. 이 두 개의 상반된 사례를 바탕으로 저는 기술을 고를 때는 보다 신중하게 기술이 목적 달성에 얼마나 큰 효과를 줄 수 있는지를 고민해야 한다는 것을 알게 되었습니다.

(앞으론 하겠습니다.)
7. (지는 거에요?) 이겨.
사실 좋았쓰! 변환기의 결과만 놓고 보면 실패에 가깝습니다. 좋았쓰! 밈이 생각보다 대중화가 되지 않아서 이를 잘 모르는 사람이 많았다는 것이 원인으로 파악됩니다. 하지만 사이드 프로젝트에 실패는 없다고 생각합니다. 내가 내 스스로 정한 목표를 달성하고, 이를 달성하는 과정에 발전한 점과 개선할 점을 느끼며 성장했다면 그걸로 성공인 것 같습니다.
그치만 제 자식같은 프로젝트가 안쓰이는 건 여전히 맘 아프니까 글을 마무리 하면서 프로젝트 링크 놓고 가겠습니다. 여러분 한 번만 써주세요. 제발.

안녕하세요. 우연히 '좋았쓰' 고양이 밈을 검색하다가 이 프로젝트를 알게 되었습니다. 여러 문장에 대해 유연하게 응답하는게 신기해서 여기까지 찾아왔는데 어떤 원리로 작동하는지 알게 되어 시원하네요! 재미있는 프로젝트 만들어주셔서 감사합니다!