[Advanced C++] 42. container size & index type(signed, unsigned, size_t), size(), ssize(), indexing, std::vector passing, at(), copy semantic, move semantic
Advanced C++

1. 컨테이너 길이의 부호 문제
컨테이너 길이의 부호 문제
우선 배열의 [ ]에 사용되는 데이터 타입은 배열의 길이를 저장하는데 사용되는 데이터 타입과 일치해야 한다
즉 [ ]안에 사용하는 숫자의 타입은 일반적으로 배열의 길이를 나타내는 데이터 타입인 std::size_t여야 가장 안전하고 이상적이라는 의미이다
이론상 가장 긴 배열의 모든 요소를 인덱싱할 수 있다
std::size_t는 부호 없는 정수 타입이기 때문에 음수가 될 수 없고 배열의 최대 인덱스도 접근이 가능하기 때문이다 (size_t는 큰 부호없는 정수 타입에 대한 typedef이고 unsigned long이나 unsigned long long이다)
컨테이너 클래스가 설계될 때 설계자들은 배열의 길이 및 첨자를 signed로 할지 unsigned로 할지 고민하다가 unsigned로 설계하는걸 선택했다, 이는 unsigned를 사용하게 되면 더 큰 범위의 index를 사용할 수 있고(-21억 ~ 21억을 0 ~ 42억까지) unsigned 사용 시 첨자의 범위 검사 시 음수 확인이 필요 없기 때문에 선택한 것이다
하지만 이는 잘못된 선택으로 여겨진다, 결국 암시적 변환으로 부호가 있는 음의 정수는 큰 부호 없는 정수(쓰레기값)으로 변환되기 때문이다
또한 배열의 길이를 20억개 이상 사용하는 경우는 거의 없기 때문에 딱히 의미가 없다
결국 signed와 unsigned를 혼합해서 사용하는건 의도치 않은 동작을 발생시킬 수 있지만 이러한 컨테이너 클래스를 사용할때는 피할 수 없다는 의미이다
일반적으로 부호 변환은 축소 변환 (narrowing conversion)으로 된다, 왜냐하면 부호 있는 타입 -> 부호 없는타입이나 부호 없는 타입 -> 부호 있는 타입은 서로 모든 값을 포함할 수 없기 때문이다
int a{ 10 };
[[maybe_unused]] unsigned int u{ a }; //compile error (리스트 초기화의 축소 변환 방지)리스트 초기화는 축소 변환을 방지하기 때문에 signed -> unsigned의 변환을 막는걸 볼 수 있다
단 변환될 값이 constexpr이고 데이터 손실 없이 값이 변환될 수 있다면 부호 변환은 축소 변환으로 간주되지 않는다
constexpr int a{ 10 };
[[maybe_unused]] unsigned int u{ a }; //ok각 표준 컨테이너 클래스는 size_t라는 typedef를 정의한다, 이는 컨테이너의 길이 및 인덱스에 사용되는 타입 별칭이다
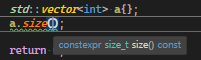
다음과 같이 컨테이너 클래스의 size_type을 가져올 수 있다 (std::size_t와 같다고 보면 된다, 컨테이너들은 자신의 size_type을 정의할 때 std::allocator의 size_type을 사용하고 이 std::allocator의 size_type은 C++표준에 의해 std::size_t로 정의되어 있음)
size_type은 std::size_t의 별칭임
std::vector<int>::size_type;컨테이너 클래스 객체의 길이
size()함수를 사용하면 된다
std::vector<int> a{ 1, 2, 3, 4, 5 };
std::cout << a.size() << std::endl; //5출력
size()는 부호 없는 size_type으로 return한다
std::size_t testvectorsize = a.size(); //size_type은 std::size_t와 같다고 보면 되기 때문에 이러한 표현식이 가능하다추가로 std::size()라는 비멤버 함수 사용도 가능하다
std::vector<int> a{ 1, 2, 3, 4, 5 };
