서론
Kafka가 필요한 이유
- MSA(MicroService Architecture)는 도메인 서비스간 분리가 되어 있어서 각 서비스간에 통신이 불가능하다.
- 하지만, 각 도메인 서비스를 나눴다고 해도 서비스간에 통신이 필요할수도 있다.
- ex) 주문 서비스에서 주문을 처리 했을 경우 재고 서비스에서 해당 재고를 차감시켜야하는 경우가 있다. → 사실 이 경우엔 도메인을 어떻게 나누냐의 차이이다.
- 위와같은 경우에서 주문 서비스만으로 다 처리가 불가능 하므로 서비스간 통신을 위한 무언가가 필요하다.
- MSA에서 서비스간 통신을 위해 지원하는 몇가지 방법이 있습니다.
- RESTful API (FeignClient)
- Message queue
MSA 통신을 위한 큰틀 고르기
- RESTful API (FeignClient)
- 동기 처리 방식으로 HTTP Endpoint에 대한 Interface를 생성하고 @FeingClient를 선언한다.
- 장점
- 간편한 사용 : FeignClient는 인터페이스 기반으로 동작하며, 간단한 애노테이션을 사용하여 API 요청을 정의할 수 있습니다.
- 인터페이스 기반으로 타입 안정성 보장: FeignClient는 타입 안정성을 제공하므로, API 요청 및 응답을 정적으로 타입 체크할 수 있습니다.
- 단점
- HTTP 기반 통신에 의존: FeignClient는 기본적으로 HTTP를 사용하여 통신하기 때문에, 다른 프로토콜에 대한 지원이 제한적입니다.
- 이게 가장 큰 이유인데 호출해야하는 API가 없으면 통신을 위해 무조건 만들어줘야한다. → 개발 리소스적으로나 단지 통신을 위해 새로운 API를 만드는 것이 안 좋을 것이라고 생각했다.
- Message queue (Kafka, RabbitMQ)
- 프로세스 또는 프로그램 인스턴스가 데이터를 서로 교환할 때 사용하는 통신 방법. 더 큰 의미로는 메시지 지향 미들웨어(MOM)를 구현한 시스템을 의미한다.
- MQ 동작 원리

- producer : 정보를 제공하는 자
- consumer : 정보를 제공받아서 사용하려는 자
- Queue : producer의 데이터를 임시 저장 및 consumer에 제공하는 곳
- MQ의 장점
- 비동기 : queue라는 임시 저장소가 있기 때문에 나중에 처리 가능
- 낮은 결합도 : 애플리케이션과 분리
- 확장성 : producer or consumer 서비스를 원하는대로 확장할 수 있음
- 탄력성 : consumer 서비스가 다운되더라도 애플리케이션이 중단되는 것은 아니며 메시지는 지속하여 MQ에 남아있다.
- 보장성 : MQ에 들어간다면 결국 모든 메시지가 consumer 서비스에게 전달된다는 보장을 제공한다.
- MQ의 단점
- 복잡성 : Message Queue는 시스템의 복잡성을 증가시킬 수 있습니다. 메시지 전송, 수신, 라우팅, 처리, 에러 처리 등과 같은 추가적인 로직과 관련된 기능들을 구현해야 합니다.
- 결론 : 제가 경험해본 느낌으론 이정도라 FeignClient보다는 Message queue가 더 좋다 생각하였습니다.
