서론
이전에 읽어야할 것
- QueryDsl Select시 성능 최적화 1부를 읽고 오시는 것을 추천드립니다.
본론
기본 세팅
- 1부에서 사용했던 Entity를 그대로 사용하도록 하겠다.
- Entity들의 연관관계
@Entity @Table(name = "categorys") public class Category { @Id @GeneratedValue private Long id; private String name; private String description1; private String description2; private String description3; @OneToMany(mappedBy = "category", fetch = FetchType.LAZY, cascade = CascadeType.ALL, orphanRemoval = true) private List<Product> products = new ArrayList<>(); } @Entity @Table(name = "products") public class Product { @Id @GeneratedValue private Long id; private String name; private Double price; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "category_id") private Category category; }- Category와 Product : 일대다(1:N) 관계. 한
Category는 여러Product를 가질 수 있습니다.
- Category와 Product : 일대다(1:N) 관계. 한
- 이어서 가기에 테스트 5번으로 진행하도록하겠다.
테스트 진행하기 5 → Id로 Select 해오기 with Pagination(No Offset), 무한 스크롤 최적화
- 기존에 사용했던 Pagination은 정적인 페이지가 존재하는 웹사이트에 최적화된 코드였습니다. 예시로는 아래와 같은 웹 사이트가 있습니다.