std::cout << std::size(a) << std::endl; //5출력이때 std::size()값을 부호 있는 타입의 변수에 저장할 때 constexpr이더라도 데이터 손실 위험이 있으면 에러가 발생한다, static_cast<>로 캐스팅 하고 사용하는게 좋다
std::vector<int> a{ 1, 2, 3, 4, 5 };
int i{ a.size() }; //a.size()가 constexpr을 return하지만 데이터 손실 위험이 있어 error
int i{ static_cast<int>(a.size()) }; //okC++20부터는 std::ssize()라는 비멤버 함수가 도입되었다, 이 함수는 길이를 큰 부호있는(signed) 정수 타입 (constexpr std::ptrdiff_t타입 으로 return해준다)
std::vector<int> a{ 1, 2, 3, 4, 5 };
std::cout << std::ssize(a) << std::endl;하지만 여전히 축소 변환의 위험이 있기 때문에 static_cast<>로 명시적인 변환을 사용해주는게 좋다
std::vector<int> a{ 1, 2, 3, 4, 5 };
int i{ static_cast<int>(std::ssize(a)) };혹은 auto를 사용하여 컴파일러가 올바른 타입을 추론하게 하는것도 좋은 방법이다

이전에 정리했듯 operator[ ]는 bound check를 하지 않는다
std::vector<int> a{ 1, 2, 3, 4, 5 };
a[10]; //crash하지만 at() 멤버함수를 사용한 배열의 element 접근은 런타임에 bound check를 진행한다
std::vector<int> a{ 1, 2, 3, 4, 5 };
a.at(10);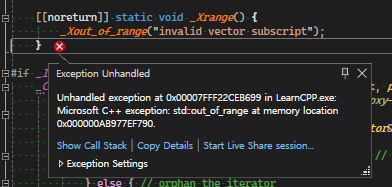
a.at(10)은 a배열에서 유효하지 않은 index이기 때문에 std::out_of_range 예외를 던진다
assert나 if로 미리 체크하고 인덱싱 하는것이 좋다
#include <cassert>
assert(a.size() > 10);
if (a.size() <= 10)
{
return;
}at()과 [ ]에 사용되는 index는 non-const가 될 수 있다
at()은 operator[ ]와 다르게 런타임에 매 호출마다 bound check를 하기 때문에 조금 더 느리지만 안전하다, 보통은 operator[ ]가 더 많이 사용되고 index를 사용하기 전에 미리 check하는 방식으로 사용하여 operator[ ]의 단점을 해소한다
인덱싱
constexpr signed 타입으로 std::vector를 인덱싱할 때는 컴파일러가 축소변환 없이 std::size_t로 암시적 변환이 가능하다
std::vector<int> a{ 1, 2, 3, 4, 5 };
constexpr int index{ 2 };
a[index]; //축소변환이 일어나지 않는다배열의 index는 non-const가 될 수 있다, 컴파일러는 index를 std::size_t로 암시적 변환하지만 축소 변환이 일어나게 된다
std::vector<int> a{ 1, 2, 3, 4, 5 };
int index{ 2 };
a[index]; //축소 변환 발생, 부호 변환 경고가 나올 수 있다따라서 non-const index라면 std::size_t를 타입으로 사용하여 축소 변환이 일어나지 않게 하는게 좋다
std::vector<int> a{ 1, 2, 3, 4, 5 };
std::size_t index{ 2 };
a[index]; //축소 변환 발생X또한 std::vector 자체를 인덱싱하는 대신 data() 멤버 함수를 통해 std::vector의 element가 보관된 C-style 배열의 포인터를 가져와 인덱싱 하는 방법도 있다
std::vector<int> a{ 1, 2, 3, 4, 5 };
a.data()[2];C-style의 배열은 signed, unsigned 타입 모두로부터 인덱싱을 허용하기 때문에 부호 변환 문제를 발생시키지 않는다
std::vector passing
std::vector 타입의 객체는 다른 객체와 마찬가지로 전달이 될 수 있다
std::vector 또한 pass by value를 하면 비용이 많이 드는 복사가 발생한다
