쓰게 된 계기
- 회사에서 사내 발표를 진행하였는데, 추가적으로 MSA를 도입하려는, MSA가 궁금한 사람들을 위해 PPT 발표 자료를 정리해서 올렸다.
Monolithic Architecture란?
- MSA가 파생되기 전에는 주로 사용하던 아키텍처는 Monolithic(모놀로식) Architecture 입니다.
- Monolithic Architecture는 모든 애플리케이션의 컴포넌트들이 하나의 단일 패키지로 통합되어 있는 구조를 의미합니다.
- 이러한 구조에서는 화면, 데이터베이스, 비즈니스 로직 등 모든 컴포넌트가 같은 시스템에 위치하고, 이들 간의 커뮤니케이션은 프로세스 내부에서 이뤄집니다.
Monolithic Architecture의 장단점
- 장점
- 개발, 테스트, 배포가 비교적 간단하며, 이해하기 쉽습니다.
- 어떤 서비스든지 개발되어있는 환경이 같아서 복잡하지 않습니다.
- 단점
- 코드베이스가 커지면 유지 보수가 어려워집니다.
- 유지보수할 때 문제가 생긴 곳을 고치면, 다른데도 같이 고장나는 경험이 있지 않은가요?
- 신규인원 투입시 전체 서비스를 이해하는데 시간이 오래걸립니다.

- 저희도 처음 들어왔을 땐 사진과 같은 경험을 한번씩은 해본적이 있죠?
- 서비스의 확장이 어렵다. 특정 부분만 확장하려 해도 전체 애플리케이션을 확장해야 합니다.
- 하나의 서비스에 대한 장애가 전체 서비스에 장애로 퍼질 가능성이 높습니다.
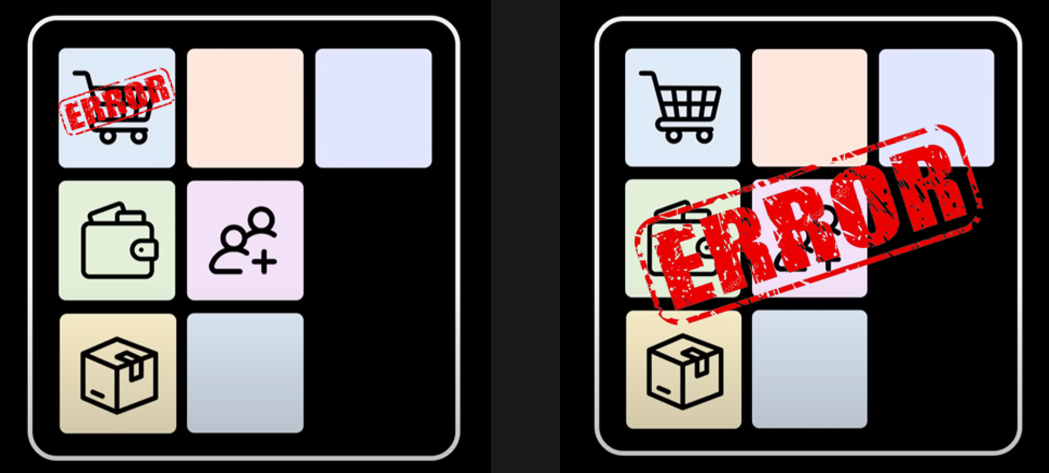
- 왼쪽 사진 처럼 하나의 서비스에 장애가 발생하면 오른쪽 사진 처럼 전체로 퍼질 가능성이 큽니다.
- 코드베이스가 커지면 유지 보수가 어려워집니다.
MSA란?
- MA의 단점으로 극복하기 위해 MSA가 탄생되었는데 여기서 MSA란? 풀어서 MicroService Architecture 입니다.
- 해석하면 각각을 마이크로하게 나눈 독립적인 서비스를 연결한 구조를 말합니다.
- MA 단점들을 극복하고 더 빠르게 더 큰 규모로 확장하기 위해 MSA가 탄생했습니다.
MSA의 장단점
- MSA 장점
- 서비스별 개별 배포가 가능하여 배포 시간이 단축됩니다.
- 배포 사진(모노 레포 상태 입니다.)
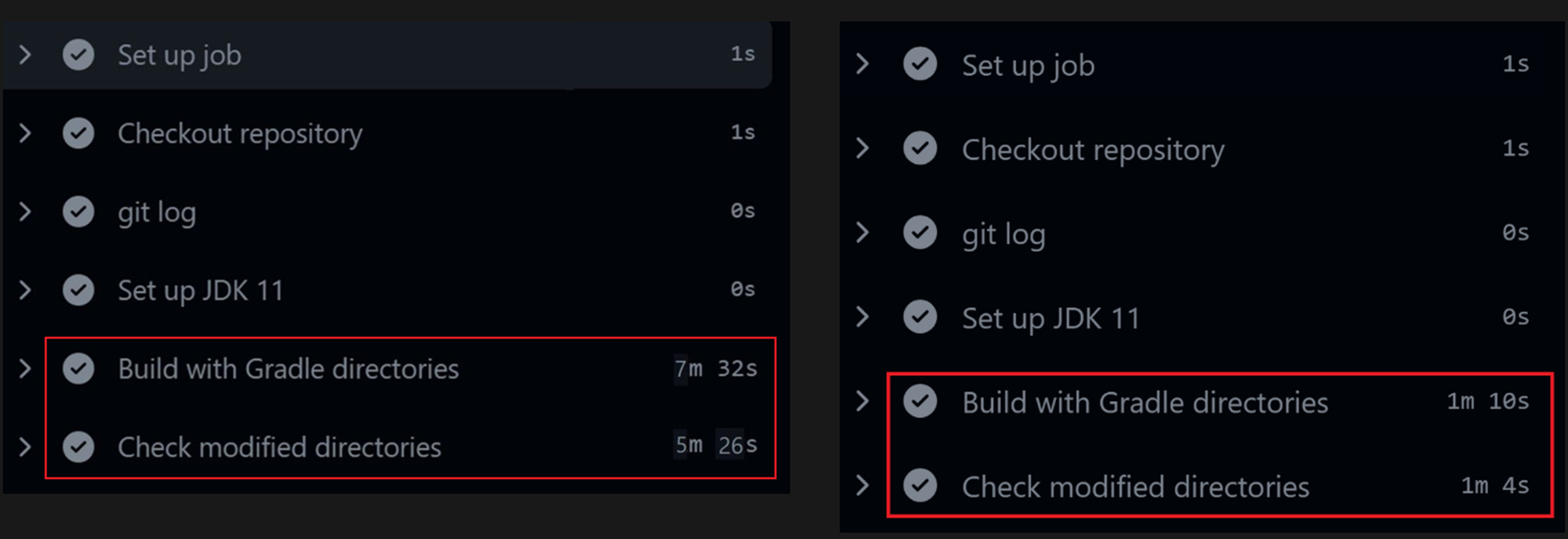
- 사진을 보면 알 수 있듯이 왼쪽은 모놀로식으로 배포한 시간이고 오른쪽은 MSA로 배포한 시간입니다.
- 빌드 및 배포 시간에 차이가 유의미하게 나타나는걸 볼 수 있다.
- 배포 사진(모노 레포 상태 입니다.)
- 특정 서비스에 대한 확장성(scale-out)이 유리합니다.
- 일부 장애가 전체 서비스로 확장될 가능성이 적습니다.
- MSA 단점
- 설계가 어렵습니다.
- MSA는 모놀리식와 다르게 서비스가 모두 분산되어 있기 때문에 상대적으로 많이 복잡하다.
- 트랜잭션 및 데이터 관리가 어렵습니다.
- 서비스가 분리 되어 여러 DB를 사용한다면 데이터 관리가 어렵고 DB 컬럼에 Join이 어려워집니다.
- MSA에도 단점이 있어도 경험해보는게 좋은 이유는 무엇일까요?
- 앞서 얘기한 모놀리식 아키텍처 단점에서 얘기한 유지보수, 확장성 등은 오랜기간 지속되면 기술 부채로 이어질 가능성이 큽니다. 따라서 기술부채를 줄이는 데 도움을 줄 수 있고
- '유연성'과 '확장성'을 통해 빠르게 변화하는 비즈니스 요구사항에 더 잘 대응할 수 있게 되기 때문입니다.
MSA 도입시 고려할 사항
- 실제로 MSA를 도입한다면 고려사항 어떤것이 있을까요?
- MA → MSA로 전환하는 방법에는 여러가지 기술스택이 필요합니다.
