
이제 막 개발자가 되겠다고 뛰어든 문돌이에게 갑자기 5분에 한 번씩 2만개 데이터가 들어올 거에요!라고 하면 어떻게 해야할까? 이건 진짜 너무한 거 아니냐고
2만 건 업데이트 해주세요~
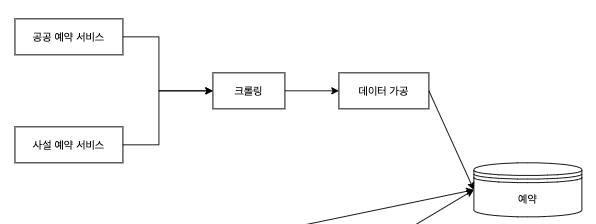
우리의 프로젝트는 파편화 되어 있는 테니스 예약 정보들을 모아서 한 번에 제공하는 것을 목적으로 한다. 이를 위해서 공공예약서비스와 사설예약서비스에서 예약 정보들을 크롤링 하여 가져와야 한다.
그렇다면 한 번에 몇 개의 데이터가 들어올까?
서울시 공공예약서비스만 하더라도 최소 2만 개 이상의 데이터가 들어온다.
최소
서울시 공공서비스예약에 존재하는 코트 수 = 17개
센터당 코트 = 3개
테니스 센터마다 한 달 치의 예약 정보 = 30일
오전 8시부터 오후 9시까지 한 시간 단위 예약 = 14타임
17 * 3 * 30 * 14 = 21,420개
하지만 이건 최소 수치다. 서남센터 테니스장의 경우 12번 코트까지 존재하고, 서울숲 테니스장의 경우 다음달 일부 일자를 추가적으로 오픈해놓기도 한다. 즉 21,420개는 가뿐히 넘는 데이터가 들어오는 것이다. 문제는 이런 데이터가 한 번 들어오는 게 아니라는 것이다.
우리의 서비스는 예약 정보를 깔끔하게 정리해서 제공하는 것이 주목적이지만, 그에 맞춰 (당연하게도) 정확한 정보를 제공해야 한다. 예약이 가능하다고 해서 들어갔는데, 들어갔더니 예약이 불가능하다고 하면 굉장히 화가 날 거 같다.
그래서 짧은 시간 안에 반복적으로 데이터를 가져와야 했고, 이것들을 빠르게 업데이트 해줄 필요가 있었다. 내부적으로 5분 단위면 그래도 큰 문제가 없을 거란 결론이 나왔고, 5분에 한 번씩 최소 2만 건의 데이터를 업데이트 해야 했다.
아키텍처를 모르는 자, 죽어라!
불과 한 달 전만 하더라도 순수한 문돌이었던 나는 업데이트 로직을 떠올리기 급급했다. 그래도 어디서 추상화 같은 건 봤다고, 나름대로 객체지향스럽게 코드를 짜보았다.
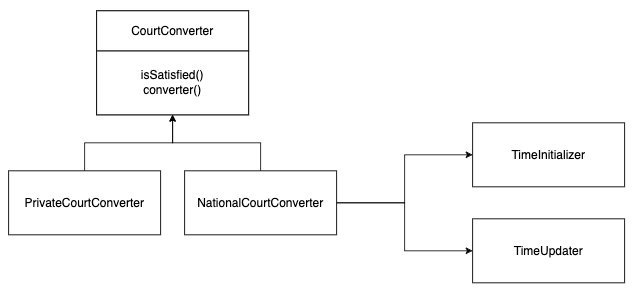
CourtConverter라는 인터페이스를 하나 놓고, 공공이냐 사설이냐에 따라 별개의 구현 클래스를 작성하였다. 그리고 TimeIniitalizer와 TimeUpdater를 CourtConverter들이 참조할 수 있도록 설계하였다.
기존의 없는 코트 정보가 들어오면 TimeInitializer를 통한 초기화를, 있는 코트 정보가 들어오면 TimeUpdater를 통해 예약 가능 정보를 변경한다.
