[Advanced C++] 48. C-style string, C-style string function, const C-style string, Multidimensional C-style 배열 & std::array, 2차원 배열 Flattening, std::mdspan(C++23)
Advanced C++

1. C-style string
C-style string
C-style의 문자열은 const char[N]으로 구성되어 있다, 결국 const char타입의 배열이라는 뜻이다
C-style 문자열 literal은 사용해도 좋지만 C-style 문자열 객체는 사용하기 어렵고 위험하기에 현대 C++에서는 권장하지 않는다 (std::string, std::string_view를 사용하자)
하지만 레거시 코드에 많이 남아있는 경우가 있으니 잘 이해는 해야한다
C-style 문자열 객체는 쉽게 말해 char, const char, constexpr char 타입의 배열 변수이다
char str1[]{ "Hello" };
const char str2[]{ "World" };
constexpr char str3[]{ "C++" };여기서 중요한 점은 null 종료 문자(\0)가 포함되어 있기 때문에 길이가 +1 된다는 것이다
C-style의 문자열을 정의할때는 배열의 length를 직접 명시하는것보다 초기화 값으로 컴파일러가 length를 계산하도록 하는 방식을 강력히 권장한다 (값이 변경될 때 업데이트가 필요 없고 null 문자를 따로 신경써서 length를 넣어줄 필요가 없어진다 -> 휴먼에러 발생 가능성 제거)
C-style의 배열은 대부분의 상황에서 암시적으로 decay된다, C-style 문자열도 C-style의 배열이기 때문에 마찬가지로 대부분의 상황에서 decay된다
C-style의 문자열 literal은 const char*(포인터) 으로 decay되고 C-style 문자열 객체는 const 여부에 따라 const char, char*로 decay된다
마찬가지로 C-style의 문자열이 decay될 때 length 정보는 손실된다
하지만 null문자 \0이 있기 때문에 언제든 length를 재계산할 수 있다
C-style 문자열을 출력할 때 std::cout은 null 문자 \0을 만날때까지 문자를 출력한다 (결국 null문자가 문자열의 끝을 의미하기 때문) 따라서 decay된 문자열 배열도 끝까지 순회하여 출력이 가능하다 (length정보는 없지만 null문자가 남아있기 때문)
void printstring(char str[]) //char* 로 decay 됨
{
std::cout << str << std::endl; //null문자를 만날때까지 출력하여 Hello가 출력됨
}
int main()
{
char str1[] = "Hello";
printstring(str1);
return 0;
}만약 null문자가 빠졌다면 문자열의 모든 문자가 출력되고 다음 메모리에서 \0을 가진 값을 만날때까지 모든 값을 출력하게 될 것이다 (매우 중요함)
C-style 문자열 입력받기
만약 사용자로부터 원하는 숫자들을 입력받는다면 사용자가 몇 글자를 입력할지는 미리 알 수 없다
Array overflow 혹은 Buffer overflow는 저장 공간이 담을 수 있는것보다 더 많은 데이터가 들어와 저장공간 외의 메모리에 값이 덮어씌워져 정의되지 않은 동작이 발생하는걸 의미한다
C++20에서는 operator>>가 C-style문자열의 길이가 허용하는 만큼만 문자를 추출하여 오버플로우를 방지시킨다
std::cin을 통해 C-style 문자열을 입력 받을때 권장하는 방법은 다음과 같다
char str1[255];
std::cout << "Enter a string: ";
std::cin.getline(str1, std::size(str1)); //std::size는 decay되지 않은 배열에서만 사용 가능함
std::cout << str1;std::cin.getline()으로 최대 문자 수를 지정한다, 이때 초과하는 문자는 버려지고 지정한 길이만큼의 문자만 원하는 문자열 변수에 할당한다
현대 C++에서는 그냥 std::string을 사용하는게 가장 안전하다, 필요한 만큼만의 문자를 담기위해 자동으로 크기를 조절한다
C-style 문자열 수정
C-style 문자열은 위에서 정리했듯 C-style 배열로 이루어져 있다
(char str[])