- 크게 생각해봐야할 것이 3가지가 있을 것 같습니다. 3가지는 아래와 같습니다.
- 서비스 분리
- 전체 어플리케이션을 분리하려면 어떤 서비스가 독립적인 서비스가 될 수 있을지 생각해봐야합니다.
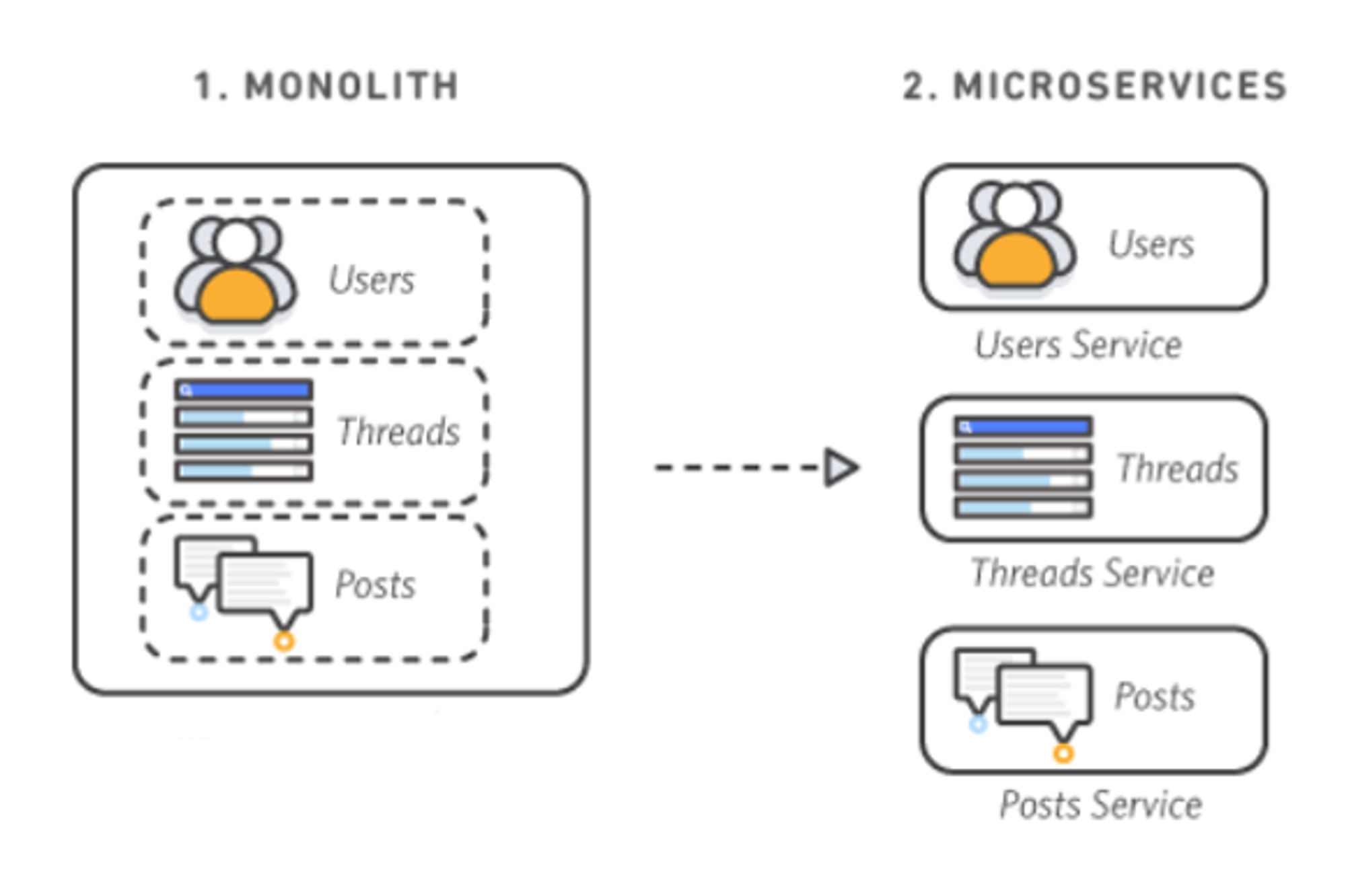
- 그림을 보고 알수있듯이 MA는 큰 덩어리 하나이고 MSA는 그 큰 덩어리를 세분화 해서 나눈걸 볼 수 있습니다.
- MSA에서 지향하는 방식은 분리된 서비스들은 각 서비스가 단일 책임을 가져야하므로 각각의 마이크로서비스는 서로 느슨한 결합이 되어야합니다.
- 느슨한 결합을 주도하기 위해 MA에서는 계층형 아키텍처를 사용했다면 MSA에서는 DDD 도메인 주도 개발, Clean Arch(클린 아키텍처)를 지향합니다.
- 전체 어플리케이션을 분리하려면 어떤 서비스가 독립적인 서비스가 될 수 있을지 생각해봐야합니다.
- 두번째로는 서비스 간 통신
- 이렇게 서비스를 나눈다면 독립성은 서비스 간의 통신을 복잡하게 만들 수 있습니다. 서비스 간에 데이터를 공유하거나 상호 작용해야 하는 경우, 이를 어떻게 해결 할 수 있을까요?
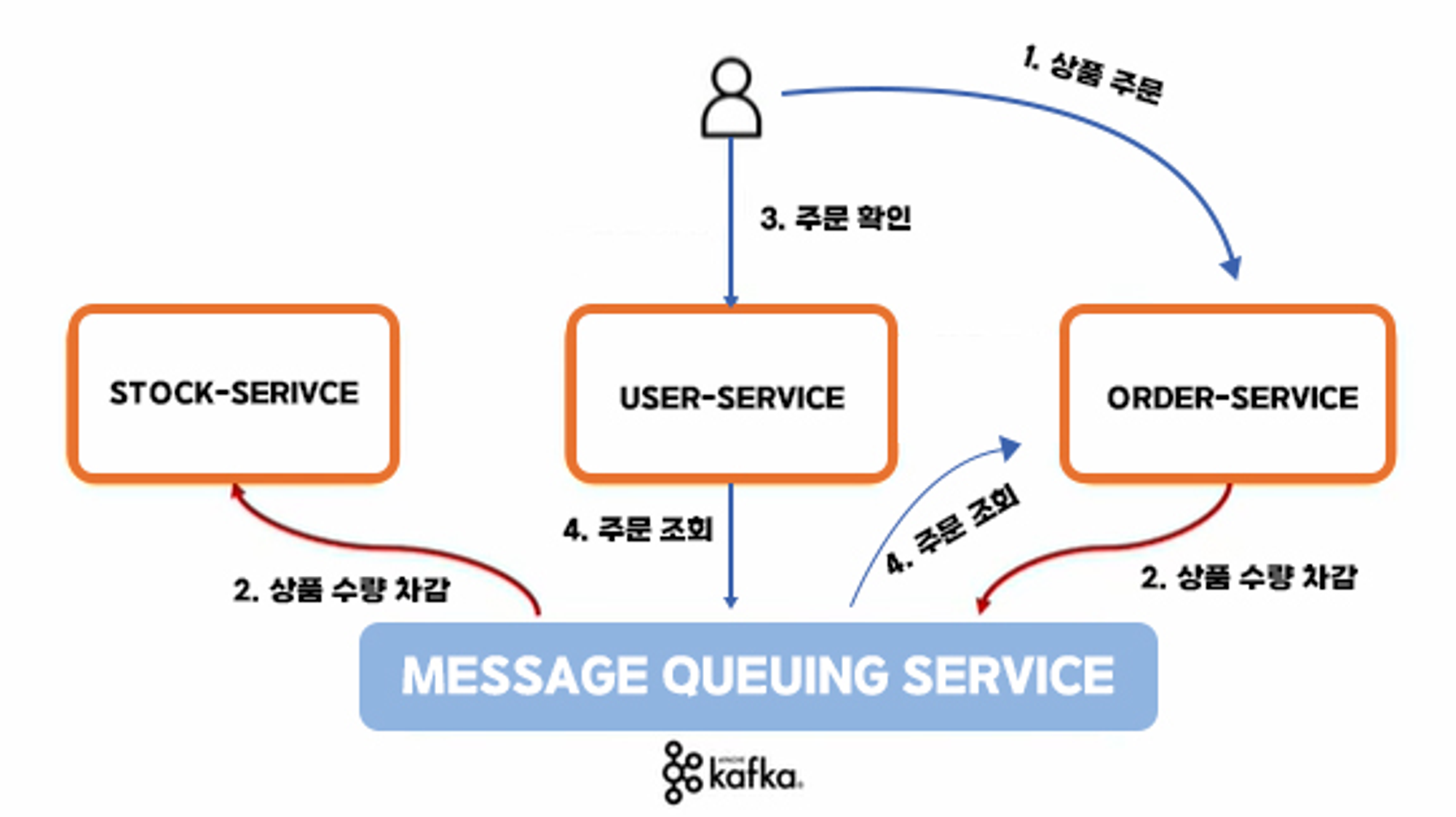
- 예를들어, 사진처럼 주문 서비스와 재고 서비스가 있다고 가정을 한다면 주문 서비스에서 주문을 처리 했을 경우 재고 서비스에서 주문한 상품의 재고를 차감시켜야 됩니다.