근데 이러한 방식은 좋은 성능을 내는 방식이라 보기 어렵다. 결국 2만 건의 데이터를 기존 데이터와 비교하며 업데이트해야 하고, Spring JPA에서 제공하는 @Modifying 어노테이션을 이용한 Bulk Update를 진행하더라도 2만 건이 업데이트 되어야 한다는 사실에는 변함이 없다. 분명 엄청난 리소스를 잡아먹을 것이다. (이 부분을 수치적으로 확인했어야 하는데, 뭘 알았어야...)
게다가 한 대의 서버로 운영하고 있었기 때문에, Crawling을 하는 부하와 2만 건의 업데이트를 하는 부하 모두 하나의 서버에서 감당해야 했었다.
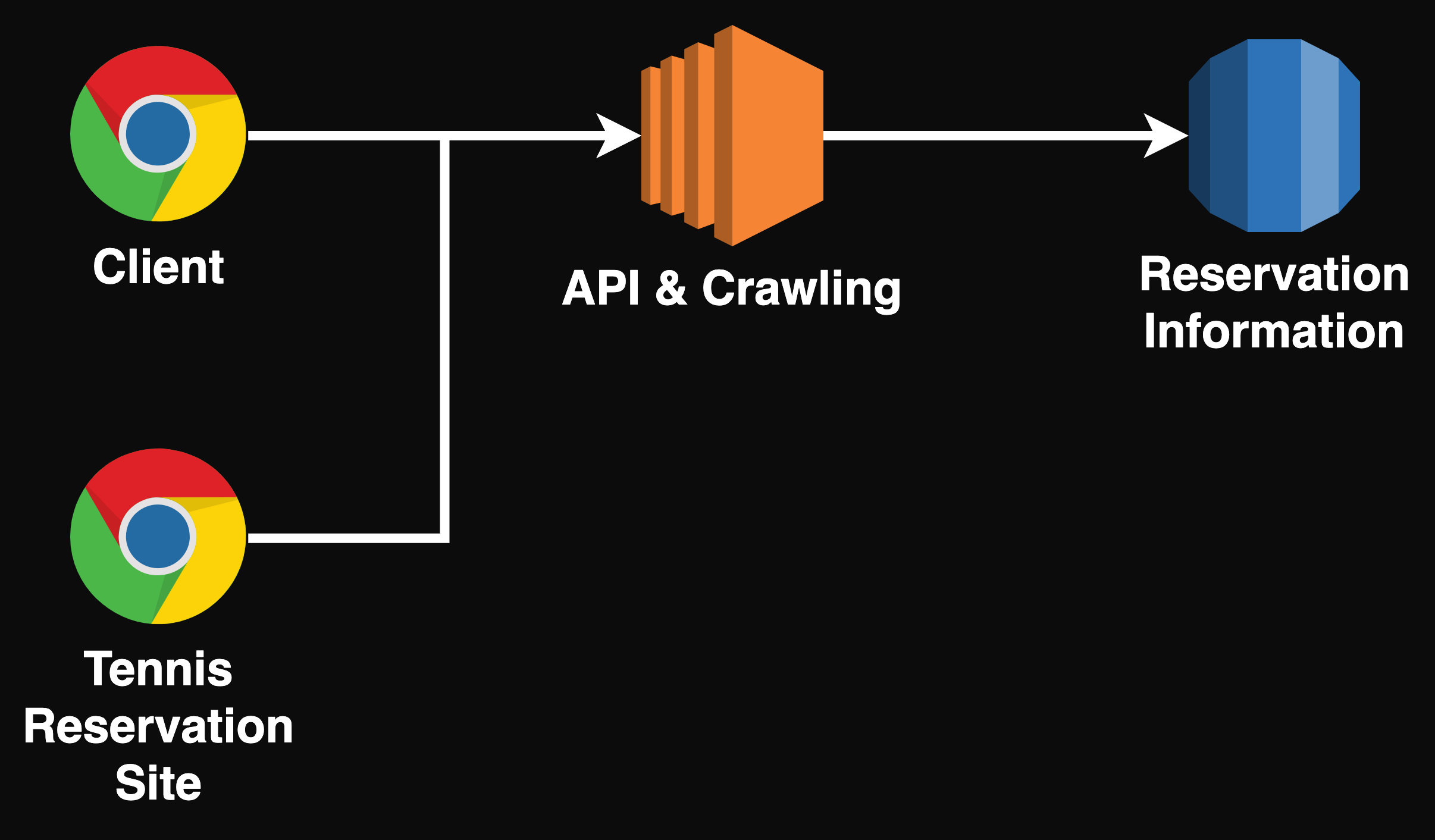
돈 없는 취준생에게는 적절한 환경이었을지 몰라도 실제 운영 환경으로서는 적절치 못하다. 5분마다 2만 건의 업데이트를 해야하고, 서버는 한 대로 운영되는 상황에서 발생할 수 있는 문제점은 크게 두 개였다.
