1. 문제 배경
- 이미지가 로드가 느린 이미지들이 있었음. 이미지 로드가 느린 이미지들은 주로 aws cloud front를 사용하는 이미지들이었음.
- 구조
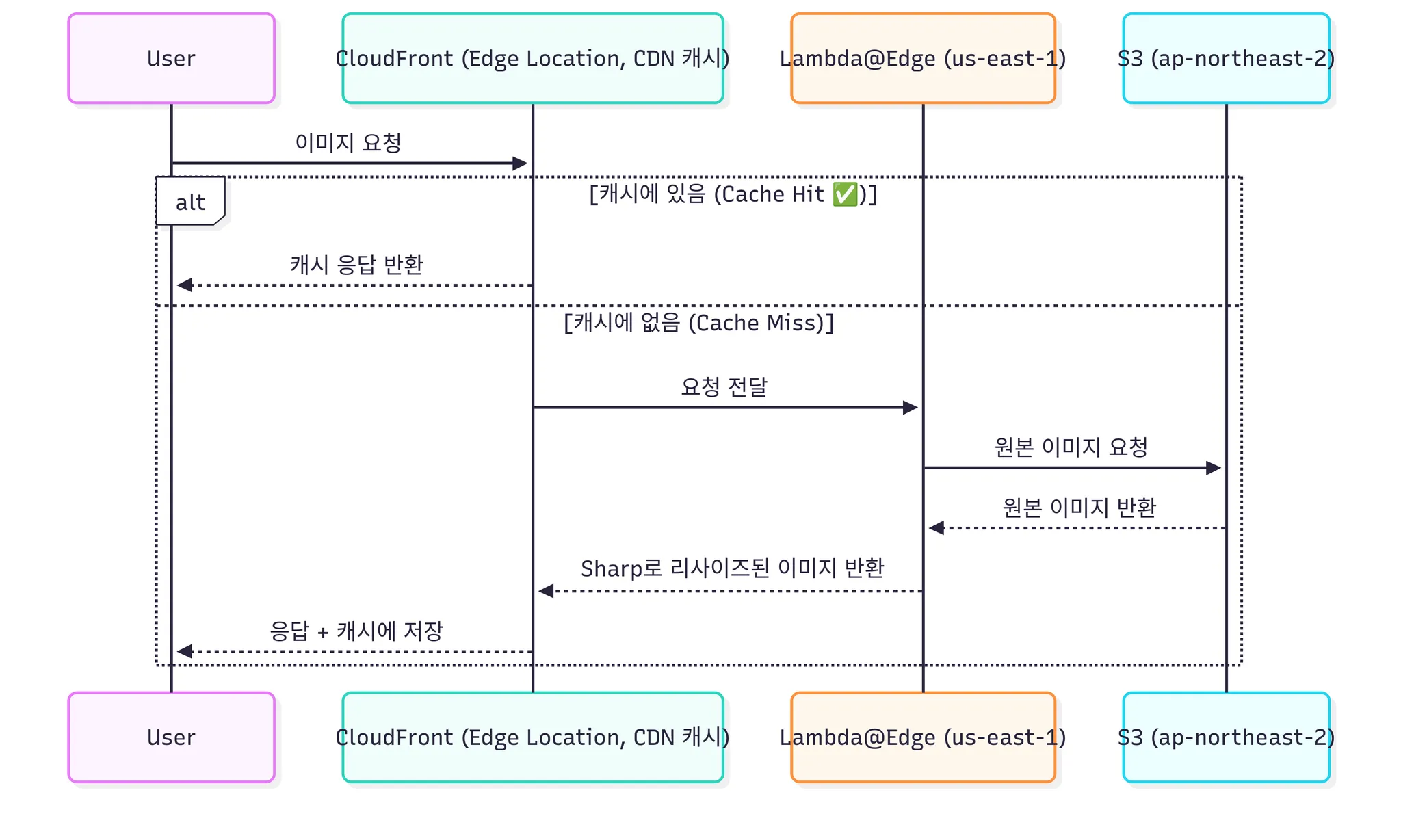
- Lambda@Edge(us-east-1) 역할
- CloudFront 요청 가로채기
- 사용자가 이미지 요청 시, CloudFront에서 캐시 MISS 나면 Lambda@Edge 실행.
- 원본 S3에서 이미지 가져오기
- S3(ap-northeast-2)에서 원본 이미지를 getObject로 읽음.
- 리사이즈 처리
- 요청 파라미터(?w=160&h=160, ?w=1035&h=1035, ?f=webp, ?q=90)를 읽어 Sharp로 리사이즈.
- 조건 처리
- gif + 포맷 변환 없음 → 원본 그대로 응답.
- 리사이즈된 이미지 크기 ≥ 1MB → 원본 그대로 응답.
- CloudFront 응답
- 리사이즈된 이미지를 Base64로 인코딩해서 CloudFront에 전달.
- CloudFront가 캐시에 저장 → 이후 요청은 바로 Cache Hit.
- CloudFront 요청 가로채기
- 즉 요청 시점(on-demand) 리사이즈 → CloudFront 캐시에만 저장 → S3에 다시 저장하지 않음 구조.
