
서론
알고 가야할 사전 지식
- 일단 제목을 해석하면 트랙잭션 복잡도이다.
- 제목을 이렇게 지은 이유는 트랙잭션 처리에 대한 고찰(?)을 하고 난 뒤 나의 경험을 기반으로 한 내용들을 정리하기 위함이다.
- MSA Phase 5. Transaction 내가 쓴 블로그이다. 한번 읽고 시작하는게 편할 것 이다.
본론
MSA에서 Transaction
- MSA에서 Transaction을 관리하는 방법은 여러가지 있다.
- 나는 그 중 Orchestration-based Saga Pattern을 사용하였다.
- 팀 마다 기술스택이나 선택하는 Pattern이 다르기에 나는 나의 뜻대로 Orchestration에 중계자가 전체 트랙잭션의 흐름을 명확하게 관리해준다는 메리트에 선택을 하게 되었다.
- 근데, 여기서 문제가 발생했다. 아래 코드 하나를 보여주겠다.
@Component @RequiredArgsConstructor public class SettlementTasklet implements Tasklet { private final GetRegisteredBankAccountPort getRegisteredBankAccountPort; private final PaymentPort paymentPort; @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext){ // 1. order service에서 주문 완료된 주문 내역을 조회한다. (order service) List<Payment> normalStatusPaymentList = paymentPort.getNormalStatusPayments(); // 2. 각 주문 내역의 franchiseId 에 해당하는 유저 정보(userId)에 대한 뱅킹 정보(계좌번호)를 가져온다. (user service) Map<String, FirmbankingRequestInfo> franchiseIdToBankAccountMap = new HashMap<>(); for (Payment payment : normalStatusPaymentList) { RegisteredBankAccountAggregateIdentifier entity = getRegisteredBankAccountPort.getRegisteredBankAccount(payment.getFranchiseId()); franchiseIdToBankAccountMap.put(payment.getFranchiseId() , new FirmbankingRequestInfo(entity.getBankName(), entity.getBankAccountNumber())); } // 3. 각 franchiseId 별로, 정산 금액을 계산한다. (settlement service) for (Payment payment : normalStatusPaymentList) { FirmbankingRequestInfo firmbankingRequestInfo = franchiseIdToBankAccountMap.get(payment.getFranchiseId()); double fee = Double.parseDouble(payment.getFranchiseFeeRate()); int caculatedPrice = (int) ((100 - fee) * payment.getRequestPrice() * 100); firmbankingRequestInfo.setMoneyAmount(firmbankingRequestInfo.getMoneyAmount() + caculatedPrice); } // 4. 계산된 금액을 펌뱅킹 요청한다. (펌뱅킹 외부 어댑터) for (FirmbankingRequestInfo firmbankingRequestInfo : franchiseIdToBankAccountMap.values()) { getRegisteredBankAccountPort.requestFirmbanking( firmbankingRequestInfo.getBankName() , firmbankingRequestInfo.getBankAccountNumber() , firmbankingRequestInfo.getMoneyAmount()); } // 5. 정산 완료된 주문 내역은 정산 완료 상태로 변경해준다. (order service) for (Payment payment : normalStatusPaymentList) { paymentPort.finishSettlement(payment.getPaymentId()); } return RepeatStatus.FINISHED; } }- Task는 아래와 같다.
