
1. float
부동 소수점
부동 소수점은 소수점이 부동할 수 있다는 의미이다 (실수를 의미)
부동 소수점은 항상 부호가 존재한다 (unsigned 타입이 존재하지 않는다)
기본적으로 3개의 기본 부동 소수점 데이터 타입이 존재한다
- float
- double
- long double
float은 일반적으로 4byte, double은 8byte의 크기를 가진다
(최신 아키텍쳐 기준으로 일반적인 크기, IEEE 754표준)
하지만 long double은 플랫폼에 따라 8,12 혹은 16byte의 크기를 차지한다
(IEEE 754표준을 사용할 수도 있고 사용하지 않을 수도 있다, 크기가 플랫폼에 따라 크게 다르기 때문에 사용을 지양한다)
IEEE 754란 컴퓨터에서 부동소수점 숫자를 표현하고 연산하는 표준 방식을 의미한다
이러한 표준을 확인하는 방법이 존재한다
#include <limits>
std::numeric_limits<float>::is_iec559;이는 float이 IEEE 754 표준을 따르는지 확인하여 T,F로 값을 반환한다
부동 소수점 값을 사용할 때는 항상 소수점 한 자리 이상을 포함해야 한다 (소수점이 0이어도)
double foo {5.0};
float foo {5.f};기본적으로 부동 소수점 값은 double이다, float을 사용하려면 부동 소수점 값에 f를 붙여야 한다
소수점이 0인경우 std::cout으로 출력하면 뒤의 소수점은 출력되지 않는다
std::cout << 5.0f << std::endl; //5.0이 아닌 5로 출력됨부동 소수점 정밀도
예를들어 1/3을 생각해보면 0.33333...으로 계속 이어지게 될것이다
컴퓨터에서 부동 소수점은 일반적으로 4, 8byte 크기를 가지기 때문에 무한으로 표현이 불가능하다
따라서 각 부동 소수점 타입은 유효숫자에 의한 정밀도를 가지고 있다
float은 6~9자리의 유효숫자, double은 15~18자리의 유효숫자 표현이 가능하다, long double은 차지하는 byte크기에 따라 최소 15,18 혹은 33까지의 유효숫자 표현이 가능하다
(최소값으로 생각하는게 좋다)
std::cout은 기본적으로 정밀도가 6이다 (유효숫자 6까지 표현)
따라서 다음과 같은 출력은 짤리게 된다
std::cout << 123456.22f << '\n'; //123456만 출력됨 (6자리 유효숫자)이러한 std::cout의 정밀도를 설정할 수 있다
#include <iomanip>
std::cout << std::setprecision(10); //std::cout 정밀도 10으로 설정
std::cout << 3.333333333f << '\n';값이 3.3333333으로 출력될 듯 하지만 실제로는 그렇지 않다, 왜냐하면 float은 일반적으로 7자리의 정밀도를 가지고 있기 때문이다 (7자리 까지만 정확함), 이러한 정밀도에 의한 부정확한 숫자 저장을 rounding error라고 칭한다
float이 double보다 정밀도가 더 낮기 때문에 f를 제거하여 double로 출력한다면 더 정확한 부동 소수점 값을 얻을 수 있다 (메모리 공간이 부족하지 않다면 double을 사용하여 더 정확한 부동 소수점을 사용하는것이 좋다)
std::setprecision()은 한번 설정하면 계속 유지된다 (std::setw와는 다름)
부동 소수점 비교
부동 소수점을 비교하게 되면 치명적인 문제가 발생하기 쉽다
1/10이라는 값을 10진수로 생각하면 0.1이지만 2진수로 생각하면 0.0001100110011...의 무한 시퀀스로 표현된다
이는 2진수와 10진수의 실수 표현 방식때문이다
10진수 실수는 1/10, 1/100, 1/1000 이런 방식으로 표현된다, 반면 2진수 실수는 1/2, 1/4, 1/8 이렇게 표현된다
결국 근본적인 원인은 1/10이라는 값을 1/2의 n승 형태로 표현할 수 없기 때문이다
1/10을 2진수로 변환해보면 다음과 같다
0.1 * 2 = 0.2 (정수 부분: 0)
0.2 * 2 = 0.4 (정수 부분: 0)
0.4 * 2 = 0.8 (정수 부분: 0)