- Lambda@Edge(us-east-1) 역할
- 문제점
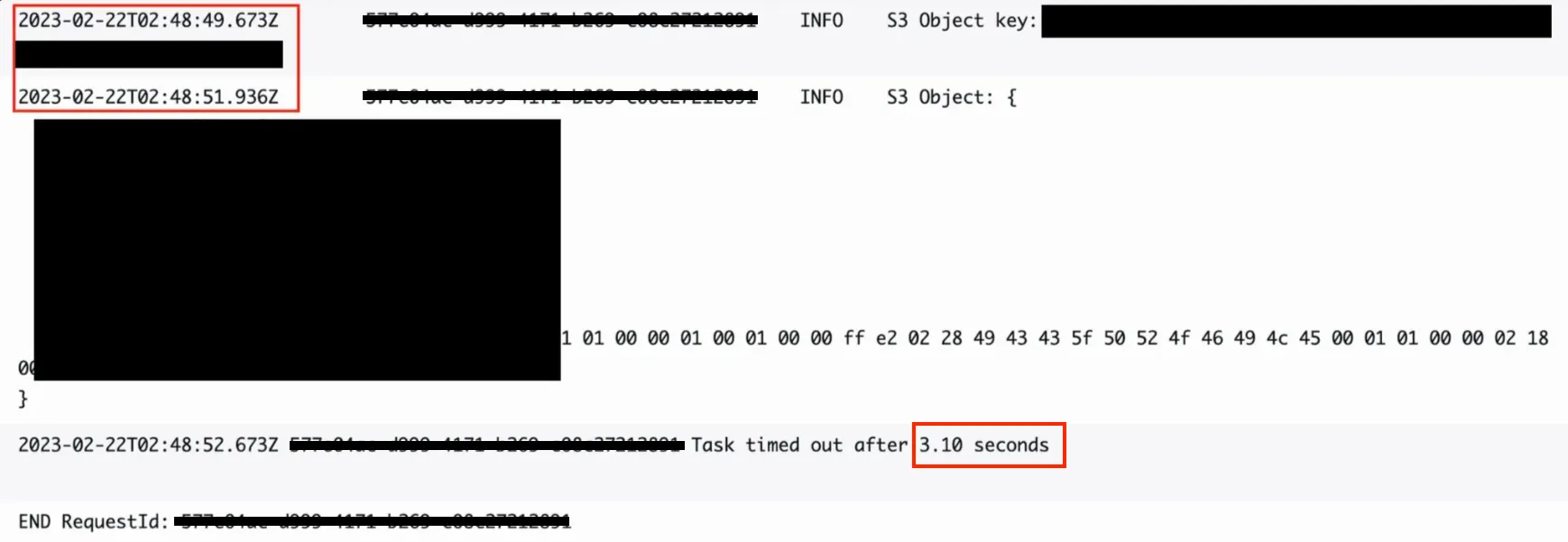
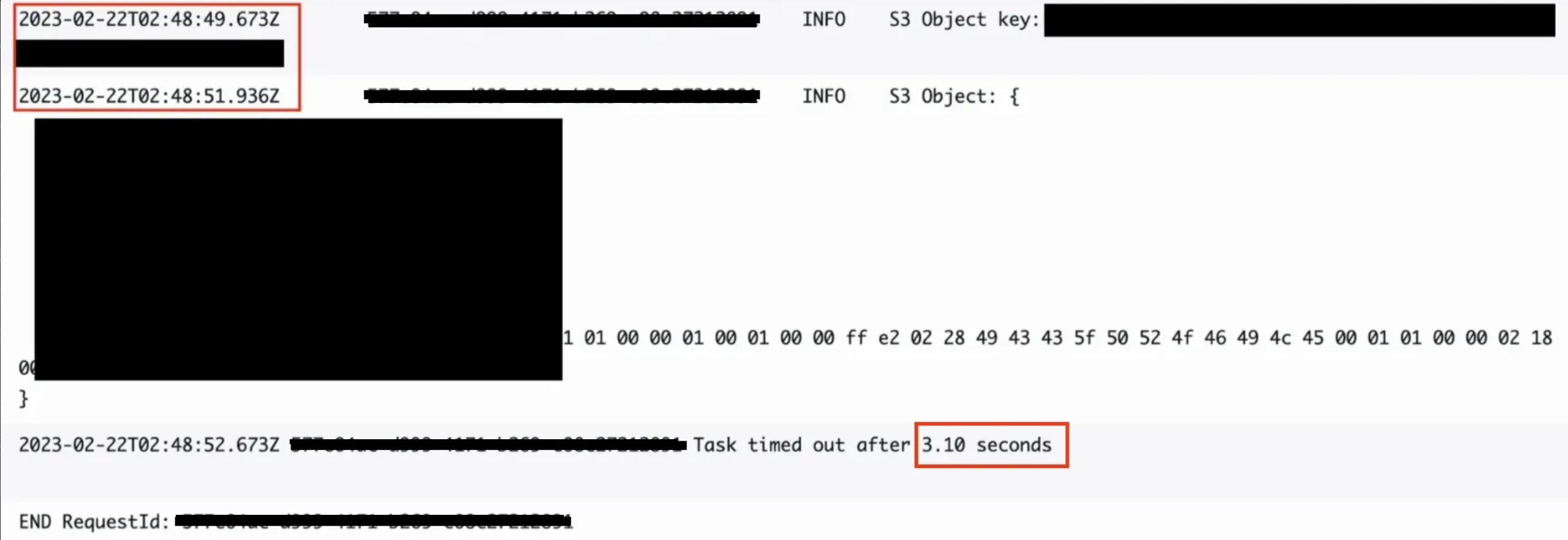
- Lambda@Edge가 us-east-1(버지니아)에 묶여있음 → S3(서울)과 거리 때문에 네트워크 레이턴시 ↑
- 따라 S3(ap-northeast-2)에서 원본 이미지를 가져오는데만 2초 정도 걸리고 그외 나머지 로직까지 다 돌고나면 총 3.1초가 걸려 유저 경험을 악화 시켰다.