- Pagination만 도입한 코드(1부에서 다뤘던 코드입니다.)
queryFactory .select(Projections.fields(ProductDetails2.class, product.id.as("productId"), product.name.as("productName"), product.price.as("productPrice"), product.category.id.as("categoryId"))) .from(product) .where(product.price.gt(0)) .orderBy(product.name.asc()) .offset(offset) .limit(pageSize) .fetch(); - 일단 앞서 진행했던 기본적인 Pagination의 코드를 보며 문제점을 간단하게 살펴보겠다.
OFFSET키워드를 사용하는 페이징 쿼리에서, 데이터베이스는 주어진OFFSET값까지의 모든 레코드를 읽고, 그 다음에 나오는LIMIT에 지정된 수만큼의 레코드만 반환한다.- 예를 들어,
OFFSET이 1000000이고LIMIT이 10일 경우, 데이터베이스는 첫 1000000개 레코드를 모두 읽은 후 다음 10개 레코드를 반환한다. - 페이지 번호가 높아질수록
OFFSET값이 커지고, 따라서 데이터베이스가 무시해야 하는 레코드의 수가 많아진다. - 간단하게 요약하자면 맨 뒷페이지로 간다고 하더라고 그 전 페이지에 들어있는 모든 데이터를 읽어야지 내가 진정 원하는 데이터를 받을수 있는 구조이다.
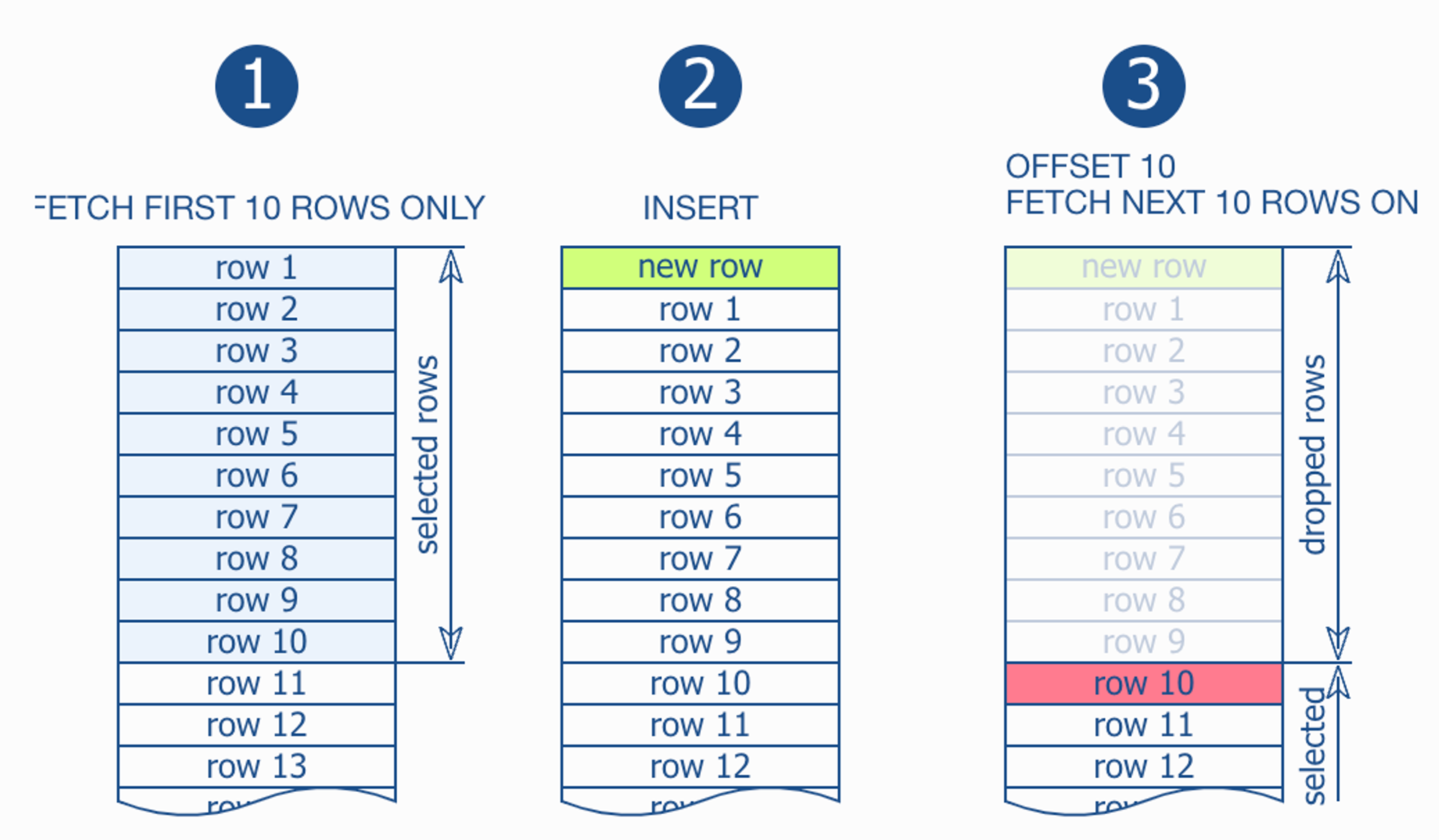
- 그리고 새로 추가되거나 삭제 되는 데이터에 대해 중복해서 읽게 되는 경우가 생길수도 있다.
- 밑 사진처럼 우리는 지금 page에 번호를 받아와서 사용하기에 새로운 컬럼이 추가되면 기존에 읽었던걸 또 읽게 될 것이다.
- 기존 코드에서 offset만 2,000,000으로 지정해서 다시 돌려보고 확인해 보았다. 이렇게 되면 2,000,001 ~ 2,000,020까지의 데이터만 가져온다. JVM Heap을 확인해보자.