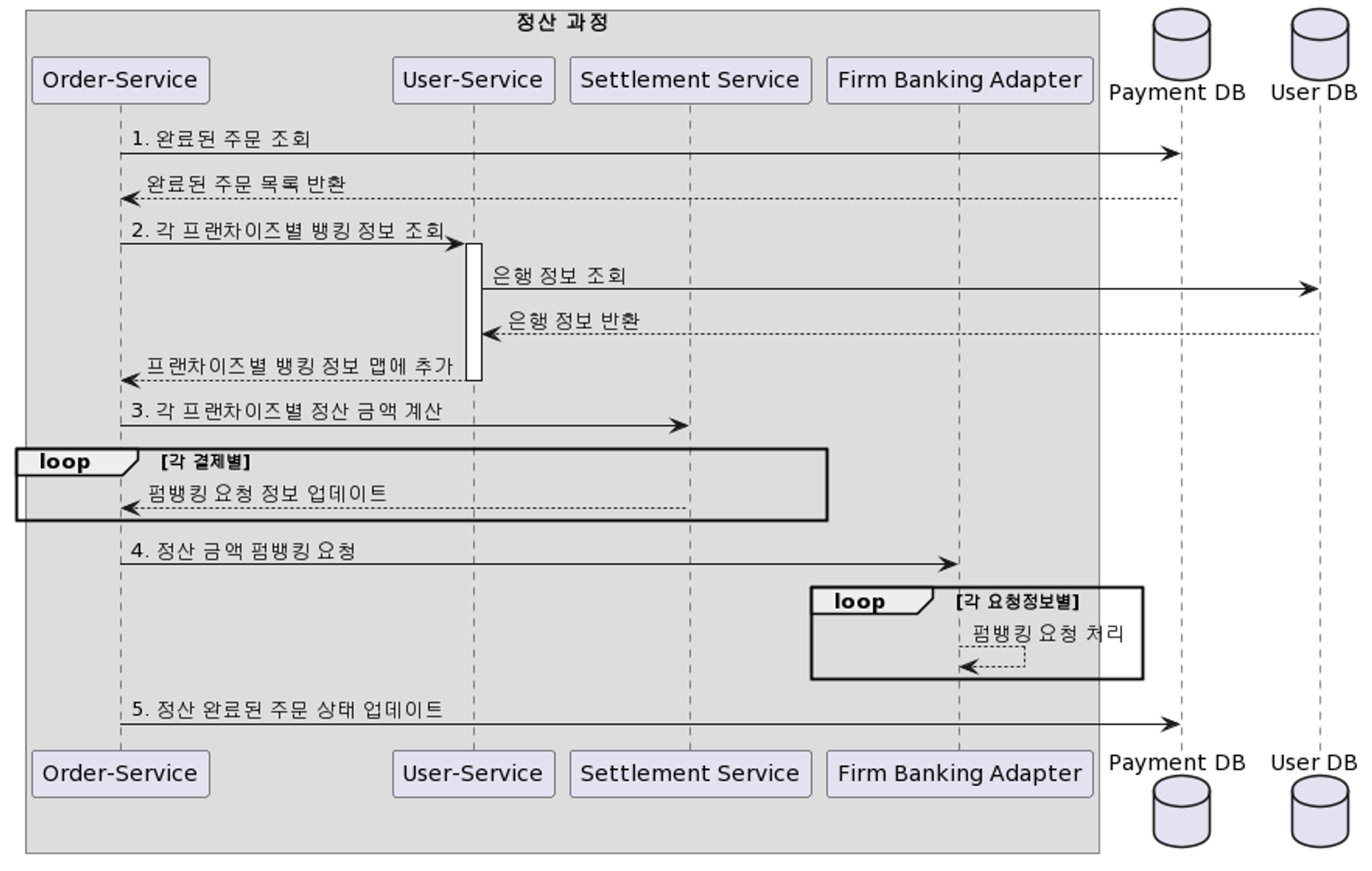
- 주문 서비스에서 정상 주문 내역들을 확인하기 (order service)
- 각 결제 내역에 대한 계좌 정보를 가져온다 (user service)
- 정상 결재 내역 건들의 가맹점 별 금액 계산하기 (settlement service)
- 가맹점과 연결된 계좌에 정산된 금액을 이체하기 (펌뱅킹 외부 어댑터)
- 결제 건들의 상태를(결제 완료 -> 정산 완료) 변경하기 (order service)
- 모든 Task들이 다 에러가 발생할 수 있다는 가정으로 시작해보자.
- Task는 아래와 같다.
에러 발생시 생각해볼 수 있는 고려사항
- Saga 도입 → 우리는 일단 트랙잭션을 관리하기 위한 Saga Pattern을 같이 구사해보지 않았는가? 도입이 가능할 것 같다.
- DLQ 도입 → DLQ(Dead Letter Queue)를 Kafka와 같이 사용하기
- Task에 대한 순서 바꾸기
가정 1 (Saga 도입)
- Task 1번은 단순 조회 작업이라 상태를 변경시키지 않기에, 롤백이 필요없다고 생각하였다.
- Saga가 필요 없다고 생각하였다.
- Task 2, 3, 5번은 Payment에 기반한 Saga가 필요하다고 생각한다.
