1.학습한 내용
필기체 인식
from keras import models
from keras import layers
network = models.Sequential()
#하나의 신경망을 시작하기 위한 코드의 시작, Sequential = 순차적
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
#첫 번째 레이어의 완성
network.add(layers.Dense(10, activation='softmax'))
#출력이 나오는 레이어
#activation = 어떤 값이 들어왔을때 그 값을 통과시킬지 말지를 결정하는 것
#결과치가 특정값 이상이면 반영 = Relu의 그래프 모양
#기본적으로 Relu를 가장 많이 사용
#값이 A,B가 있을 때 => 급격한 상승 그래프 sigmoid, tanh
#값이 여러개가 있을 때 => 자연스러운 상승 그래프 relu, leaky relu, elu
#softmax
#=입력받은 값을 0~1사이의 값으로 모두 정규화, 출력 값들의 총합은 항상 1이 되는 특성
#=분류하고 싶은 클래수의 수 만큼 출력으로 구성한다.
#=가장 큰 출력 값을 부여받은 클래스가 확률이 가장 높은 것으로 이용
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#optimizer = 손실값을 가져와서 각 층의 가중치를 조절해준다
#=경사하강법(Gradient Descent) = 기울기가 0에 가까운 최적치를 찾는것
#=경사하강법의 여러가지 다른 방법들이 존재한다
#=RMSProp(조금만 보고 빨리, 맥락을 봐가면서)
#=Adam(RMSProp+Momentum(스텝계산, 내려오던 방향으로))
#loss='categorical_crossentropy' => 손실값을 계산하고 분류
#손실값이 둘 중 하나를 판별하는 것일 때는 loss='binary underbar crossentropy' 사용
train_images = train_images.reshape(60000, 28*28)
train_images = train_images.astype('float32') /255
#실수형으로 바꾸는 작업
test_images = test_images.reshape(10000, 28*28)
test_images = test_images.astype('float32') /255
#실수형으로 바꾸는 작업
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
#데이터를 카테고리컬 데이터로 바꿔준다
#데이터 준비, 신경망 만들고, 이제 학습만 시키면 된다
network.fit(train_images, train_labels, epochs=5, batch_size=128)
#epochs = 학습회수
#batch_size = 학습시 학습량
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
test_acc: 0.9110999703407288
#1단계 작업 마무리
영화 리뷰 분류
#2단계 작업 시작(영화 리뷰 분류 예제)
#MDB 데이터셋 => 양극단의 리뷰 50000개
#train data 25000, test data 25000, keras에 포함되어 있음
#데이터는 전처리되어있어서 포함되어있는 단어들이 모두 숫자로 변환되어 있음
#신경망에 숫자 리스트를 바로 주입할 수 없음(텐서로 변환해야함)
#원 핫 인코딩을 사용해서 10000차원의 벡터로 변환해서 사용
import keras
from keras.datasets import imdb
(train_data, train_label), (test_data, test_label) = imdb.load_data(num_words=10000)
#num_words = keras에서 샘플을 가져올 때 자주 쓰는 것들만 추려서 가져오겠다는 명령어
len(train_data)
25000
len(test_data)
25000
train_data[0]
train_label[0]
#positive =1 , negative = 0
#데이터가 뜻하는 단어가 궁금할 때?
#word_index는 단어와 정수 인덱스를 매핑한 딕셔너리입니다
word_index = imdb.get_word_index()
#정수 인덱스와 단어를 매핑하도록 뒤집습니다
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
#리뷰를 디코딩합니다.