- (5분마다) Crawling을 하기 위해 Chrome을 띄우는 것 + 2만 건의 업데이트 = 매우 부담
- API 환경과 Crawling 환경이 서로 영향을 준다.
아키텍처를 알면 어떨까?
겉핥기로 아키텍처에 대해 알게 된 지금, 이 문제를 마주한다면 어떤 해결책을 제시할 수 있을까?
관심사를 분리하자
어쩌면 (2) API 환경과 Crawling 환경이 서로 영향을 준다.는 문제는 간단하게 해결할 수 있을 거 같다.
클린코드에서 함수를 다룰 때 강조하는 것이 하나의 함수에 하나의 관심사이다. 이유는 다르지만, 위의 경우에 이런 말을 적용할 수 있겠다. 하나의 서버에 하나의 관심사.
API 환경 상에서 문제가 발생하든 Crawling 환경에서 문제가 발생하든, 필연적으로 다른 쪽에 영향을 주는 상황이다. 게다가 Crawling 환경에선 Chrome을 사용해야 하기 때문에, 이 부분에서 CPU 리소스를 많이 사용하게 된다. API 성능으로 이어질 수 있는 부분이다.
이를 해결하기 위해선 서버를 분리하는 게 좋을 것이다.
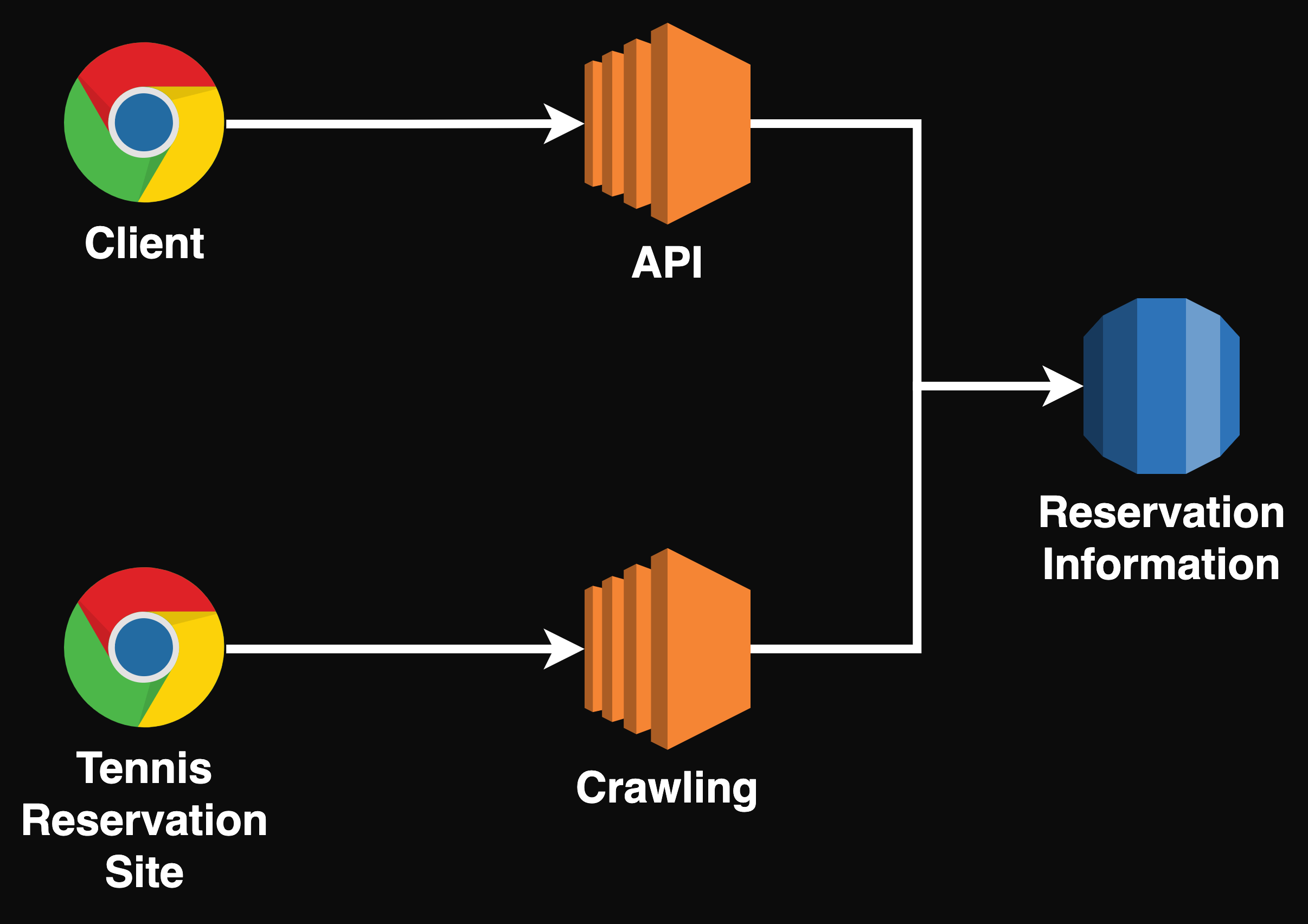
위와 같이 API와 Crawling 서버를 분리하는 경우 상호 간에 영향을 주는 문제나, 크롤링을 위해 켜지는 Chrome으로 인해 API 서버의 성능이 저하되는 상황은 발생하지 않을 것이다.
돈은 누가 내?
야속하게도 AWS 프리티어는 하나의 서버만을 무료로 사용할 수 있다. 돈 없는 취준생은 서버를 두 개 운영하는 것이 부담이 된다. 그렇기 때문에 서버를 추가하지는 않으면서도 위의 상황을 해결할 수 있는 방법이 필요하다.