MQ(Kafka, RabbitMQ) 특징
Kafka
- Kafka 동작 원리
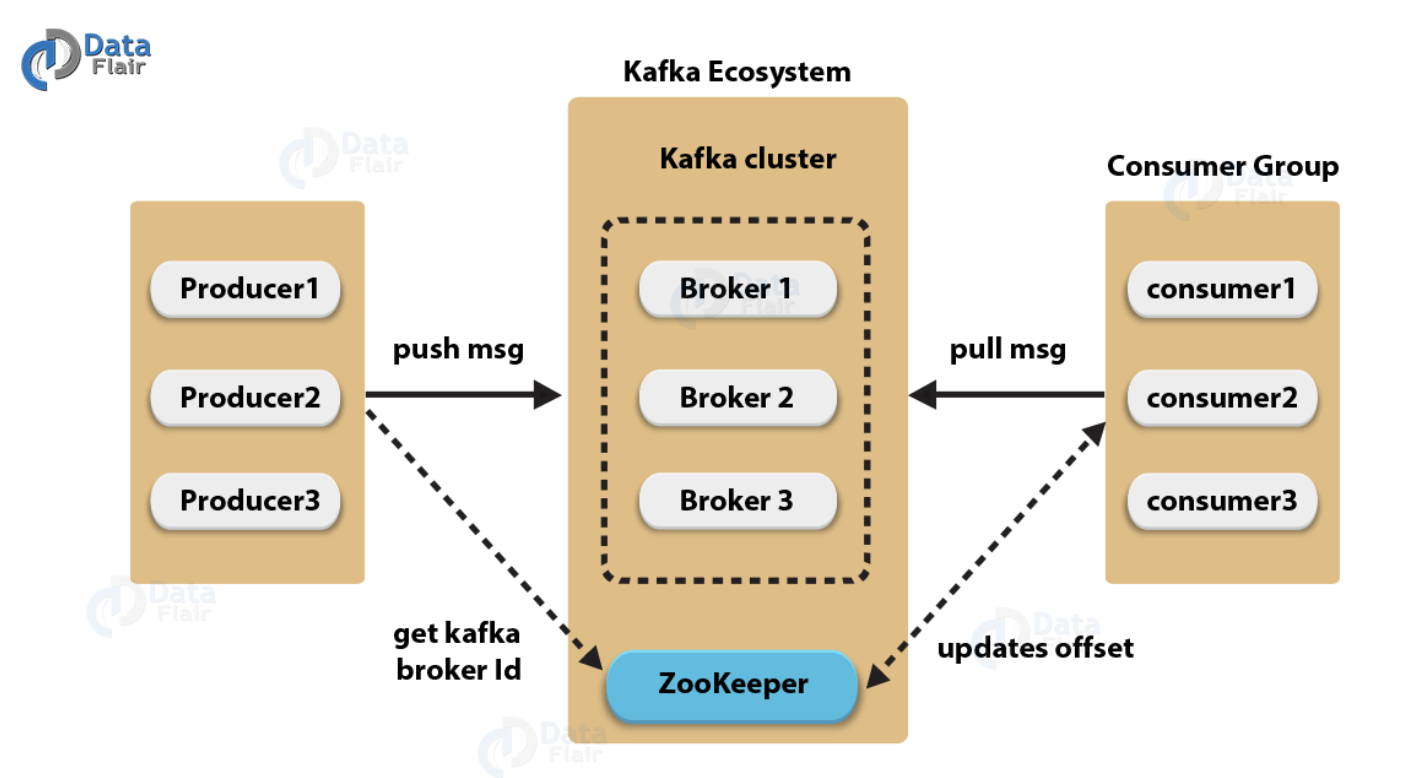
- Publisher(=producer) : 데이터를 카프카에게 보내는 역할을 합니다. 데이터를 생성하고 해당 데이터를 카프카의 Topic으로 전송합니다.
- Subscriber(=consumer) : 카프카로부터 데이터를 소비하는 역할을 합니다. Subscriber는 특정 Topic에서 메시지를 읽고 처리합니다.
- Topic : 카프카에서 데이터가 전달되는 주제를 의미합니다. Topic은 여러 개의 파티션으로 구성될 수 있으며, 데이터가 분산 저장되는 곳입니다.
- Broker : 카프카 클러스터 내에서 데이터를 저장하고 관리하는 서버입니다. 여러 대의 브로커가 하나의 카프카 클러스터를 형성하며, 데이터는 클러스터 내의 여러 브로커에 분산 저장됩니다.
- ZooKeeper : 카프카의 분산 시스템을 관리하기 위해 사용되는 분산 코디네이터입니다. 주키퍼는 브로커들의 메타데이터, Topic의 구성, 파티션의 할당 등을 관리하며, 카프카 클러스터의 안정적인 운영을 지원합니다.