- 해당 경우에서 주문 서비스만으로 다 처리가 불가능 하므로 서비스간 통신을 위한 무언가가 필요합니다.
- 예를들어, 사진처럼 주문 서비스와 재고 서비스가 있다고 가정을 한다면 주문 서비스에서 주문을 처리 했을 경우 재고 서비스에서 주문한 상품의 재고를 차감시켜야 됩니다.
- 이런 부분을 해소해 주기 위해 몇가지 방법이 있습니다.
- Neflix에서 만든 라이브러리인 FeignClient가 있고
- Message queue 기반인 카프카 존재합니다.
- 이렇게 서비스를 나눈다면 독립성은 서비스 간의 통신을 복잡하게 만들 수 있습니다. 서비스 간에 데이터를 공유하거나 상호 작용해야 하는 경우, 이를 어떻게 해결 할 수 있을까요?
- 세번째로는 트랙잭션 관리
- MAS에서 Error가 발생했다면?
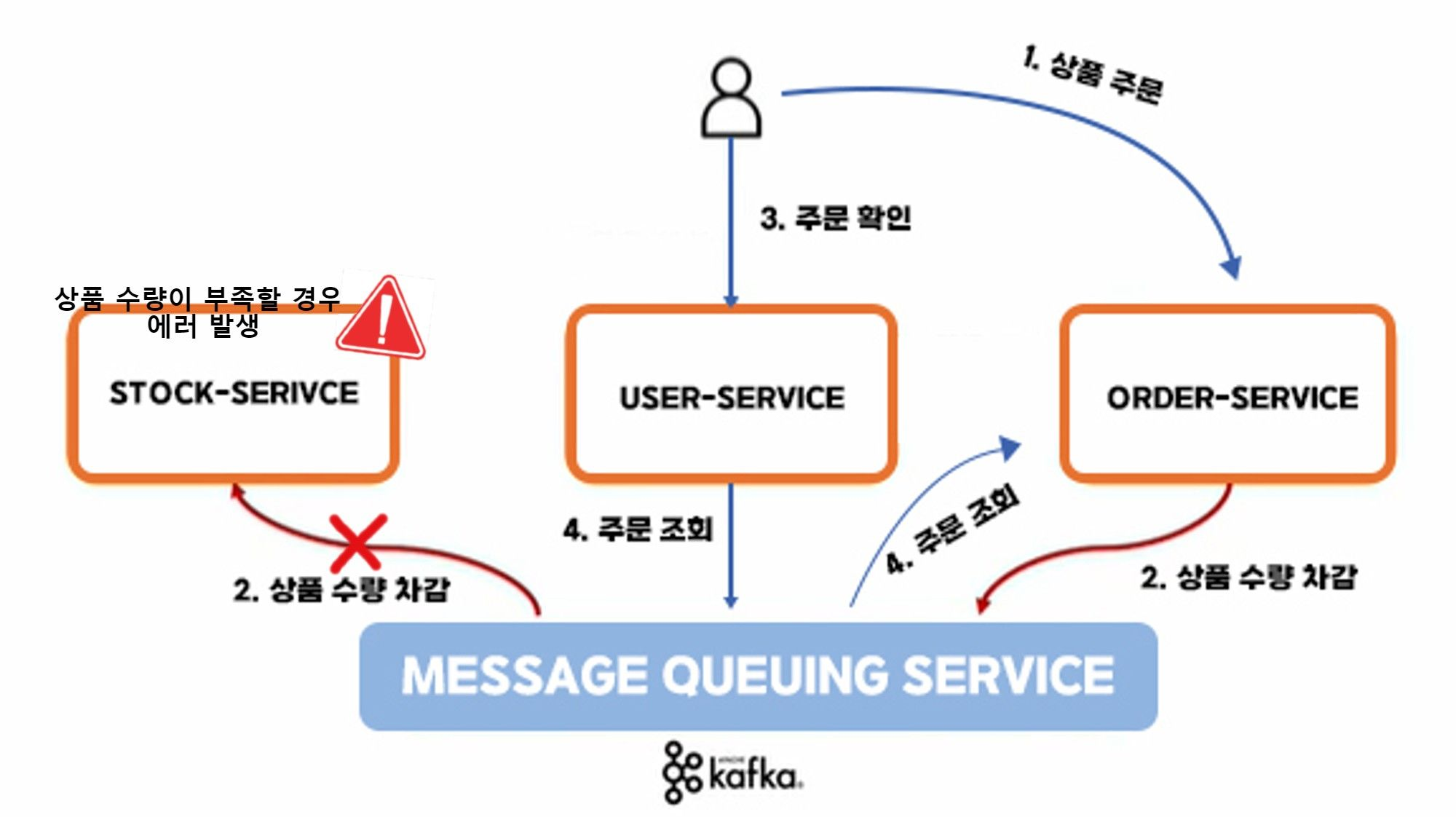
- 모놀리식 아키텍처에서는 한 개의 데이터베이스가 모든 비즈니스 로직을 처리합니다. 이런 구조에서 ACID 트랜잭션(원자성, 일관성, 고립성, 지속성을 갖는 트랜잭션)이 자연스럽게 지원됩니다.
- 하지만 마이크로서비스에서는 각 서비스가 자체 데이터베이스를 가질 수 있어 분산 트랜잭션을 처리하는 것이 어렵습니다.
- 사진처럼 주문 서비스는 잘 처리가 되었는데 재고 서비스에서 주문한 상품의 재고가 부족할 경우는 어떻게 처리해야할까요?
- 이런점을 보안하기 위해 MSA에서 분산 트랙잭션을 관리하기 위한 사가 패턴이 존재하고 있습니다.
- MAS에서 Error가 발생했다면?
1. 서비스 분리
- 앞서 얘기한 도입 시 고려야할 사항중에 첫번째인 DDD, 클린아키텍처에 설명하겠습니다.
- Clean Architecture는 계층형 아키텍처의 단점을 보안하고 MSA가 지향하는 독립적인 서비스의 확장성과 유연성을 위해 탄생한 아키텍처입니다.
- 여기서 계층형 아키텍처는 단점을 보안한다고 얘기했는데요 계층형 아키텍처는 다들 익히 알고있는 MVC 패턴이고 단점을 간단하게 집고 넘어가겠습니다.
- 데이터 베이스 주도 개발을 유도합니다.
