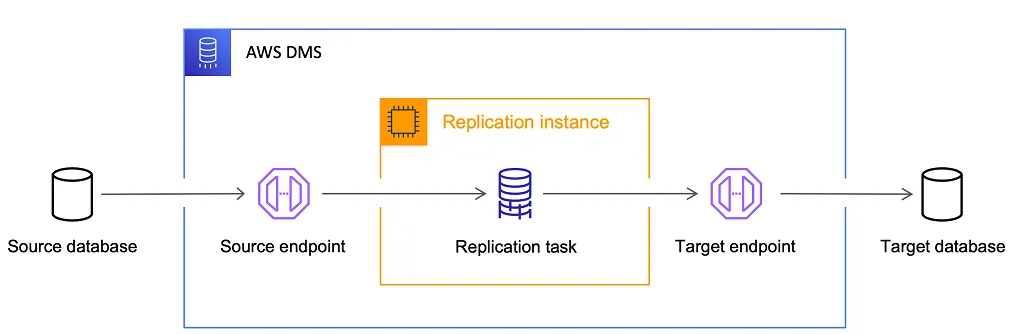
1. AWS DMS 아키텍처 핵심 컴포넌트
- Replication Instance
- 관리형 EC2, RDBMS 각각의 트랜잭션 로그(binlog, WAL, redo 등) 읽기 → 변환 → 대상 전송
- 로그 소비 방식 두 가지 (둘 다 binlog 사용)
- RDS/Aurora 리드 레플리카
- MySQL 엔진이 binlog 단일 스트림을 그대로 재생

- 기본적으로
MIXED모드 사용 → 내부적으로STATEMENT또는ROW를 상황에 따라 선택ROW: 변경된 데이터 값 자체(row-level) 기록STATEMENT: SQL 문장을 기록
ROW도 완전히 지원하며 정합성 보장에 유리함STATEMENT모드는 "비결정적 함수"(예:UUID(),NOW()등)가 포함되면 복제 결과가 달라질 수 있음- 예:
UPDATE users SET token = UUID();→ 마스터와 레플리카의 UUID가 달라질 수 있음 - 그래서 이 경우 MySQL이 자동으로
ROW모드로 전환함 (→ MIXED의 의미)
- 예:
- MySQL 엔진이 binlog 단일 스트림을 그대로 재생
- AWS DMS CDC
- DMS 인스턴스가 row-based binlog만 지원

- SQL 문장이 아닌 row 변경 데이터 자체를 추출해 대상 시스템(S3, Kafka 등)에 적용
- 다양한 시스템에 전송하는 데이터 파이프라인 용도
binlog_format이 반드시ROW로 설정되어 있어야 함
- DMS 인스턴스가 row-based binlog만 지원
- 한줄 요약: 둘 다 binlog를 사용하지만, RDS는 DB 자체를 복제해서 읽기 전용 레플리카를 만들고, DMS는 binlog를 읽어와 다양한 시스템으로 데이터를 스트리밍하는 파이프라인 역할을 한다.