따라서 C-style 배열의 규칙을 따른다, 생성 시 값 초기화가 가능하지만 이후에 =로 재할당이 불가능하다
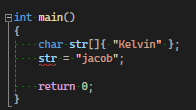
결국 배열이기 때문에 [ ]로 개별 문자 변경은 가능하다
char str[]{ "Kelvin" };
str[0] = 'j';
//str은 jelvin이 된다C-style 문자열은 std::size(), std::ssize()로 길이를 얻을 수 있다, 단 decay된 문자열에는 동작하지 않고 문자열의 길이가 아닌 C-style 배열의 할당된 크기를 return한다
char str[255]{ "string" };
std::cout << std::size(str); //255가 나옴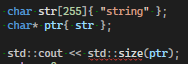
실제 문자열의 길이를 얻고 싶다면 cstring헤더에 있는 std::strlen()을 사용하면 된다, null문자를 제외한 실제 문자열의 길이를 return한다, 이는 decay된 배열에도 동작한다
#include <cstring>
char str[255]{ "string" };
char* ptr{ str };
std::cout << std::strlen(ptr); //6하지만 std::strlen()은 전체 배열을 순회하며 카운팅하기 때문에 느리다
그 외 다양한 C-style 문자열 조작 함수
- strcpy(), strncpy(), strcpy_s()
한 C-style 문자열을 다른 문자열로 덮어쓴다 (복사), strcpy()는 Buffer overflow에 취약하고 strncpy()는 unsafe하기 때문에 strcpy_s() 사용을 권장한다
const char src[]{ "This is a very long string" };
char dest[100];
std::strcpy(dest, src); const char src[]{ "This is a very long string" };
char dest[100];
//널 문자는 복사되지 않음
std::strncpy(dest, src, sizeof(dest));이때 C4996 error가 발생할 수 있는데 임시로 #pragma warning(disable:4996)으로 에러를 무시하여 테스트 하거나 #define _CRT_SECURE_NO_WARNINGS를 코드 최상단에 작성해주면 된다
(strncpy()는 unsafe하여 deprecated될 수 있으니 strcpy_s()를 사용하라고 권장함)
char dest[7];
strcpy_s(dest, std::size(dest), "kelvin");- strcat(), strncat()
한 C-style 문자열을 다른 문자열의 끝에 추가한다, 마찬가지로 strcat()도 Buffer overflow에 취약하기 때문에 strncat 사용을 권장한다
char str1[20]{ "Kelvin" };
const char str2[]{ "Park" };
std::strcat(str1, str2); //Kelvin Park 출력, 이때 str1에 Park이 들어갈 충분한 buffer가 제공되지 않으면 문제가 발생한다 (buffer overflow) char str1[20]{ "Kelvin" };
const char str2[]{ "Park" };
std::strncat(str1, str2, std::size(str1)); //buffer overflow로부터 안전- strcmp(), strncmp()
두 C-style 문자열을 비교한다, 같으면 0을 return한다
const char str1[]{ "Kelvin" };
const char str2[]{ "Kelvin" };
bool result = std::strcmp(str1, str2); //0이때 strncmp를 사용하면 특정 갯수만 비교가 가능하다
const char str1[]{ "Kelvin" };
const char str2[]{ "Kelddd" };
size_t n{ 3 };
bool result = std::strncmp(str1, str2, n); //3글자만 비교하기 때문에 0이 나옴굳이 C-style 문자열을 사용해야할 강력한 이유가 없다면 그냥 사용하지 않는게 좋다 (고정 크기 배열로 작업하는 경우 정도?) 대신 std::string, std::string_view를 사용하자
C-style 문자열 상수
C++에는 C-style 문자열 상수를 만드는 두 가지 방법을 지원한다