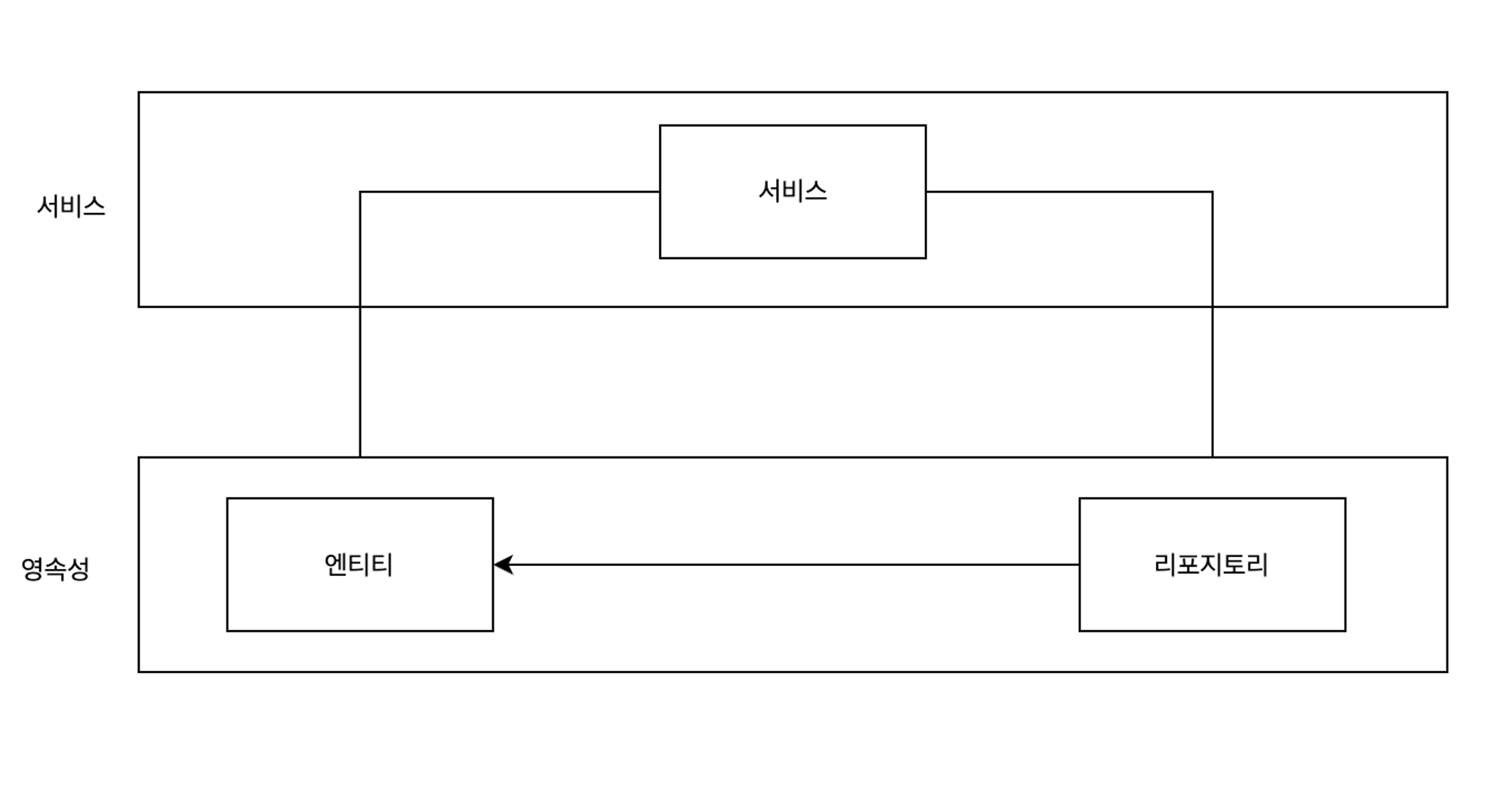
- 우리는 위와같이 계층형 아키텍처를 구현하지 않는가요?
- 이렇게 구현을 하였다면 영속성 서비스에 강한 결합이 생깁니다.
- 강한 결합이 생기면 안 좋은 점은 한 계층에서 변경이 발생하면 다른 계층에도 영향을 미쳐 코드 수정이 불가피해집니다.
- 실무적으로 동시에 작업하기가 어렵습니다.
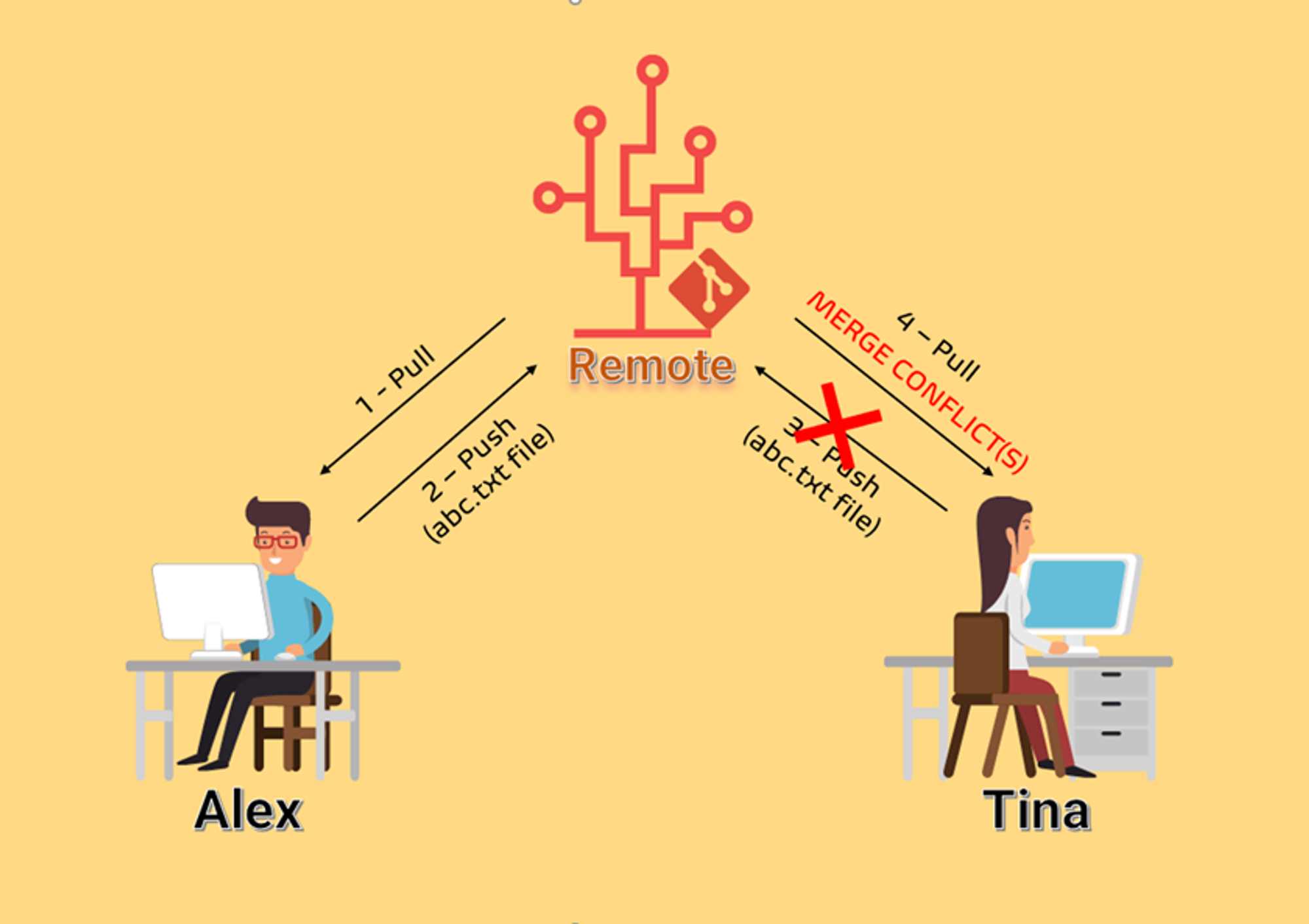
- 다들 그림과 같은 경험이 많이 있지 않나요?
- 내가 수정한 영역과 다른사람이 수정한 영역이 동일해서 해당 파일에 충돌하여 push, merge가 불가능한 경험 다들 한번 쯤은 있으시죠?
- 계층형 아키텍처는 controller, service, repository로 크게 분류해서 작업하는데 하나의 기능 개발을 할 때 2명 이상이 들어가서 작업하는 것이 많이 힘듭니다.
- 다들 그림과 같은 경험이 많이 있지 않나요?
- 데이터 베이스 주도 개발을 유도합니다.
Clean Architecture란?