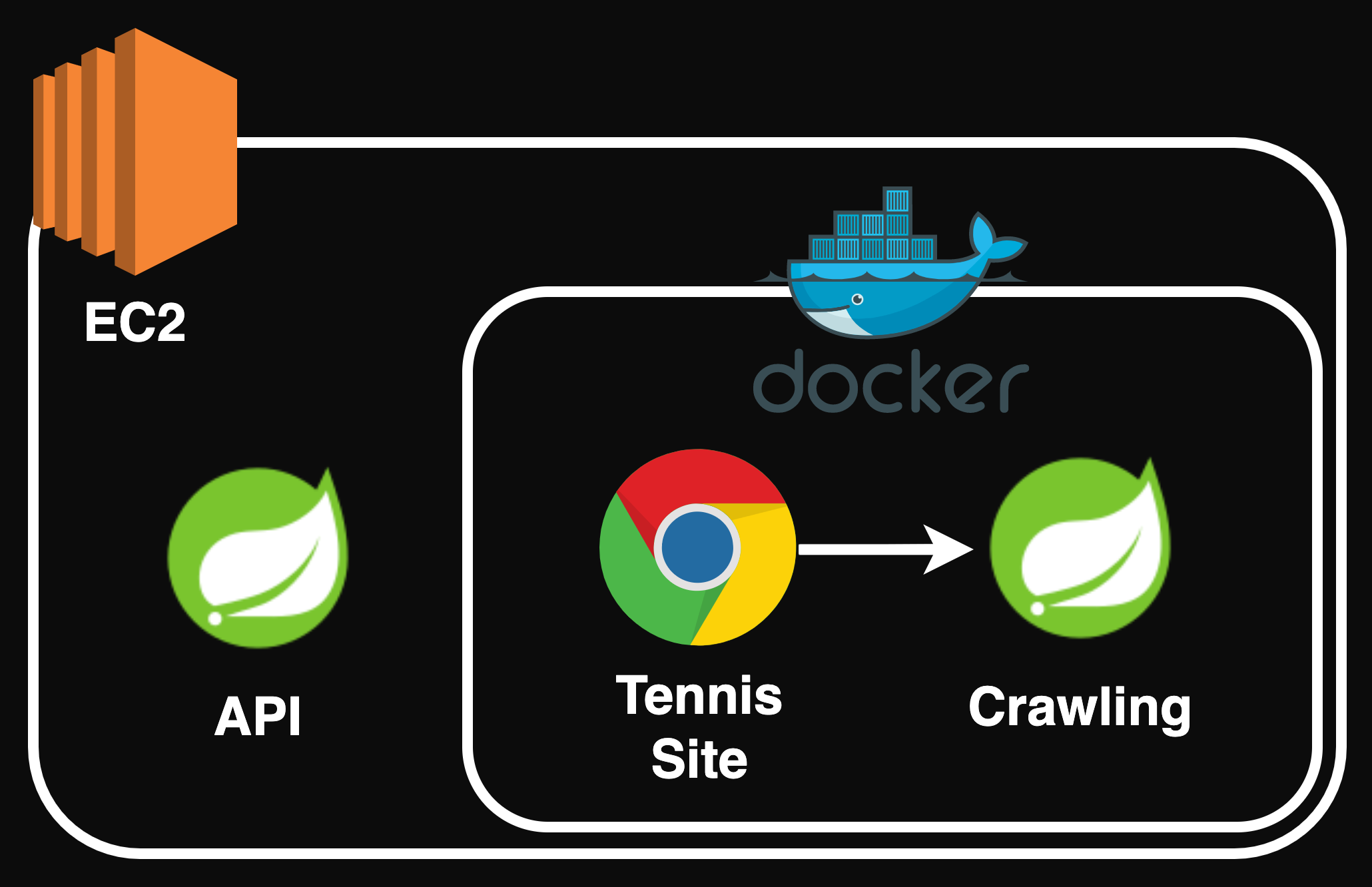
일정한 주기로 실행되어야 하는 Crawling을 Docker로 분리한다. 상대적으로 높은 부하가 생길 가능성이 높은 Crawling 환경이 분리되면서, API 환경이 영향을 받을 여지도 줄어든다. 물론 Docker도 경우에 따라 유료지만 나랑 상관이 없다.
업데이트는? 해줘~
서로 영향을 주는 환경은 어떻게 해결했다고 하자. 여전히 최소 2만 건의 데이터를 업데이트 해야 하는 환경이라는 사실에는 변함이 없다.
기존의 로직에서는 크롤링 데이터를 기존 데이터와 하나하나 비교하여 가능 불가능 여부를 RDB에 저장하였다. 이런 빈번한 I/O 상황에서 빠르고 가볍게 동작하는 게 Redis다.