- 각 Payment에 대한 독립적인 Saga 인스턴스를 생성하여 트랜잭션을 관리한다고 생각하였다.
- 문제는 여기이다.
- Task 4번은 Payment에 의존하는 것이 아니라 특정 franchiseIdToBankAccountMap에 의존하고 있다.
- 위 같은 상황일 땐 실무에서는 기존에 사용하던 Payment가 아닌 새로운 Saga를 만들어서 처리를 해야하는지?
- 즉, 하나의 비즈니스 프로세스에서 2개 이상의 Saga를 사용하는게 좋을까? 라는 고민을 하였다.
- 고민을 하는 이유
- 1개의 Saga 인스턴스를 사용하는 것도 어려웠던 경험이 있고 2개 이상의 Saga 인스턴스는 엄첨난 복잡성을 초래할 것으로 예상이 된다.
가정 2 (DLQ 도입)
- Task 2, 3, 4, 5번과 같이 Payment나 다른 요소에 의존하는 작업은 실패할 가능성이 있다.
- 복잡한 비즈니스 로직에서 메시지 전달의 실패를 방지하고, 실패한 경우에도 안전하게 메시지를 보관하며 재처리할 수 있는 방법이 필요하다고 생각하게 되었다.
- DLQ를 통해 실패한 메시지를 재처리하면서 시스템의 안정성을 유지할 수 있다.
- DLQ에 저장된 메시지의 상태를 모니터링하면서 문제점을 빠르게 파악하고 해결할 수 있다.
- DLQ 도입으로 인해 시스템의 복잡성이 증가할 수 있으나, 이는 비즈니스 로직의 안정성과 데이터의 무결성을 확보하기 위한 필요한 투자라고 판단되었다.
실행 2 (DLQ 도입)
- 우리는 기존에 Kafka에 대한 설정을 다 마친 상태이다. 기존 상태는 유지하되 추가적으로 넣어야하는 부분은 Retry에 관련된 설정들이다.
- 먼저 Kafka에 대한 설정들부터 변경하겠다.
- 우리는 메세지를 보내고 난 뒤 비즈니스 로직을 처리 한 후에 성공, 실패에 따른 Consume을 설정해주기 위해 ConsumerConfig를 바꿔줘야한다.
- ConsumerConfig에 넣어줘야하는 것은 Retry에 대한 로직, Retry 횟수를 다 끝내도 에러가 떴을 경우 Call Back으로 로직을 처리해준다.
- 이젠 코드로 설명하겠다.
- KafkaConsumerConfig
@Slf4j @Configuration public class KafkaConfiguration { @Value("${kafka.bootstrap-servers}") private String bootstrapServers; @Autowired private KafkaProperties kafkaProperties; @Autowired private KafkaTemplate<String, String> kafkaTemplate; // Kafka Consumer Config @Bean public ConsumerFactory<String, String> consumerFactory() { final Map<String, Object> properties = new HashMap<>(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaProperties.getBootstrapServers()); properties.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaProperties.getConsumer().getGroupId()); properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, kafkaProperties.getConsumer().getAutoOffsetReset()); properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); properties.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, KafkaProperties.IsolationLevel.READ_COMMITTED.toString().toLowerCase(Locale.ROOT)); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return new DefaultKafkaConsumerFactory<>(properties); } // Retry Template(Kafka 2.8 이상부터 사용함.) @Bean public RetryTopicConfigurer retryTopicConfigurer() { return RetryTopicConfigurer .builder() .create(kafkaTemplate); } // Retry Template(Kafka 2.8 이상부터 사용하지 않음.) private RetryTemplate retryTemplate() {~~ RetryTemplate retryTemplate = new RetryTemplate(); // 재시도시 1초 후에 재 시도하도록 backoff delay 시간을 설정한다. FixedBackOffPolicy fixedBackOffPolicy = new FixedBackOffPolicy(); fixedBackOffPolicy.setBackOffPeriod(1000L); retryTemplate.setBackOffPolicy(fixedBackOffPolicy); // 최대 재시도 횟수 설정 SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy(); retryPolicy.setMaxAttempts(2); retryTemplate.setRetryPolicy(retryPolicy); return retryTemplate;~~ } // Roll Back Logic private RecoveryCallback<Object> recoveryCallback() { return new RecoveryCallback<Object>() { @Override public Object recover(RetryContext context) { ConsumerRecord<?, ?> record = (ConsumerRecord<?, ?>) context.getAttribute("record"); String topic = "dlt_" + record.topic(); try { log.warn("[Send to dead letter topic] {} - value: {}.", topic, record.value()); kafkaTemplate.send(topic, record.value().toString()); } catch (Exception e) { log.error("[Fail to send to dead letter topic]: {}", topic, e); } Acknowledgment acknowledgment = (Acknowledgment) context.getAttribute("acknowledgment"); if (acknowledgment != null) { acknowledgment.acknowledge(); } return Optional.empty(); } }; } // Kafka Listener @Bean public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory(KafkaProperties kafkaProperties, KafkaTemplate<String, String> kafkaTemplate) { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory(kafkaProperties)); // factory.setRetryTemplate(retryTemplate()); // Kafka 2.8 이상부터 사용하지 않음. factory.setRecoveryCallback(recoveryCallback()); factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL); return factory; } }- 일단 코드에 주석을 달아두어서 큰 틀은 바로 이해할 수 있을 것이다.
