모델의 지능도 중요하지만, 사실 AI의 성능을 결정짓는 80%는 어떤 데이터를 넣어주느냐에 달려 있다.
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
class UltimateFeaturePredictor:
def __init__(self, file_path: str):
self.df = pd.read_csv(file_path)
self.features = ['time_input', 'total_class_count', 'is_multi_learner', 'is_extra_class', 'major_field', 'inflow_route']
self.target = 'completed'
for col in ['major_field', 'inflow_route']:
self.df[col] = self.df[col].fillna('Unknown')
self.df = self.df[self.features + [self.target]].dropna()
def run_ultimate_analysis(self):
encoded_df = pd.get_dummies(self.df, columns=['major_field', 'inflow_route'])
X = encoded_df.drop(columns=[self.target])
y = encoded_df[self.target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = RandomForestClassifier(
n_estimators=100,
class_weight='balanced',
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"--- 특성 공학 적용 결과 ---")
print(f"사용된 총 컬럼 수: {len(X.columns)}개")
print("\n[혼동 행렬]")
matrix = confusion_matrix(y_test, y_pred)
print(matrix)
print(f"\n실제 수료자 42명 중 AI가 찾아낸 인원: {matrix[1, 1]}명")
print("\n" + classification_report(y_test, y_pred))
# --- 실행부 ---
predictor = UltimateFeaturePredictor('train.csv')
predictor.run_ultimate_analysis()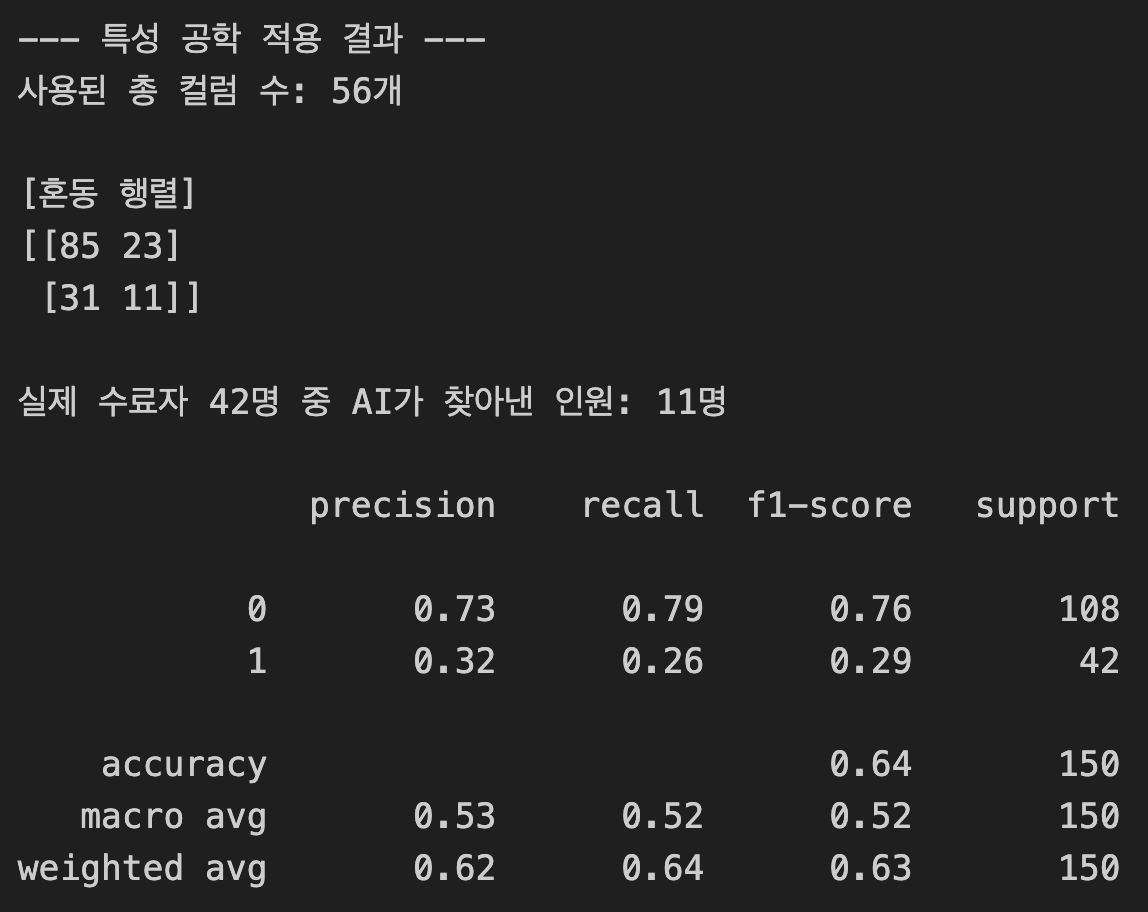
적중 인원(Recall)의 하락 원인:
- 지난번에는 20명을 맞혔는데 이번에는 11명으로 줄었다. 이는 '정보의 노이즈'때문일 가능성이 크다.
- 변수가 너무 많아지면 모델이 진짜 중요한 핵심보다 덜 중요한 정보에 휘둘리게 된다. 이를 차원의 저주라고도 부른다.

AI/ML Engineer 🧑💻