2. CDN 캐싱 원리 정리 및 저장소와 비용의 상관관계
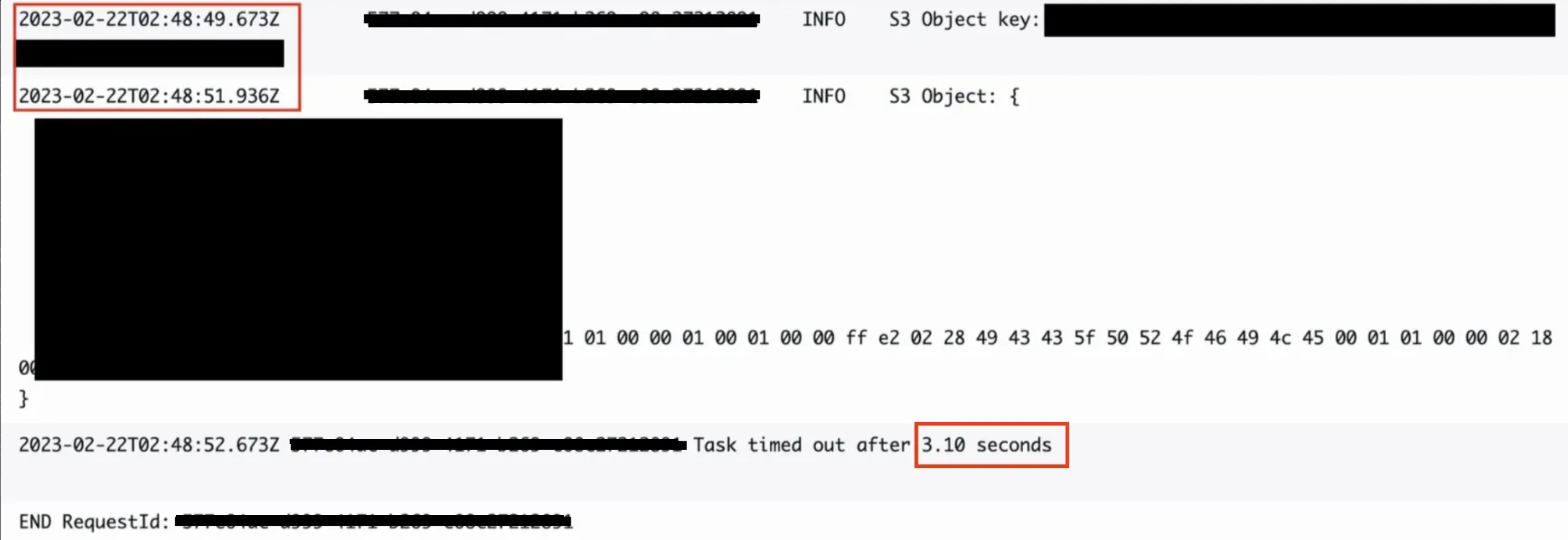
- CDN 캐싱 원리
- 사용자 요청 흐름
- 사용자가 가까운 엣지 서버(CloudFront Edge Location) 에 요청
- 캐시에 있으면 즉시 응답 (Cache Hit ✅)
- 캐시에 없으면 원본(S3 등)에서 가져와 저장 후 응답 (Cache Miss ❌)
- 캐싱 방식
- Push Caching : 운영자가 CDN에 미리 업로드 → 즉시 제공 (앱 설치 파일, 동영상 등)
- Pull Caching : 사용자가 요청할 때 원본에서 가져와 캐싱 (대부분 서비스 기본)
- 원본 업데이트 시 처리 기존 캐싱된 이미지는 어떻게 되는가?
- TTL(Time-To-Live)
- 캐싱 유지 시간.
- Cache-Control: max-age=3600 → 3600초 동안 원본에 재요청 안 함.
- TTL이 끝나면 다음 요청 시 원본에서 다시 가져옴.
- Invalidate (무효화)
- 운영자가 강제로 캐시 삭제 (콘솔·API로 요청)
- 삭제 후 들어오는 요청은 원본에서 가져와 새로 캐싱됨.
- 그렇게 선호되는 방식은 아니라고 함.
- TTL(Time-To-Live)
- 사용자 요청 흐름
- CDN 저장소와 비용의 상관관계
- RAM (In-memory Cache)
- 자주 요청되는 핫 콘텐츠 저장
- 응답 속도 : μs (마이크로초, 초고속)
- 공간 한정 → 밀리면 SSD로 이동
- SSD (Disk Cache)
- 용량 : 수십 ~ 수백 GB
- 응답 속도 : 수 ~ 수십 ms
- 원본 서버로 가는 것보단 훨씬 빠름
- 정책
- LRU (Least Recently Used) : 오래 안 쓰인 객체부터 제거
- TTL이 남아있어도 밀려날 수 있음
- 비용
- CloudFront 과금은 RAM/SSD 구분 없음
- 캐시 히트여도 : 요청 수(Request) + 사용자 전송량(GB)
- 캐시 미스면 : + S3 GET 비용 + S3 → CloudFront 전송 비용
- CloudFront 과금은 RAM/SSD 구분 없음
- 캐시 저장 공간이 더 차는 건 괜찮은가? → 괜찮음.
- RAM/SSD는 CloudFront가 알아서 관리 → 사용자가 비용 직접 지불 X
- 저장소가 꽉 차면 LRU 정책으로 오래 안 쓰인 캐시를 자동 제거
- 과금은 저장소 용량이 아니라 요청 수 + 전송량 기준
- 즉, 캐시 공간이 크든 작든 비용 영향은 없고 오히려 캐시가 많아야 S3 호출 줄어 비용 절감
- RAM (In-memory Cache)
3. 기존 방식의 한계
- CloudFront에 Lambda 붙일 때, Viewer/Origin 이벤트 모두 Lambda@Edge(us-east-1)만 선택 가능 → 리전에 맞춘 Regional Lambda 연결 불가.
- 결국 모든 이미지 처리 Lambda는 미국에서 실행 → 한국 사용자 입장에선 손해.
- 캐시로도 해결 불가
- 최초 요청이 늦으면 이후 응답도 느려짐.
- 큰 이미지일수록 Resize 과정이 오래 걸려 Timeout.
4. 해결 방안 탐색
- Lambda@Edge 그대로 쓰기 + 캐시 정책 업데이트
- 유지보수 단순하지만 초기 성능 개선은 불가능.
- 단, 캐시 정책을 늘리는 것으로 쉽게 처리가 가능함.
- 장점
- 구조 변경 없이 바로 적용 가능 → 유지보수 단순.
- 캐시 TTL만 늘려도 S3 호출 수를 줄일 수 있음. → S3 비용 ↓
- 단점
- Lambda는 us-east-1 고정 → S3(서울)과 거리로 인한 네트워크 지연 해소 불가.
- 큰 이미지 리사이즈 시 여전히 3초 Timeout 발생.
- 근본적인 성능 개선 효과 없음.
- S3 Trigger Lambda (업로드 시 미리 리사이즈)
- 요청 시 즉시 전달 가능하지만 저장소 부담 커짐.
- 특정 할 수 있는게 몇개 있다면 "?w=160&h=160", "?w=1035&h=1035” 해당 몇개만 리사이징을 미리 진행해준다.