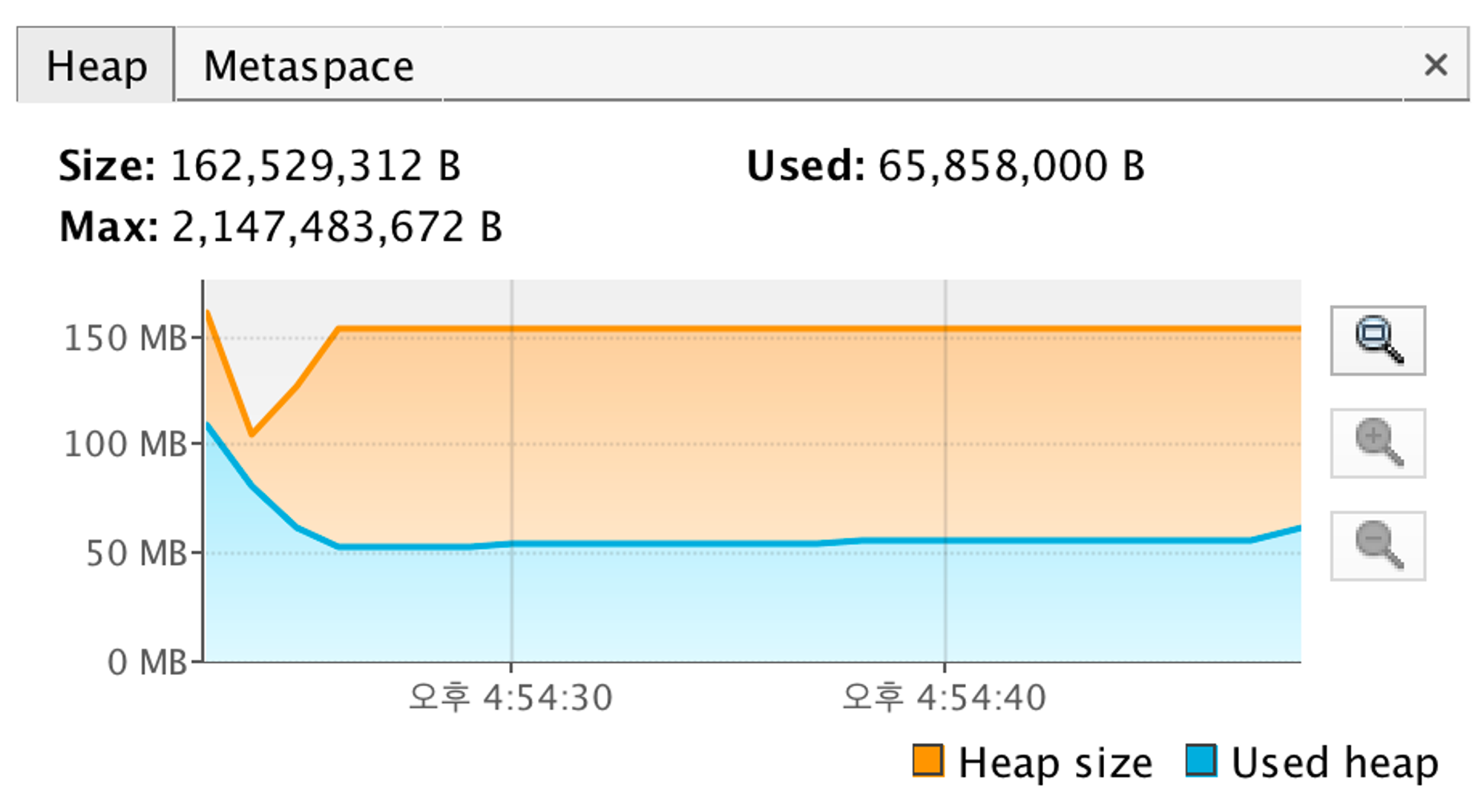
- JVM Heap을 보니 첫 페이지를 가져왔을 때는 0.7s가 소요됐는데, 지금 거의 마지막 페이지를 조회했을 때 15s 이상 걸리는 것을 파악할 수 있다.
- 15s가 걸리는 웹사이트는 운영이 불가능할 것이다…
- 이러한 단점을 보안하기 위해 No Offset 페이징을 사용하였다.
- No Offset 페이징이란?
- 각 페이지 조회 시, 직전 페이지의 마지막 ID를 기준으로 삼아 그 이후의 데이터를 조회한다. 이를 위해, 마지막 조회 ID를 쿼리의 조건문에 포함시킨다.
- 이 방식은 클러스터 인덱스(주로 PK)를 활용하여 데이터를 빠르게 검색한다. 클러스터 인덱스는 데이터가 물리적으로 정렬되어 저장되어 있어, 특정 ID 이후의 데이터를 효율적으로 찾을 수 있다.
- 페이지 번호가 높아져도 처음 페이지를 읽는 것과 동일한 성능을 제공한다. 즉, 뒤쪽 페이지에서도 성능 저하 없이 데이터를 조회할 수 있다.