- RDS/Aurora 리드 레플리카
- 스펙(T2/T3, R5 등)과 스토리지 크기, ParallelLoadThreads 조정이 성능 좌우
- ParallelLoadThreads란? Full Load 단계에서 AWS DMS가 데이터를 여러 스레드로 나눠 병렬로 로드할 때 사용할 스레드 수를 지정하는 설정
- Endpoints
- Source: Aurora MySQL Writer 엔드포인트(Reader는 CDC 불가)
- RDS Reader는 바이너리 로그(binlog)를 제공하지 않아 DMS CDC에 필요한 변경 이벤트를 읽을 수 없기 때문
- Target: OpenSearch, RDS, S3, Kafka 등 다중 지원
- VPC·보안 그룹·SSL·IAM 역할로 접근 통제
- Source: Aurora MySQL Writer 엔드포인트(Reader는 CDC 불가)
- Migration Task
- 모드: Full Load / CDC / Full+CDC
- Transformation: 필터·컬럼 매핑·타입 변환(단순)
- 컬럼명을 바꾸며 문자열↔숫자/날짜 같은 단순 타입 변환을 적용하는 기능
2. DMS 복제 시나리오 및 활용 패턴
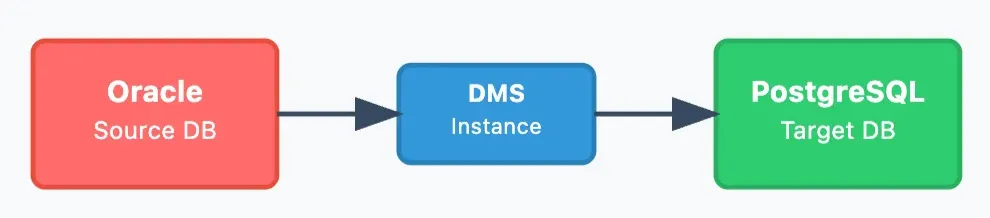
- 1:1 복제 (이기종 마이그레이션)
- 용도: Oracle → PostgreSQL 등 DB 엔진 변경
- 특징: 스키마 자동 변환, 라이선스 비용 절감
- 사진
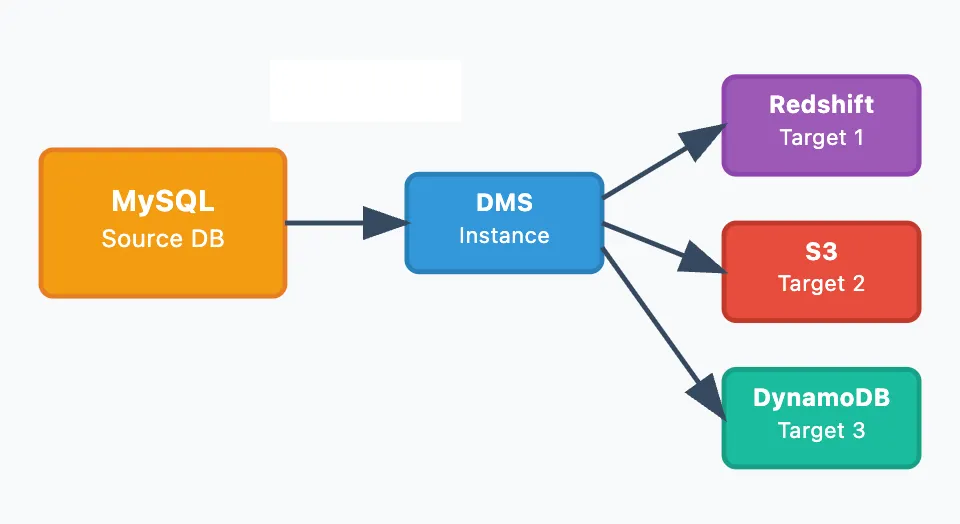
- 1:N 복제
- 용도: 단일 소스 → 여러 타겟 (분석DB, 백업 등)