- 구조
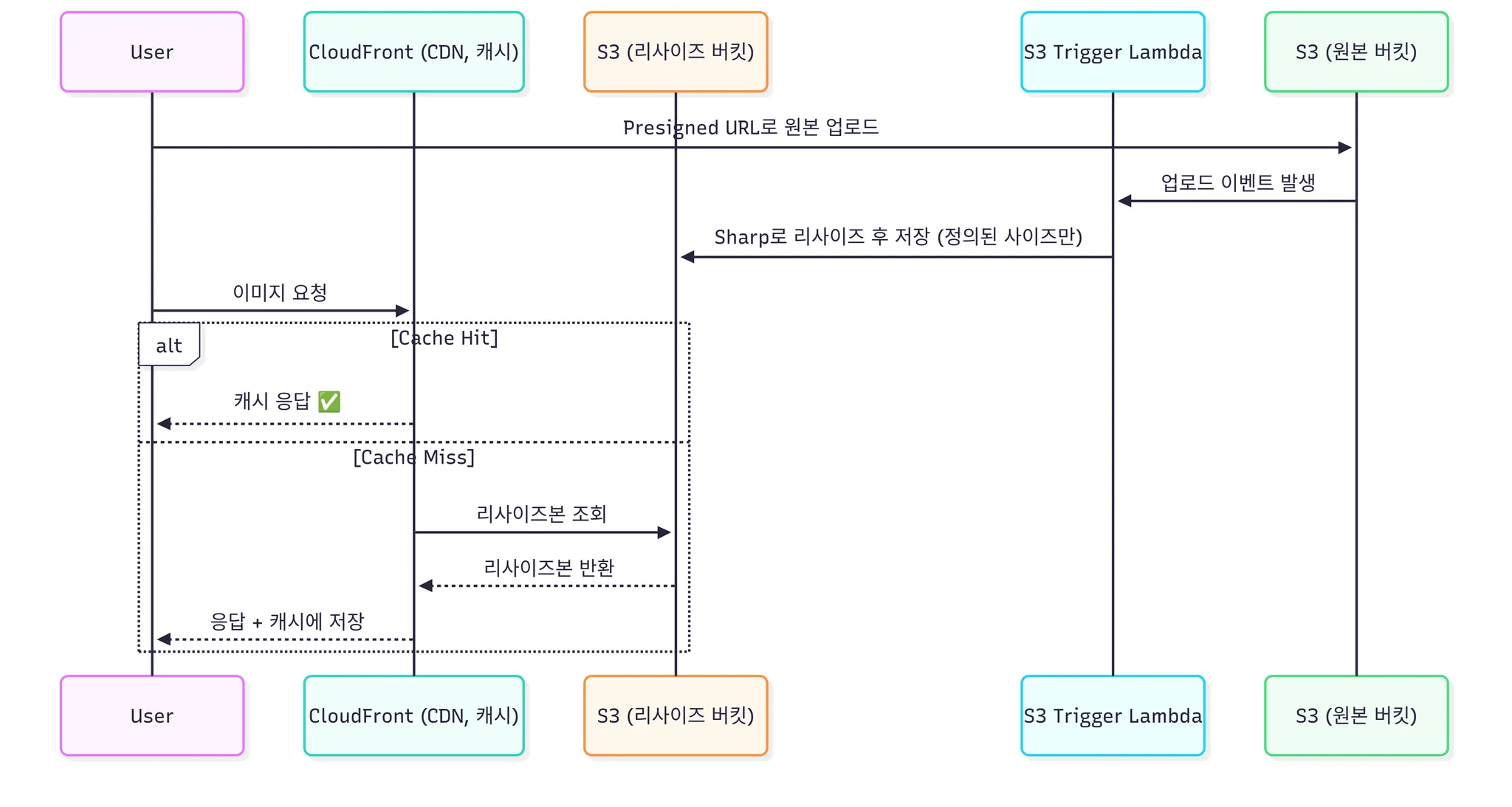
- 장점
- 요청 시 즉시 전달 가능 → Lambda@Edge(us-east-1)를 거치지 않고 서울 리전 S3에서 바로 응답 → 사용자 경험 빠름.
- CloudFront 캐시와 함께 동작 → 반복 요청은 거의 무료 수준.
- 단점
- 여러 사이즈를 미리 만들어두면 스토리지 비용 증가. → 하지만 우리 서비스상 사이즈를 2개만 두는 것으로 확인이 됨.
- 새로운 사이즈가 필요할 때 즉시 대응 불가 → 코드/트리거 수정 필요.
- AWS Serverless Image Handler (SIH)
- AWS 공식 솔루션 (CloudFront + API Gateway + Lambda + S3)
- Regional Lambda 기반이라 원본 S3와 같은 리전에서 실행 → 네트워크 지연 최소화.
- 다양한 파라미터(w,h,f,q) 지원 → 지금 쓰던 Sharp 코드와 기능적으로 동일.
- 캐시 전략도 CloudFront에 그대로 적용 가능.
- 구조
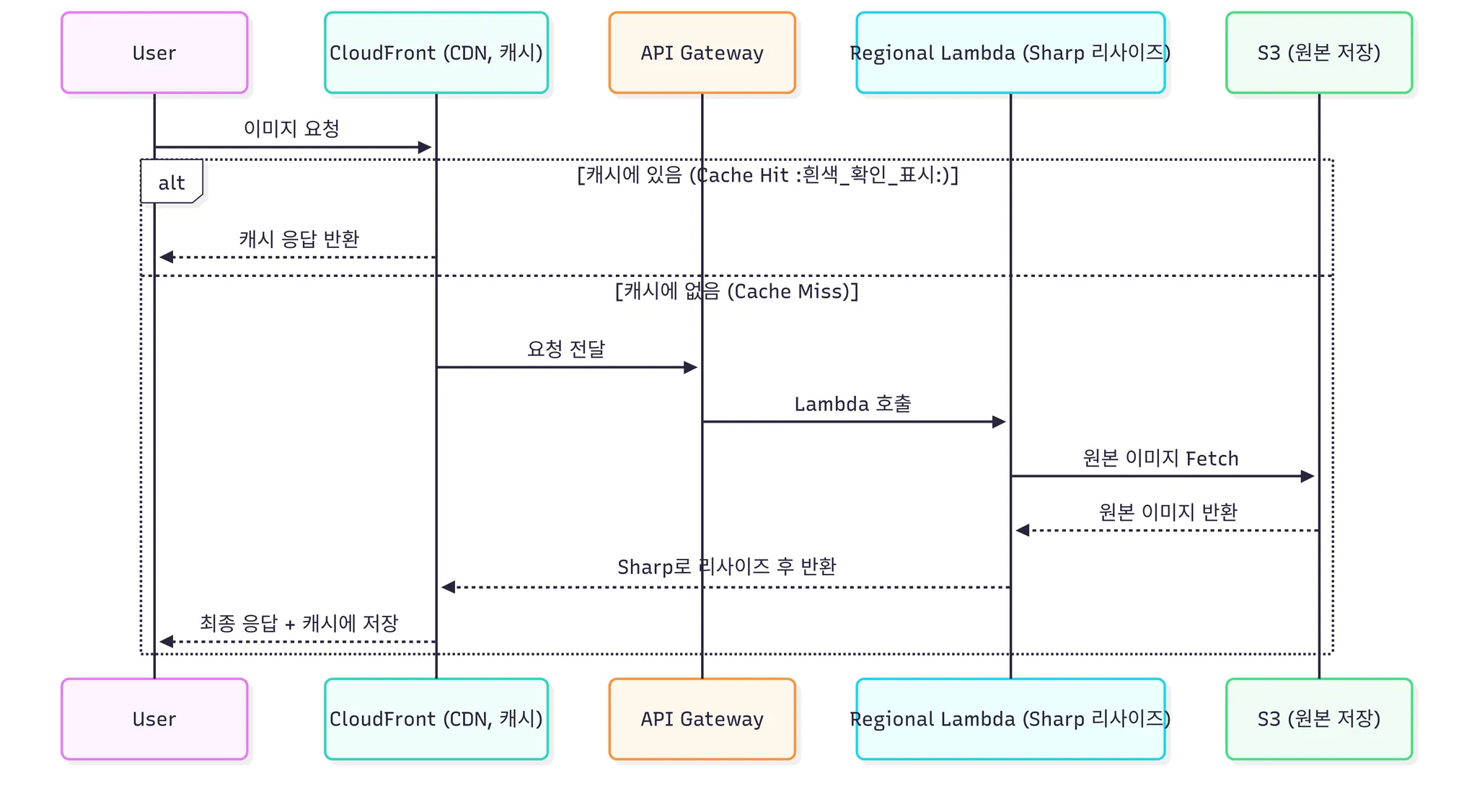
- 장점
- Regional Lambda → S3와 같은 리전에서 실행 → 네트워크 지연 최소화.
