특성 중요도(Feature Importance)란?
랜덤 포레스트 모델은 학습을 마친 후, 각 변수가 의사결정 나무의 불순도를 줄이는 데 얼마나 기여했는지 점수를 매긴다. 이 점수가 높을수록 수료 여부를 결정짓는 '결정적 단서'였다는 뜻이다.
왜 중요한가?
- 변수 다이어트: 점수가 0에 가까운 무의미한 변수들을 제거하여 모델을 가볍고 정확하게 만든다.
- 비즈니스 인사이트: "아, 수료에는 유입 경로보다 학습 시간이 압도적으로 중요하구나!" 같은 결론을 내릴 수 있다.
import pandas as pd
import matplotlib.pyplot as plt
import koreanize_matplotlib
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
class FeatureImportanceAnalyzer:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner',
'is_extra_class', 'major_field', 'inflow_route']
self.target = 'completed'
for col in ['major_field', 'inflow_route']:
self.df[col] = self.df[col].fillna("Unknwon")
self.df = self.df[self.features + [self.target]].dropna()
def analyze_importance(self):
# 1. 전처리 및 학습
encoded_df = pd.get_dummies(self.df, columns=['major_field', 'inflow_route'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = RandomForestClassifier(
n_estimators=100,
class_weight='balanced',
random_state=42
)
model.fit(X_train, y_train)
# 특성 중요도 추출
importances = model.feature_importances_
features_name = X.columns
# 데이터프레임으로 정리
fi_df = pd.DataFrame({'Feature': features_name, 'Importance': importances})
fi_df = fi_df.sort_values(by='Importance', ascending=False).head(10) # 상위 10개
# 시각화
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=fi_df)
plt.title("Top 10 Important Features for Completion Prediction")
plt.tight_layout()
plt.savefig("feature_importance.png")
print("--- 상위 10개 중요 변수 ---")
print(fi_df)
print("\n그래프가 'feature_importance.png'로 저장되었습니다.")
# --- 실행부 ---
analyzer = FeatureImportanceAnalyzer('train.csv')
analyzer.analyze_importance()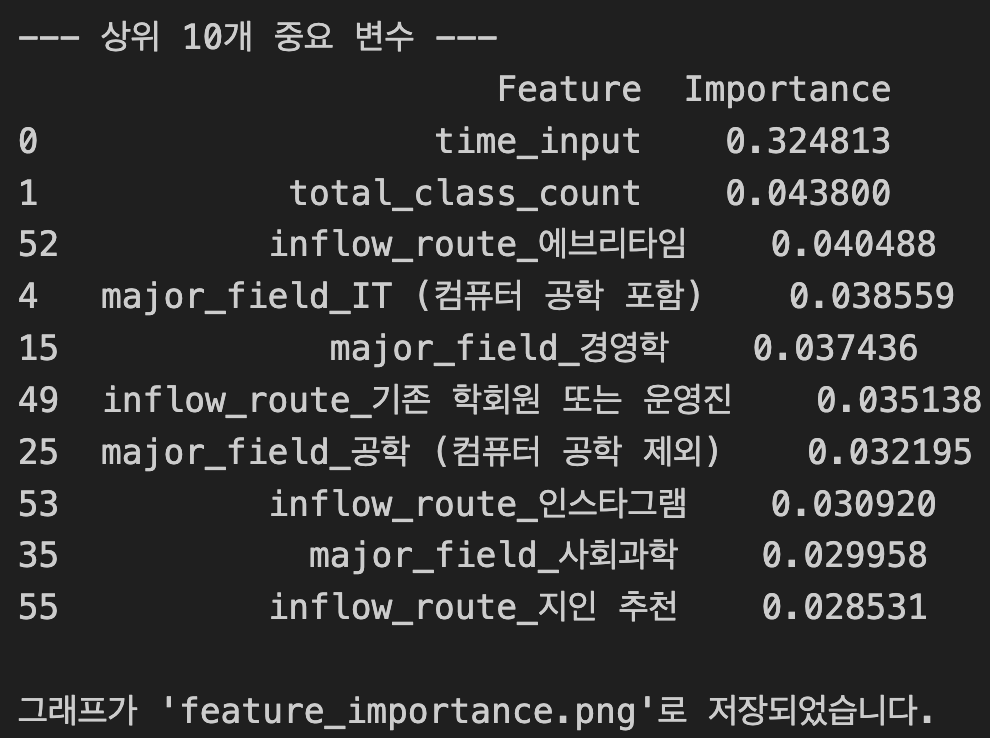
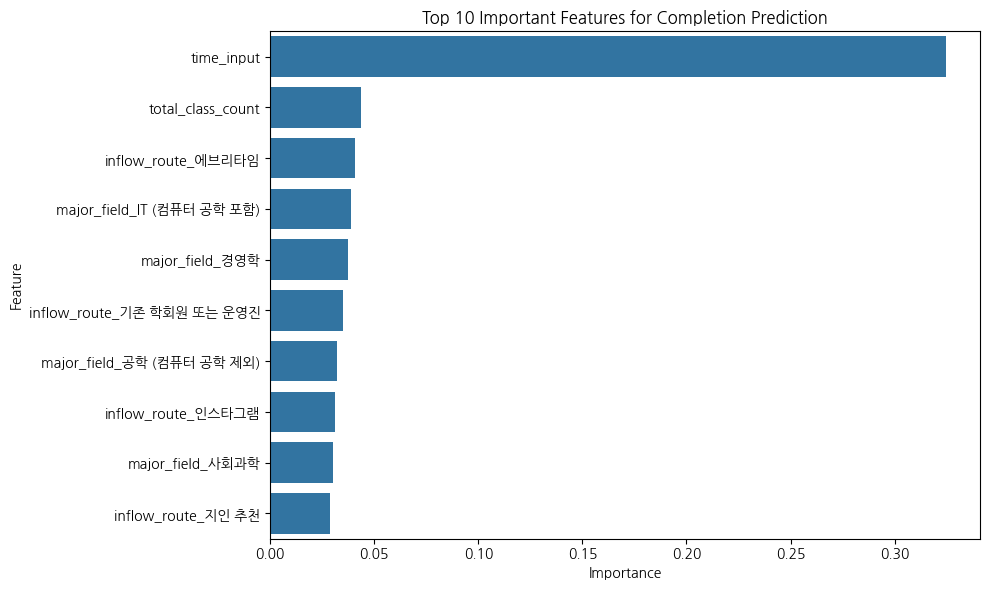
압도적 1위 time_input (0.3248):
- 학습 시간이 수료를 결정짓는 가장 큰 요인이었다. 다른 변수들의 중요도가 0.04 수준인 데 비해 혼자서 0.32를 차지한다는 건, 수료를 하려면 일단 '절대적인 시간'을 투자하는 게 핵심이라는 뜻이다.

AI/ML Engineer 🧑💻