[Advanced C++] 7. DataType, void, Object size & sizeof, Integer, Fixed-width Integer & size_t
Advanced C++

1. Data Type
Data Type
컴퓨터의 모든 data는 결국 bit sequence이다, 우리는 data type (type)을 이용하여 컴파일러에게 메모리에 있는 데이터를 의미있는 방식으로 해석하는 방법을 알려주는 것이다
int a; //a라는 변수는 정수값으로 해석된다고 알려주는 것 (int)이러한 객체에 값을 주면 컴파일러와 CPU는 해당 data type에 적합한 비트 시퀀스로 값을 인코딩하고 메모리에 저장한다 (이때 메모리에는 bit가 저장되는것)
ex) int a = 65; 하면 컴파일러와 CPU는 정수형 65를 비트 시퀀스로 인코딩하여 0100 0001로 객체에 할당된 메모리에 저장한다
C++에는 다양한 data type이 내장되어 있다 이를 기본 데이터 타입이라고 칭한다
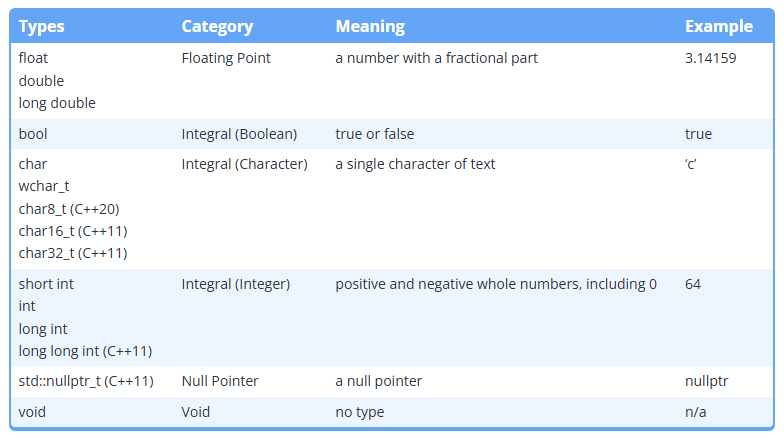
따라서 위의 표에 없는 문자열 타입은 기본 데이터 타입이 아닌 복합 데이터 타입이다 (std::string)
또한 최신버전의 C++에서 정의된 타입들은 보통 _t가 붙는 모습을 확인할 수 있다
2. Void
void
void란 타입 없음을 의미한다 (incomplete type)
incomplete type (불완전한 타입)은 컴파일러가 이러한 타입은 알고는 있지만 해당 타입의 객체에 할당할 메모리 크기를 결정할 수 없기때문에 인스턴스화 할 수 없다
void foo; //불가능일반적으로 void가 사용되는 곳은 함수의 반환형, 매개변수이다
값을 반환하지 않는 함수의 반환형으로 void를 사용한다
void foo()
{
std::cout << "foo" << std::endl;
}이러한 반환형이 없는 함수에서 값을 return을 하게 되면 컴파일 에러가 발생한다
C에서는 매개변수를 가지지 않는다는 의미로 void를 사용한다
int foo(void)
{
int x{100};
return x;
}이러한 문법은 C++에서 컴파일은 가능(이전 버전과의 호환성을 위함)하지만 더이상 C++에서는 사용되지 않는것으로 간주된다
매개변수가 없다면 그냥 공백으로 처리한다
3. Object size, sizeof
Object size
객체에 더 많은 메모리가 할당될수록 더 많은 정보를 저장할 수 있다
단일 bit는 0과 1 두가지 값만 저장이 가능하다, 2bit는 4개, 3비트는 8개의 값을 저장할 수 있다
(2의 n승개의 값을 가질 수 있다)
컴퓨터는 유한한 메모리를 가지고 있다, 따라서 크기가 큰 객체가 많이 필요한 프로그램일 경우 하나의 객체의 크기가 곧 최적화에 큰 영향을 미칠 수 있다 (수백만개의 객체가 필요한 프로그램에서 각 객체에 할당된 메모리 크기가 1byte인지 8byte인지는 매우 큰 영향을 미침)
C++표준에서의 data type 크기
C++표준에서는 다음과 같이 data type크기에 대한 정의를 내린다
- 객체는 최소한 1byte를 차지해야 한다, 이는 각 객체가 고유한 memory address를 갖게하기 위함이다
- 정수타입인 char, short, int, long, longlong의 최소크기는 1, 2, 2, 4, 8byte이다
- char와 char8_t는 정확히 1byte이다
각 data type의 크기는 다음과 같이 추정할 수 있다
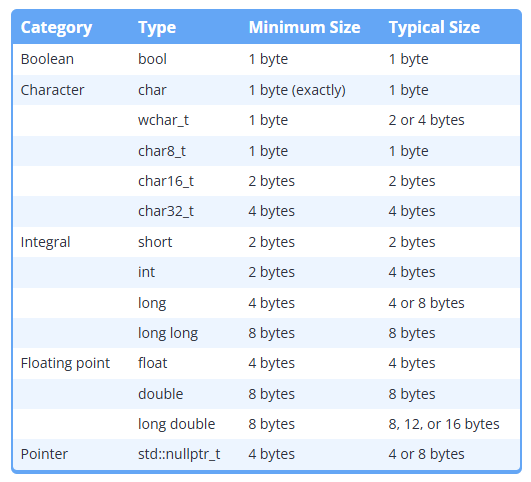
C++에서는 type이 특정 최소 크기를 가진다는것만 보장하고 특정 크기를 가진다는 보장은 없다
따라서 객체의 크기는 최소 크기보다 크다고 가정하지 않는것이 좋다, 이는 다양한 플랫폼에서의 동일한 코드 작동을 설계하기 위해 타입의 크기를 동일시하기 위함이다 (최소 크기는 보장되지만 실제 크기는 구현에 따라 달라질 수 있기 때문)
이는 하드웨어 아키텍처나 컴파일러에 따라서 다르기 때문이다 C++은 16,32,64비트에 따라 효율적으로 타입의 크기를 결정하기 때문에 int는 무조건 4byte라는 공식은 틀리다
sizeof