- 코드로 확인해보면 다음과 같다.
@Test @DisplayName("Product 안에 category Id 만 가져오기 with Pagination (No Offset)") public void test5() { em.flush(); em.clear(); System.out.println("------------ 영속성 컨텍스트 비우기 -----------\n"); JPAQueryFactory queryFactory = new JPAQueryFactory(em); int pageSize = 20; // 페이지 당 항목 수 (예: 20) Long productId = 1000000L; // 이전 페이지의 마지막 ID List<ProductDetails2> results = queryFactory .select(Projections.fields(ProductDetails2.class, product.id.as("productId"), product.name.as("productName"), product.price.as("productPrice"), product.category.id.as("categoryId"))) .from(product) .where(product.price.gt(0), ltProductId(productId)) // No Offset 조건 추가 .orderBy(product.id.desc()) // ID 기준 정렬 .limit(pageSize) .fetch(); } private BooleanExpression ltProductId(Long productId) { if (productId == null) { return null; // BooleanExpression 자리에 null이 반환되면 조건문에서 자동으로 제거된다. } return product.id.lt(productId); }- 페이지 결정 방식
- 기존 쿼리 :
OFFSET를 사용하여 페이지 번호에 기반한 데이터 위치를 결정한다다. 예를 들어, 페이지 번호가 100,000이고 페이지 크기가 20이면,OFFSET는 1,999,980 ((100000 - 1) * 20)이 된다. 이는 데이터베이스가 1,999,980 레코드를 건너뛴 후 데이터를 조회한다는 것을 의미한다. - No Offset 쿼리 :
OFFSET대신 마지막 조회 ID를 사용하여 다음 페이지의 데이터를 조회한다. 이 방식은 데이터베이스가 이전 페이지의 끝 ID부터 시작하여 데이터를 읽기 시작하므로, 불필요한 레코드를 건너뛸 필요가 없다.
- 기존 쿼리 :
- 성능
- 기존 쿼리 : 페이지 번호가 높아질수록 데이터베이스가 더 많은 레코드를 건너뛰어야 하므로, 조회 성능이 점점 느려질 수 있다.
- No Offset 쿼리 : 페이지 번호에 관계없이 성능이 일정하다. 데이터베이스는 각 페이지 요청마다 오직 필요한 레코드만 읽기 때문에, 높은 페이지 번호에서도 성능 저하가 거의 없다.
- 쿼리 구조
- 기존 쿼리 :
OFFSET와LIMIT키워드를 사용한다. - No Offset 쿼리 :
OFFSET대신 특정 조건 (ltProductId(productId))을 사용하여 데이터를 조회한다.
- 기존 쿼리 :
- 그리고 이제 이렇게 되면 가장 마지막에 읽었던 Id에 대해 알고 있기에 중복된 데이터를 읽을 일이 전혀 없어질 것이다.
- Hibernate를 확인해보면 다음과 같다.
Hibernate: select product0_.id as col_0_0_, product0_.name as col_1_0_, product0_.price as col_2_0_, product0_.category_id as col_3_0_ from products product0_ where product0_.price > ? and product0_.id < ? order by product0_.id desc limit ?- 별 다른 쿼리 없이 기존에 사용했던 쿼리이지만, 다른 점이 있다면 where문에 이미 시작 될 부분부터 찾고 나머지 쿼리를 실행한다.
- JVM Heap을 확인해보면 다음과 같다.