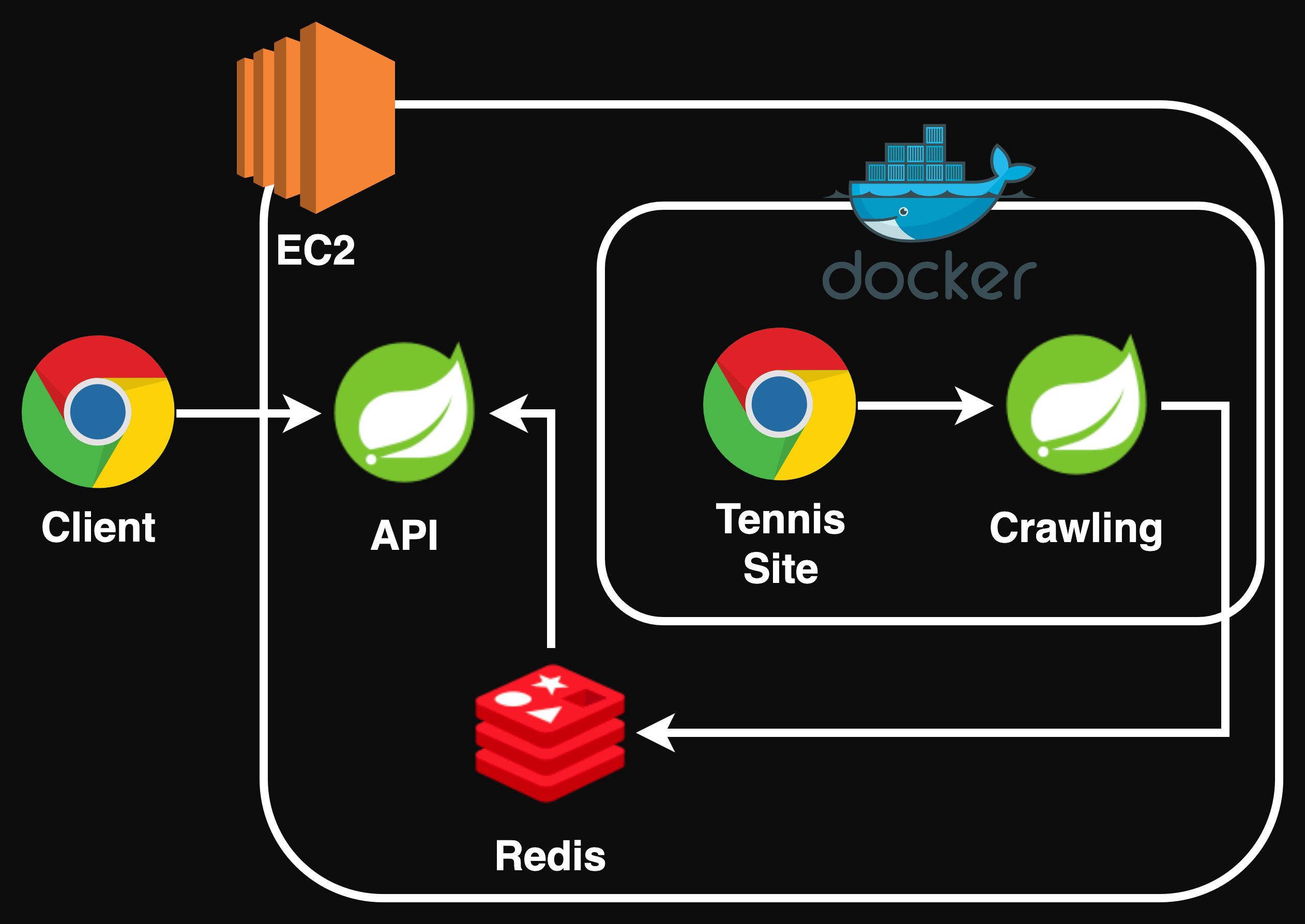
꽤나 복잡해 보이지만, 크롤링 데이터 결과만 Redis에 저장해두는 차이 뿐이다. 사용자로부터 특정 테니스 센터, 코트의 데이터에 대한 조회 요청이 들어오면 해당 시간 정보만 Redis에서 조회해오면 된다.
전체를 비교하는 기존의 방식을 고수하더라도, I/O가 더 빠르다는 Redis의 특징만으로도 충분히 성능 개선을 이뤄낼 수 있을 것이다.
그래서요?
사실 위에서 언급한 아키텍처를 활용한 해결 방법들을 시도해보고 수치적으로 비교해서 글을 썼다면 더할 나위 없이 좋은 경험이면서 공부였겠지만 아쉽게도 그러지 못했다. 몰랐던 게 문제였고, 이제는 알았으니 다음 프로젝트에서 이런 것들을 적용해본다면 충분할 것이다.
