
다중 회귀(Multiple Regression)란?
여러 개의 독립 변수를 사용하여 하나의 종속 변수를 예측하는 모델이다.
- 공식:
- AI는 각 변수가 결과에 얼마나 중요한지 가중치를 스스로 찾아낸다.
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
class CompetitionPredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'prev_difficulty_level', 'is_multi_learner']
self.target = 'completed'
self.df = self.df[self.features + [self.target]].dropna()
self.model = LinearRegression()
def run_multiple_regression(self):
X = self.df[self.features]
y = self.df[self.target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
self.model.fit(X_train, y_train)
y_pred = self.model.predict(X_test)
r2 = r2_score(y_test, y_pred)
print(f"--- 다중 회귀 분석 결과 ---")
print(f"사용한 변수: {self.features}")
print(f"결정계수(R2 Score): {r2: .4f}")
for feature, coef in zip(self.features, self.model.coef_):
print(f"{feature}의 영향력: {coef: .4f}")
# --- 실행부 ---
predictor = CompetitionPredictor('train.csv')
predictor.run_multiple_regression()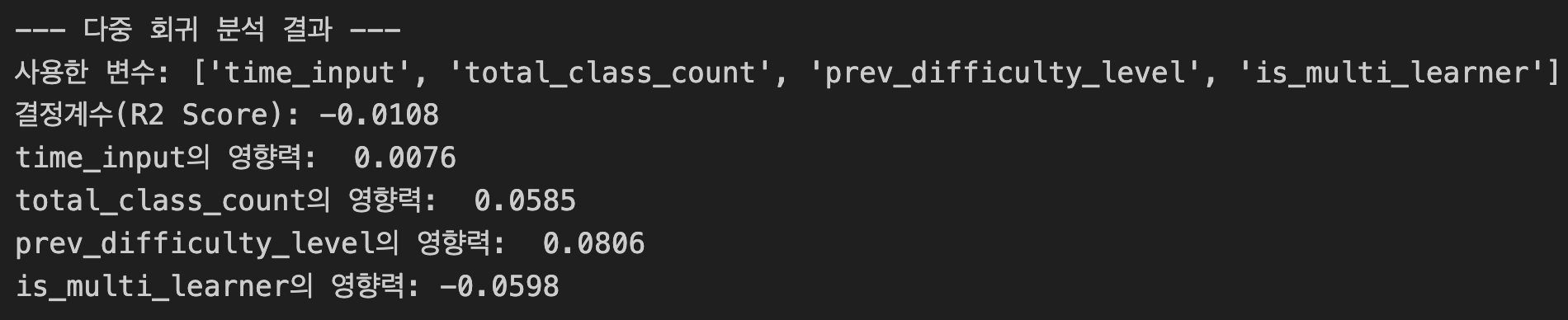
Coef (Coefficient, 회귀 계수) = "영향력의 크기와 방향"
회귀 계수는 독립 변수가 한 단위 변할 때 종속 변수가 얼마나 변하는지를 나타내는 숫자이다.
- 비유: 요리할 때 '설탕'이라는 재료의 Coef가 2.0이라면, 설탕을 한 스푼 더 넣을 때마다 요리의 단맛이 2만큼 높아진다는 뜻이다.

AI/ML Engineer 🧑💻