const char name[]{ "Kelvin" }; //C-style 문자열 literal로 초기화 된 상수 문자열
const char* const nameptr{ "Jacob" }; //C-style 문자열 literal을 가리키는 상수 포인터이 둘을 std::cout으로 출력하면 Kelvin, Jacob이 출력되게 된다, 같은 결과를 생성하지만 내부적으로 C++은 이 둘의 메모리 할당을 다르게 처리한다
- const char name[]{ "Kelvin" };
- "Kelvin"이라는 문자열 literal이 (보통 읽기전용) 메모리에 배치된다
- length가 7인(Kelvin + \0) C-style 배열을 위한 메모리를 할당하고 해당 메모리를 Kelvin문자열로 초기화한다
- 결국 Kelvin은 두개가 생성된 것이다, 특정 메모리에 배치된 literal "kelvin"과 배열에 복사된 "kelvin"
- 하지만 이때 name은 const이기 때문에 절대 수정되지 않는다 따라서 이러한 복사본을 만드는건 비효율적일 수 있다
- const char* const nameptr{ "Jacob" };
- 일반적으로 컴파일러는 "Jacob"이라는 문자열 literal을 읽기 전용 메모리에 배치한다
- 포인터인 nameptr은 Jacob 문자열의 주소로 초기화 한다, 결국 nameptr은 "Jacob"이 배치된 읽기 전용 메모리 주소를 가리킨다
- const char* const이기 때문에 가리키는 대상도 const이고 포인터 자체도 const이다
또한 최적화 목적으로 여러개의 문자열 literal이 단일 값으로 통합될 수 있다
const char* name1{ "Kelvin" };
const char* name2{ "Kelvin" };name1, name2는 최적화를 위해 같은 주소를 공유한다 (어차피 같은 문자열 literal이기 때문에 하나로 통합 후 같은 주소를 공유하게 해서 메모리 절약)
const C-style 문자열에서의 타입 추론
auto를 사용하여 C-style 문자열의 타입 추론이 간단하게 가능하다
auto n1{ "kelvin" }; //C-style 문자열이 "kelvin"은 const char*로 decay되기 때문에 const char*로 타입 추론됨
auto* n2{ "kelvin" }; //auto*로 추론된 타입이 포인터임을 나타냄, 위와 같은 방식으로 decay되기 때문에 const char*로 타입 추론됨
auto& n3{ "kelvin" }; //auto&이기 때문에 const char(&)[7]로 배열에 대한 참조타입으로 타입 추론됨std::cout에서의 포인터 처리
int intarr[]{ 1, 2, 3, 4, 5 };
char chararr[]{ "abcdef" };
const char* charptr{ "abcdef" };
std::cout << intarr << std::endl;
std::cout << chararr << std::endl;
std::cout << charptr << std::endl;intarr은 주소가 나오고 chararr과 charptr은 위에서 정리한대로 각 문자열이 출력되게 된다
이는 출력 스트림의 처리와 관련이 있다
char가 아닌 포인터가 출력 스트림에 전달되면 포인터가 가리키는 주소를 출력하고 char포인터나 const char포인터가 전달되면 문자열 출력의 의도를 파악하여 가리키고 있는 문자열 자체를 출력한다
하지만 이러한 동작은 의도치 않은 결과를 만들어낼 수 있다
char c{ 'c' };
std::cout << &c << std::endl;&c로 char*를 출력하게 되면 이상한 문자가 출력된다, 이는 'c'에 null문자인 \0이 없기 때문에 \0을 만날때까지 출력하기 때문이다
문자열이 아닌 실제 char*의 주소를 출력하고 싶다면 static_cast를 사용하여 const void포인터로 캐스팅하고 출력해야 한다
const char* c{ "Hello, World!" };
std::cout << static_cast<const void*>(c) << std::endl;여기서 void포인터란 어떤 타입의 객체든 가리킬 수 있는 포인터를 의미하고 주소 값 자체를 다룰때 많이 사용한다
2. Multidimensional C-style 배열
다차원 C-style 배열
예를들어 3x3 데이터를 저장하려면 어떻게 해야할까?
