[Advanced C++] 47. C-style array, C-style array sizeof(), length, decay, Pointer연산 및 [ ]연산, 음수 index, Pointer연산으로 배열 순회
Advanced C++

1. C-style array
C-style array
말 그대로 C언어에서 상속받은 배열을 의미하며 다른 STL 컨테이너 클래스와 달리 C++ 언어에 내장되어 있다 (따로 헤더를 include할 필요가 없음)
유일하게 언어 자체에서 지원하는 배열 타입이다
C-style array는 [ ]를 사용하여 선언한다, 이는 컴파일러에게 [ ]를 사용한 객체가 배열임을 알린다, [ ]에는 배열의 length를 제공하고 마찬가지로 std::size_t 타입 정수값이다
(여기서 [ ]는 operator[ ]가 아니고 그냥 선언 구문의 일부이다)
int testarr[10]{};C-style array의 length는 최소 1이어야 한다, 0이거나 음수로 들어가면 컴파일 에러를 발생시킨다
(heap에 할당된 C-style 배열은 length가 0이어도 허용됨)
std::array와 마찬가지로 length는 상수 표현식이어야 한다, 또한 operator[ ]로 인덱싱이 가능하다
int testarr[10]{};
testarr[0] = 1;
testarr[1] = 2;C-style array의 인덱스로는 모든 정수 타입(signed, unsigned)와 enum의 enumerator를 사용할 수 있다
다른 STL 컨테이너 클래스와 마찬가지로 operator[ ]는 bound check를 하지 않기 때문에 out of bound 인덱싱 시 크래시가 발생할 수 있다
std::array와 마찬가지로 C-style array는 aggregate이기 때문에 aggreagte initialization을 사용할 수 있다 ({ })
int testarr[5]{ 1, 2, 3, 4, 5 };C-style array에 초기화 값을 제공하지 않으면 unitialized되어 쓰레기 값이 들어가게 된다
따라서 { }를 이용하여 값 초기화를 해주는게 좋다
이때 초기화 리스트에 정의된 배열 길이보다 더 많은 초기화 값이 들어가면 컴파일 에러가 발생되고 더 적은 값이 들어가면 나머지는 기본 값 초기화가 된다
int testarr[5]{ 1, 2, 3, 4, 5, 6 }; //error
int testarr[5]{ 1, 2, 3 }; //1, 2, 3, 0 0 C-style array의 단점 중 하나는 클래스 템플릿이 아니기 때문에 CTAD를 이용한 타입 추론이 불가능하여 타입을 반드시 명시적으로 작성해야 한다는 것이다 (auto 사용 불가능)

C-style array는 초기화 값의 개수로부터 length를 추론할 수 있다, 따라서 초기화 값을 제공하고 length는 따로 작성하지 않아도 된다 (선호하는 방식이다, 초기화 값의 변경에 따라 length를 자동으로 제어해주기 때문이다, length와 초기화 값 개수간 불일치 위험이 없다)
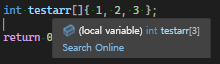
이는 초기화 값이 명시적으로 제공될 때만 작동한다
int testarr[]{}; //errorconst C-style array
std::array와 마찬가지로 C-style array는 const, constexpr이 가능하다
다른 const변수와 마찬가지로 반드시 선언과 동시에 초기화 되어야 한다
constexpr int testarr[]{ 1, 2, 3 };
testarr[1] = 30; //error, testarr가 constexpr이기 때문에 수정불가C-style array sizeof()
sizeof()는 객체나 타입의 크기를 byte로 return하는 함수이다, 이 함수를 C-style array에 적용하면 배열 전체가 사용하는 byte를 return한다
constexpr int testarr[]{ 1, 2, 3 };
std::cout << sizeof(testarr) << std::endl; //(본인 아키텍쳐에서)int가 4바이트로 되어있어서 12가 나옴C-style array length
다른 컨테이너 클래스와 마찬가지로 C++17부터는 iterator헤더에 있는 std::size(), C++20부터는 std::ssize()를 사용할 수 있다
std::size()로 unsigned 정수타입인 std::size_t 타입으로 값을 얻을 수 있고 std::ssize()로는 signed 정수 타입인 std::ptrdiff_t로 값을 얻을 수 있다
#include <iterator>
constexpr int testarr[]{ 1, 2, 3 };
std::cout << std::size(testarr) << std::endl;
std::cout << std::ssize(testarr) << std::endl;그렇다면 C++14이전에는 어떻게 length를 얻을까?