- 다양한 파라미터(w,h,f,q) 지원 → FE가 원하는 사이즈를 즉시 생성 가능.
- CloudFront 캐시와 결합 → 반복 요청은 빠르고 저렴.
- 서버 관리 불필요, AWS 공식 지원 → 유지보수 부담 ↓.
- 단점
- 아키텍처 도입/마이그레이션 비용 발생 (CloudFormation, API Gateway, Lambda 설정 필요).
- 최초 요청 시 Lambda 리사이즈 지연은 존재. → 콜드 스타드는 람다에 고질적인 문제로 해결이 거의 불가능. → 한가지 있다면 람다를 항상 웜업 상태로 유지하는 것인데 그건 람다가 지향하는 방식(요청이 있을 때만 실행되는 모델)과는 다르다고 생각함.
5. 2번(S3 Trigger Lambda) + 3번(AWS Serverless Image Handler, SIH)을 함께 선택한 이유
- 업로드 단계에서의 최적화 (S3 Trigger Lambda)
- 사용자가 올리는 이미지가 너무 클 경우 S3 Trigger Lambda가 자동으로 리사이즈해 저장 → 불필요하게 큰 원본 이동/저장 방지.
- 이를 통해 네트워크/스토리지 비용 절감 + 불필요한 대용량 이미지 전송 차단.
- 리전 문제 해결
- 기존 Lambda@Edge는 us-east-1(버지니아)에 묶여있어, S3(서울)과의 거리 때문에 네트워크 지연이 컸음. → 이미지가 늦게 나오는데 주된 이유
- SIH는 Regional Lambda를 사용하기 때문에 S3와 같은 서울 리전에서 동작 → 네트워크 레이턴시 최소화.
- 공식 지원 + 관리 편의성
- 기존에는 Lambda 코드 작성·배포·업데이트와 Sharp 버전 관리까지 직접 맡아야 했음.
- SIH는 AWS 공식 템플릿과 내장 Sharp로 제공되어 유지보수·보안 패치 부담이 크게 줄어듦.
- 즉, 업로드 단계에서 불필요하게 큰 이미지를 줄여두고(2번) + 실제 서비스 단계에서 유연한 사이즈 변환은 SIH로 처리(3번) → 성능, 비용, 유지보수성을 동시에 잡기 위해 2번 + 3번을 함께 선택함.
- 당연하게도 단점이 존재함.
- 구조 복잡성 증가
- 업로드 파이프라인(S3 Trigger Lambda) + 요청 파이프라인(SIH) 둘 다 관리해야 함 → 아키텍처가 복잡해지고 운영 범위가 넓어짐.
- 운영/테스트 부담
- 두 방식이 동시에 동작하기 때문에 장애 추적이나 성능 문제 원인 파악이 어려워질 수 있음 (예: 업로드 트리거 실패 vs SIH 변환 지연)
- 구조 복잡성 증가
6. 그렇게 되면 아키텍처는?
- 다이어그램
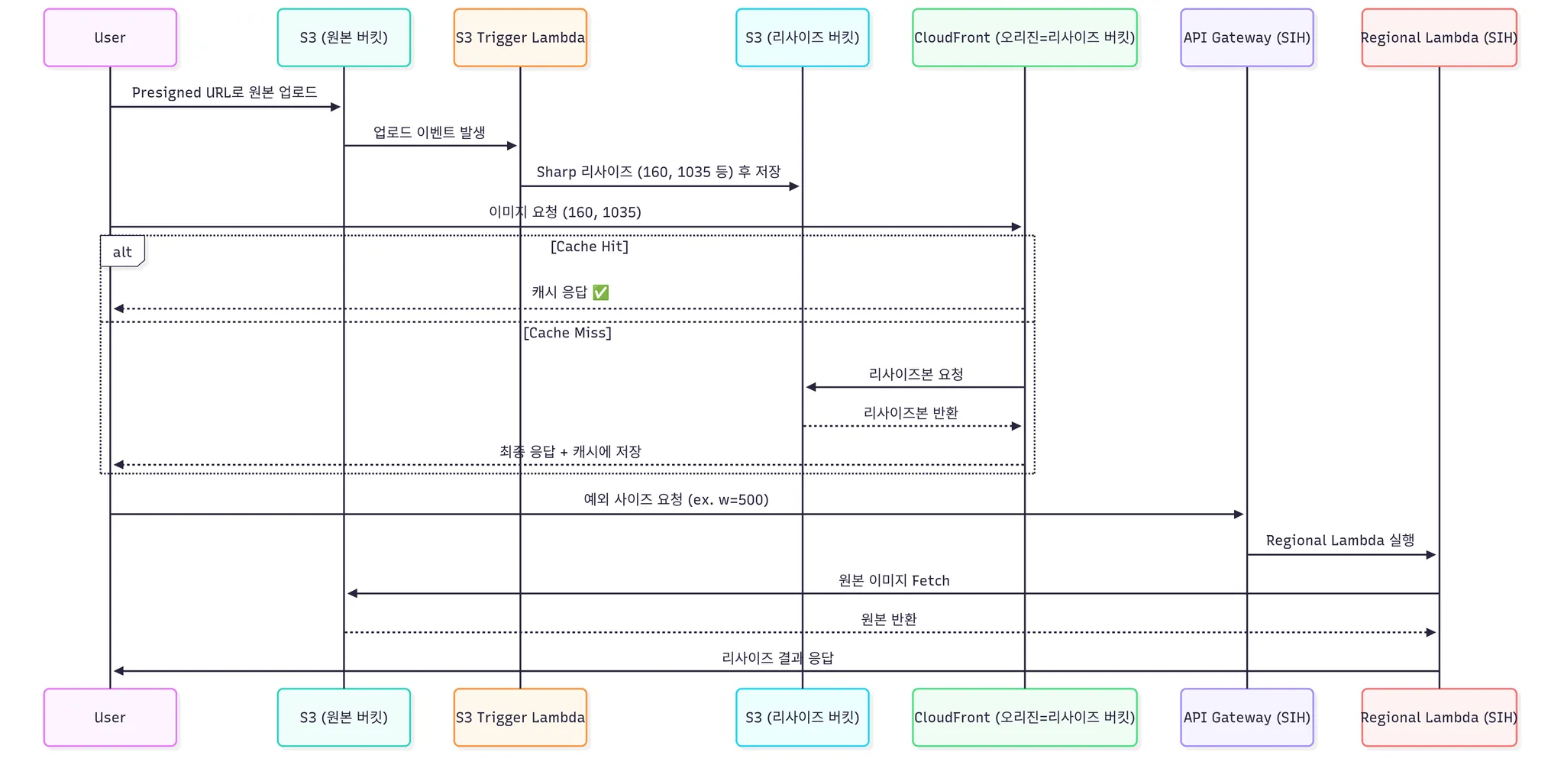
- 위에 다이어그램이 보기가 조금 힘드니 유저 입장에서 플로우 차트를 아래 그렸다.