sizeof연산자는 타입이나 변수의 크기를 알려주는 연산자이다
int main()
{
int foo{10};
std::cout << sizeof(foo) << "\n"; //4
std::cout << sizeof(int) << "\n"; //4
}이때 console output을 조금 더 깔끔하게 출력하는 방법이 존재한다
//#include <iomanip> //setw()
int main()
{
std::cout << std::left; // left justify output
std::cout << std::setw(16) << "bool:" << sizeof(bool) << " bytes\n";
std::cout << std::setw(16) << "char:" << sizeof(char) << " bytes\n";
std::cout << std::setw(16) << "short:" << sizeof(short) << " bytes\n";
std::cout << std::setw(16) << "int:" << sizeof(int) << " bytes\n";
std::cout << std::setw(16) << "long:" << sizeof(long) << " bytes\n";
std::cout << std::setw(16) << "long long:" << sizeof(long long) << " bytes\n";
std::cout << std::setw(16) << "float:" << sizeof(float) << " bytes\n";
std::cout << std::setw(16) << "double:" << sizeof(double) << " bytes\n";
std::cout << std::setw(16) << "long double:" << sizeof(long double) << " bytes\n";
return 0;
}std::left, right로 console output을 원하는 쪽에서 정렬이 가능하며 std::setw(n)로 해당 output의 최소 width를 지정할 수 있다, 이때 값이 n보다 크다면 지정한 n width를 무시하고 더 작다면 왼쪽에 공백을 추가하여 채운다 (기본적으로 오른쪽 정렬이 됨)
std::setw(n)은 한번만 적용된다 (다시 기본으로 돌아감), 따라서 매 출력마다 해줘야한다
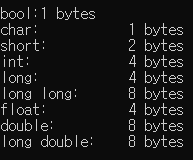
climits헤더를 이용하여 타입의 최대, 최소값을 알 수 있다
#include <climits>
int main()
{
CHAR_BIT; //8
CHAR_MIN;
CHAR_MAX;
INT_MIN; //-21억...
INT_MAX: //21억...
//Min,Max는 해당 타입의 최소값, 최대값을 의미한다, BIT는 bit수를 의미한다
}이때 sizeof(void)는 불가능하다 (incomplete type)
보통은 메모리를 덜 사용하는 type이 메모리를 더 많이 사용하는 type보다 성능상 유리하다고 생각할 수 있다, 하지만 이는 정확하지 않다
CPU는 종종 특정 크기의 data를 처리하도록 최적화 되어 있기 때문이다, 예를 들어 32bit 크기의 데이터 처리에 최적화 되어있다면 32bit int가 16bit short나 8bit char보다 빨리 연산될 수 있는것이다
4. integer
integer
정수란 0을 포함한 양수, 음수를 의미한다, C++에는 4가지 기본 integer type이 존재한다
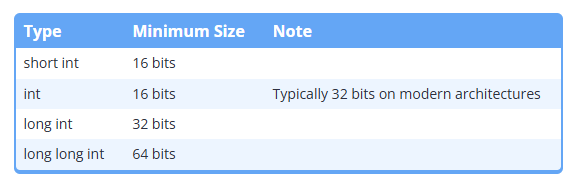
위에서 설명했듯 더 큰 타입의 정수는 더 큰 정수를 담을 수 있다
표에는 존재하지 않지만 char, bool type은 정수 타입으로 간주된다 (값을 정수로 저장하기 때문)
C++에는 부호가 존재한다, 이때 부호는 값의 일부로 저장된다 (부호는 1bit)
(signed, unsigned)
type에서 뒤의 int는 작성하지 않아도 된다
short s;
int i;
long l;
long long ll;이때 기본적으로 signed는 앞에 붙어있다 (음수, 양수 전부 가능), 명시적으로 작성하지 않아도 된다
각각의 type들은 어느정도 범위의 정수를 담을 수 있을까?