따라서 class타입과 마찬가지로 이러한 복사를 피하기 위해 참조 전달, 주소 전달을 이용한다
(매개변수 작성 시 element 타입을 반드시 명시해야 한다)
void Foo(const std::vector<int>& InVector)
{
std::cout << InVector.at(0) << std::endl;
}매개변수로 element 타입을 명시하기 때문에 다른 타입의 vector는 넘길 수 없다
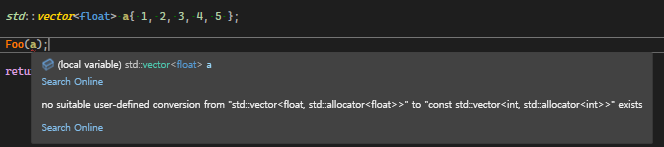
CTAD는 초기화자로부터 타입을 추론할 수 있지만 함수의 매개변수를 추론하는데 사용할 수 없기 때문에 다음과 같은 표현식은 컴파일 에러를 발생시킨다
void Foo(const std::vector& InVector)
{
std::cout << InVector.at(0) << std::endl;
}이럴때 함수 템플릿을 사용하면 다양한 타입의 vector를 전달할 수 있다
template <typename T>
void Foo(const std::vector<T>& InVector)
{
std::cout << InVector.at(0) << std::endl;
}
int main()
{
std::vector a{ 1, 2, 3, 4 };
std::vector b{ 1.5, 2.5, 3.5 };
Foo(a);
Foo(b);
}CTAD에 의해 a, b vector의 타입이 정해지고 Foo()에서 템플릿 인수 추론으로 인자로 넣은 타입의 vector를 받아 처리하게 된다
더욱 간단하게 어떤 타입의 객체든 받아들일 수 있는 함수 템플릿을 만들어 사용도 가능하다
template <typename T>
void Foo(const T& InVector)
{
std::cout << InVector.at(0) << std::endl;
}
int main()
{
std::vector a{ 1, 2, 3, 4 };
std::vector b{ 1.5, 2.5, 3.5 };
Foo(a);
Foo(b);
} .at()이 구현된 객체라면 뭐든 사용이 가능하다, [ ]를 사용한다면 operator [ ]가 구현된 객체라면 전부 사용이 가능하다
C++20부터는 축약형 함수 템플릿을 사용하여 (auto) 동일한 작업을 할 수 있다
void Foo(const auto& InVector)
{
std::cout << InVector.at(0) << std::endl;
}
int main()
{
std::vector a{ 1, 2, 3, 4 };
std::vector b{ 1.5, 2.5, 3.5 };
Foo(a);
Foo(b);
}편하긴 하지만 원하지 않는 객체를 인자로 받아들일 수 있다는 점에서 단점이 될 수 있다 (버그로 이어질 가능성이 높다)
copy semantic (복사 의미론)
특정 타입이 copy semantic을 지원한다고 하면 해당 타입의 객체가 복사가 가능하다는걸 의미한다
copy semantic이 호출되면 결국 객체의 사본을 만들게하는 특정 작업이 수행되었다는걸 의미한다
클래스 타입인 경우에는 copy semantic은 복사 생성자, 복사 대입 연산자를 통해 구현되고, 해당 클래스 타입의 객체가 어떻게 복사되는지를 정의하는것이다
std::vector arr1 { 1, 2, 3, 4, 5 }; // { 1, 2, 3, 4, 5 }를 arr1으로 복사, initialize-list<>를 인자로 받는 생성자에서 복사
std::vector arr2 { arr1 } //arr1을 arr2로 복사 (복사 생성자 호출)
//arr1과 arr2의 element는 전부 동일하지만 각각 독립적인 객체이다다음과 같은 경우는 copy semantic이 optimal하지 않을때이다
std::vector<int> Foo()
{
std::vector<int> a{ 1, 2, 3, 4, 5 };
return a;
}
int main()
{
std::vector<int> arr{ Foo() };
}arr을 초기화 할때 Foo()라는 std::vector< int > 타입의 임시 객체를 return값으로 받아 초기화 된다, 이는 표현식의 끝에서 소멸되는 rvalue이기 때문에 해당 시점 이후에는 사용이 불가능하다