- 플로우 차트 (리사이징 버킷이 오리진이 됨)
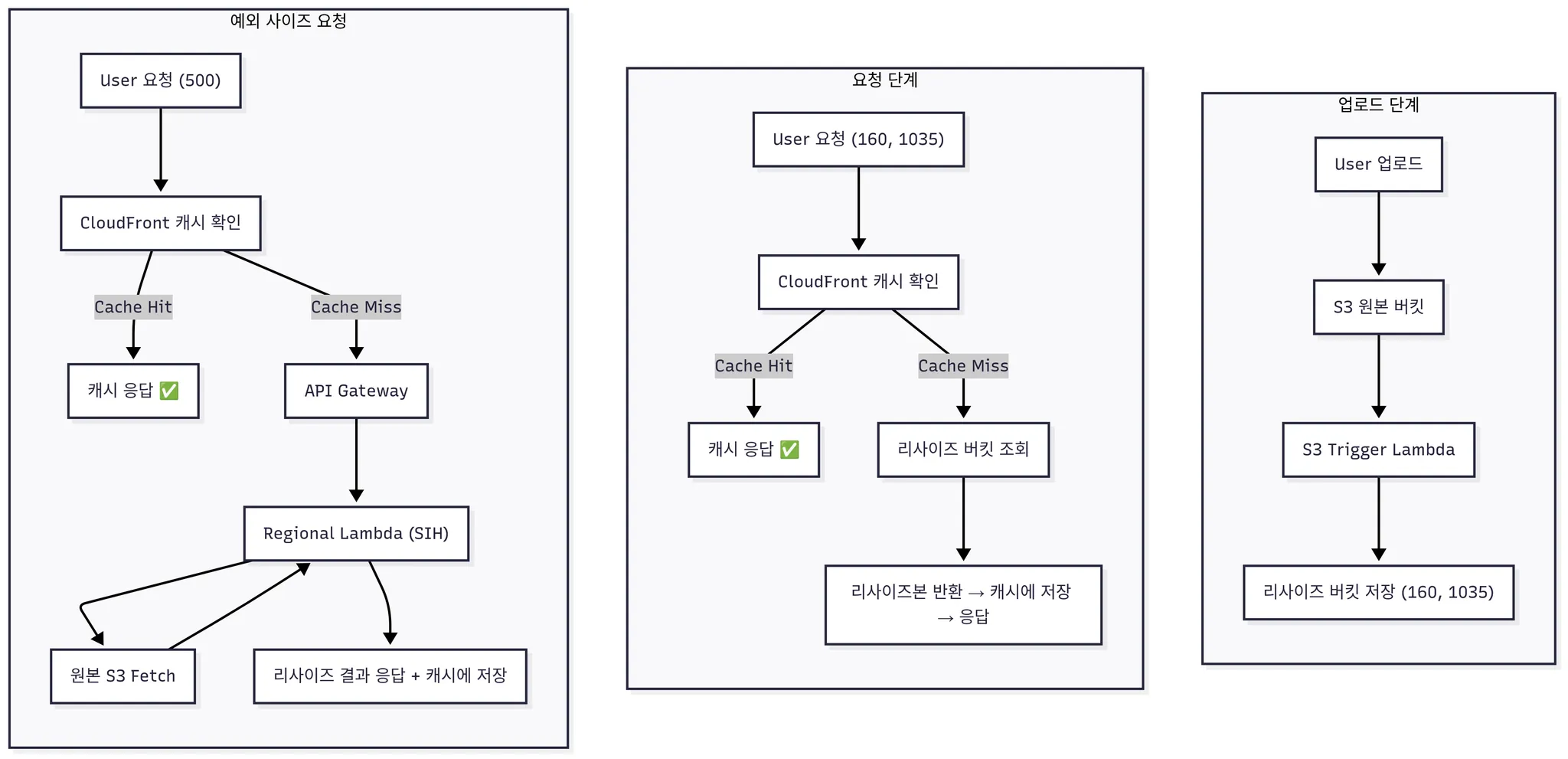
- 우리 앱 서비스 상 예외 사이즈 요청이 거의 없기에 보험으로 SIH를 두었음
- 플로우 차트중에 조금 의아한 부분이 있을 것이다. → User 요청이 들어왔는데 CF에서 어떻게 SIH와 Resizing S3로 나눠줄 수 있는지 의아할 것이다.
- 이걸 어떻게 처리했는지는 아래에서 설명하겠다.