- Clean Architecture 구조
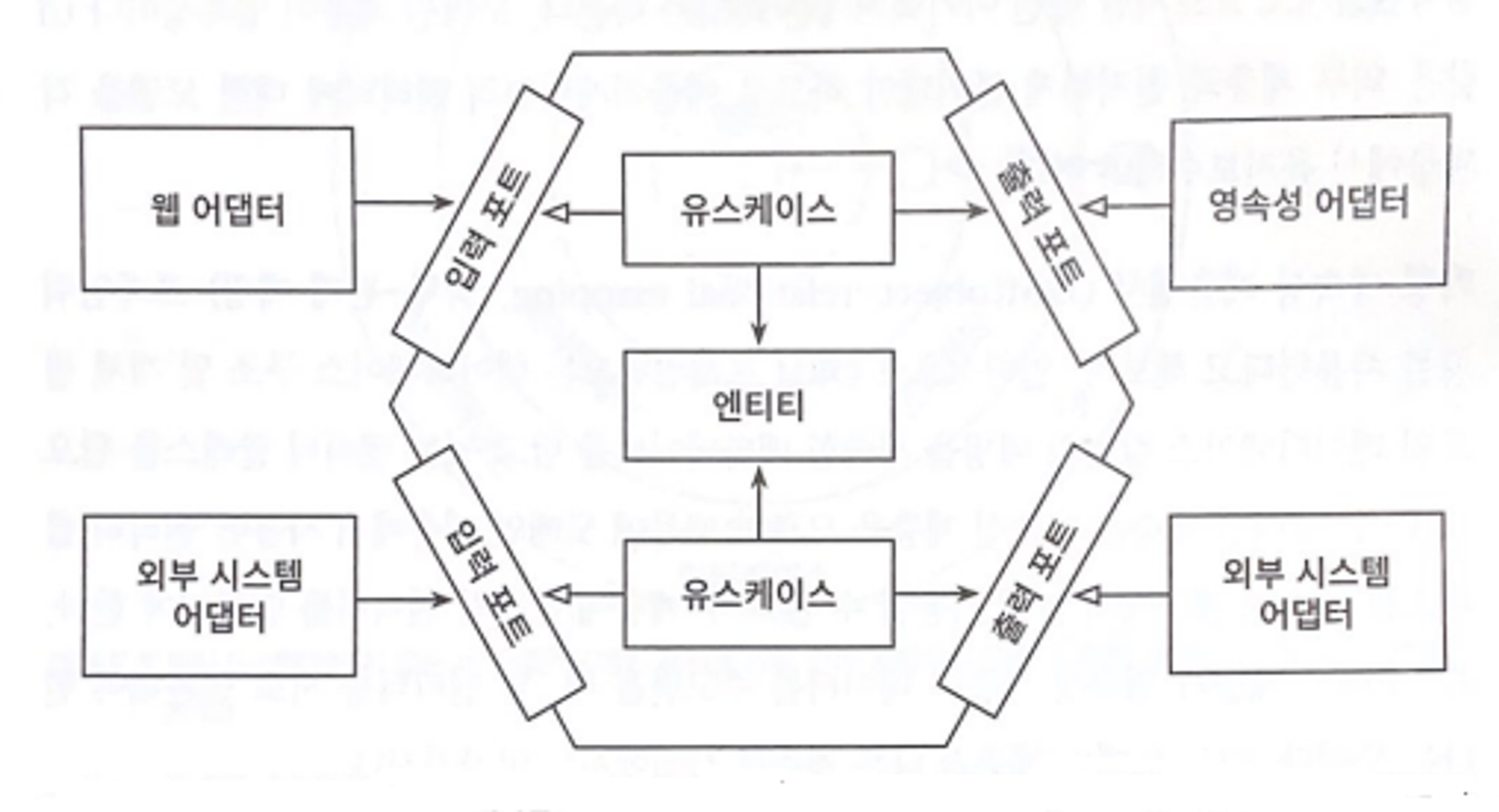
- 그림을 보듯 알수있듯이 화살표가 입력, 출력포트를 기준으로 디펜젼시 인젝션 의존성 역전을 지원하고 있습니다.
- 라이트한 버전이라 디테일한 Clean Arch에 대해 설명하지 않겠습니다.
- 찾아보니 클린 아키텍처는 언어와 프레임워크에 종속적이지 않더라고요.
- 파이썬에 django, fastapi
- 자바와 코틀린에 Spring
- 등에서 사용이 가능합니다.
Clean Architecture 장점, 단점
- 장점
- 유연성과 확장성에 용이합니다.
- 여러명이 동시에 작업하기 좋습니다.
- 기능별로 뚜렷하게 분리된 구조를 가지고 있기에 여러 개발자가 동시에 작업하기 좋습니다.
- 테스트코드 작성이 용이합니다.
- 이것도 마찬가지로 기능별로 뚜렷하게 구분된 구조를 가지 있기에 모킹을 사용하여 유닛 테스트를 쉽게 수행할 수 있습니다.
- 단점
- 학습 곡선 가파릅니다.
- 오버 엔지니어링이 있습니다.
- 작은 프로젝트나 단순한 애플리케이션에 Clean Architecture를 적용하면, 과도한 설계와 복잡성을 초래할 수 있습니다.
2. 서비스 간 통신
- 앞서 얘기한 도입 시 고려야할 사항중에 두번째인 각각의 마이크로서비스들의 통신에 대해 설명하겠습니다.
- 마이크로서비스의 통신은 크게 3가지가 있는데 1가지만 얘기하겠습니다.
- Message queue (Kafka, RabbitMQ)
- Message queue는 인스턴스가 데이터를 서로 교환할 때 사용하는 통신 방법입니다.
- MQ 동작 원리를 간단하게 설명하겠습니다.

- 그림을 보면 알수 있듯이 3가지가 있습니다.
- producer(프로듀서) : 정보를 제공하는 역할로, 메시지를 생성하고 특정 토픽과 같이 큐에게 보냅니다.
- consumer(컨슘) : 정보를 제공받는 역할로, 특정 토픽을 구독하고 해당 토픽에 대한 메시지를 받아와서 비즈니스 로직을 처리합니다.
- Queue(큐) : producer의 메세지를 임시 저장 및 consumer에 제공하는 곳입니다.
MQ의 장점, 단점
- 장점
- 비동기를 지원하며 서비스간 낮은 결합도를 지원합니다.
- 프로듀서, 컨슘은 서비스를 원하는대로 확장할 수 있어 확장성에 용이합니다.
- 단점
- 시스템의 복잡성을 증가시킬 수 있습니다. 메시지 전송, 수신, 라우팅, 에러 처리(트랙잭션)등과 같은 추가적인 로직과 관련된 기능들을 구현해야 합니다.
3. Transaction 관리
- 모놀로식에서 Transaction 관리
- 비즈니스 로직에 트랙잭션(데이터베이스에 상태 변화)이 필요한 작업을 수행한다. → 트랙잭션 시작
- 트랜잭션 안에서 여러개의 쿼리나 명령이 실행되며, 중간에 어떤한 오류도 발생하지 않아야한다.
- 모든 연산이 성공적으로 완료되면 트랜잭션은 커밋 상태가 된다.
- 커밋은 트랙잭션 내의 모든 변경사항이 데이터베이스에 영구적으로 저장되는 것을 의미한다.
- 만약 트랜잭션 중간에 오류가 발생하거나 어떤 이유로 트랙잭션을 취소해야하는 경우 롤백이 발생한다.
- 롤백은 트랙잭션 내에서 일어난 모든 변경사항을 취소하고, 데이터 베이스를 트랙잭션 시작 전으로 돌리는 과정이다.
- 이러한 모든 Flow가 1PC(1-Phase Commit)이라고 한다.
- 모놀로식 아키텍처에서는 데이터베이스 연결과 트랙잭션 관리가 일반적으로 단일 서비스 내에서 이루어지기 때문에 ACID 속성을 유지하는 것이 비교적 간단하다.
MSA에서 Transaction 필요한 이유
- MSA에서는 여러 서비스가 존재하는데 각 서비스별로 각각의 고유의 DB를 가지고 있다.
- MSA가 지향하는 점으로 각 서비스엔 각각의 DB를 가지는걸 지향한다.
- 두개 이상의 서비스에서 DB 상태 변화가 일어날 때 하나 이상의 서비스에서 오류가 발생한다면 두 서비스 모두 롤백을 해줘야하는데 서비스가 다르기에 자체적으로 ACID를 지원하지 않는다.
- 따라서 이런 부분을 해소해주기위해 MSA에서 새로운 Transaction 방식을 채택해야한다.
MSA에서 Transaction 관리
- 이번 내용은 서론이 조금 길었는데 앞에 내용을 이해해야지 MSA에서 Transaction 관리를 어떻게 하는지 파악하기가 더 쉽다!
- 그리고 진짜로 MSA에 여러 경험이 있는건 아니지만 Transaction 관리하는게 제일 어려웠던 것 같다…
- 다시 돌아와 MSA에서 Transaction 관리로는 여러 방법이 있다.
- 2PC(2-Phase Commit)
- Saga Pattern
- Ochestration Pattern
- Choregraphy Pattern
- 위 몇가지 방법을 이론적으로 먼저 소개하겠다.
