[Advanced C++] 43. Container & loop, off-by-one error, container loop에서의 부호 문제, for-each, enum & enum class를 이용한 인덱싱 및 길이관리
Advanced C++

1. Array and loop
Array and loop
배열의 모든 element를 순회(iterating)하려면 어떻게 해야할까?
배열의 index는 반드시 상수 표현식일 필요가 없고 런타임 표현식이 될 수 있다 (변수의 값을 index로 사용할 수 있음)
반복문을 이용하면 배열의 모든 element를 순회할 수 있다
std::vector<int> vec{ 10, 20, 30, 40, 50 };
std::size_t length{ vec.size() };
int total{ 0 };
for (std::size_t index{ 0 }; index < length; ++index)
{
total += vec[index];
}
int average{ total / static_cast<int>(length) };최대 index를 vector의 size()로 지정함으로서 vector의 길이가 달라져도 수정이 필요 없는 유지보수성이 좋은 순회 코드이다
이러한 iterating 코드를 조금 더 확장성 있게 만들기 위해 함수 템플릿을 이용할 수 있다
template <typename T>
T calcAverage(const std::vector<T>& vec)
{
std::size_t length{ vec.size() };
if (length <= 0)
{
return 0;
}
T total{ 0 };
for (std::size_t index{ 0 }; index < length; ++index)
{
total += vec[index];
}
return total / static_cast<T>(length);
}
int main()
{
std::vector<int> vec{ 10, 20, 30, 40, 50 };
std::vector<float> vec1{ 11, 22, 33, 44, 56 };
std::cout << calcAverage(vec1) << std::endl;
}이때 T가 클래스 타입이라면 T total{ 0 }; 초기화 구문은 작동하지 않을 수 있다, template을 사용하여 T{}로 초기화하면 해당 타입의 기본값으로 초기화된다 (int는 0, double은 0.0)
또한 T가 지원하지 않는 연산자를 사용하면 컴파일 에러를 발생시킨다
0으로 나누면 크래시가 발생하기 때문에 length가 0보다 작거나 같으면 early return 처리를 함
off-by-one error
index를 이용하여 배열의 모든 element를 iterating할 때 주의할 점은 정확한 횟수만큼 실행되게 하는것이다
(n번 더 실행, n번 덜 실행되면 의도치 않은 동작을 할 수 있다)
또한 배열의 length를 최대 index로 사용할 때 반드시 <=가 아닌 <로 사용해야 out of bounds가 발생하지 않는다 (0부터 시작이기 때문에)
Array loop에서 부호 문제
std::vector 및 다른 컨테이너 클래스의 길이와 index는 unsigned 정수 타입인 std::size_t를 사용한다, 이러한 unsigned 타입은 문제가 될 수 있다
template <typename T>
T print(const std::vector<T>& InVec)
{
for (std::size_t index{InVec.size() - 1}; index >= 0; --index)
{
std::cout << InVec[index] << std::endl;
}
}만약 InVec의 size()가 0이라면 for()를 시작하자마자 음수가 된다, 이때 타입이 unsigned이기 때문에 매우 큰 양수가 되고 의도치 않은 동작이 될 수 있다
(infinite loop 가능성, 언더 플로우가 발생하여 매우 큰 양수로 변경되어 의도치 않은 동작 발생)
그렇다면 어떻게 처리하는게 좋은 방법일까?