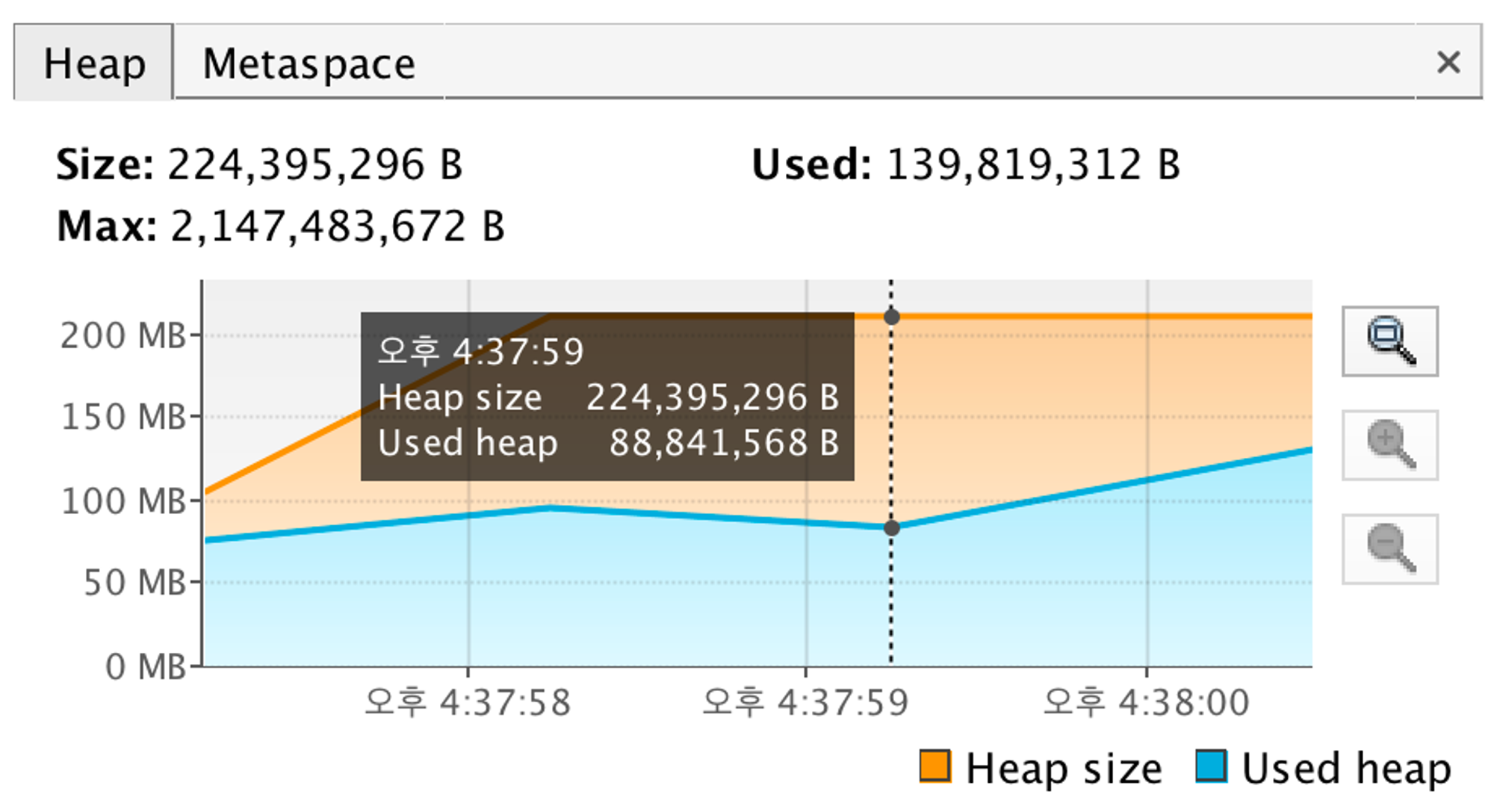
- 앞서 우리는 15s가 걸렸는데 이젠 중간 페에지, 마지막 페이지 상관 없이 일정하게 0.8s가 걸리는 것으로 파악이 된다.
- 대략 17배 향상된 처리 속도를 보여주고 있다.
- 페이지 결정 방식
Pagination(No Offset)에 대한 단점
- 정책상 정적인 페이지가 나와야한다면 사용하지 못할수 있다.
- 중간부터 볼수 없고 무조건 첫번째부터 시작을 해야한다.
- 이 두가지 단점 때문에 다른 방법을 사용하기도 한다. → Covering Index 방식이 있는데 밑에서 설명하겠다.
테스트 진행하기 6 → Id로 Select 해오기 with Pagination(Covering Index)
- 위에서 말했던 두가지 단점 때문에 어쩔수 없이 Covering Index를 사용하는 경우도 있다.