2PC(2-Phase Commit)
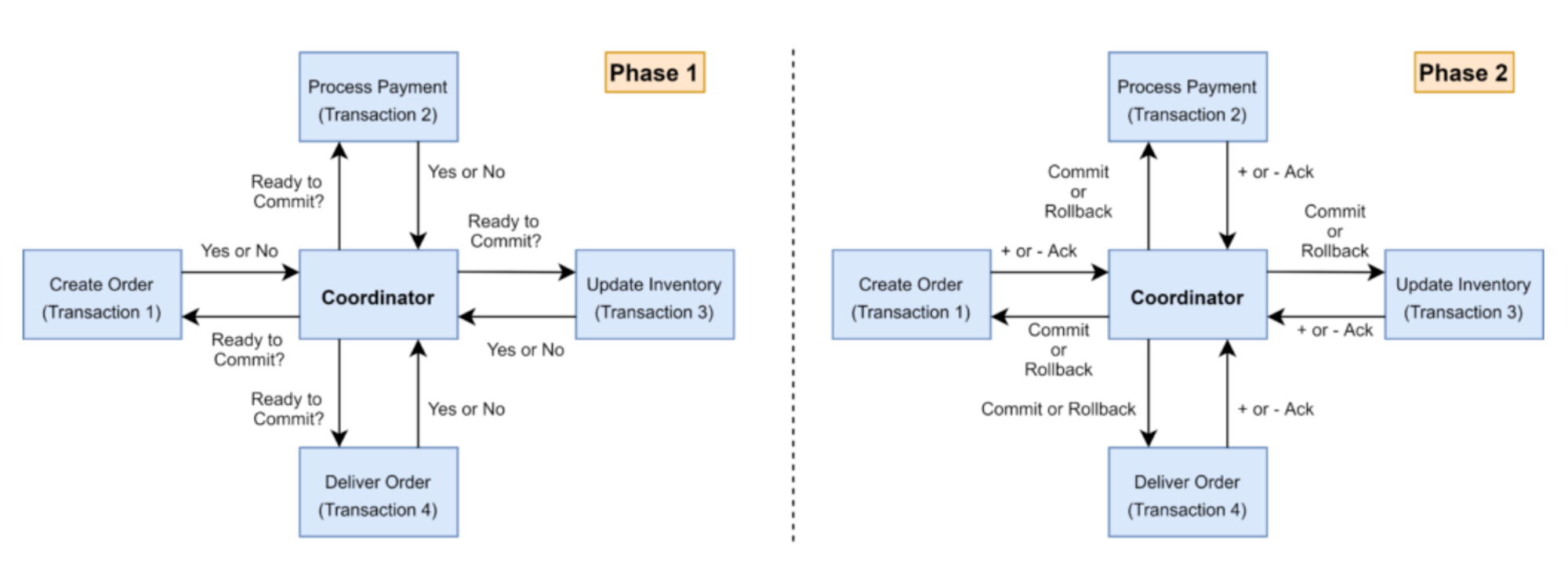
- 2PC(2-Phase Commit or N-Phase Commit)는 분산 시스템에서 트랜잭션을 관리하는 알고리즘이다.
- 1 단계 : 준비단계(Prepare Phase)
- 코디네이터(Coordinator)는 모든 참여자에게 트랜잭션을 준비하고 커밋할 준비가 되었는지 묻는 Request-To-Prepare 메시지를 보냅니다.
- 참여자(Participant = Managers)는 트랜잭션을 준비하고, 커밋할 준비가 되면 Yes로 응답하고, 그렇지 않으면 No로 응답합니다. Yes로 응답한 참여자는 트랜잭션을 롤백하지 않고 잠시 대기합니다.
- 2 단계 : 커밋 단계 (Commit Phase)
- 코디네이터(Coordinator)는 모든 참여자(Participant = Managers)로부터 Yes 응답을 받으면, 모든 참여자에게 Commit 메시지를 보내 트랜잭션을 완료하도록 합니다.
- 만약 어떤 참여자라도 No로 응답하거나 응답이 없다면, 코디네이터(Coordinator)는 모든 참여자(Participant = Managers)에게 Rollback 메시지를 보내 트랜잭션을 취소합니다.
- 1 단계인 준비단계가 필요한 이유
- 모놀리식에서는 어차피 본인들의 인스턴스를 공유 → 트랜잭션 적용하려는 DB가 트랜잭션이 가능한 상태지인지 알아야할 필요 X → 전체(1개)의 어플리케이션이 1개의 DB를 사용하기 때문이다.
- MSA에서는 인스턴스 분리로 인해 대상 DB가 트랜잭션이 가능한 상태인지 미리 확인해야한다. → 전체(여러개)의 어플리케이션이 각 고유의 DB를 사용하기 때문이다.
2PC(2-Phase Commit) 장점, 단점
- 장점
- 모든 참여자가 트랜잭션에 대해 합의하므로 데이터 일관성이 유지된다.
- 여러 서비스 또는 데이터베이스에서 동작하는 분산 트랜잭션을 관리할 수 있다.
- 단점
- 모든 참여자가 커밋을 완료할 때까지 대기해야 하므로 시스템 전반의 성능이 저하됩니다.
- 알고리즘이 복잡하여 구현 및 유지 관리가 어려울 수 있습니다.
- 참여자 중 하나가 실패하거나 응답이 느리면, 다른 모든 참여자가 해당 참여자의 응답을 기다리는 동안 데드락이 발생할 수 있습니다.
- 참여자들은 트랜잭션의 최종 커밋/롤백이 결정될 때까지 자원을 보유해야 합니다. 이는 시스템에 부하를 줄 수 있습니다.
- NoSQL에서는 지원하지 않는다.
Saga Pattern
- 드디어 왔다. MSA에서 제일 어려운 트랙잭션 관리 중에서도 Saga Pattern이다.
- Saga 패턴이란 마이크로서비스들끼리 이벤트를 주고 받아 특정 마이크로서비스에서의 작업이 실패하면 이전까지의 작업이 완료된 마이크서비스들에게 보상(complemetary) 이벤트를 소싱함으로써 분산 환경에서 원자성(atomicity)을 보장하는 패턴입니다.
- Saga에는 두가지 패턴이 존재하는데 위에서 설명했듯이 Choreography, Orchestration 두가지가 존재한다.
Choreography-based Saga
- 분산 트랜잭션을 책임지는 중계자(Saga Manager)가 존재하지 않는 방식이다.
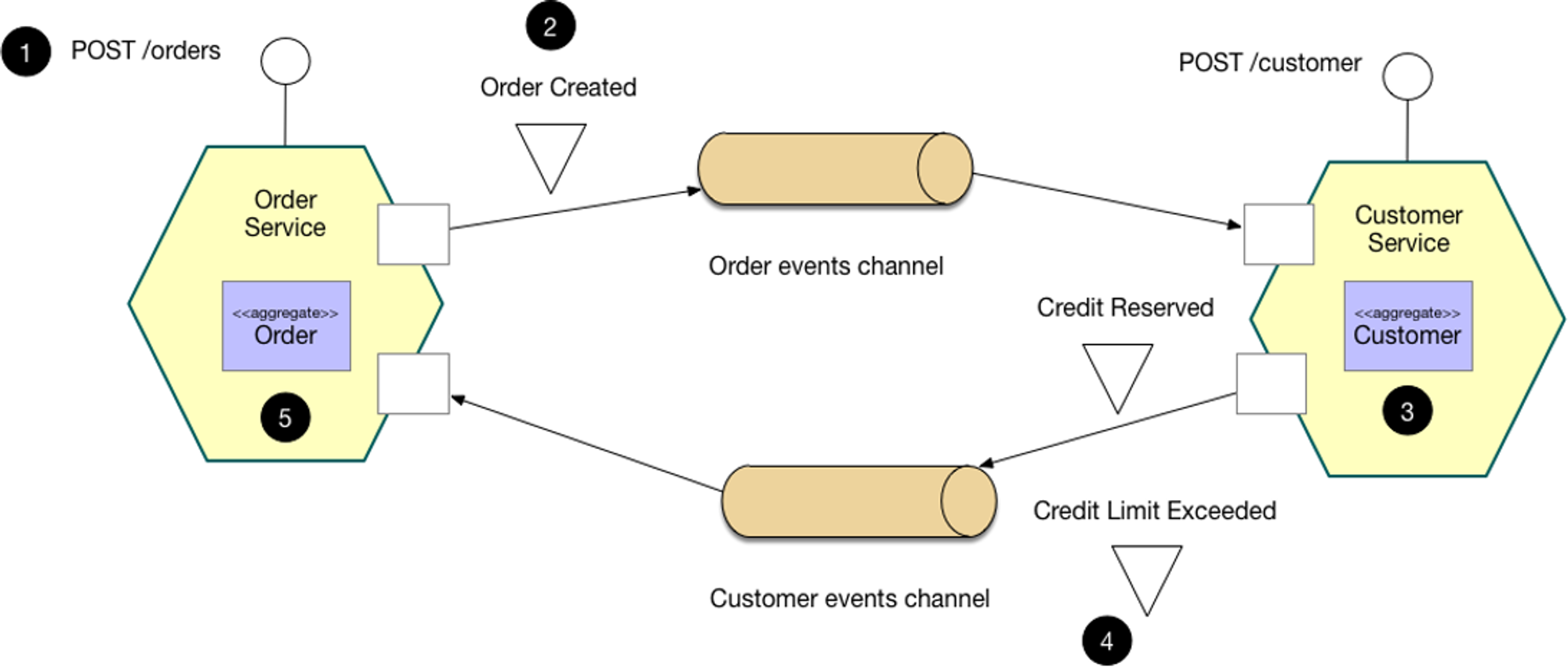
- 로컬 트랜잭션을 처리하고 다음 서비스에게 이벤트 전달한다.