0.8 * 2 = 1.6 (정수 부분: 1)
0.6 * 2 = 1.2 (정수 부분: 1)
0.2 * 2 = 0.4 (정수 부분: 0) <-- 2번 과정과 동일한 0.2가 다시 출력
0.4 * 2 = 0.8 (정수 부분: 0)
0.8 * 2 = 1.6 (정수 부분: 1)
0.6 * 2 = 1.2 (정수 부분: 1)
... (이후 계속 0011이 반복)결과가 0.0001100110011... 로 나오는걸 확인할 수 있다
double d{ 0.1 };
std::cout << d << '\n';
std::cout << std::setprecision(17);
std::cout << d << '\n';정밀도 17로 설정 후 값을 출력하면 0.10000000000000001이 나오게 된다, 따라서 실질적으로 0.1은 0.1이 아닌것이다 (double의 메모리 크기가 제한적이기 때문에 근사값으로 자른것임, 16자리까지는 정확하지만 17부터 정확하지 않음) -> rounding error
std::cout << std::setprecision(17);
double d1{ 1.0 };
std::cout << d1 << '\n';
double d2{ 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 + 0.1 }; // should equal 1.0
std::cout << d2 << '\n';
return 0;위와 같은 문제로 해당 코드는 1.0과 1.0으로 같은 값이 나올것 같지만
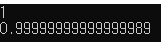
이런 결과값을 나타내게 된다, 이러한 케이스를 실제로 사용하다가 만나게 되면 큰 오류를 발생시킬 수 있다
부동 소수점 연산을 계속하다보면 이러한 오차도 점점 커지게 된다 (금융권에서 부동 소수점 사용시 굉장히 주의하는 이유 중 하나)
따라서 부동 소수점끼리의 비교연산은 지양하는게 좋다
NaN, Inf
IEEE 754 형식에는 무한대를 의미하는 Inf와 숫자가 아님을 의미하는 NaN이 존재한다, 또한 +0과 -0이 존재한다
double zero{ 0.0 };
double posinf{ 5.0 / zero };
std::cout << posinf << '\n'; //inf
double neginf{ -5.0 / zero };
std::cout << neginf << '\n'; //-inf
double z1{ 0.0 / posinf };
std::cout << z1 << '\n'; //0
double z2{ -0.0 / posinf };
std::cout << z2 << '\n'; //-0
double nan{ zero / zero };
std::cout << nan << '\n'; //NaN0으로의 나눗셈은 크래시를 발생시키기 때문에 절대 사용하지 않는다
2. bool
bool
bool은 True, False 두 가지 값만 가지는 타입이다
bool foo = true;
bool foo1 = false;bool 타입 값은 !연산자로 반대로 뒤집을 수 있다
!true; //false
!false; //truebool값을 그냥 std::cout으로 출력하면 true는 1, false는 0으로 출력하게 된다
이때 실제로 true, false라는 문자열로 출력하고 싶다면 std::boolalpha를 해주면 된다
std::cout << std::boolalpha;
bool foo = true;
std::cout << foo << '\n'; //true이를 다시 끄고 싶다면 std::noboolalpha; 처리를 해주어야 한다
bool타입 변수에 리스트 초기화{ }로 초기화를 하게되면 0과1이 아닌 다른 정수는 사용할 수 없다, 하지만 복사 초기화를 하게 된다면 0과1이 아닌 다른 정수도 초기화가 가능하다 (0이 아닌 다른 수는 모두 true)
(리스트 초기화는 타입 검사를 하기 때문)
bool foo{ 3 }; //compile error
bool foo1 = 4; //compile success그렇다면 std::cin으로 bool 타입 변수에 값을 어떻게 넣을까?