- 백엔드(BE) 할 일
- URL 발급/정책 통제
- 정해진 사이즈(160, 1035 등) → /images/... 형태로 내려줌
- 예외 사이즈(500 등) → /resize/... 형태로 내려줌
- URL 발급/정책 통제
- 프론트(FE) 할 일
- 그냥 BE에서 받은 URL 그대로 사용.
- CloudFront(CF) 할 일
- Path 기반 오리진 분리
- /images/* → 오리진 = Resized S3 버킷
- /resize/* → 오리진 = API Gateway (SIH Lambda)
- 캐시 정책 분리
- /images → 길게 캐싱 (미리 리사이즈 된 것, 변동 적음)
- /resize → 상대적으로 짧게 캐싱 (동적 요청 많음, 자주 바뀔 수 있음)
- 쿼리 파라미터 처리
- SIH는 w,h,f,q 같은 파라미터를 그대로 전달받아야 하므로 → CloudFront 캐시 정책에 쿼리스트링 Forward 켜줘야 함.
- Path 기반 오리진 분리
- 백엔드(BE) 할 일
7. 기존 람다와 변경할 람다의 차이점
| 구분 | 기존 Lambda@Edge | S3 Trigger Lambda | 변경할 SIH Lambda |
|---|---|---|---|
| 실행 위치 | us-east-1 (고정) | 원본 S3와 같은 리전 (예: ap-northeast-2) | 원본 S3와 같은 리전 (예: ap-northeast-2) |
| 트리거 방식 | CloudFront Viewer/Origin 이벤트 | S3 업로드 이벤트 (ObjectCreated) | API Gateway → Lambda (CloudFront 통합) |
| 리사이즈 처리 | 요청 시점에 Sharp 리사이즈 (on-demand) | 업로드 시점에 Sharp로 미리 정의된 사이즈만 리사이즈 (예: 160x160, 1035x1035) | 요청 파라미터(w,h,f,q) 기반 Sharp 리사이즈 (유연) |
| 저장 방식 | 리사이즈본을 S3에 저장하지 않고 CloudFront 캐시에만 유지 → 캐시 만료 시 매번 다시 리사이즈 | 리사이즈본을 S3에 저장 → 이후 요청은 캐시 HIT 또는 S3에서 바로 응답 | 기본은 캐시에만 저장, 필요 시 리사이즈본을 S3에도 저장 가능 → 캐시 만료 후에도 빠른 응답 |
| 유연성 | 코드 수정 필요 (새 옵션 추가 시) | 미리 정의된 사이즈만 가능 (새 사이즈 필요 시 코드 수정) | 파라미터 기반 → 다양한 사이즈/포맷 즉시 지원 |
| 성능 | Cross-region 지연 (us-east-1 ↔ ap-northeast-2) | 업로드 시 미리 처리 → 요청 시 즉시 응답 (빠름) | Regional Lambda 실행 → 네트워크 지연 최소화 |
| 운영/유지보수 | 직접 Lambda 코드 관리 필요 | 사이즈 정의/업데이트 시마다 Lambda 코드 수정 필요 | AWS 공식 관리 솔루션 (CloudFormation, Sharp 포함) |
| 보안 옵션 | 직접 구현 필요 (URL 서명 등) | 직접 구현 필요 | 기본 제공 (Signed URL/Signed Cookie) |
8. 캐시 버스트(Cache Busting) 필요성
- 문제 상황
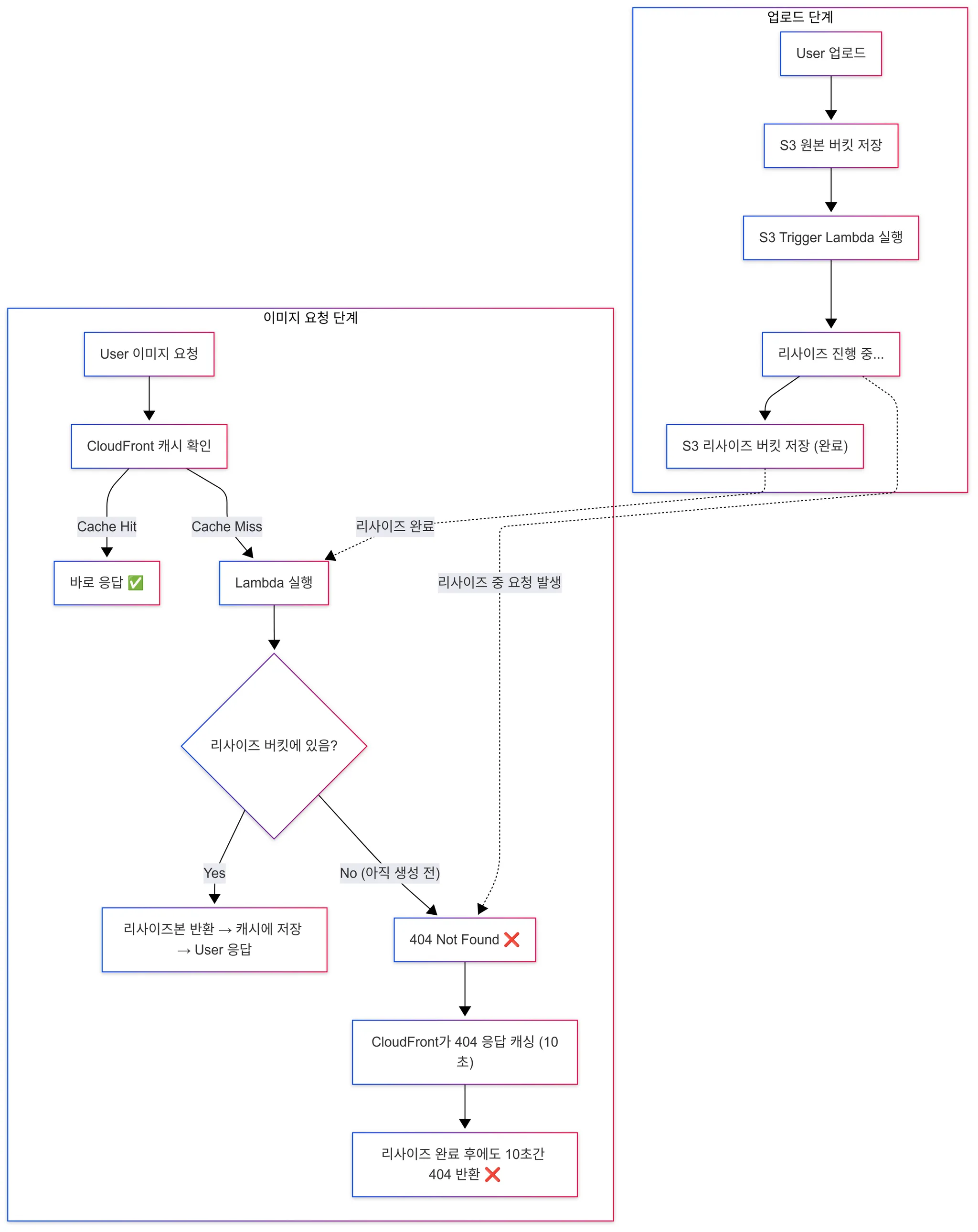
- 업로드 시 S3 Trigger Lambda 또는 SIH가 이미지를 리사이즈하고 저장하는 과정은 수백 ms~수 초까지 걸릴 수 있음.