- 특징: 독립적 복제, 장애 격리, 용도별 저장소 최적화
- 사진
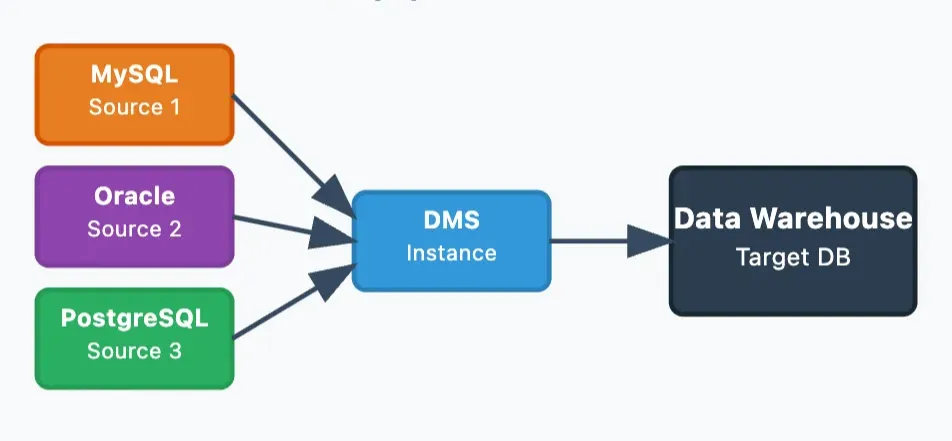
- N:1 복제
- 용도: 여러 소스 → 데이터 웨어하우스 통합
- 특징: 데이터 중앙 집중화, 통합 분석 환경
- 사진
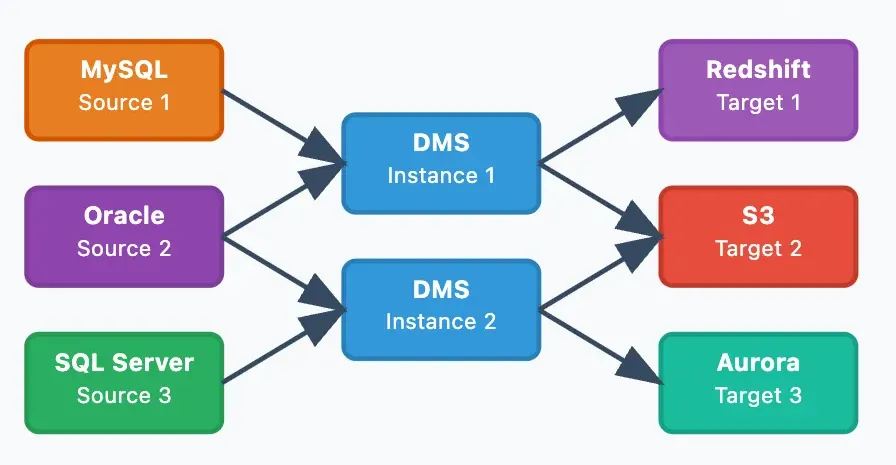
- N:M 복제 (복합)
- 용도: 대규모 엔터프라이즈 복합 파이프라인
- 특징: 복수 DMS 인스턴스, 높은 유연성
- 사진
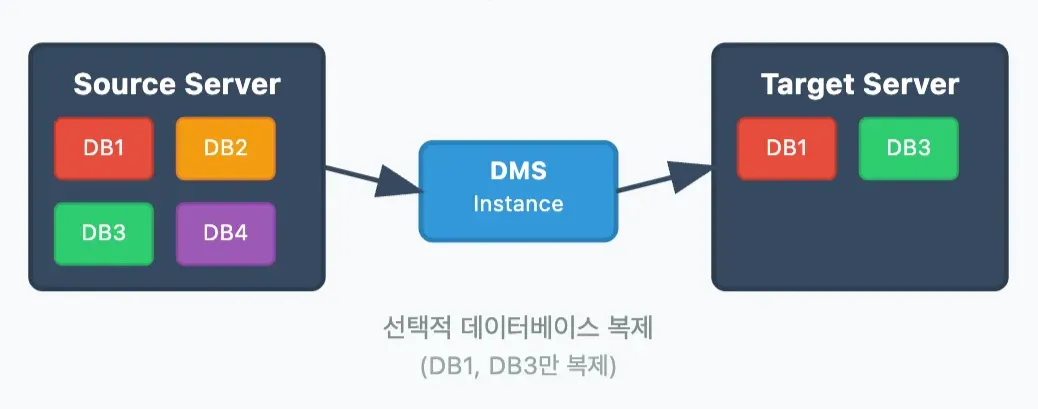
- 데이터베이스 단위 제어
- 레벨별 필터링: DB → 테이블 → 컬럼 → 조건부
- 활용: 개발/테스트용 부분 복제, 개인정보 제외
- 사진
3. 데이터 이동 흐름 (Full Load, CDC)
https://claude.ai/public/artifacts/33f41ab8-6957-4bb1-af95-7078500cc416

- Full Load
- 목적: 초기 상태를 한 번에 동기화
- 작업 :
- 전체 테이블을 병렬 스레드로 스캔 (SELECT *)
- 대량 데이터를 Bulk 적재 (Bulk API)
- 로드 중 발생하는 INSERT/UPDATE/DELETE 이벤트는 메모리 캐시에 임시 보관
- 고려사항 :
- 병렬 스레드(ParallelLoadThreads)로 처리하는데 로드할 때도 DMS는 테이블 간 의존성(FK 순서)을 고려해 부모 테이블을 먼저 로드한 뒤 자식 테이블을 처리하도록 워크플로우를 관리하는데 이러면 성능적 저하가 불가피하다.