consumerFactory→ Kafka Consumer에 대한 설정 정보를 담아둔다.retryTopicConfigurer→ Retry Template을 대체하기 위해 만든 Retry Topic 설정 정보이다.- Retry Template를 대체하는 이유는 Kafka 2.7.0 이하 버전은 동일한 파티션에서만 재시도가 가능했고, DLT가 수동으로 처리가 되어 권장하지 않아서
retryTopicConfigurer로 수정하였습니다.
- Retry Template를 대체하는 이유는 Kafka 2.7.0 이하 버전은 동일한 파티션에서만 재시도가 가능했고, DLT가 수동으로 처리가 되어 권장하지 않아서
recoveryCallback→ Roll Back에 대한 비즈니스 로직을 만들어두었다.kafkaListenerContainerFactory→ Kafka Listener가 사용할 수 있도록 설정을 미리 해두었다.
- KafkaConsumer
@Slf4j @Service @RequiredArgsConstructor public class KafkaConsumer { private final PaymentRepo paymentRepo; @KafkaListener(topics = "Payment-topic", containerFactory = "kafkaListenerContainerFactory") @RetryableTopic(attempts = "2", backoff = @Backoff(delay = 1000)) public void requestFirmBanking(String kafkaMessage) { // 펌뱅킹을 요청하는 비즈니스 로직 처리 } }containerFactory→ kafkaListenerContainerFactory로 설정이 되어있는데, kafkaListenerContainerFactory는 Kakfa Consumer의 세부 동작 방식을 구성하는데 사용된다.- 우리는 위에서 이미 @Bean으로도 등록을 해둔 상태이다.
@RetryableTopic(attempts = "2", backoff = @Backoff(delay = 1000))RetryableTopic→ Kafka 메시지 처리 중 오류가 발생했을 때 재시도 로직을 구성할 수 있게 도와준다.attempts→ 재 시도 회수는 최대 2번이다.backoff→ 다시 요청하는데 지연시킬 시간은 1000ms이다.
- 비교적 간단한 방법으로 처리를 하였다.
가정 3 (Task 순서 변경)
- 사실 이 부분을 제일 많이 고민 했던 부분이다.
- 모든 부분에서 에러가 발생할수 있기에 트랙잭션을 처리해 주어야하는데, 저는 트랙잭션이 어려운 부분(정산 금액을 이체하고 다시 돌려받는 어려운 점)이 있어서 고민을 하게 되었습니다.
- 그래서 저는 트랙잭션 우선순위 두기라는 것을 생각해보았습니다.
- 트랜잭션 우선순위란 다시 롤백하기 어려운 순서대로 우선순위가 높습니다. 해당 Task에서는 4번(정산 금액 이체)이 가장 트랙잭션이 높다고 할 수 있습니다.
- 사실 그 전에 모든 Task들은 DB를 다시 Roll Back 시키면 되지만 이미 보내진 돈은 돌아오지 않기 때문입니다.
- 따라서 트랙잭션 우선순위가 높은걸 Task 순서상 가장 마지막에 두는 것이 좋다고 생각하였습니다.