따로 템플릿 함수를 만들어서 사용해야 한다
template <typename T, std::size_t N>
constexpr std::size_t GetLength(const T(&) [N]) noexcept
{
return N; //길이 반환
}
int main()
{
constexpr int testarr[]{ 1, 2, 3 };
std::cout << GetLength(testarr) << std::endl;
return 0;
}굉장히 오래된 코드에서는 C-style array의 길이를 전체 배열의 크기에서 배열 element 하나의 크기로 나누는 방식을 사용하는걸 볼 수 있다
constexpr int testarr[]{ 1, 2, 3 };
std::cout << sizeof(testarr) / sizeof(testarr[0]) << std::endl;
return 0;이러한 방식은 decay된 array에서 의도치 않게 동작할 수 있다 (굳이 이런 방식을 사용할 필요가 없음)
C-style array는 할당을 지원하지 않는다
int testarr[]{ 1, 2, 3 };
testarr[0] = 10;
testarr = { 4, 5, 6 }; //error, 배열 할당 불가능C-style array는 수정 가능한 lvalue로 간주되지 않기 때문이다, 만약 새로운 값 목록을 할당해야 한다면 std::vector를 사용하자 혹은 std::copy를 사용하여 값을 복사하는 방식이 있다
#include <algorithm>
int main()
{
int testarr[]{ 1, 2, 3 };
int testarr1[]{ 4, 5, 6 };
std::copy(std::begin(testarr), std::end(testarr), std::begin(testarr1)); // std::copy 사용
return 0;
}testarr의 시작부터 끝까지를 testarr1에 복사한다는 의미이다, 따라서 testarr1도 element가 1, 2, 3으로 들어가게 된다
C-style array decay
void foo(int a)
{
std::cout << a;
}
int main()
{
int a{ 10 };
foo(a);
return 0;
}위 코드는 a의 값이 복사되어 foo()의 매개변수로 전달되고 10이 출력된다, 단순 int값 하나를 복사하기 때문에 오버헤드가 크게 발생하지 않는다
그렇다면 다른 객체를 element 1000개를 가진 배열을 이와 같은 방식으로 passing한다면 어떨까? 예상하기에는 비용이 아주 많이 발생할 것이다
void foo(int a[1000])
{
std::cout << a[0];
}
int main()
{
int a[1000]{ 5 };
foo(a);
return 0;
}C 설계자들은 위와 같은 비용 문제로 해결책을 고안하였다
우선 C언어에는 참조 개념이 없기 때문에 pass by ref는 사용할 수 없었다
또한 length가 각각 다른 배열 인자를 받을 수 있는 함수를 사용할 수 있어야 한다는걸 중점으로 설계했다
사실 위 코드는 복사가 발생하지 않는다, 왜 발생하지 않는지 정리해보자
C-style array가 표현식에서 사용될 때 배열은 암시적으로 element 타입의 포인터로 변환되고 0번째 element의 주소로 초기화 된다, 이를 array decay라고 칭한다
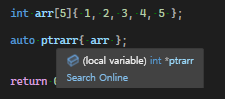
auto가 int*로 추론된 걸 확인할 수 있다, 이때 arr는 decay 되었다고 한다
여기서 ptrarr은 단순히 arr배열의 0번째 element의 주소를 가지게 된다
배열이 const라면 const 포인터로 decay된다
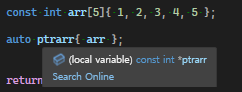
C++에서 C-style array가 decay되지 않는 경우가 몇 가지 존재한다
-
sizeof(), typeid()의 인자로 사용될 때
여기서 typeid()는 typeinfo 헤더가 필요하며 런타임에 타입을 식별하는 함수이다(std::type_info를 return함, name()을 사용하여 이름을 얻을 수 있다) -
operator&로 배열의 주소를 가져올때 (&arr)
배열 전체의 시작 주소를 return한다, 배열의 element 0번째를 가리키는 포인터가 아닌 배열 자체를 가리키는 포인터이다 (배열의 크기 정보를 포함한다) -