bool foo{};
std::cin >> foo;
std::cout << foo << '\n';이때 문자열인 true나 false를 입력하게 되면 0을 출력하게 된다
실제로 true,false를 입력하고 싶다면
std::cin >> std::boolalpha;
std::cin >> foo;로 해주어야 한다, 이제 true를 넣으면 1이 나오게 된다 (대문자 X)
단 std::boolalpha를 사용하면 숫자는 넣을 수 없게 된다
3. if statements
if
if문은 특정 조건이 참일경우 명령을 실행시키는 조건문이다, 이때 조건으로는 bool로 평가되는 표현식을 사용해야 한다
if (조건)
{
명령;
}
int foo {10};
if (foo > 1)
{
std::cout << foo << '\n';
}조건이 참이 아닐때 명령을 실행시키려면 else를 사용한다
int foo {4};
if (foo > 5)
{
std::cout << foo << '\n';
}
else
{
std::cout << "Test" << '\n';
}그렇다면 조건이 참일때, 거짓일때 뿐 아니라 다른 조건을 체크해서 명령을 실행시키고 싶다면 else if()를 사용한다
int foo { 0 };
if (foo > 0)
{
}
else if (foo < 0)
{
}
else
{
}조건에는 bool로 판단만 가능하다면 뭐든 들어갈 수 있다 (함수, 포인터 변수 (nullptr인지 아닌지 체크))
물론 상수도 가능하다 (0이 아닌 상수는 전부 true)
early return
개발을 하면서 if, else if, else를 많이 쓰다보면 depth가 굉장히 길어지게 된다, depth가 길어지면 가독성이 좋지 않다
if (!Knight)
{
return;
}
Knight->Attack();early return은 이런식으로 코드를 가독성 좋게 만들어줄 수 있다
4. char
char
char는 단일 문자를 가지는 타입이다
char는 기본적으로 정수형이며 값이 정수로 저장된다, 이는 bool과 비슷하다 bool에서 0이 false고 1이 true가 되는것 처럼 char에서의 정수는 문자로 매핑된다
ASCII코드에서 0~127사이의 숫자들은 특정 문자로 매핑되어 있다 (여기서 32 ~ 126까지가 출력가능 코드, 97은 a이다)
C++에서 문자는 ' '안에 기입한다
다른 타입과 같은 방식으로 초기화 하여 사용한다
char foo {'a'};
char foo {97};char타입 변수는 정수로 초기화가 가능하지만 ASCII코드를 완벽하게 암기하고 있는 사람이 아니라면 굳이 이런 방식으로 초기화하지 않는게 좋다
char foo {97};
std::cout << foo << '\n'; //a가 출력됨입력도 다른 타입과 마찬가지이다
char foo{ };
std::cin >> foo;
std::cout << foo << '\n';앞에서 정리했듯 std::cin은 입력 버퍼처리가 되기 때문에 한번에 여러 문자를 입력하고 enter 시 남은 문자가 입력 buffer에 남아있어 자동으로 다음 문자가 들어가게 된다
char foo{ };
char foo1{ };
std::cin >> foo;
std::cout << foo << '\n';
std::cin >> foo1;
std::cout << foo1 << '\n';abcd를 한번에 입력 시 두번째 입력은 입력 buffer에 남은 문자가 바로 들어가 a, b가 한번에 출력된다
a공백b도 마찬가지이다
그렇다면 공백을 문자로 받아서 처리하고 싶다면 어떻게 할까?
char foo{};
std::cin.get(foo);
std::cout << foo << '\n';
std::cin.get(foo)
std::cout << foo << '\n';std::cin.get()으로 공백을 무시하지 않고 cin처리를 할 수 있다
char는 C++에서 항상 1byte 크기로 정의된다
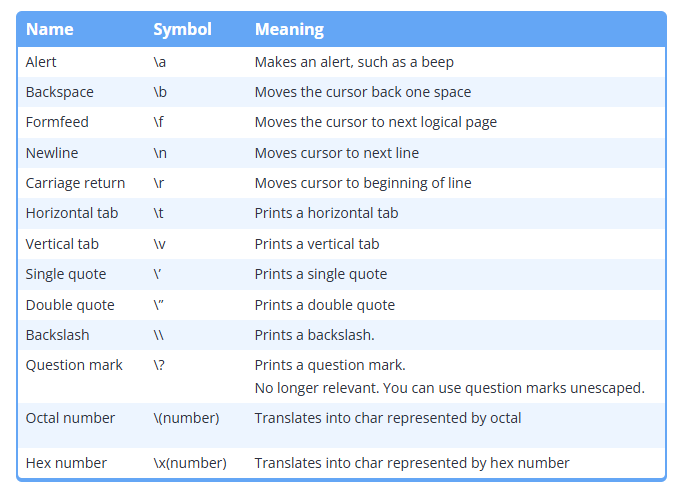
escape sequences
C++에는 특별한 의미를 가진 문자 시퀀스가 존재한다
\n, \t, 이런 문자 시퀀스를 escape sequences라고 한다
\n은 한 줄 아래로, \t는 tab을 의미한다
\'는 작은따옴표, \"는 큰 따옴표, \는 백슬래시를 의미한다
C++에서는 이전 버전과의 호환성을 위해 다중 문자를 지원한다 ('ab')
하지만 이러한 방식은 피하는것이 좋다
Unicode
유니코드는 전 세계 다양한 문자를 ASCII처럼 매핑하는 표준법이다
무려 144,000개가 넘는 정수를 전 세계 문자와 매핑한다
UTF-8, UTF-16, UTF-32 등으로 각 문자를 표현하는데 필요한 bit가 다르다
유니코드 문자를 사용하려면 타입을 char16_t, char32_t로 UTF에 맞춰서 사용하면 된다 (C++11)
UTF8은 char8_t로 사용한다 (C++20)