- 그래서 공식문서에서는 외래키를 제거하고 Full Load를 하라고 나와있다.

- 캐시된 변경 반영
- 시점 : Full Load 완료 직후
- 작업 :
- 캐시에 쌓인 변경 이벤트를 FIFO(선입선출) 순서로 꺼내어 대상 시스템에 순차 적용 (INSERT/UPDATE/DELETE)
- 효과: Full Load 중 발생한 변경까지 모두 반영하여 데이터 일관성 보장
- CDC
- 시점 : Full Load가 끝나고 캐시에 쌓인 변경 이벤트를 순서대로 (FIFO) 처리가 완료 된 직후
- 작업 :
- Aurora/MySQL의 바이너리 로그(binlog) 또는 PostgreSQL의 WAL 스트림을 실시간 모니터링
- 새로운 변경 이벤트를 감지하는 즉시 대상에 Near Real-Time 반영
- 고려 사항 :
- Replica vs CDC
구분 순서 보장 (테이블 내) 순서 보장 (테이블 간) 실행 방식 스트림 구조 RDS/Aurora 리플리카 ✅ ✅ 싱글 스레드 단일 스트림 AWS DMS CDC (기본 설정) ✅ ✅ 싱글 스레드 (트랜잭션 단위 처리) 트랜잭션 단일 스트림 AWS DMS CDC (배치 적용 모드) ✅ ❌ 멀티 스레드 (또는 배치 처리) 테이블별 병렬 스트림 - 왜 순서 보장 차이가 발생하나요?
- 데이터 복제 시 순서 보장은 매우 중요합니다. 특히 외래 키(FK) 제약 조건이 있는 경우, 부모 테이블의 변경이 자식 테이블의 변경보다 먼저 적용되어야 데이터 정합성이 유지됩니다.
- RDS/Aurora 리플리카는 데이터베이스의 바이너리 로그 또는 WAL 스트림을 단일 스트림으로 복제합니다. 이는 소스 데이터베이스에서 변경이 발생한 정확한 순서대로 모든 테이블의 변경 사항을 재생하므로 테이블 간 순서 정합성(FK 제약 조건 유지)이 완벽하게 보장됩니다.
- AWS DMS는 기본적으로 트랜잭션 정합성 모드로 CDC를 처리합니다. 이는 소스 데이터베이스에서 커밋된 트랜잭션 단위로 변경 이벤트를 묶어서 처리하며 대상에 단일 스레드로 순차적으로 적용하여 트랜잭션 무결성과 테이블 간 순서 정합성(FK 제약 조건 유지)을 보장합니다.