클래스 타입의 멤버에 존재할때
-
참조로 전달될 때 (void foo(int(&arr)[5])
decay된 배열에는 length 정보를 포함되지 않는다 (T*를 타입으로 가지기 때문)
decay된 배열은 결국 length 정보의 손실을 나타낸다
decay된 배열에도 operator[ ]를 사용하여 인덱싱이 가능하다
const int arr[5]{ 1, 2, 3, 4, 5 };
auto ptrarr{ arr };
std::cout << ptrarr[2] << std::endl;위에서 설명한 함수의 인자로 배열을 넘기는 상황에서 복사가 발생하지 않는 이유가 바로 이 decay된 배열때문이다 (포인터를 넘기는 방식이 되기 때문)
따라서 int[5]나 int[1000]이나 결국 decay된 array가 넘어가기 때문에(int*) 다른 길이의 배열을 전달 할 수 있는것이다
void foo(const int* ptrarr)
{
std::cout << ptrarr[0];
}
int main()
{
const int arr[5]{ 1, 2, 3, 4, 5 };
const int arr1[1000]{ 1, 2, 3, 4, 5 };
foo(arr); //decay
foo(arr1); //decay
return 0;
}단 이렇게 함수의 매개변수를 포인터로 작성하면 배열이 아니라 단순히 포인터를 넘기는 의미로 보일 수 있기 때문에 대체 선언 형식인 T arr[]를 사용하는게 좋다
void foo(const int ptrarr[])
{
std::cout << ptrarr[0];
}컴파일러는 결국 const int ptrarr[]를 const int*와 동일하게 해석한다, 호출자에게 포인터 값이 아닌 decay된 C-style array라는걸 알릴 수 있어서 더 선호하는 방식이다
[ ]사이에는 length 정보가 들어가지 않는다, 들어가도 어차피 사용되지 않기 때문에 무시됨
복사 오버헤드도 없고 굉장히 좋은 방식으로 보이지만 단점이 존재한다
decay 시키지 않기 위해 &를 사용한다면 [ ]에 length를 무조건 넣어야 한다
void foo(int (&inArr)[3])
{
std::cout << sizeof(inArr);
}- sizeof() 시 decay된 배열과 그냥 배열은 다른 값을 return한다
void foo(const int ptrarr[])
{
std::cout << sizeof(ptrarr) << std::endl;
}
int main()
{
const int arr[5]{ 1, 2, 3, 4, 5 };
foo(arr); //8
std::cout << "sizeof(arr) : " << sizeof(arr) << std::endl; //20
return 0;
}일반 배열의 sizeof()는 element의 크기를 전부 합친 값이 byte로 나오지만 decay된 배열은 포인터이기 때문에 포인터 크기로 나오게 된다
이러한 결과 때문에 C-style array에 sizeof()를 사용하는게 위험하다는 것이다, 위에서 length를 얻기 위해 배열의 크기를 배열의 0번째 element 크기로 나누는 방식을 정리했는데 만약 decay된 array의 sizeof()를 사용한다면 의도치 않은 값이 나올 수 있다
- decay된 배열은 length 정보가 없기에 인덱싱과 순회에 어려움을 겪을 수 있다
void foo(const int ptrarr[])
{
std::cout << ptrarr[3] << std::endl; //길이 정보가 없기 때문에 유효한 인덱싱인지 보장되지 않음
}길이가 없기 때문에 언제 배열의 끝에 도달했는지 모른다 따라서 순회를 하는데 어려움이 생긴다
이러한 길이 정보 부족 문제를 해결하기 위한 방법이 존재한다
(1) 함수에 길이 정보 전달하기
void foo(const int ptrarr[], int length)
{
assert(length > 3); //함수 매개변수라 static_assert 사용불가
std::cout << ptrarr[3] << std::endl;
}반드시 배열과 길이 정보를 맞춰주어야 한다, 휴먼 에러 발생 가능성이 높다
또한 assert만 사용이 가능하기 때문에 런타임 체크만 가능하다
(2) 의미 없는 값 하나를 end로 지정하기
의미 없는 값 하나를 element의 끝으로 지정한다면 해당 element를 end로 판단하여 순회가 가능하다