- 커버링 인덱스란? 데이터베이스 쿼리가 필요로 하는 모든 데이터를 인덱스에서 바로 가져올 수 있게 하는 인덱스이다.
- 이를 통해 데이터베이스가 실제 데이터 테이블 대신 빠른 인덱스를 통해서만 데이터를 가져오므로, 쿼리의 성능이 크게 향상된다.
- 인덱스는 데이터베이스의 디스크보다 빠른 메모리에 저장되어 있다. 커버링 인덱스를 사용하면 디스크 접근을 줄여 데이터베이스 성능이 향상된다.
- 페이징 조회에서의 사용법 : 먼저, 인덱스를 사용해 필요한 데이터의 ID들만 조회한다. 그 후, 이 ID들을 사용해 실제 데이터를 조회한다. 이 방식은 페이징 조회(예를 들어, 웹 페이지에서 데이터를 페이지별로 보여주는 경우)에서 성능을 향상시키는 데 특히 유용하다.
@Test @DisplayName("Product 안에 category Id 만 가져오기 with Covering Index") public void test6() { em.flush(); em.clear(); System.out.println("------------ 영속성 컨텍스트 비우기 -----------\n"); JPAQueryFactory queryFactory = new JPAQueryFactory(em); QProduct product = QProduct.product; int pageNumber = 1000000; // 페이지 번호 int pageSize = 20; // 페이지 당 항목 수 long offset = (pageNumber - 1) * pageSize; // 페이지 시작 위치 계산 // 첫 번째 쿼리: ID만 조회 List<Long> productIds = queryFactory .select(product.id) .from(product) .where(product.price.gt(0)) .orderBy(product.name.asc()) .offset(offset) .limit(pageSize) .fetch(); // 두 번째 쿼리: 실제 데이터 조회 List<ProductDetails2> results = queryFactory .select(Projections.fields(ProductDetails2.class, product.id.as("productId"), product.name.as("productName"), product.price.as("productPrice"), product.category.id.as("categoryId"))) .from(product) .where(product.id.in(productIds)) .fetch(); }- 위에서 설명했듯이 첫 번째 쿼리에서는 Id만 조회하고 두 번째 쿼리에서 실제 데이터를 조회하는 방식이다.
- Hibernate를 확인해보면 다음과 같다.
// 첫 번째 쿼리: ID만 조회 Hibernate: select product0_.id as col_0_0_ from products product0_ where product0_.price>? order by product0_.name asc limit ? // 두 번째 쿼리: 실제 데이터 조회 Hibernate: select product0_.id as col_0_0_, product0_.name as col_1_0_, product0_.price as col_2_0_, product0_.category_id as col_3_0_ from products product0_ where product0_.id in ( ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? ) - Jvm Heap은 다음과 같다.