결국 임시객체가 소멸된 후에도 사용하기 위해서 복사를 하여 초기화를 한 코드이다, 코스트가 높은 copy semantic이 이러한 케이스에서는 optimal하지 않다는 의미이다
move semantic
그렇다면 위에서 arr이 Foo()로부터 생성된 임시객체를 복사해서 초기화 하는 방법 말고 데이터를 단순히 이동시키는 방법은 없을까? 그게 바로 move semantic 개념이다
이동비용은 복사 비용에 비해 매우 코스트가 낮다 (두개 세개 포인터 할당 정도), 추가로 임시객체의 데이터를 이동시키게 되면 임시객체가 소멸될 때 결국 파괴할 데이터가 없기때문에 이러한 비용도 제외된다
결국 move semantic이란 한 객체의 데이터가 다른 객체로 어떻게 이동되는지를 결정하는 규칙을 의미한다, move semantic이 호출되면 이동할 수 있는 모든 데이터는 이동되고 이동할 수 없는 데이터는 복사된다
(데이터 소유권 이동)
비싼 복사를 대체할 수 있는 케이스에서 move semantic은 의미가 있어진다
일반적으로 같은 타입의 객체로 초기화 되거나 할당되면 copy semantic이 사용된다 (복사 생략X 가정시)
단 다음의 조건이 모두 참이면 move semantic이 호출된다
- 객체의 타입이 move semantic을 지원할 때
- 객체가 동일한 타입의 임시객체 rvalue로 초기화되거나 할당될 때
- 이동이 생략되지 않을때
생각보다 많은 타입이 move semantic을 지원하지는 않지만 std::vector, std::string은 둘 다 지원한다
따라서 std::vector는 이동 가능한 타입이기 때문에 return by value가 효율적이다
return by value는 rvalue를 반환하기 때문에 반환된 값인 rvalue가 대상 객체로 복사되지 않고 이동될 수 있다, 따라서 std::vector는 return by value가 효율적이다
(인자 전달은 참조, 포인터 전달 해야함)
std::vector<int> doSomething(std::vector<int> v2)
{
// 3 -- 호출자에게 반환될 값 생성 (v3)
std::vector v3 { v2[0] + v2[0] };
return v3; // 4 -- 실제로 값 반환 (이동 또는 복사 발생 가능성)
}
int main() {
std::vector v1 { 5 }; // 1 -- 함수에 전달될 값 생성 (v1)
// 2 -- 실제로 값 전달 (v1 -> v2 복사 발생)
std::cout << doSomething(v1)[0] << '\n'; // 출력: 10
std::cout << v1[0] << '\n'; // 출력: 5 (v1은 변경되지 않음)
return 0;
}std::vector가 move가 불가능하고 복사 생략이 없다고 가정하면
- 초기화 리스트로 5값을 v1으로 복사
- v1을 함수 매개변수 v2로 복사
- v2[ 0 ] + v2 [ 0 ] 값 초기화리스트가 v3로 복사
- v4를 복사하여 return
총 4번의 복사가 발생한다
여기서 1,3번은 최적화가 불가능하다 (객체가 생성되는 과정이기 때문)
2번 같은 경우는 참조나 주소 전달 방식으로 변경하여 최적화가 가능하다
이때 의미없는 복사가 아니기 때문에 복사 생략은 일어나지 않는다, 인자가 lvalue이기 때문에 move semantic 사용이 불가하다 (만약에 move를 한다고 하면 v1에서 v2로 데이터가 옮겨가기 때문에 v1은 비어있는 vector가 된다)
이럴때 2번같은 경우는 무조건 참조나 주소 전달 방식이 최선이다
4번은 참조나 주소로 return하게 되면 로컬 변수는 함수 종료 시 소멸되고 dangling pointer참조가 발생할 수있다, 따라서 불가능하다
이러한 복사는 생략이 가능하다
v3는 함수 return 시 소멸될 것이기 때문에 move를해서 호출자에게 이동시켜 복사를 피할 수 있다
(컴파일러가 복사 생략을 하지 않고 move semantic이 가능한 타입이라면 return by value 시 자동으로 move semantic이 호출된다)
정리하면 move semantic이 지원되는 타입은 참조나 포인터 전달, 값 반환을 권장한다