ex) C-style string에서 문자열의 끝을 표시하기 위한 NULL \0과 같은 방식, 따라서 C-style string은 decay되어도 순회가 가능하다
결국 마찬가지로 휴먼에러 발생 가능성이 높아 의도치 않은 동작이 발생할 확률이 존재한다
일반적으로 이러한 decay된 array와 관련된 위험때문에 C-style array는 지양하는게 좋다
std::array, std::vector, std::string std::string_view를 사용하자
C++에서는 C와 다르게 배열을 ref로 전달이 가능하기때문에 배열이 decay되지 않는다, 단 고정된 길이를 가지기 때문에 특정 길이의 배열만 처리가 가능하고 참조를 사용하지 않으면 decay 되기 때문에 휴먼 에러도 발생할 수 있다, 그냥 std::array를 사용하자
2. Poitner arithmetic and subscripting
포인터 연산, 첨자 연산
포인터에 덧셈, 뺄셈, 증가, 감소 연산을 적용하여 특정 메모리 주소에 접근하는 연산을 포인터 연산이라고 한다
예를들어 ptr이라는 포인터에 +1을 하면 다음 객체의 주소를 return한다, 이때 ptr이 int타입 포인터이고 int가 4byte인 아키텍처라면 ptr + 1은 1이 증가하는게 아니라 4가 증가하게되어 4byte 뒤의 메모리 주소가 return되고 +2는 같은 방식으로 8byte 뒤의 메모리 주소가 return된다
int a{};
const int* ptra{ &a };
std::cout << ptra << ' ' << (ptra + 1) << ' ' << (ptra + 2) << '\n';
//int가 4byte인 아키텍쳐 기준으로 4씩 증가한 메모리 주소를 return한다많이 사용되지는 않지만 뺄셈도 같은 방식으로 동작한다
포인터가 가리키는 타입에 기반하여 다음/이전 메모리 주소를 return하는게 키포인트이다
++, --도 같은 동작을 하지만 이 연산은 실제 포인터 변수가 가리키는 주소 자체를 변경시킨다
int a{};
const int* ptra{ &a };
++ptra;
std::cout << ptra << std::endl;
--ptra;
std::cout << ptra << std::endl;
//실제 ptra가 가리키는 주소 자체가 변경C++ 표준에서는 이러한 포인터 연산은 같은 배열 안에서만 안전하세 사용될 수 있다고 정의되어 있다 (배열의 마지막 element 바로 다음까지)
위의 예시로 작성한 단일 변수에서의 포인터 연산은 위험할 수 있으니 조심해야 한다
operator[ ] 첨자 연산은 포인터 연산을 통해 구현된다, operator[ ]는 포인터에 적용할 수 있다
const int arr[]{ 1, 2, 3, 4, 5 };
const int* ptrarr{ arr }; //arr[0]의 주소를 보유한 포인터로 decay된다
std::cout << ptrarr[2] << '\n'; //arr[0]의 주소로부터 +2 된 메모리 주소의 객체를 return한다)이러한 [ ]연산은 사실 ((ptr) + n))과 동일한 구문이다 (포인터 주소값에 N을 더하고 연산으로 실제 해당 주소의 객체를 얻는다)
int main()
{
const int arr[]{ 3, 2, 1 };
std::cout << &arr[0] << ' ' << &arr[1] << ' ' << &arr[2] << '\n';
std::cout << arr[0] << ' ' << arr[1] << ' ' << arr[2] << '\n';
std::cout << arr << ' ' << (arr + 1) << ' ' << (arr + 2) << '\n';
std::cout << *arr << ' ' << *(arr + 1) << ' ' << *(arr + 2) << '\n';
//같은 동작을 하게 된다
return 0;
}배열의 element는 메모리에서 순차적이기 때문에 배열의 이름이 0번째 element를 가리키는 포인터이고 + n 을 하면서 n번째 element를 return 하게 된다
여기서 배열이 1이 아닌 0기반 indexing을 하는 주요 이유가 나타난다, 1이라면 + n을 할 때 항상 -1을 해줘야 했을것이다
사실 ptr[n]은 ((ptr) + (n))과 동일하다고 했기 때문에 n[ptr]도 ((n) + (ptr))로 동일하게 동작하게 된다 (실무에서 이렇게 절대 사용하지 말 것, 그냥 작동은 함)