- 왜냐하면 사실 순서상 4번(정산 금액 이체) 수행 후 5번(결제 건들의 상태(결제 완료 → 정산 완료) 변경하기)을 수행하는 것과 5번을 수행 후 4번을 수행하는 것은 클라이언트 입장에서는 동일하다고 생각하였습니다.
- 5번을 먼저 수행하게 되면 결제 건들에 대해 미리 상태를 결제 완료에서 정산 완료로 변경한 뒤 정산 금액을 이체합니다.
- 하지만 정산 금액 이체가 제대로 되지 않는 경우에는 Retry를 통해 몇번 더 수행후에도 똑같다면, DLQ에 넣어 주는것을 생각하고 DLQ에 들어가기 전 미리 정산 완료로 변경한 Row에 대해 다시 Roll Back 작업을 진행해 주게 되는 겁니다.
- 위에서 말한 Flow는 아래와 같습니다. 4번 → 5번 x, 5번 → 4번 o
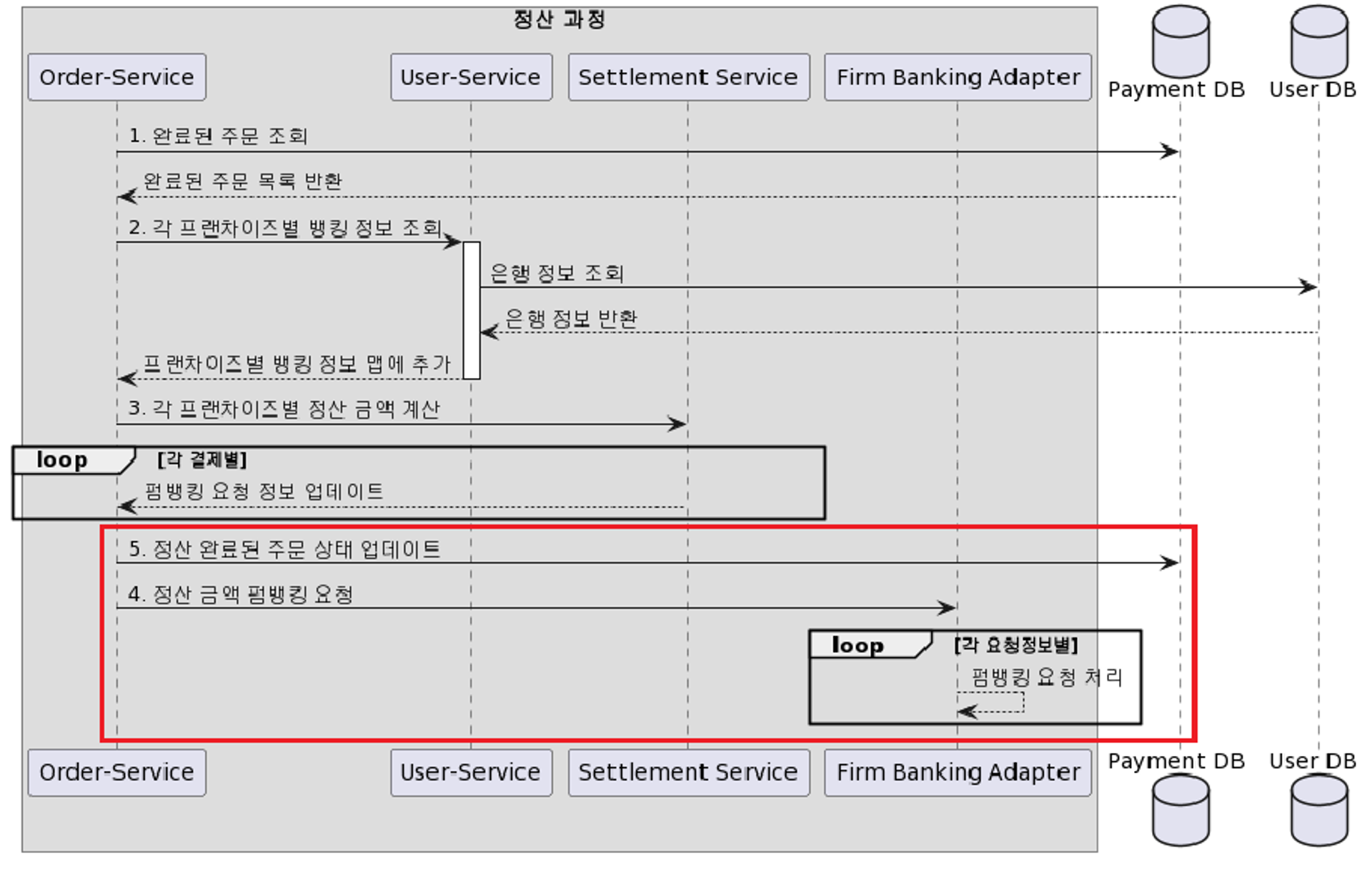
- 위 생각은 내가 옛날에 보았던 유튜브 강의인 EO에서 영감을 얻게 되었다.