단순하게 생각하면 index를 size_t로 사용하지 않고 signed int로 사용하는것이다
template <typename T>
T print(const std::vector<T>& InVec)
{
for (int index{ static_cast<int>(InVec.size() - 1) }; index >= 0; --index)
{
std::cout << InVec[static_cast<size_t>(index)] << std::endl;
}
}정상적으로 작동하지만 static_cast<>가 들어가 코드가 복잡해지고 가독성이 매우 낮아졌다
다른 방법으로는 size_type을 사용하는 방법이다
size()는 size_type을 return하고 operator[ ]는 size_type을 index로 쓰기 때문에 사실 size_type을 사용하는게 가장 일관성있고 안전한 unsigned 타입이다 (정말 드물게 size_type이 size_t 이외의 다른 것에도 작동하기 때문)
template <typename T>
void print(const std::vector<T>& InVec)
{
for (typename std::vector<T>::size_type index{ 0 }; index < InVec.size(); ++index)
{
std::cout << InVec[index] << " ";
}
}size_type은 nested type이기 때문에 클래스::를 이용하여 접근해야 한다
(std::size_type이 아닌 std::vector<>::size_type)
가독성이 떨어지게 된다
template 매개변수에 의존하는 중첩된 이름을 타입으로 사용 시 typename 키워드를 접두사로 붙여야 한다 (그래야 컴파일러가 타입이라는걸 인지한다)
std::vector<T>::size_type index//template 매개변수에 의존하는 중첩된 이름 (error)
typename std::vector<T>::size_type index//ok
T total{ 0 }; //ok, 중첩된 이름이 아님, T자체가 이미 타입이기 때문에 typename키워드 없이 사용가능위의 std::vector< int >::size_type을 편하게 사용하기 위해 타입 별칭을 사용하는 경우도 있다
using arrayindex = std::vector<int>;
template <typename T>
void print(const std::vector<T>& InVec)
{
for (arrayindex::size_type index{ 0 }; index < InVec.size(); ++index)
{
std::cout << InVec[index] << std::endl;
}
}혹은 매개변수의 type을 반환하는 decltype를 사용하여 대체할 수 있다 (단 매개변수가 참조타입인 경우 ::로 접근이 불가능하기에 아래처럼 사용은 불가능하다)
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
for (decltype(testvec)::size_type index{ 0 }; index < testvec.size(); ++index)
{
std::cout << testvec[index] << std::endl;
}또 다른 방법은 signed loop variable을 사용하는 방법이다
그렇다면 어떤 signed 타입을 사용해야할까?
대표적으로 int, std::ptrdiff_t, auto가 있다
기본적으로 int는 기본 signed 정수 타입으로서 어마어마하게 큰 배열이 아닌이상 int를 사용하는것이 좋다
(std::size_t에 암시적 변환이 됨)
std::ptrdiff_t는 매우 큰 배열을 다루거나 방어적 코딩에 사용한다 (cstddef헤더가 필요)
(이러한 std::ptrdiff_t는 type alias를 만들어 사용하는것이 보기에 좋다)
#include <cstddef>
using ArrayIndex = std::ptrdiff_t;
int main()
{
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
for (ArrayIndex index{ 0 }; index < testvec.size(); ++index)
{
std::cout << testvec[index] << std::endl;
}
}초기화 값에서 타입을 추론할 수 있을경우 auto를 사용하는것도 좋다
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
for (auto index{ static_cast<std::ptrdiff_t>(0) }; index < testvec.size(); ++index)
{
std::cout << testvec[index] << std::endl;
}C++23부터는 Z접미사를 사용하여 std::size_t의 signed 대응 타입(str::ptrdiff_t)의 literal 정의가 가능하다
for (auto index{ 0Z }; index < std::ssize(arr); ++index) { /* ... */ }배열의 길이를 signed type으로 얻어오려면 C++20 이전에는 size()를 static_cast< >하여 사용하는 방법이 최선이었다
auto len{ static_cast<std::ptrdiff_t>(arr.size()) };C++20 이후부터는 std::ssize()라는 함수로 배열의 크기를 signed type(ptrdiff_t)으로 얻어올 수 있다
#include <utility>
std::ssize(arr);