이러한 type들의 최소값, 최대값을 넘어가는 값을 넣게되면 의도하지 않은 값이 나오게된다, 이를 언더플로, 오버플로라 한다
산술연산으로 인해 값이 최소값, 최대값을 넘어가게 되도 마찬가지로 언더플로, 오버플로가 발생한다
short s {50000}; //overflow
short s {10000};
short ts = s * 10000; //overflowbit로 생각해보자, 만약 signed char가 있다고 가정하고 0111 1111 이라고 생각해보자 (최대값 127) 여기서 1을 더하게 되면 1000 0000이 된다 따라서 음수 처리가 들어가서 -128이 되는 방식이다
정수와 정수의 연산은 정수로 나온다 (정수 타입은 소수값을 가질 수 없기때문에 짤림)
8 / 5; //1unsigned int
각 타입 앞에 unsigned를 붙히게 되면 음수의 범위가 양수로 넘어가게 된다
unsigned short us;
unsigned int ui;음수의 범위가 양수로 넘어가기 때문에 unsigned char는 0 ~ 255가 된다
따라서 두배 큰 양수를 저장할 수 있게 되는것이다
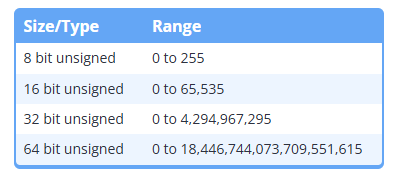
unsigned type은 부호가 없기 때문에 부호가 차지하는 메모리 없이 더 많은 양수를 저장할 때 사용하기 적합하다
unsigned type에서의 overflow는 조금 다른 방식으로 동작한다
예를들어 살펴보자
int main()
{
unsigned short us{ 65535 };
std::cout << us << std::endl;
us = 65536;
std::cout << us << std::endl;
us = 65537;
std::cout << us << std::endl;
return 0;
}위 결과는 순서대로 65535, 0, 1이 나오게 된다 왜 이런 결과가 나오는걸까?
unsigned type같은 경우에는 overflow가 발생하면 최대값 + 1만큼 뺀 값이 나오게 된다, 이를 modulo rapping이라 한다
반대로 -로 가게되면 다음과 같은 결과가 나오게 된다
int main()
{
unsigned short us{ 0 };
std::cout << us << std::endl; //0
us = -1;
std::cout << us << std::endl; //65535
return 0;
}이것도 마찬가지로 bit로 생각해보면 unsigned char의 최대값인 255로 가정했을 때 1111 1111이 나오게 되고 여기서 1을 더하게 되면 1 0000 0000이 나오게 된다, 이때 char는 8bit만 표현하기 때문에 0000 0000이 나와 0이 나오게 되는것이다 (반대도 마찬가지)
이러한 rapping은 의도하지 않은 동작을 유발할 수 있다
일반적으로 unsigned int는 피하는것이 좋은데 다음과 같은 이유가 있다
- 쉽게 overflow, underflow가 발생할 수 있다
- signed와 unsigned 사이의 연산으로 인한 의도하지 않은 동작 발생 가능 (매우 중요)
무조건 signed와 unsigned를 같이 연산하는 코드는 피해야 한다
하지만 unsigned를 사용하는 경우도 존재한다
- 비트단위 조작 시
- 암호화 및 난수 생성 알고리즘
- 메모리가 굉장히 제한된 상태에서의 개발 (부호가 차지하는 메모리가 없기 때문에)
5. Fixed-width integer, size_t
C++은 type의 최소 크기만 보장한다, 이때 int의 크기는 16bit, 32bit 아키텍쳐에 따라 다르다
int x {32767};
x += 1;
std::cout << x << std::endl;32bit 머신에서 32787은 int type의 최소, 최대 크기 안에 들어가기 때문에 문제가 없다, 하지만 만약 16bit 머신에서 위 코드를 빌드하게 되면 범위에 맞지 않기때문에 오버플로를 발생시킨다
그렇다면 int type의 크기는 왜 고정되어 있지 않을까?