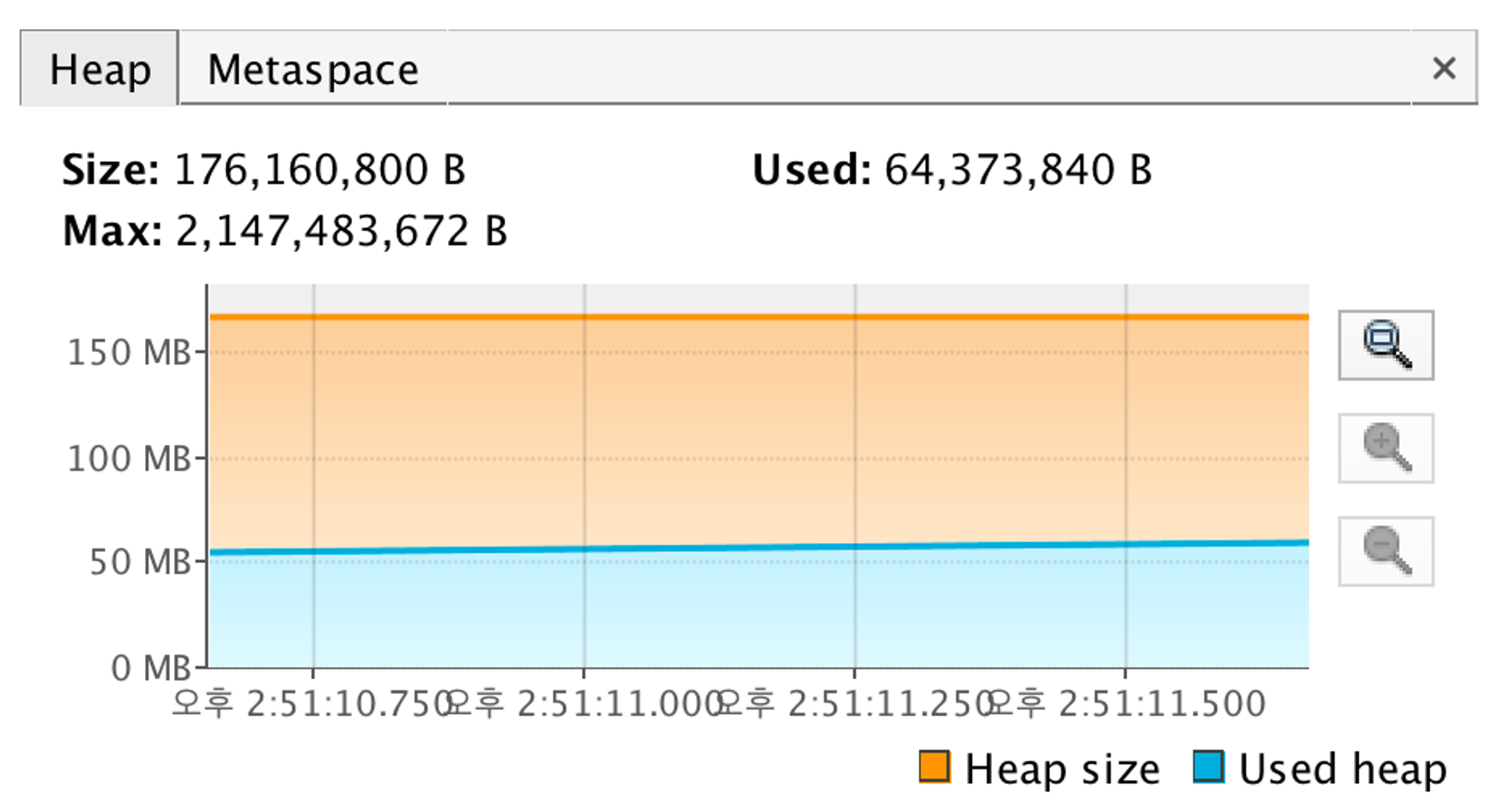
- 위 사진(JVM Heap)에서 볼수 있듯이 메모리 사용량이 0.1GB로 줄은 것으로 보인다.
- 전체 컬럼을 가져온 결과(1.25GB) → Id값 하나만 가져온 결과(0.9GB) → Pagination(0.1GB) → Pagination with Covering Index(0.06GB)으로 처리한 결과를 보니 점점 더 메모리 사용량이 줄어든 것으로 확인이 된다.
- 그리고 뒷 페이지로 가도 첫 페이지와 거의 동일한 속도를 보여주고 있다.
결론
후기
- 여태 QueryDsl에서 Select만 성능 최적화를 진행했다. 앞으로 Update라던지 Delete도 진행해볼 예정이다.
- 그전에 원래 우리는 Pagination을 할 땐 꼭 Counting도 같이 보내지 않는가?
- 프론트에서 받아서 사용하기 위해
- 지금은 안 보내고 있는데 Counting도 데이터가 많으면 최적화가 필요한 부분으로 판단이 된다.
- 그래서 다음 글에서는 Counting하는 부분도 최적화를 진행할 것이다.
- 또한, 아직 Covering Index에 대한 개념이 많이 부족한 것 같다. 이 부분도 따로 포스팅을 할 예정이다.
- 그럼 다음 이시간에🫡

지나가는 개발자