이렇게 signed 타입의 index 변수를 만들고 나서 [ ]에 사용하려면 암시적 변환 경고가 발생할 수 있다, 사용 시 static_cast로 변환해서 사용한다 (operator[ ]는 size_type을 사용하기 때문)
using ArrayIndex = std::ptrdiff_t;
int main()
{
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
ArrayIndex index{ 0 };
for (index; index < std::ssize(testvec); ++index)
{
std::cout << testvec[static_cast<std::size_t>(index)] << std::endl;
}
}만약 함수 템플릿에서 변환 함수를 만든다면 T에 대한 타입 체크가 필요할 수 있다
static_assert(std::is_integral_v<T> || std::is_enum_v<T>);이렇게 std::is_???_v< type >로 체크가 가능하고 static_assert를 사용하면 된다 (그냥 int, double도 사용할 수 있고 템플릿 매개변수 T도 사용 가능)
또 다른 방법은 STL의 컨테이너를 인덱싱 하는 방법 대신 C-style 배열을 인덱싱 하는 방법이다
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
testvec.data()[0];data()로 배열 데이터를 C-style 배열 포인터로 반환하여 사용하는것이다 (C-style 배열은 signed, unsigned 둘다 경고 없이 인덱싱이 가능함)
그리고 아예 foreach를 사용하거나 iterator를 이용하여 인덱싱 자체를 피하는 방법도 있다 (추후에 정리)
for-each
위에 정리한 for loop 배열 순회는 off by one error가 발생하기 쉽고 인덱싱 부호 문제에 취약하다
프로그램을 개발하며 배열을 순회하는건 굉장히 자주 있을 상황이다, 이에 맞춰 C++은 범위 기반 for loop를 지원한다 (ranged-based-for loop) (for-each라고 부른다)
for-each는 명시적인 인덱싱 없이 배열을 순회하게 해준다
for(element선언 : 배열)
{
}
std::vector<int> testvec{ 1, 2, 3, 4, 5 };
for (int element : testvec)
{
std::cout << element << std::endl;
}for-each에 선언된 element에 배열의 element값이 복사된다 (타입에 따라 비용이 크게 들 수 있다)
특별한 경우가 아니면 배열을 순회할때는 명시적인 인덱싱 없는 for-each를 권장한다
만약 순회하려는 array가 empty하다면 for each문은 돌지 않는다
std::vector여기서 element를 선언할 때 auto를 사용하여 컴파일러의 타입 추론을 사용하는것도 가능하다 (개인적으로 선호하지는 않음)
for (auto element : testvec)
{
}추후에 배열의 element type이 변경되는 작업이 들어와도 수정할 필요가 없어진다 (이것이 오히려 단점으로 돌아올 수 있음, 갑작스러운 타입 변화로 복사 비용이 늘어난다던가 하는.. ex) std::string_view -> std::string으로 변경되면 잘 동작하지만 성능저하가 발생한다)
또한 명확한 타입 확인이 힘들다는 단점도 존재한다
(개인적으로 auto는 cast와 마찬가지로 명확한 타입이 존재할 때 사용하는걸 선호함)
for-each에 선언된 element에는 배열의 element값이 복사되기 때문에 타입에 따라 비용이 크게 들 수 있다, 이러한 복사를 방지하기 위해서는 역시나 참조나 포인터를 사용하면 된다
std::vector<std::string> testvec{ "mom", "dad", "me" };
for (std::string element : testvec) //std::string의 복사로 인해 비용 상승
{
std::cout << element << std::endl; //비싸게 복사한 데이터를 단순히 여기서만 사용되고 소멸
}
for (const std::string& element : testvec) //&로 복사 비용 발생X
{
std::cout << element << std::endl;
}auto도 마찬가지이다, 복사 비용이 큰 타입일 경우 그냥 auto&를 사용하고(수정할 수 없게 하려면 const auto&) 그렇지 않다면 auto를 사용한다
auto는 왠만하면 const auto&를 사용하는것이 좋다, 타입이 바뀌어도 불필요한 복사를 방지할 수 있기 때문이다 (자동으로 컴파일러가 타입 추론을 하기 때문에 동작은 하지만 불필요한 복사가 많이 발생할 수 있다)
이러한 for-each는 vector뿐 아니라 다양한 컨테이너 타입에서 동작한다
(C-style array, std::array, std::vector, list, map 등등)
단 decayed된 C-style array는 사용이 불가능하다
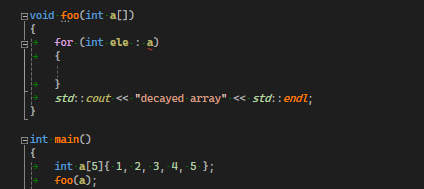
함수에 배열을 넘길때 위와 같이 넘기게 되면 배열의 시작(0번째) 포인터가 넘어가기 때문에 배열의 전체 길이 정보를 알지 못한다 이런 상황을 배열이 decay되었다고 한다 (붕괴) 따라서 for-each가 동작하지 않는다
for-each문에서는 현재 element의 index를 얻을 수 있는 방법이 없다 (이는 for-each가 동작하는 다른 컨테이너 클래스인 std::list와 같은 컨테이너에서 index를 지원하지 않기 때문이다)
따라서 index가 꼭 필요하다면 for loop를 사용하는것을 고려해야한다
for-each는 forward방향으로 순회한다 (0 ~ end), 그렇다면 reverse로 순회하려면 어떻게 해야할까?