이 또한 옛날 하드웨어 성능의 잔재이다, C 구현 시 int가 대상 컴퓨터 아키텍쳐에서 가장 효율적으로 사용될 수 있는 크기를 선택할 수 있게하기 위해 크기를 열어둔것이다
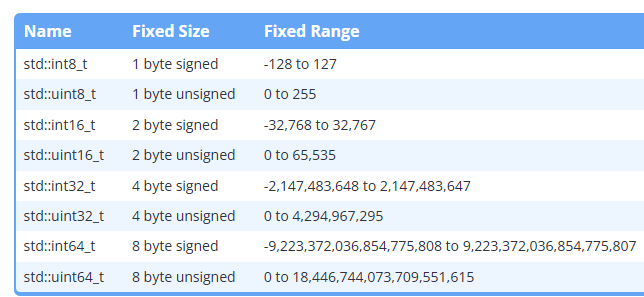
이러한 문제를 해결하기 위해 C++11에서는 모든 아키텍쳐에서 동일한 크기가 보장되는 정수타입들을 제공한다, 이러한 타입들을 Fixed-width integer type이라 한다
(cstdint헤더 포함 필요)
int main()
{
std::int32_t a{ 32767 };
a += 1;
std::cout << a << std::endl; //32768
return 0;
}이렇게 항상 32bit 크기를 가지는 int type으로 지정이 가능하다
이때 std::int8_t와 std::uint8_t는 각각 char, unsigned char와 같은 방식으로 동작한다
따라서 정수를 넣어도 해당 값을 출력하면 char와 같이 동작하여 문자가 나오게 된다 (ASCII)
이러한 Fixed-width integer type에도 잠재적인 단점이 존재한다
- 기본 정수 type이 있는 시스템에서만 존재한다 (사실상 거의 다 존재함)
- 더 큰 type보다 느릴수 있다, std::int32_t가 64bit정수 처리보다 느릴수 있다는 것이다
이러한 속도 차이를 개선하기 위한 int type과 메모리 사용량을 고려한 가장 작은 크기의 int type이 존재한다
#include <cstdint> // for fast and least types
#include <iostream>
int main()
{
std::cout << "least 8: " << sizeof(std::int_least8_t) * 8 << " bits\n";
std::cout << "least 16: " << sizeof(std::int_least16_t) * 8 << " bits\n";
std::cout << "least 32: " << sizeof(std::int_least32_t) * 8 << " bits\n";
std::cout << '\n';
std::cout << "fast 8: " << sizeof(std::int_fast8_t) * 8 << " bits\n";
std::cout << "fast 16: " << sizeof(std::int_fast16_t) * 8 << " bits\n";
std::cout << "fast 32: " << sizeof(std::int_fast32_t) * 8 << " bits\n";
return 0;
}std::int_fast#_t는 최소 #비트 크기를 가진 int타입중 CPU에서 가장 빠르게 처리할 수 있는 정수 타입을 의미한다
std::int_least#_t는 최소 #비트 크기를 가진 int타입중 가장 작은 정수 타입을 의미한다
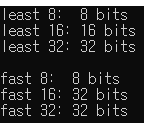
int_least16_t는 16bit의 크기를 가지고 int_fast16_t는 32bit의 크기를 가진다고 출력되었다 (아키텍쳐에 따라 다름)
이는 해당 머신에서 32bit정수가 16bit정수보다 처리 속도가 빠르다는걸 의미한다
(거의 사용하는 프로그래머가 없고 실제 크기가 이름과 다르기 때문에 메모리 낭비 가능성이 있다 또한 아키텍쳐에 따라 다른 결과를 나타낼 수 있다, 사용을 지양하는게 좋다고 생각함)
std::size_t
sizeof()연산자의 return type은 std::size_t이다
std::size_t는 객체의 byte 크기를 나타내는데 사용한다 (unsigned __int64)
#include <cstddef>
int main()
{
int x {10};
std::size_t s = { sizeof(x) };
std::cout << s << std::endl; //4
}이때 이 std::size_t는 32bit, 64bit application에 따라 다르다
32bit인 경우 32bit의 unsigned int가 되고 64bit인 경우에는 64bit의 unsigned int가 된다
따라서 현재 x64 application에서 다음 코드를 돌려보면 8이 나온다
std::cout << sizeof(std::size_t) << std::endl;