RabbitMQ
- RabbitMQ 동작 원리
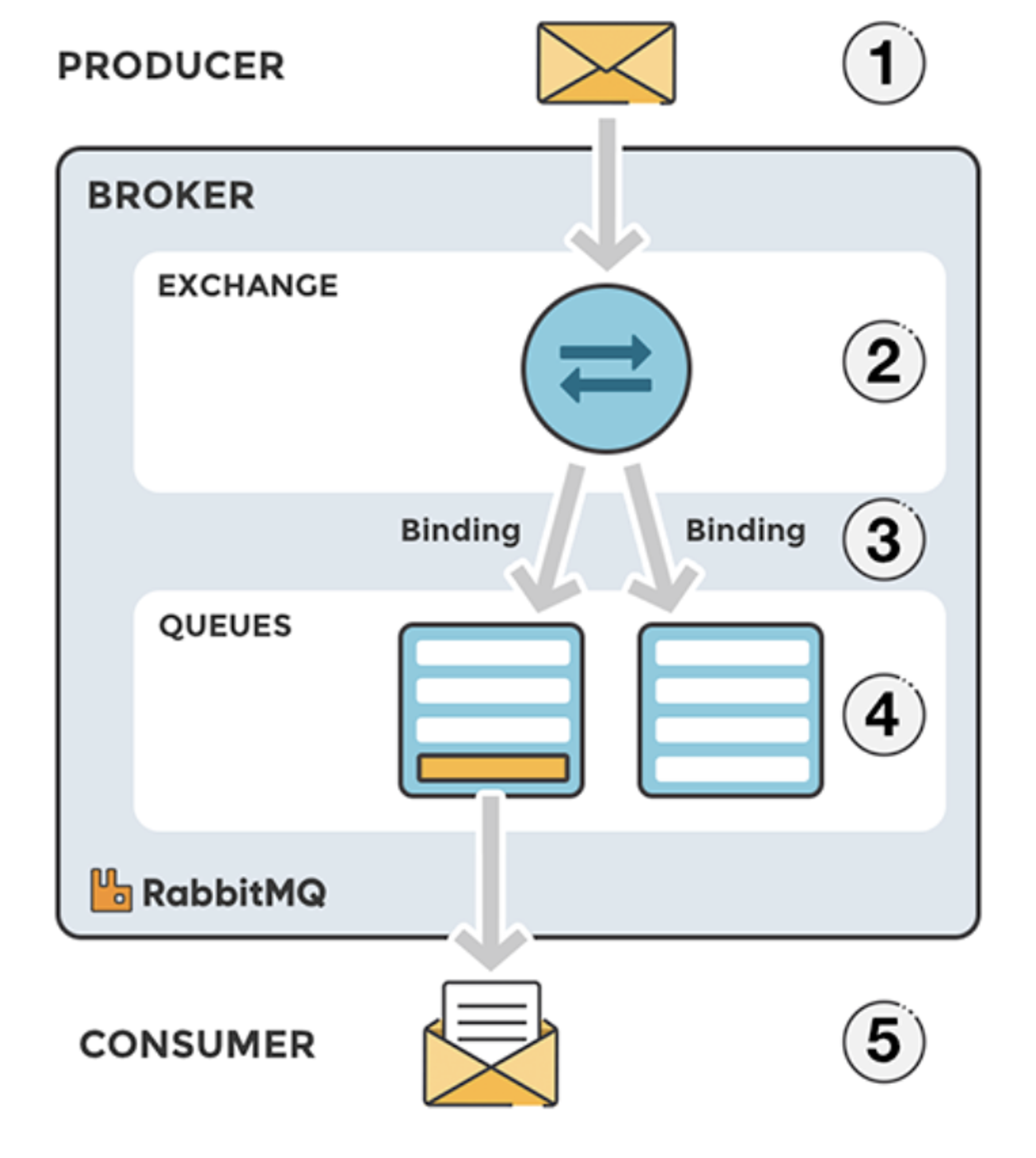
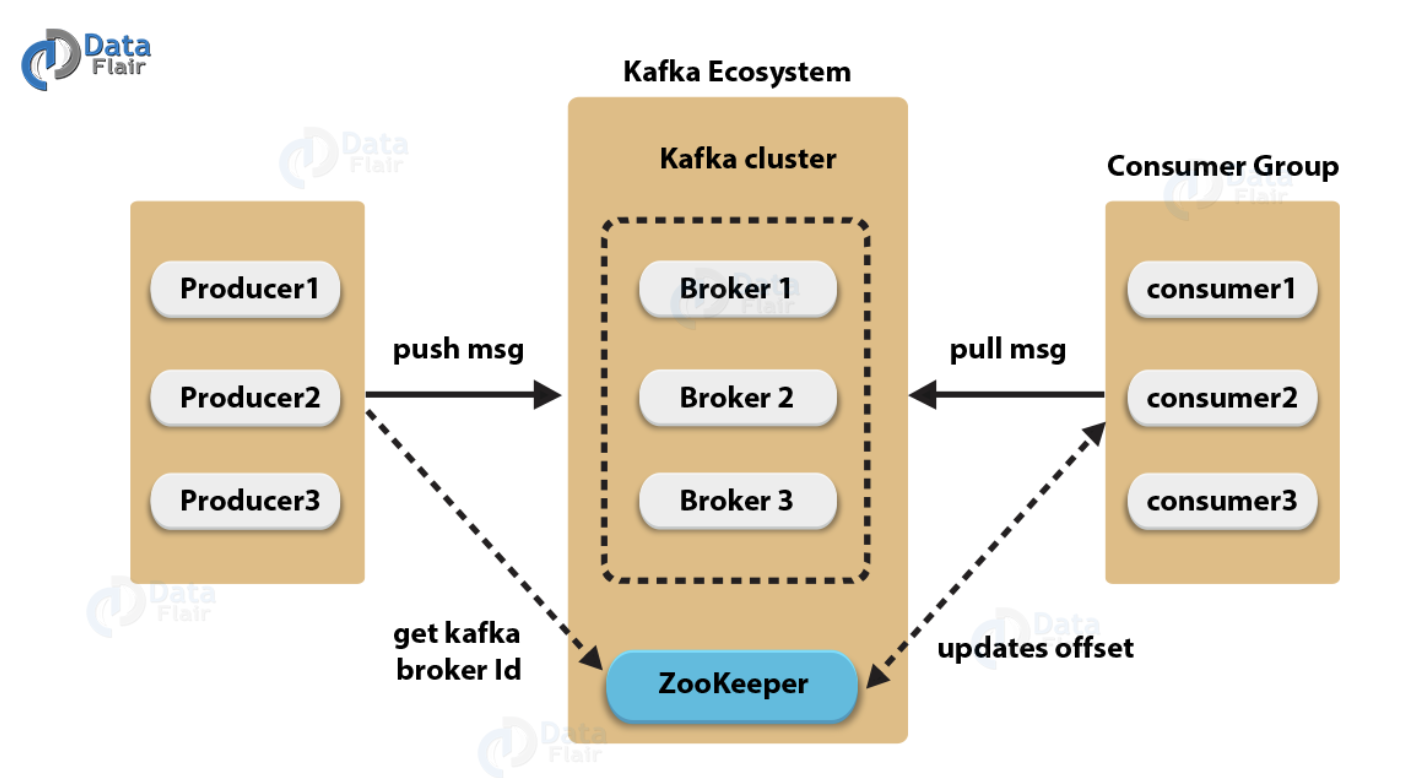
- publisher : 메시지를 보내는 쪽
- consumer : 메시지를 받는 쪽
- exchange : publisher가 전달한 메시지를 queue에 전달하는 역할
- queue : 메시지를 저장하는 버퍼
kafka vs RabbitMQ
- 두개 다 사용해보진 않았지만, 이론적인 측면에서 보았을 때와 제 경험을 기반으로 기술 스택을 선정하였습니다.
본론
가정
- User(유저 서비스), Mate(운동 게시글 서비스) 두개의 서비스가 분리되어 DDD로 만들어진 MSA가 있다.
- Mate 서비스에서 게시글을 생성시에 User 서비스에 게시글의 Tilte(제목)을 보내줘야할 때를 상황으로 전제해두겠다.
코드
- 코드를 작성하기 전 아까 보았던 Kafka의 동작 원리 그림을 확인해보면 우리가 필요한게 어떤건지 알수 있다.
- Publisher(=producer)
- Subscriber(=consumer)
- 위 두개가 코드상에서 필요한 부분들이다.