- 해당 영상에서는 “문제를 해결하는 가장 좋은 방법이 정책을 바꾸고 프로그래밍을 안 하는 것일 수도 있다” 라고 말해주게 돼서 영감을 얻게 되었다.
- 그리고 예시까지 들어주었는데, 엘리베이터 예시는 여태 비유중 제일 좋았던 것 같다.
실행 3 (Task 순서 변경)
- SettlementTasklet → 비즈니스 로직을 담당
@Component @RequiredArgsConstructor public class SettlementTasklet implements Tasklet { private final GetRegisteredBankAccountPort getRegisteredBankAccountPort; private final PaymentPort paymentPort; @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext){ // 1. order service에서 주문 완료된 주문 내역을 조회한다. (order service) List<Payment> normalStatusPaymentList = paymentPort.getNormalStatusPayments(); // 2. 각 주문 내역의 franchiseId 에 해당하는 유저 정보(userId)에 대한 뱅킹 정보(계좌번호)를 가져온다. (user service) Map<String, FirmbankingRequestInfo> franchiseIdToBankAccountMap = new HashMap<>(); for (Payment payment : normalStatusPaymentList) { RegisteredBankAccountAggregateIdentifier entity = getRegisteredBankAccountPort.getRegisteredBankAccount(payment.getFranchiseId()); franchiseIdToBankAccountMap.put(payment.getFranchiseId() , new FirmbankingRequestInfo(entity.getBankName(), entity.getBankAccountNumber())); } // 3. 각 franchiseId 별로, 정산 금액을 계산한다. (settlement service) for (Payment payment : normalStatusPaymentList) { FirmbankingRequestInfo firmbankingRequestInfo = franchiseIdToBankAccountMap.get(payment.getFranchiseId()); double fee = Double.parseDouble(payment.getFranchiseFeeRate()); int caculatedPrice = (int) ((100 - fee) * payment.getRequestPrice() * 100); firmbankingRequestInfo.setMoneyAmount(firmbankingRequestInfo.getMoneyAmount() + caculatedPrice); } // 5. 정산 완료된 주문 내역은 정산 완료 상태로 변경해준다. (order service) for (Payment payment : normalStatusPaymentList) { paymentPort.finishSettlement(payment.getPaymentId()); } // 4. 계산된 금액을 펌뱅킹 요청한다. (펌뱅킹 외부 어댑터) for (FirmbankingRequestInfo firmbankingRequestInfo : franchiseIdToBankAccountMap.values()) { getRegisteredBankAccountPort.requestFirmbanking( firmbankingRequestInfo.getBankName() , firmbankingRequestInfo.getBankAccountNumber() , firmbankingRequestInfo.getMoneyAmount()); } return RepeatStatus.FINISHED; } }- Task의 순서를 변경하는 것은 위에서부터 순차적으로 실행이 되기에 코드에 위치만 변경해주었다.
결론
후기
- 필수불가피할 땐 코드를 작성하고 비즈니스 로직을 처리해야겠지만, 조금만 더 전체적인 틀에서 생각해보니 코드를 최대한 적게 작성하면서도 깔끔한 처리가 되었다.
- 사실 이게 정답이라고는 생각하지 않는다.
- 팀마다 추구하는 방향과 팀원들의 성격에 따라 다르기에 설득하기에는 내가 최대한 알고 말해야할 것 같다.
- 그리고…Kafka에 대해서 조금 알았다고 생각했는데 Offset부터 시작해서 Kafka Listener까지 아직 모르는게 투성이다…다음에 제대로 Kafka에 대해 공부해 보도록하자!!

지나가는 개발자