- 공식문서

- 공식문서
- AWS DMS CDC 배치 적용 모드는 성능 향상을 위해
BatchApplyEnabled옵션을 true로 설정하여 배치 적용 모드를 사용할 수 있습니다. 이 모드는 변경 이벤트를 테이블별로 그룹화하거나 멀티 스레드할 수 있습니다. 하지만 이로 인해 서로 다른 테이블 간(예: 부모 → 자식)의 순서가 바뀔 수 있어 FK 제약 조건이 깨질 위험이 존재합니다.- 예시
- 엄청나게 많은 로그데이터를 매일매일 수집하는 분석용 데이터베이스에 넣고 싶을 때
- 운영 중인 데이터베이스의 데이터를 재해 복구(DR) 목적으로 다른 리전이나 다른 데이터베이스에 백업 형태로 계속 복제해두고 싶을 때
- 공식문서

- 예시
- Replica vs CDC
- 링크
4. Full Load vs CDC 비교
| 구분 | Full Load | Change Data Capture (CDC) |
|---|---|---|
| 범위 | 전체 테이블(수 GB~TB) | 변경된 레코드만(수 KB~MB) |
| 부하 | 일시적 대량 I/O | 상시 소량 스트리밍 |
| 지연 | 완료까지 분·시간 대 | 초(튜닝 시 서브초) |
| 사용 시점 | 초기 마이그레이션, 대량 백업·복구 | 운영 중 실시간 동기화 |
5. RDS Aurora (MySQL) → OpenSearch 데이터 마이그레이션 예시

- 테이블명이 인덱스명이 됨
- 각 행(row) → 하나의 도큐먼트
- 데이터 타입 매핑
- VARCHAR/TEXT → keyword 또는 text
- INT/BIGINT → long
- DECIMAL → double
- DATE/TIMESTAMP → date
- BOOLEAN → boolean
6. 데이터 타입 자동 매핑의 문제점
| 문제 | 설명 |
|---|---|
| 무분별한 필드 생성 | 개발 중 발생하는 모든 칼럼·잠정 파라미터가 곧바로 매핑되어 수백 개의 작은 인덱스 필드가 생성될 수 있습니다. (mapping explosion) |
| 잘못된 데이터 타입 | 예: 우편번호나 전화번호 같은 숫자형이지만 text 로 매핑되어 범위 쿼리·숫자 집계에 부적합해집니다. |
| 분석기 미지정 | 한글·일본어 등 비영어 텍스트에 기본 standard analyzer를 사용 → 토크나이저 성능 저하. |
| 스키마 변경 대응 어려움 | 동적 매핑이 신규 필드를 허용하므로 스키마 변경 시 의도치 않은 타입 추론이 발생할 수 있습니다. |
7. 커스텀 매핑을 위한 접근법
- 동적 매핑 비활성화 (Disabling Dynamic Mapping)
- 장점
- 스키마가 조금이라도 흐트러지는 걸 절대 용납 못 할 때
- 정의되지 않은 필드는 아예 못 들어오게 막고 싶을 때 사용
- 단점
- 새로운 필드가 추가되면 수동으로 매핑을 꼭 바꿔줘야 함
- 깜빡하면 데이터가 누락되거나 시스템이 멈출 수도 있음
- 장점
- 명시적 매핑 (Explicit Mapping)
- 장점
- 데이터 필드가 거의 변하지 않고 아주 중요할 때 (예: 사용자 ID, 정확해야 하는 가격, 검색 핵심 단어).
- 완벽하게 통제하고 싶을 때 사용
- 단점
- 필드가 많거나 자주 바뀌면 관리하기 정말 힘듬
- 장점
- 동적 템플릿 (Dynamic Templates)
- 장점
- 필드 이름에 규칙이 있거나 비슷한 필드가 많을 때 (예:
_id로 끝나는 건 무조건 키워드 타입,ko_로 시작하는 건 한글 검색용으로) - 유연함과 통제를 동시에 원할 때 제일 현실적인 방법
- 필드 이름에 규칙이 있거나 비슷한 필드가 많을 때 (예:
- 단점
- 처음에 템플릿 규칙을 잘 만드는 게 어려울 수 있음
- 규칙이 복잡하면 오히려 헷갈릴 수도 있음
- 장점
- 그렇다면 다른 회사에서는 어떻게 처리를 하는가? (토스)

- 동적 매핑 비활성화 (
dynamic: false){ "dynamic": false, ... }설정으로 정의되지 않은 필드가 인덱스에 들어오는 것을 아예 막아버림
- 명시적 매핑 (Explicit Mapping)
user.name필드를{ "type": "keyword" }로 명시하는 것처럼, 필요한 필드는 정확하게 지정하여 데이터의 정확성과 검색 효율성을 보장
- 동적 템플릿 (
dynamic_templates) 활용strings_as_keyword템플릿처럼 모든 문자열(string) 필드를 기본text가 아닌keyword로 자동 매핑하여 잘못된 타입 추론을 막고 불필요한 분석기 사용을 줄임
- 동적 매핑 비활성화 (
8. 그래서 왜 OpenSearch인가?