따라서 포인터 연산과 [ ]연산은 상대 주소라는걸 알 수 있다 (0을 기준으로 얼마나 +n하는지에 따라 다른 메모리 주소를 return하기 때문에 상대주소다)
arr[1], arr[2]가 무조건 1번, 2번 element를 가리키는게 아닐수도 있다는 것이다
const int arr[]{ 1, 2, 3, 4, 5 };
const int* ptrarr{ arr };
ptrarr = &arr[2]; //element 3을 가리키는 주소로 재할당
std::cout << ptrarr[1]; //3기준으로 상대주소 + 1이기 때문에 4가 나온다하지만 배열에서 [ ]연산을 사용할 때 보통은 0을 항상 기준으로 하는게 혼란스럽지 않다, 따라서 상대적인 위치를 지정할때는 포인터 연산을 사용하고 그렇지 않고 0을 기준으로 인덱싱 한다면 [ ]를 사용하는게 좋다
Negative indices
C-style array는 다른 STL 컨테이너 클래스와 달리 인덱스가 signed, unsigned 정수일 수 있다고 정리했다
이는 실제로 C-style array는 음수로 인덱싱이 가능하다는 의미이다
ex) ptr[-1]
이 구문은 곧 *(ptr - 1)이 되고 이전 객체의 주소를 return하게 된다
const int arr[]{ 1, 2, 3, 4, 5 };
const int* ptrarr{ arr };
ptrarr = &arr[2]; //element 3을 가리키는 주소로 재할당
std::cout << ptrarr[-1]; //*(ptr - 1) 연산이기 때문에 3이전의 element인 2를 출력한다포인터 연산으로 배열 순회
포인터 연산의 가장 일반적인 사용처는 인덱싱 없이 C-style 배열을 순회하는것이다
constexpr int arr[]{ 1, 2, 3, 4, 5 };
const int* begin{ arr }; //배열의 0번째 element의 주소 (decay)
const int* end{ arr + std::size(arr) }; //배열의 마지막 element바로 다음 주소
for (; begin != end; ++begin) //시작과 끝 포인터가 같지 않을때까지 증가
{
std::cout << *begin << '\n'; //순회
}end 포인터에는 배열의 마지막 element 바로 다음 주소가 들어가있다, 해당 주소에는 valid한 값이 없기때문에 역참조해서는 안된다
이러한 시작과 끝 주소를 가진 포인터를 이용하여 배열을 순회하는것의 장점은 바로 decay된 배열과 decay되지 않은 배열간의 동작 차이에 의한 이슈를 막을 수 있다는 것이다
void print(const int* begin, const int* end)
{
for (; begin != end; ++begin)
{
std::cout << *begin << '\n';
}
}
int main()
{
constexpr int arr[]{ 1, 2, 3, 4, 5 };
const int* begin{ arr };
const int* end{ arr + std::size(arr) };
print(begin, end);
return 0;
}함수의 인자로 배열을 전달 시 decay되어 원래 배열과 동작 차이가 발생할 수 있지만 위와 같은 코드는 시작, 끝 주소를 가진 포인터만 전달하기 때문에 발생하지 않는다
그렇기 때문에 추후에 다양한 알고리즘에서 begin, end 를 사용하는 함수가 많은것이다
C-style array에 대한 for-each loop는 포인터 연산을 사용하여 구현된다
constexpr int arr[]{ 1, 2, 3, 4, 5 };
for (int i : arr)
{
std::cout << i << '\n';
}for-each의 내부 구현을 보면 다음과 같다
// begin-expr는 범위의 시작을 나타내는 표현식
auto __begin = begin-expr;
// end-expr는 범위의 끝(바로 다음)을 나타내는 표현식
auto __end = end-expr;
// 내부적으로는 begin/end 포인터를 사용하는 일반 for 루프로 변환됨
for ( ; __begin != __end; ++__begin)
{
// range-declaration은 루프 변수 (예: auto e)
range-declaration = *__begin; // 현재 요소를 루프 변수에 복사
// loop-statement는 루프 본문 (예: std::cout << e << ' ';)
loop-statement;
}