#0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위한 인덱스이므로 3을 뺍니다
decoded_review = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
#알파벳들을 숫자로 만들어 놓은 데이터 => 치환된 숫자들을 학습해서
#0,1로 긍정적, 부정적 문장들을 구분
import numpy as np
#one win incoding
#10000개짜리 배열을 만들고 word를 넣어 함수를 만들어보자
#0으로 다 채우고 해당하는 단어에만 1로 표시
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
#enumerate => 반복 가능한 개체로 바꿔준다, index번호가 자동으로 매겨진다
#index는 단어의 수만큼 들어간다
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#단어의 길이만큼 배열을 만든다 => 넘겨받은 sequence의 길이만큼 배열을 만든다
y_train = np.asarray(train_label).astype('float32')
y_test = np.asarray(test_label).astype('float32')
#실수형으로 바꾸기
#데이터 준비 완료
#model이라는 이름으로 3개의 신경망을 만들어보자
#16개 layerm 16개 layer 1개의 뉴런 => 최종결론 1또는 0
#ayer의 개수는 줄여나갈 수 있지만 줄였다가 다시 늘릴순 없다(정보의 손실때문)
#데이터가 들어오는 모양 => 폭이 10000개짜리, 입력되는 데이터의 모양은 10000개
#activation 함수는 sigmoid함수 사용, relu사용
#신경망을 미리 설계하는 과정이 필요하다
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#레고와 비슷하다
#input의 모양을 지정해줘야 한다
from keras import losses
from keras import metrics
from tensorflow.keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics='accuracy')
#optimizer=optimizers.RMSprop(lr=0.001) => 가중치 제어하는 것과 같다
#신경망 준비 완료
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
#슬라이싱 기법, 25000중에서 10000개를 뗴어낸다
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
#지금 전체 데이터 2세트
#train데이터 중 10000개를 잘라서 x_value에 저장,10000개 이후 나머지 부분을 partial_x에 저장
#학습, 검증
history = model.fit(partial_x_train,
partial_y_train,
epochs = 3,
batch_size = 512,
validation_data = (x_val, y_val))
#epochs = 학습회수
#batch_size = 학습시 학습량
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
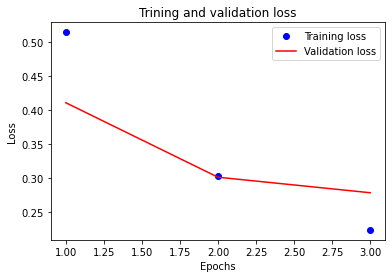
#x축에는 반복횟수(epochs), y축에는 loss값
#학습에 대한 loss값은 학습률이 증가할수록 감소하는데 이는 데이터의 과접합을 의미
#그래프로 그려보자
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'r-', label='Validation loss')
plt.title('Trining and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
#validation loss가 가장 낮을 때가 가장 높은 정확도가 나온다
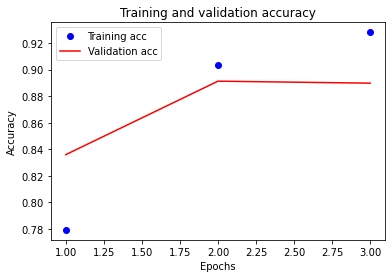
#정확도를 그래프를 그려보자
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'r-', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
#모델 평가
results = model.evaluate(x_test, y_test)
results
[0.2947840690612793, 0.8837599754333496]
#손실값, 정확도
#쇼핑몰에 리뷰가 달릴때 마다 이런 딥러닝을 통해 평가를 해준다
#만약 negative한 반응이 올때 담당자에게 알려줌으로써 즉각적으로 대응할 수 있게함
#예측치
model.predict(x_test)
#0에 가까울수록 nanative, 1에 가까울수록 positive
#이런 자료들을 분석report로 만들어서 위에 보고하는게 일
array([[0.3490996 ],
[0.9973907 ],
[0.9564816 ],
...,
[0.20124963],
[0.27750385],
[0.6183299 ]], dtype=float32)
이미지 인식
#CNN(convolutional Neural Networks)
#이미지를 인식하기 위해 패턴을 찾는데 유용
#데이터 학습, 패턴을 사용해 이미지를 분류
#특징을 수동으로 추출할 필요없다
#자율주행, 얼굴인식과 같은 객체인식이나 computer vision이 필요한 분야에 많이 사용
#AI에는 크게 3가지 분야
#데이터 분석, computer vision, NLP(자연어 처리)
#computer vision => 사진분석, 동영상분석
import keras
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu',input_shape=(28,28,1)))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPool2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
#특성을 뽑아내는 작업
#flatten layer 플래튼 레이어
#이미지를 데이터화, 일자로 길게 펴는 작업
#분류하는 작업 => dense layer로 뽑아내게 된다
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
#더 깊어진 신경망을 썼다
#신경망의 깊이가 깊어지면 깊어질수록 연산 시간이 길어진다
from keras.datasets import mnist
#0~9사이의 값
from tensorflow.keras.utils import to_categorical
#학습,테스트 데이터 가져오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
#데이터 준비(모양바꾸기)
#각각의 픽셀 데이터 = 0~255의 gray 칼라값
train_images = train_images.reshape((60000,28,28,1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000,28,28,1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#신경망 완성
#학습
model.fit(train_images, train_labels, epochs=5, batch_size=64)
#평가
test_loss, test_acc = model.evaluate(test_images, test_labels)
loss: 0.0293 - accuracy: 0.9926
test_acc
0.9926000237464905
-
학습내용 중 어려웠던 점
-여러가지 예제들을 실습해보았다. 예제 생성하는 코드를 따라가면서 만들어보니 신기했지만 이해하기가 너무 쉽지 않다. 특히 이미지 인식 예제는 알아두면 참 좋을것 같은데 쉽지 않다. -
해결방법
-지금 배우는 코드들이라도 외우고 어떤 경우에 쓰이는지 해보는 수 밖에 없다. -
학습소감
-예제들을 따라가다보니 분량에 치인다. 최대한 깔끔하게 정리해서 깃허브에도 올려봐야 하는데 밀리는 느낌이 크다. 좀 더 시간을 내야한다.
