
오늘은 Box Plot과 Categorical Visualization(범주형 시각화)을 해보자.
먼저, test_data.csv를 '등급이 포함된 버전'으로 갱신한다.
import pandas as pd
# 1. 기존 데이터 불러오기
df = pd.read_csv('data_test.csv')
# 2. 등급 계산 로직 적용
# 90점 이상 A, 80점 이상 B, 그 외 C
df['grade'] = df['score'].apply(lambda x: 'A' if x >= 90 else ('B' if x >= 80 else 'C'))
# 3. 갱신된 데이터를 다시 csv로 저장
pd.to_csv('test_data.csv', index=False)
print("--- test_data.csv 파일에 grade 컬럼이 추가되었습니다! ---")
print(df)import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
class EnhancedVisualAnalyzer:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
print(f"[성공] 데이터를 불러왔습니다. 현재 컬럼: {list(self.df.columns)}")
def plot_box(self, x_col: str, y_col: str):
plt.figure(figsize=(10, 6))
sns.boxplot(data=self.df, x=x_col, y=y_col)
plt.title(f"{y_col} Distribution by {x_col}")
plt.show()
def plot_scatter_with_hue(self, x_col: str, y_col: str, hue_col: str):
plt.figure(figsize=(10, 6))
sns.scatterplot(data=self.df, x=x_col, y=y_col, hue=hue_col, s=100)
plt.title(f"{x_col} vs {y_col} (Colored by {hue_col})")
plt.show()
# --- 실행부 ---
# 1. 객체 생성
v_analyzer = EnhancedVisualAnalyzer('test_data.csv')
# 2. 등급(grade)별 점수(score) 분포 확인
v_analyzer.plot_box('grade', 'score')
# 3. 나이와 점수 관계를 보되, 등급별로 색깔 나누기
v_analyzer.plot_scatter_with_hue('age', 'score', 'grade')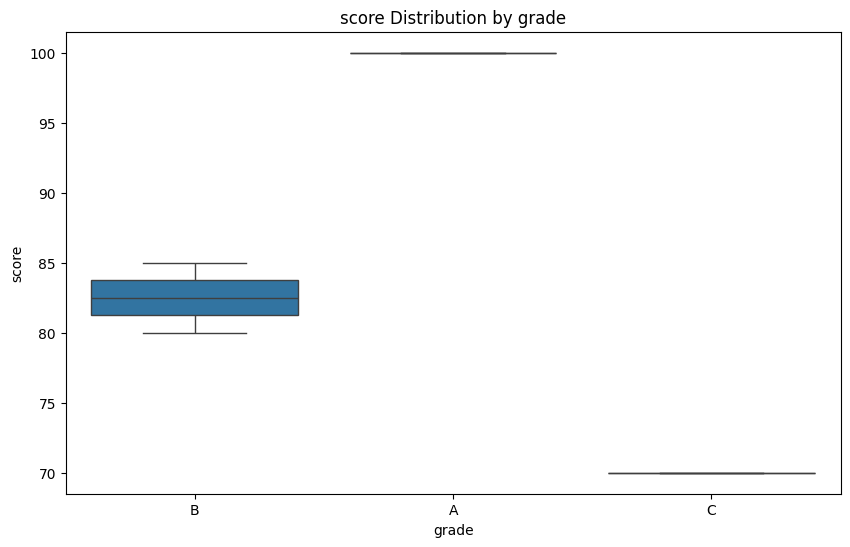
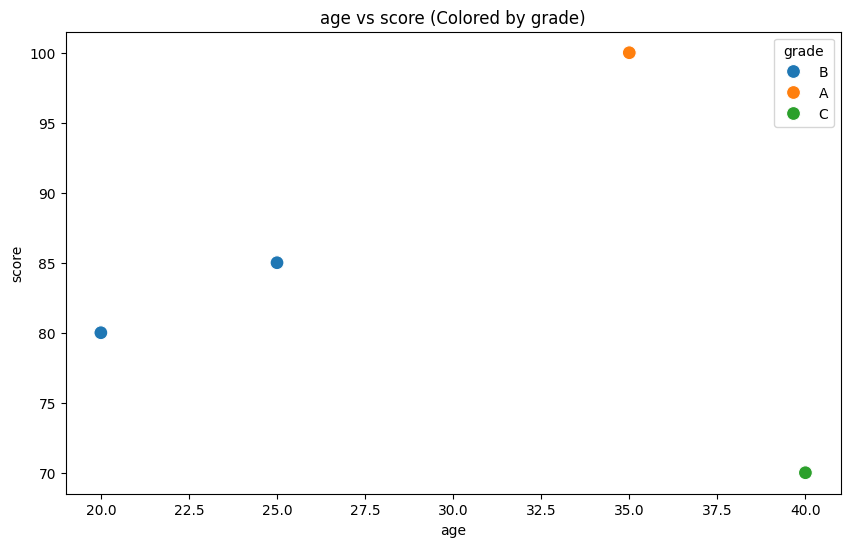
- hue 파라미터: 시각화에서 '차원을 더한다'는 말은 색깔이나 모양으로 데이터를 구분한다는 뜻이다. hue 하나로 단순한 점들이 "의미 있는 군집"으로 보이기 시작한다.
- 데이터 인사이트: 박스 플롯을 그렸을 때 특정 등급의 박스가 유독 짧다면, 그 그룹은 성적이 아주 고르게 분포되어 있다는 뜻이다.

AI/ML Engineer 🧑💻