이제까지 정리한 방법으로는 9개의 개별 변수를 사용하는 방법, length가 9인 배열을 사용하는 방법이 있다
int arr[9];이러한 배열은 결국 arr[0] arr[1] arr[2] arr[3] arr[4]... 형태로 이루어진 1차원 배열이다
3x3과는 조금 다른 느낌이 있다
이러한 행렬과 같은 배열을 구현하기 위해서는 다차원 배열을 사용하는게 좋다
int mularr[3][3]; //3x3다차원 배열 (3행 3열)
a[0][0] a[0][1] a[0][2]
a[1][0] a[1][1] a[1][2]
a[2][0] a[2][1] a[2][2]이러한 다차원 배열의 element에 접근하기 위해서는 두 개의 인덱스가 필요하다 (행, 열)
mullarr[1][0];다차원 배열이기 때문에 2차원 이상의 배열도 가능하다 (매우 드물게 사용하긴 함)
int mullarr[3][3][3]; //3x3x3 배열사실 메모리는 1차원이기 때문에 다차원 배열도 실질적으로는 일반 배열과 마찬가지로 순차적으로 element가 메모리에 저장된다 (C++은 행 우선 순서)
[0][0] [0][1] [0][2] [0][3] [0][4] [1][0] [1][1] [1][2] [1][3] [1][4] [2][0] [2][1] [2][2] [2][3] [2][4]
2차원 배열 초기화
2차원 배열은 다음과 같은 방식으로 초기화가 가능하다
int array[3][5]
{
{ 1, 2, 3, 4, 5 }, // row 0
{ 6, 7, 8, 9, 10 }, // row 1
{ 11, 12, 13, 14, 15 } // row 2
};여기서 누락된 값은 0으로 값 초기화 된다
int array[3][5]
{
{ 1, 2 }, // row 0 = 1, 2, 0, 0, 0
{ 6, 7, 8 }, // row 1 = 6, 7, 8, 0, 0
{ 11, 12, 13, 14 } // row 2 = 11, 12, 13, 14, 0
};초기화 된 다차원 배열은 행의 개수를 생략할 수 있다
int array[][5] // 행의 개수는 생략 가능, 열의 개수(5)는 명시해야 함
{
{ 1, 2, 3, 4, 5 },
{ 6, 7, 8, 9, 10 },
{ 11, 12, 13, 14, 15 }
};컴파일러가 행의 개수를 알아서 계산한다
일반 배열과 마찬가지로 {}를 사용하여 전부 0으로 초기화도 가능하다
int array[3][5] {}; // 모든 요소를 0으로 초기화2차원 배열 순회
2차원 배열의 모든 element를 순회하려면 2개의 loop가 필요하다 (하나는 행, 하나는 열)
C++의 다차원 배열은 행 우선이기 때문에 외부 loop에 행을 넣고 내부 loop에 열을 넣는게 효율적이다
(메모리에 배치된 순서대로 element에 접근하는게 효율적이기 때문)
int arr[3][4]
{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
for (std::size_t row{ 0 }; row < std::size(arr); ++row)
{
for (std::size_t col{ 0 }; col < std::size(arr[0]); ++col)
{
std::cout << arr[row][col] << ' ';
}
}여기서 std::size(arr)로 행의 개수, std::size(arr[0])으로 열의 개수를 얻어와 전체 다차원 배열의 element를 순회한다
for-each loop로도 가능하다
for (const auto& row : arr)
{
for (const auto& ele : row)
{
std::cout << ele << ' ';
}
}여기서 arr이란 4개의 int를 가지는 배열의 배열을 의미한다, 결국 row는 4개의 int를 가지는 배열의 참조가 되고 ele는 이 4개의 int를 전부 순회할 수 있다
다차원 std::array
일반적으로 C-style의 배열은 피하고 std::array를 사용하는게 좋다, 하지만 STL에는 다차원 배열 클래스가 존재하지 않는다, 따라서 std::array를 이용하여 다차원 구현이 필요하다
std::array<std::array<int, 4>, 3> arr
{ { //2중 중괄호 필요
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
} };이러한 2차원 배열 구현은 가독성이 굉장히 좋지 않다, 또한 C-style 다차원 배열과 다르게 행, 열이 반대로 사용된다
(int arr[3][4]가 3행4열 2차원 배열이라면 std::array에서는 std::array<std::array<int, 4>, 3>이 되어야 한다)
인덱싱은 C-style 2차원 배열과 동일하게 작동한다
arr[1][2];2차원 std::array 배열도 함수의 인자로 전달이 가능하다 (템플릿 사용)
template <typename T, std::size_t Row, std::size_t Col>
void PrintArr(const std::array<std::array<T, Col>, Row>& arr)
{
for (std::size_t i = 0; i < Row; ++i)
{
for (std::size_t j = 0; j < Col; ++j)
{
std::cout << arr[i][j] << " ";
}
std::cout << std::endl;
}
}상당히 복잡하여 가독성이 매우 떨어진다, 이를 조금이나마 해소하기 위해 type alias를 사용할 수 있다
using Array2dint33 = std::array<std::array<int, 3>, 3>;
Array2dint33 arr
{ {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
} };
template <typename T, std::size_t Row, std::size_t Col>
using Array2d = std::array<std::array<T, Col>, Row>;
template <typename T, std::size_t Row, std::size_t Col>
void PrintArr(const Array2d<T, Col, Row>& arr)
{
for (std::size_t i = 0; i < Row; ++i)
{
for (std::size_t j = 0; j < Col; ++j)
{
std::cout << arr[i][j] << " ";
}
std::cout << std::endl;
}
}이러한 type alias 템플릿을 사용하게 되면 위에서 설명한 2차원 std::array의 col, row의 순서가 2차원 C-style array에서의 순서와 다른 이슈를 해결할 수 있다
(Col, Row를 내 맘대로 순서 변경해서 사용이 가능하기 때문, 의미가 더 직관적이게 된다)
2차원 배열 length
1차원 std::array에서는 size()멤버함수나 std::size()를 통해 length를 얻을 수 있다, 2차원에서는 어떻게 할 수 있을까?