- 나머지 Topic ,Broker, ZooKeeper 는 서버적인 설정이 필요하다.
- Publisher(=producer) → 데이터를 카프카에게 보내는 쪽이다. 지금 상황에서는 Mate 서비스에서 Title을 보내야하기에 Mate 서비스가 Publisher가 된다.
- KafkaProducerConfig.java
@EnableKafka @Configuration public class KafkaProducerConfig { @Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> properties = new HashMap<>(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return new DefaultKafkaProducerFactory<>(properties); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }ProducerConfig.BOOTSTRAP_SERVERS_CONFIG→ 카프카 클러스터에 연결하기 위한 브로커(서버)의 호스트와 포트 정보를 지정 (도커 컨테이너명 : 포트번호)ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG→ Kafka 프로듀서의 키 직렬화 클래스로 StringSerializer.class 사용하고 있다.
- KafkaProducer.java
@Service @Slf4j @RequiredArgsConstructor public class KafkaProducer { private final KafkaTemplate<String, String> kafkaTemplate; public void send(String topic, CreateMatePostRequest createMatePostRequest) { ObjectMapper mapper = new ObjectMapper(); String jsonInString = ""; try { jsonInString = mapper.writeValueAsString(createMatePostRequest); } catch (JsonProcessingException exception) { exception.printStackTrace(); } log.info("Kafka Producer sent: " + jsonInString); kafkaTemplate.send(topic, jsonInString); } }mapper.writeValueAsString(createMatePostRequest)→ createMatePostRequest를 JSON 형식의 문자열로 만들어준다.- 직렬화를 해주는 이유 : Kafka에서 통신을 하기 위해서는 Json에 형태로 보내야하기에 직렬화를 해주었다.
kafkaTemplate.send(topic, jsonInString)→ send 메소드를 이용하여 Kafka 서버로 토픽과 데이터를 보내주었다.
- 이렇게 되면 Kafka에서 해당 토픽을 구독하고 있는 Subscriber(=consumer) 서버를 찾아준다.
- Subscriber(=consumer) → 특정 Topic에서 메시지를 읽고 처리합니다. 지금 상황에서는 Title을 User 서비스에서 읽어야하므로 User 서비스가 Subscriber(=consumer)가 된다.
- KafkaConsumerConfig.java
@EnableKafka @Configuration public class KafkaConsumerConfig { @Bean public ConsumerFactory<String, String> consumerFactory() { Map<String, Object> properties = new HashMap<>(); properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka:9092"); properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroupId"); properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return new DefaultKafkaConsumerFactory<>(properties); } @Bean public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>(); kafkaListenerContainerFactory.setConsumerFactory(consumerFactory()); return kafkaListenerContainerFactory; } }ConsumerConfig.GROUP_ID_CONFIG→ Consumer Group을 식별하는 값이다.
- KafkaConsumer.java
@Service @Slf4j @RequiredArgsConstructor public class KafkaConsumer { private final UserJpaRepo userJpaRepo; @KafkaListener(topics = "user-topic") public void getTitle(String kafkaMessage) { log.info("Kafka Message: ->" + kafkaMessage); Map<Object, Object> map = new HashMap<>(); ObjectMapper mapper = new ObjectMapper(); try { map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {}); } catch (JsonProcessingException ex) { ex.printStackTrace(); } log.info("this is " + (String) map.get("title")); } }@KafkaListener(topics = "user-topic")→ Kafka에서 구독할 토익명을 적어준다.mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {})→ 첫 번째 매개변수인 kafkaMessage는 변환할 JSON 문자열입니다. 두 번째 매개변수인 TypeReference는 변환할 객체의 타입을 지정합니다.
서버에서 도커 이미지 내려받기
- 우리는 지금 받아야할 도커 이미지는 kafka, zookeeper가 있다.
- kafka docker image를 받기 위한 명령어는 밑과 같다.
- docker pull wurstmeister/kafka
- zookeeper docker image를 받기 위한 명령어는 밑과 같다.