- 성공, 실패를 큐로 응답으로 넣어준다.
- 실패 시 보상 트랜잭션 발행한다.
- 장점
- 각 서비스가 독립적으로 작동하므로 시스템이 더 분산적이다.
- 각 서비스가 자체적으로 단계를 처리하므로, 개별 서비스 변경이 더 쉽다.
- 서비스간에 느슨한 결합이 유지되므로, 한 서비스의 변경이 다른 서비스에 큰 영향을 미치지 않는다.
- 단점
- 트랜잭션이 많은 서비스를 포함하는 경우, 전체 흐름을 이해하거나 디버깅하기가 어려울 수 있다.
- 각 서비스가 독립적으로 작동하므로, 전체 트랜잭션의 일관성을 유지하는 것이 어려울 수 있다.
- 오류가 발생하면, 이미 완료된 단계를 롤백하는 로직이 복잡해질 수 있다.
Orchestration-based Saga
- 하나의 orchestrator가 전체 트랜잭션의 흐름을 관리합니다.
- Orchestration는 각 서비스를 순차적으로 호출하고, 오류가 발생하면 적절한 롤백 로직을 호출하여 트랜잭션을 복구합니다.
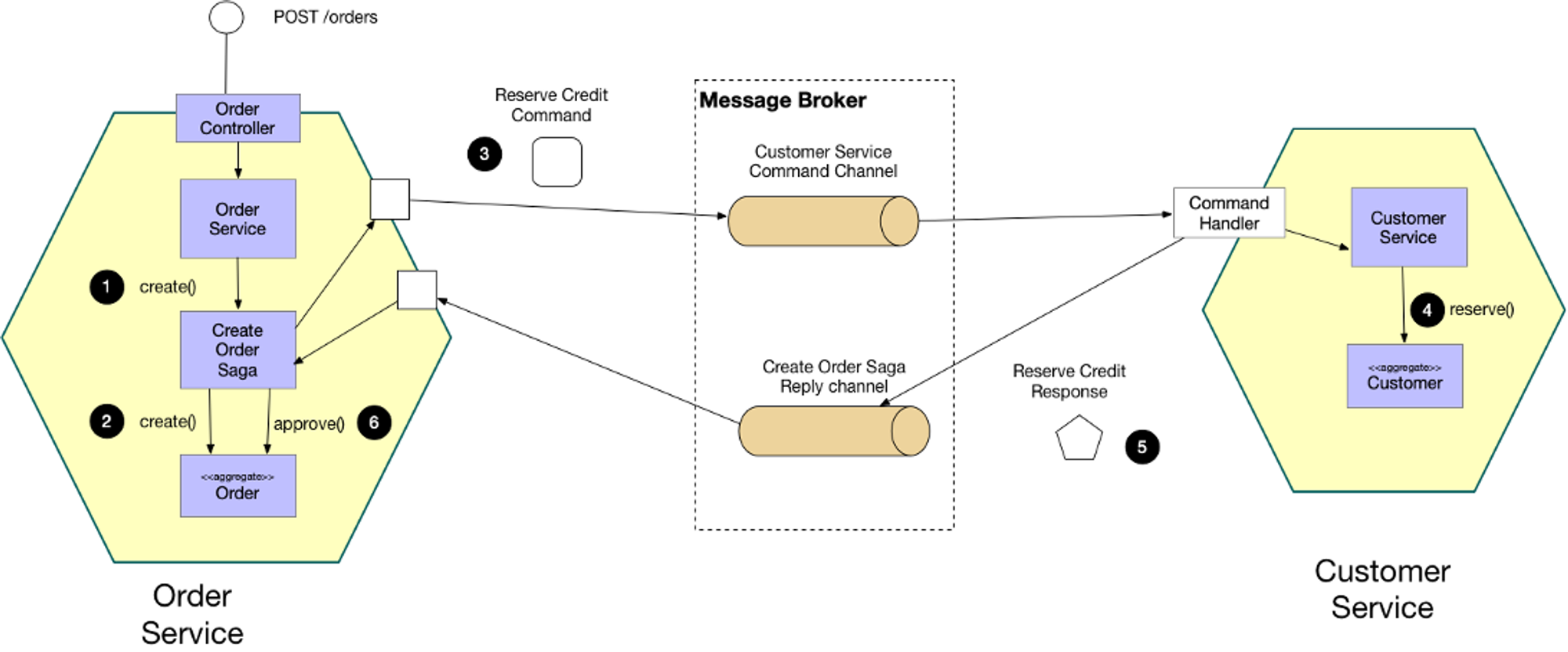
- 트랜젝션에 관여하는 모든 서비스는 중계자에 의해서 점진적으로 트랜잭션을 수행하며 결과를 중계자에게 전달한다.
- 그렇게 진행하다 마지막 트랜잭션이 끝나게되면 중계자를 종료하면서 전체 트랜잭션 처리를 종료한다.
- 실패 시 보상 트랜잭션 발행한다.
- 장점
- 중앙 중계자가 있으므로 전체 트랜잭션 흐름이 명확하고 일관됩니다.
- 오류 처리와 롤백 로직이 중앙에 있으므로, 오류 관리가 더 간결하고 효과적일 수 있습니다.
- 전체 흐름이 한 곳에서 관리되므로, 코드 유지보수가 더 용이할 수 있습니다.
- 단점
- 중앙 중계자가 시스템의 복잡성을 증가시킬 수 있습니다.
- 중앙 중계자는 서비스 간의 결합도를 높일 수 있으며, 시스템의 유연성을 제한할 수 있습니다.
Transaction Pattern 선택
- 두 패턴(Choreography, Orchestration)은 어떤 프로젝트에서 사용하는게 나은지는 프로젝트의 특성에 따라 나뉠수 있다고 생각한다.
- 내가 생각했을 땐 Choreography-based Saga가 결합도 측면에서 조금 더 MSA가 지향하는 방식이 아닐까 하지만 단지 결합도 측면만 봐서는 안 될 것 같다.
- 왜냐하면 유지보수 및 관리적인 측면에서 서비스가 커지면 커질수록 Orchestration-based Saga는 개발 리소스가 적게 들 것이다.
- 또한, 추적성 측면에서 중앙 중계자를 통해 명확한 트랙잭션이 추적이 가능하고 제일 크다고 느낀점은 바로 오류 처리 및 롤백 측면이다.
- 해당 부분은 Orchestration Saga가 직접 롤백을 관리하기에 각각의 서비스를 자체적으로 롤백하지 않아도 돼서 이 부분이 제일 맘에 들었다.