2차원 std::array에서 size()는 행의 길이를 가져오고 std::array의 [0] element의 size()는 열의 길이를 가져온다
using Array2dint34 = std::array<std::array<int, 4>, 3>;
Array2dint33 arr
{ {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
} };
std::size(arr); //3
std::size(arr[0]); //4이때 행이 0이라면 정의되지 않은 동작을 하게 된다
이보다 더 나은 방법은 함수 템플릿을 사용하여 비타입 템플릿 매개변수로부터 길이를 return하는 방식이다
template <typename T, std::size_t Row, std::size_t Col>
using Array2d = std::array<std::array<T, Col>, Row>;
// Row 비타입 템플릿 매개변수로부터 행의 수를 가져옴
template <typename T, std::size_t Row, std::size_t Col>
constexpr int rowLength(const Array2d<T, Row, Col>&) // 선호한다면 std::size_t를 반환해도 됨
{
return Row; //constexpr std::size_t -> constexpr int는 narrowing conversion 아님
}
// Col 비타입 템플릿 매개변수로부터 열의 수를 가져옴
template <typename T, std::size_t Row, std::size_t Col>
constexpr int colLength(const Array2d<T, Row, Col>&) // 선호한다면 std::size_t를 반환해도 됨
{
return Col; //constexpr std::size_t -> constexpr int는 narrowing conversion 아님
}
int main(){
// 3행 4열의 int 타입 2차원 배열 정의
Array2d<int, 3, 4> arr {{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
}};
std::cout << "Rows: " << rowLength(arr) << '\n'; // 행의 길이 가져오기
std::cout << "Cols: " << colLength(arr) << '\n'; // 열의 길이 가져오기
return 0;
}2차원 배열 Flattening
2차원 배열은 1차원 배열에 비해 만들고 사용하기가 복잡하다
따라서 평탄화(Flattening)을 해서 1차원 배열을 2차원 배열 처럼 사용하는 방식이 존재한다
(2차원 배열을 단순한 1차원 배열로 처리하기 때문에 다루기 쉽다)
따라서 실제로는 데이터가 1차원 배열 형태로 되어 있지만 사용할때는 2차원 배열로 사용할 수 있는 인터페이스를 제공하는 것이다
이를 실제로 구현해보자
// 두 개의 차원을 사용하여 1차원 std::array를 정의할 수 있도록 하는 타입 별칭 템플릿
template <typename T, std::size_t Row, std::size_t Col>
using ArrayFlat2d = std::array<T, Row * Col>;
template <typename T, std::size_t Row, std::size_t Col>
class ArrayView2d {
private:
std::reference_wrapper<ArrayFlat2d<T, Row, Col>> m_arr{}; //그냥 참조로 사용하면 재지정이 불가능하여 복사 할당이 안됨, 따라서 reference_wrapper로 사용함
public:
ArrayView2d(ArrayFlat2d<T, Row, Col>& arr)
: m_arr{ arr }
{}
// 단일 첨자를 통해 요소 가져오기 (operator[] 사용)
T& operator[](int i) { return m_arr.get()[static_cast<std::size_t>(i)]; }
const T& operator[](int i) const { return m_arr.get()[static_cast<std::size_t>(i)]; }
// 2차원 첨자를 통해 요소 가져오기 (operator() 사용, C++23 이전에는 operator[]가 다중 차원을 지원하지 않음)
// 인덱스 계산: row * 열의_총_개수 + col (3x3행렬에서 [2][2]는 1차원 배열에서 8번째이다)
T& operator()(int row, int col) { return m_arr.get()[static_cast<std::size_t>(row * cols() + col)]; }
const T& operator()(int row, int col) const { return m_arr.get()[static_cast<std::size_t>(row * cols() + col)]; }