- docker pull wurstmeister/zookeeper
docker-compose.yml 파일 작성하기
- docker-compose.yml
version: '3' services: ewm-user: container_name: ewm-user image: taeyun1215/ewm-user expose: - 8081 ports: - 8081:8081 environment: - EUREKA_SERVER=http://ewm-eureka:8761/eureka depends_on: - ewm-eureka - kafka - zookeeper ewm-mate: container_name: ewm-mate image: taeyun1215/ewm-mate expose: - 8082 ports: - 8082:8082 environment: - EUREKA_SERVER=http://ewm-eureka:8761/eureka depends_on: - ewm-eureka - kafka - zookeeper kafka: container_name: kafka image: wurstmeister/kafka ports: - 9092:9092 environment: KAFKA_ADVERTISED_HOST_NAME: kafka KAFKA_ADVERTISED_PORT: 9092 KAFKA_CREATE_TOPICS: "test:1:1" # Topic명:Partition개수:Replica개수 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 depends_on: - zookeeper zookeeper: container_name: zookeeper image: wurstmeister/zookeeper ports: - 2181:2181 ewm-apigateway: container_name: ewm-apigateway image: taeyun1215/ewm-apigateway ports: - 8000:8000 depends_on: - ewm-eureka environment: - EUREKA_SERVER=http://ewm-eureka:8761/eureka ewm-eureka: container_name: ewm-eureka image: taeyun1215/ewm-eureka ports: - 8761:8761 depends_on: - kafka - zookeeper- ewm-user, ewm-mate 도커 이미지는 이미 구축이 되어 있는 상태에서 시작하겠다.
- 단, depends_on에 kafka, zookeeper를 추가해주면 된다.
- kafka container
- ports는 default port인 9092로 하였다.
- environment(환경 설정)
- KAFKA_ADVERTISED_HOST_NAME, KAFKA_ADVERTISED_PORT → KafkaProducerConfig, KafkaConsumerConfig에서 두었던 ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG와 동일하게 매칭시켜주면 된다.