리멤버에서는 해당 부분을 이렇게 사용했다고 합니다.
- MongoDB의 한계: 속도 병목
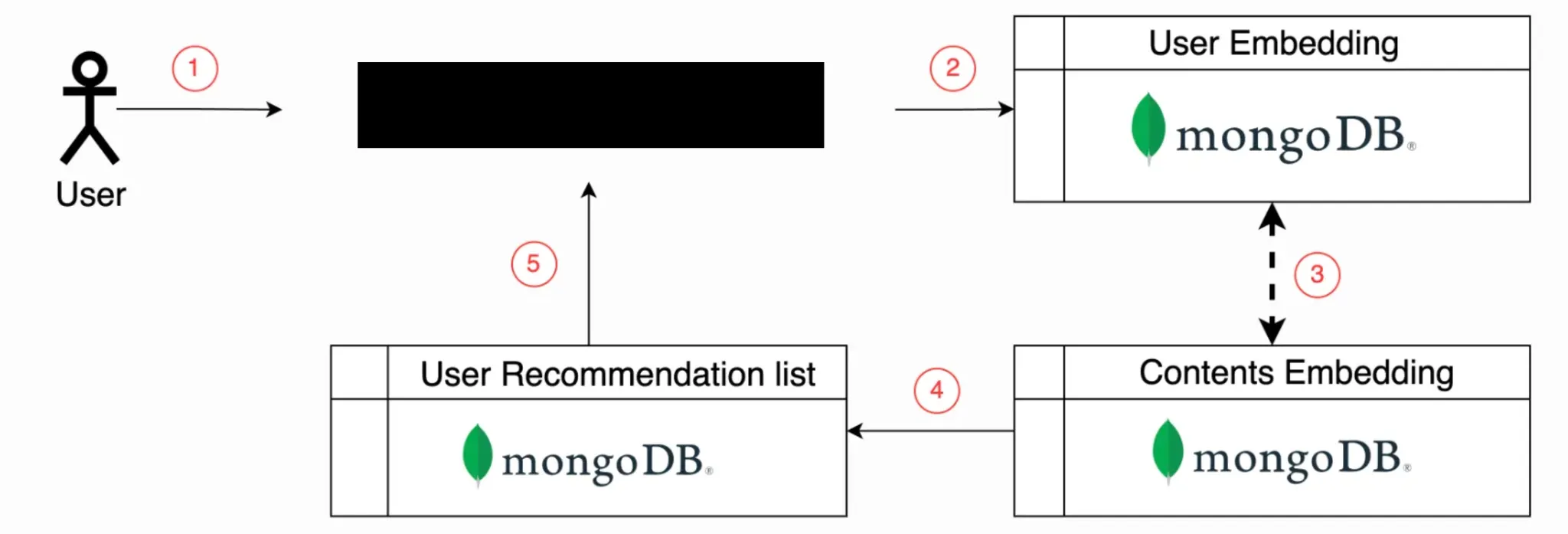
- 처음에는 MongoDB에 임베딩을 저장하는 방식을 고려했지만 수천 개 임베딩의 유사도 계산에 5초나 걸려 실시간 서비스엔 부적합했다고 함
- MongoDB는 대량의 데이터를 빠르게 저장하지만 내부 벡터 유사도 계산 기능이 없어 모든 데이터를 앱에서 직접 처리해야 하는 비효율성이 컸음
- OpenSearch의 해결책: 압도적인 속도와 기능
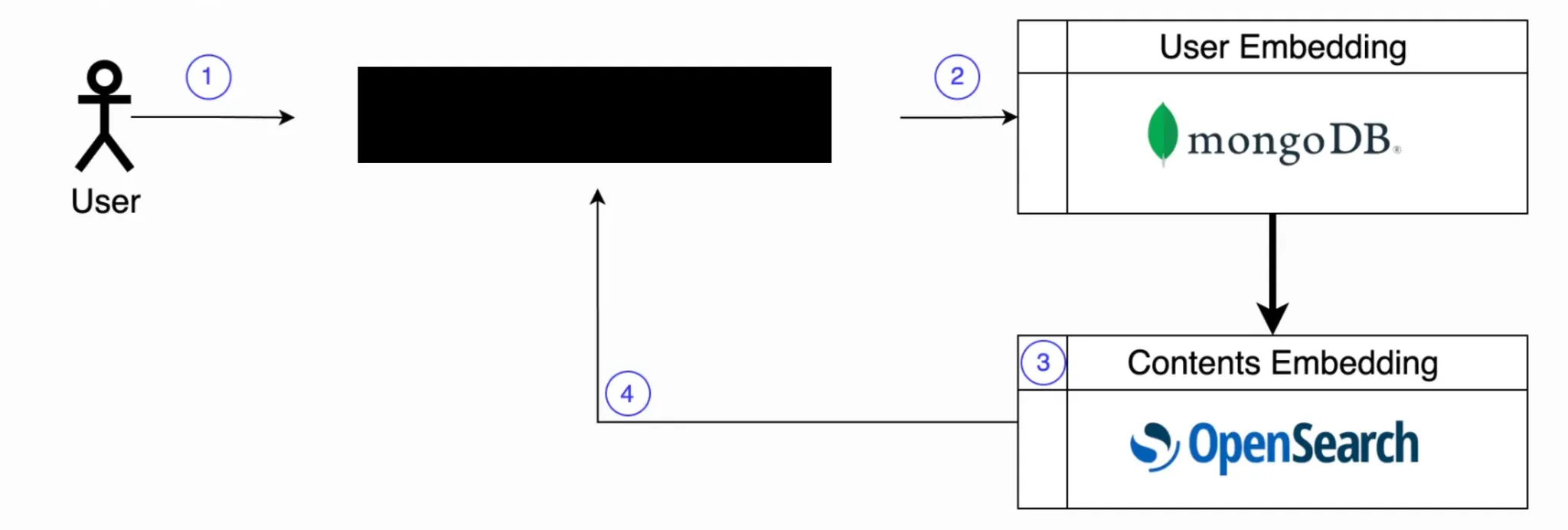
- OpenSearch는 분산 검색 엔진 내부에서 벡터 간 유사도를 직접 그리고 매우 빠르게 계산(k-NN 검색)하는 기능을 제공함
- 특히 HNSW 알고리즘 기반 k-NN 검색 덕분에 방대한 임베딩 벡터 속에서도 가장 유사한 벡터들을 단시간(0.x 초)에 찾을 수 있음.
- 왜 실시간 AI 모델 추론엔 OpenSearch일까?
- 고차원 벡터 유사도 검색 특화: OpenSearch는 k-NN 검색으로 수백~수천 차원의 임베딩 벡터 간 유사도를 엔진 내부에서 초고속으로 계산합니다.
- 압도적인 실시간 성능: 데이터베이스에서 데이터를 가져와 앱이 계산하는 병목을 없애 진정한 실시간 AI 추론 및 추천 서비스를 가능하게 합니다.
- 탁월한 확장성: 사용자나 콘텐츠 임베딩 데이터가 아무리 늘어나도 수평적 확장을 통해 안정적인 성능을 유지할 수 있습니다.
- 결론!
- 스캠 유저 탐지 모델이나 개인화된 추천 모델처럼 방대한 임베딩 벡터 사이에서 가장 유사한 대상을 실시간으로 찾아야 하는 미래의 AI/ML 모델 추론 서비스에서는 MongoDB가 아닌 OpenSearch를 강력하게 추천함.
- OpenSearch는 벡터 검색에 특화된 기능으로 AI 모델의 성능과 효율성을 혁신적으로 높여줄 것임.
참고 자료
Using an Oracle database as a source for AWS DMS - AWS Database Migration Service
Amazon Kinesis stream as a source for EventBridge Pipes - Amazon EventBridge
What is AWS Database Migration Service? - AWS Database Migration Service

지나가는 개발자