결론
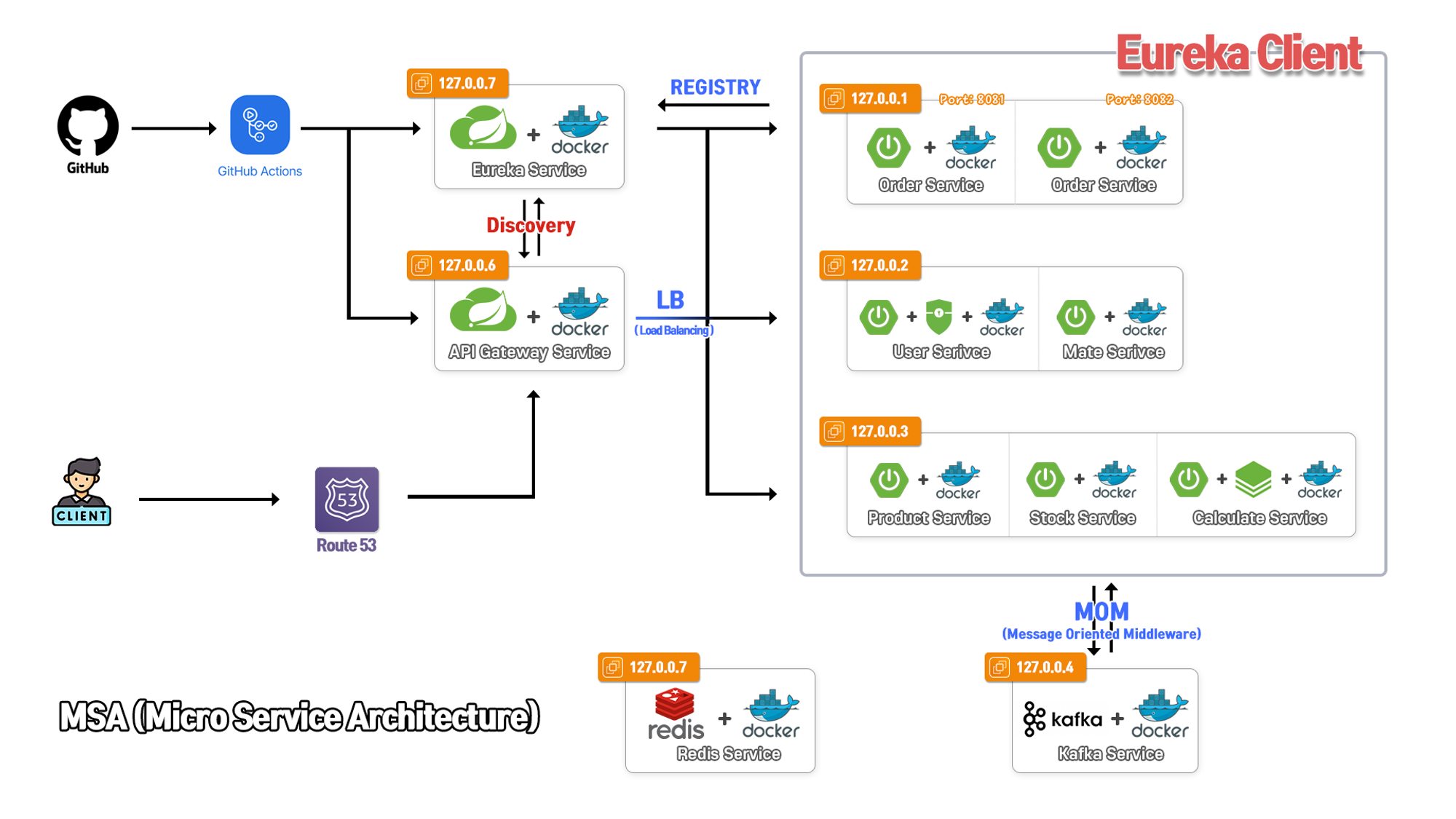
infrastructure architecture
- 위에서 말했던 모든 마이크로 서비스를 합친 인프라 아키텍처입니다.
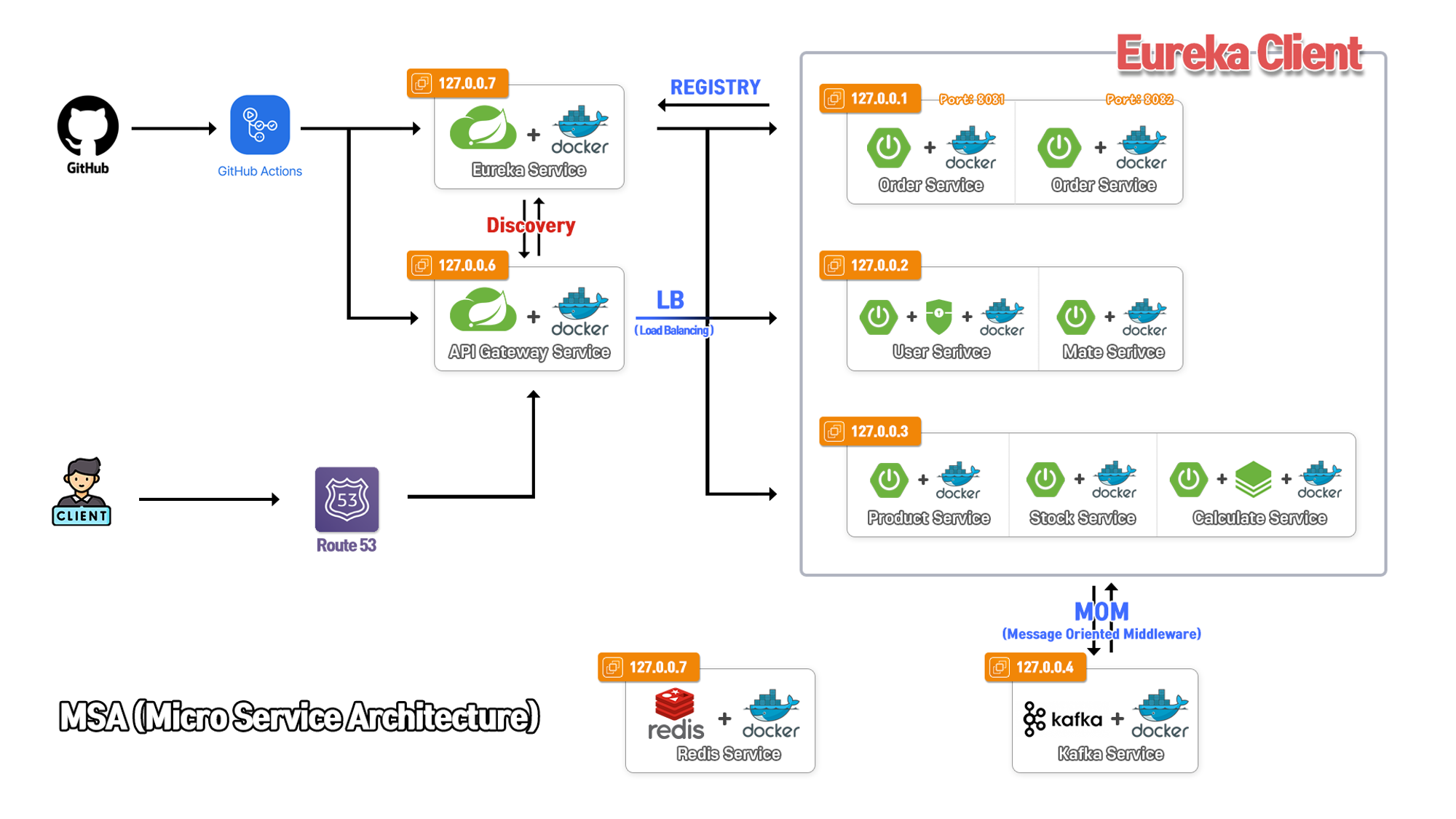
- 사진에 보이듯이 유레카 클라이언트로 등록된 도메인 마이크로서비스는 6개이고 서비스간 통신은 Kafka를 사용하고 Proxy Server 역할로 Spring Cloud API Gateway를 사용하였고 모두 합쳐 서버는 7개를 사용하였습니다.
- 또한, API Gateway에 Client로 등록을 해주기 위해 Eureka Server를 따로 두었습니다. 여기서
- API Gateway는 라우팅 기능을 이용하여 각 서비스로 통신을 보내줍니다. 비유를 하자면 기차와 같고
- Eureka는 라우팅을 통해 갈 수 있게 길을 연결을 해주는 서비스입니다. 비유를 하자면 철길과 같습니다.
- Redis는 Redission을 이용하여 전체 서비스에 세션을 관리합니다.
- 그리고 API Gateway 각 서비스중 주문서비스만 로드밸런싱을 담당해주고 있습니다.
마지막으로
- 마지막으로 제가 여태 어떤 이유로 MSA가 좋은지만 설명했는데 꼭 MSA가 무조건 좋다는 절대절대 아닙니다.
- 그리고 저희가 자주 방문하는 사이트중 하나인 스택 오버플로우라는 사이트가 있습니다.

- 해당 사이트는 한달에 1억명 방문하는 사이트인데 MSA를 사용하지도 않고도 잘 운영되고 있죠.
- 이런걸 보았을 때 상황에 맞춰서 합리적인 판단이 든다면 MSA를 경험해보는 것도 좋을 것 같습니다.

지나가는 개발자