C++20이전에는 for-each로는 쉽게 할 수 없었고 일반 for loop를 사용해야 했다, 하지만 C++20부터 ranges라이브러리의 reverse기능을 사용하여 reverse iterating이 가능하다
#include <ranges> //C++20 Ranges library
int main()
{
std::vector<std::string> testvec{ "mom", "dad", "me" };
for (const auto& word : std::views::reverse(testvec))
{
std::cout << word << std::endl;
}
}std::views::reverse()로 reverse view를 제공하여 reverse iterating이 가능하다
(#include < ragnes >가 필요함)
enum을 이용한 배열 인덱싱 및 길이 관리
단순히 정수형을 배열의 인덱스로 사용하면 의미가 명확하지 않다
std::vector testvec{ 150, 160, 170 };
testvec[2]; //이게 어떤 element를 의미하는건지 명확하지 않다위에서 정리했듯 인덱스의 타입은 size_type이다 (std::size_t의 type alias), 따라서 인덱스는 size_type이거나 size_type으로 암시적 변환이 되어야 한다
enum은 std::size_t로 암시적 변환이 가능하기 때문에 index로 enum을 사용할 수 있다
namespace Family
{
enum Name
{
Mom, //0
Dad, //1
Me //2
};
}
int main()
{
std::vector testvec{ 150, 160, 170 };
std::cout << testvec[Family::Dad] << std::endl; //160출력
}조금 더 element의 의미가 명확해진걸 확인할 수 있다
이때 enum의 기본 타입을 명시적으로 unsigned로 처리하면 부호 변환 문제가 발생하지 않는다
namespace Family
{
enum Name : unsigned int //enumerator의 기본타입을 unsigned int로 지정
{
Mom,
Dad,
Me
};
}
int main()
{
std::vector testvec{ 150, 160, 170 };
Family::Name name{ Family::Dad };
std::cout << testvec[name] << std::endl; //unsigned int이기 때문에 부호 변환이 발생하지 않음 (name은 unsigned int임이 보장됨)
}count enumerator를 사용하여 컨테이너에 유용하게 사용이 가능하다
namespace Family
{
enum Name : unsigned int
{
Mom,
Dad,
Me,
FamilySize //count enumerator (가능한 enumerator의 총 갯수가 된다)
};
}
int main()
{
std::vector<int> testvec(Family::FamilySize); //가능한 Family::Name enum의 enumerator최대 갯수
testvec[Family::Mom] = 150;
}enumerator의 추가가 있어도 count enumerator 위에 선언을 한다면 count enumerator는 자동으로 늘어나게 되어 수정 없이 사용이 가능하다
배열의 크기와 비교할때도 유용하게 사용이 가능하다
assert(std::size(testvec) == Family::FamilySize);
//이때 배열이 constexpr이라면 static_assert()사용!
//vector는 constexpr을 지원하지 않지만 std::array, C-style 배열은 지원한다enum class는 정수 타입으로의 암시적 변환이 없기 때문에 해당 enum class의 enumerator를 배열의 index로 사용한다면 에러가 발생한다
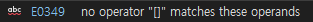
enum class FamilyName
{
Mom,
Dad,
Me,
Counts
};
int main()
{
std::vector<int> testvec{ 150, 160, 170 };
std::vector<int> testvec1(FamilyName::Counts); //배열의 길이는 size_t라 enum class의 enumerator가 암시적 변환이 불가능하여 에러
testvec[FamilyName::Dad] = 150; //배열의 인덱스는 size_t라 enum class의 enumerator가 암시적 변환이 불가능하여 에러
}이를 해결하는 가장 간단한 방법은 static_cast<>로 캐스팅 하는것이다
enum class FamilyName
{
Mom,
Dad,
Me,
Counts
};
int main()
{
std::vector<int> testvec1(static_cast<std::size_t>(FamilyName::Counts));
testvec1[static_cast<std::size_t>(FamilyName::Dad)] = 150;
}하지만 가독성이 너무 떨어지는 단점이 있다
따라서 헬퍼 함수를 만들어서 사용하는것이 가독성에 좋다, 다음은 간단하게 + 단항 연산자를 오버로딩하여 헬퍼 함수를 만든 코드이다
#include <type_traits> //std::underlying_type_t
enum class FamilyName
{
Mom,
Dad,
Me,
Counts
};
constexpr auto operator+(FamilyName f) noexcept
{
return static_cast<std::underlying_type_t<FamilyName>>(f);
}
int main()
{
std::vector<int> testvec1(+FamilyName::Counts);
testvec1[+FamilyName::Dad] = 150;
}std::underlying_type_t로 enum class의 enumerator가 사용하는 실제 타입이 무엇인지 알 수 있다 (위에서는 enum class의 타입을 지정하지 않았기 때문에 int가 나오게 된다, 만약 uint8_t로 한다면 unsigned char가 나오게 됨)