- 만약 유저가 리사이즈본이 아직 생성되기 전에 요청하면 404 Not Found가 떨어짐.
- FE에서는 이를 대비해 폴링(1초마다 재요청) 을 시도할 수 있음.
- 하지만 CloudFront는 이 404 응답도 캐싱함 → 정책상 기본 최소 TTL이 10초.
- 따라서 실제로 리사이즈본이 생성되더라도, 10초 동안은 계속 404를 돌려주게 됨 → UX 악화.
- 해결 방법 (Cache Busting)
- 동일한 URL로 계속 요청하지 않고, 쿼리 파라미터를 살짝 다르게 붙여서 요청 → CloudFront 캐시를 우회.
- 예: ?w=160&h=160 → ?w=160&h=160&ts=1, ?ts=2
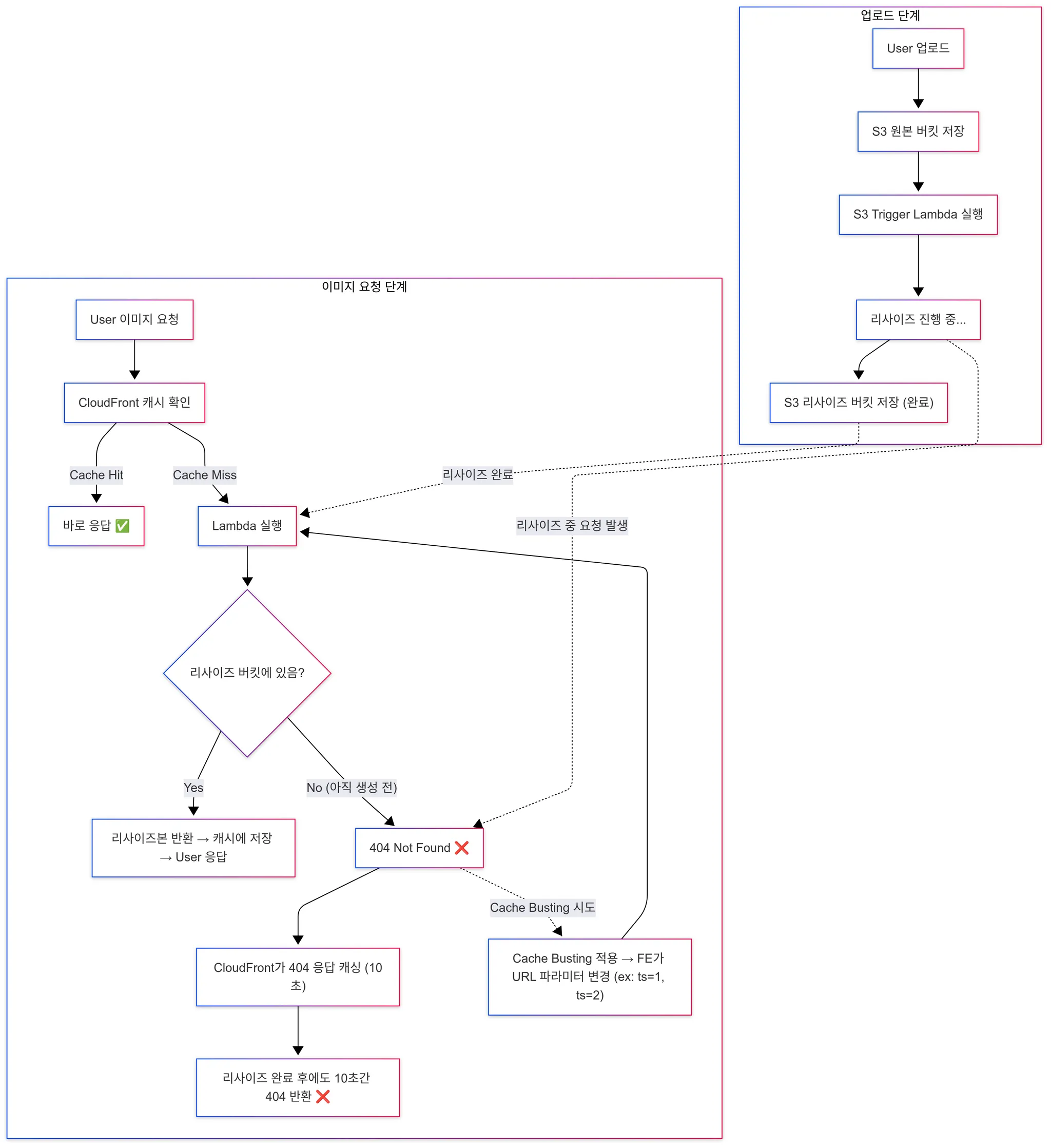
- 정리
- Cache Busting을 쓰면 404 캐시가 걸려 있는 동안에도 새로운 요청을 강제로 우회해서, 이미지가 준비되는 즉시 받아올 수 있음.
- 즉, 리사이즈 직후~캐시 반영 사이의 공백 문제를 해결하기 위한 테크닉.
9. 결론
- 이번 과정을 통해 단순히 “이미지 보여주기”가 아니라 이미지가 어떤 구조로 돌아가고 리사이징, 최적화가 어디서 이뤄지며 CDN 캐시 정책과 버스팅이 어떻게 UX에 영향을 주는지를 알 수 있었다.
- 즉, 이미지 처리라는 게 단순 기술이 아니라 서비스 성능, 비용, 운영성 전반에 영향을 주는 중요한 인프라 설계 포인트라는 걸 배웠다.
- 이번엔 이미지 최적화 여정을 통해 백엔드 → 프론트 → CDN 전체가 맞물려야 진짜 빠른 서비스가 된다는 걸 알게 됐다.

지나가는 개발자