- KAFKA_CREATE_TOPICS → container가 실행될 때 토픽을 자동으로 생성해준다.
- KAFKA_ZOOKEEPER_CONNECT → zookeeper container와 연결하기 위함이다.
- zookeeper container
- ports는 default port인 2181로 하였다.
- ewm-user, ewm-mate 도커 이미지는 이미 구축이 되어 있는 상태에서 시작하겠다.
- docker-compose up -d로 백그라운드에서 실행시켜주면 된다.
통신 확인
- API는 API마다 다르겠지만, 지금 우리가 가정한것은 Mate → User 서비스로 통신을 해주기 위함으로 Mate 서비스에서 request를 날려줘야한다.
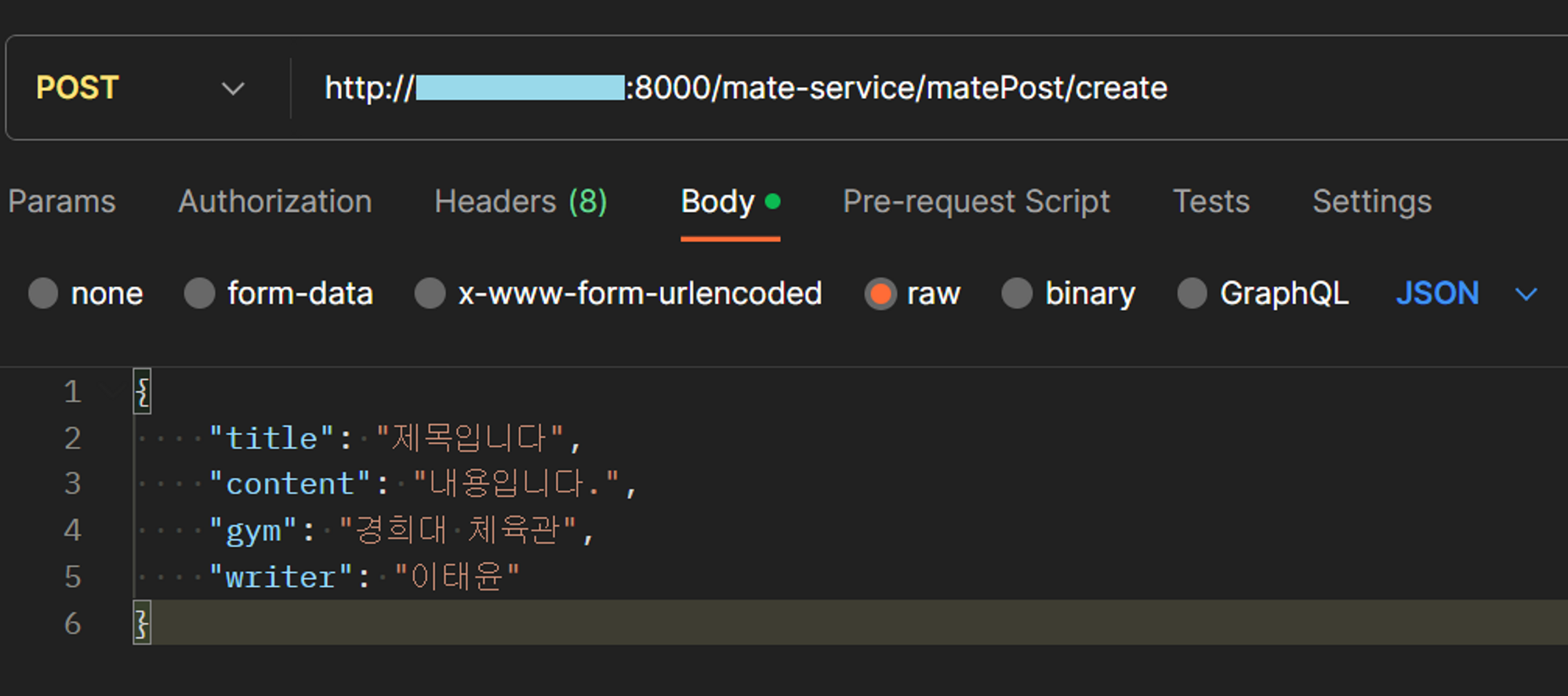
- request는 CreateMatePost 객체를 Json 형태로 만들어서 보낸 것 이다.
- 위와 같이 보냈다면 KafkaProducer.java에서 찍어둔 Log를 확인할 수 있다.

- 지금과 같이 Producer에서 보냈을 때 Topic을 Consumer에서 구독한 Topic과 동일하다면 Consumer에서 받게 될 것이다.
- 지금은 User 서비스에서 받게 될 것으로 User 서비스에 KafkaConsumer Log를 확인해보면 밑과 같다.

- Mate에서 보내준 CreateMatePost 객체를 User에서 그대로 받고 있다.
결론
후기
- 이로써 MSA 통신을 위한 Kafka를 붙였다.
- 처음에는 도메인별로 나눴을 때 다른 서비스에 도메인을 어떻게 접근해서 수정하지? 라는 생각이 컸는데 다 방법이 있었다.
- 그리고 더 찾아보니 Kafka를 이용해서 하나의 서비스에 여러 DB가 붙는 경우 데이터 동기화도 가능한 것으로 확인되었다.
- 이 부분은 추후에 서비스가 더 커지면 도입해 볼 예정
- Kafka를 붙여보긴 했지만 아직 이론적인 공부가 좀 더 필요할 것으로 판단이 된다.
- 기본적인건 이해하였지만 디테일하게 사용하려면 더욱 공부가 필요할듯 합니다…
궁금한 점
- Kafka에는 이미 Topic으로 구분을 하는데 KafkaConsumerConfig에서 GROUP_ID_CONFIG로 다시 나눠주는 이유가 무엇인지?
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "consumerGroupId");- 만약 user에 대한 도메인 서비스가 있고 스케일 아웃을 통해 user 서비스에 인스턴스를 2개 이상 실행하고 GROUP_ID_CONFIG에 대한 정보가 다 같다는 가정이라면, Kafka에서 동일한 GROUP_ID_CONFIG를 갖고 있으면 작업을 분담해서 처리를 시켜준다. 그리고 방금 말했던 것과 같이 스케일 아웃에 특화되어 있다.
- 하지만, 이미 저는 Springboot API-Gateway를 통해 스케일 아웃에 대한 인스턴스들을 로드밸런싱 해두어 굳이 필요 없다고 생각을 하였습니다.

지나가는 개발자