// C++23에서는 다차원[] operator가 지원되기 때문에 가능함
T& operator[](int row, int col) { return m_arr.get()[static_cast<std::size_t>(row * cols() + col)]; }
const T& operator[](int row, int col) const { return m_arr.get()[static_cast<std::size_t>(row * cols() + col)]; }
int rows() const { return static_cast<int>(Row); }
int cols() const { return static_cast<int>(Col); }
int length() const { return static_cast<int>(Row * Col); }
}; // 1차원 std::array 정의 (3행 4열 개념)
ArrayFlat2d<int, 3, 4> arr{
1, 2, 3, 4, // 행 0
5, 6, 7, 8, // 행 1
9, 10, 11, 12 // 행 2
};
// 1차원 배열에 대한 2차원 뷰 정의
ArrayView2d<int, 3, 4> arrView{ arr };
// 배열 차원 출력
std::cout << "Rows: " << arrView.rows() << '\n';
std::cout << "Cols: " << arrView.cols() << '\n';
// 단일 차원을 사용하여 배열 출력
for (int i = 0; i < arrView.length(); ++i)
std::cout << arrView[i] << ' ';
std::cout << '\n';
// 두 개의 차원을 사용하여 배열 출력
for (int row = 0; row < arrView.rows(); ++row)
{
for (int col = 0; col < arrView.cols(); ++col)
std::cout << arrView(row, col) << ' '; // operator() 사용
std::cout << '\n';
}
//C++23에서는 arrview[row, col]도 가능함
std::cout << '\n';std::mdspan
C++23에서는 이러한 연속된 element sequence에 대한 다차원 배열 인터페이스를 제공하는 뷰를 제공한다
std::mdspan은 수정 가능한 view로 std::string_view와 다르게 읽기 전용 view가 아니다
(element sequence가 const가 아니라면 수정 가능)
template <typename T, std::size_t Row, std::size_t Col>
using ArrayFlat2d = std::array<T, Row * Col>;
int main()
{
// 1차원 std::array 정의 (3x4)
ArrayFlat2d<int, 3, 4> arr {
1, 2, 3, 4,
5, 6, 7, 8,
9, 10, 11, 12
};
// 1차원 배열에 대한 2차원 스팬(span) 정의
// std::mdspan에 element sequence에 대한 포인터를 전달해야 하며,
// 이는 std::array 또는 std::vector의 data() 멤버 함수를 통해 수행할 수 있음
std::mdspan mdView { arr.data(), 3, 4 }; // 포인터, 행 수, 열 수 (이때 포인터는 decay된 C-style배열도 가능하고 data()를 통한 포인터도 가능하다)
// 배열 차원 출력
// std::mdspan은 이를 extents(범위)라고 부름
std::size_t rows { mdView.extents().extent(0) }; // 0번째 차원(행)의 크기
std::size_t cols { mdView.extents().extent(1) }; // 1번째 차원(열)의 크기
std::cout << "Rows: " << rows << '\n';
std::cout << "Cols: " << cols << '\n';
// 1차원으로 배열 출력
// data_handle() 멤버는 요소 시퀀스에 대한 포인터를 제공하며,
// 이를 인덱싱할 수 있음
for (std::size_t i=0; i < mdView.size(); ++i) // mdView.size()는 전체 요소 수
std::cout << mdView.data_handle()[i] << ' ';
std::cout << '\n';
// 2차원으로 배열 출력
// 다차원 []를 사용하여 요소에 접근
for (std::size_t row=0; row < rows; ++row)
{
for (std::size_t col=0; col < cols; ++col)
std::cout << mdView[row, col] << ' '; // [row][col]이 아닌 [row, col] 사용 (C++23)
std::cout << '\n';
}
std::cout << '\n';
return 0;
}