TimescaleDB란?
TimescaleDB는 PostgreSQL에 시계열 데이터를 지원한 RDBMS다.
Postgre에서 확장되었기에 당연하게 Postgre를 지원하는 모든 클라이언트, ORM을 지원하는 여러 코드에서 사용이 가능하다.
기존 RDBMS를 사용하고 있다면 기존의 SQL문을 재활용하면서 부담없이 Porting이 가능하다는 장점이 있다.
TimescaleDB 특징
특정 테이블이 TIMESTAMP 또는 DATE 타입의 필드를 포함할 경우, 시계열 테이블(time-series table)로 취급된다. (보다 전문적으로는 hypertable이라고 부르며 TimescaleDB의 핵심 개념이라고 할 수 있다.)
시계열 테이블에는 데이터 변경점이 발생할 때마다 시계열 필드를 기준으로 테이블을 여러 덩어리(chunked)로 쪼개는 최적화 작업을 백그라운드에서 자동으로 수행한다. 이를 통해 가장 최근의 덩어리에 해당하는 데이터와 인덱스가 메모리에 유지되어 대량의 데이터가 유입되어도 꾸준하게 빠른 성능의 CRUD를 보장한다.
한편, 백그라운드에서 내부 알고리즘의 판단에 의해 자동으로 특정 시일이 지난 덩어리를 압축한다. 이를 통해 최신 데이터의 유입 성능은 보장하면서(노드 1개 기준 초당 10만개 로우 유입 보장) 오래된 데이터를 압축하여 전체 스토리지 공간을 절약할 수 있다. (압축 기법을 통해 200TB 이상의 데이터를 16TB 크기에 담을 수 있다.)
TimescaleDB의 단점
PostgreSQL만큼 보편적이지 않다보니 클라이언트나 코드 레벨에서 네이티브하게 지원하지 않는다. 예를 들어 TimescaleDB에만 존재하는 시계열 필드 관련 Function의 실행은 가능하지만, 네이티브하게 알아듣지는 못한다. 코드 레벨에서 JPA의 경우 커스텀 Dialect 구현체를 직접 구현해야 한다.
InfluxDB vs TimescaleDB
시계열 데이터를 지원하긴 하나 근본적으로는 RDMBS이기 때문에 TSDB와 완전히 동일하지는 않다.
TSDB에서 유명한 InfluxDB와 성능비교를 하면 다음과 같다.
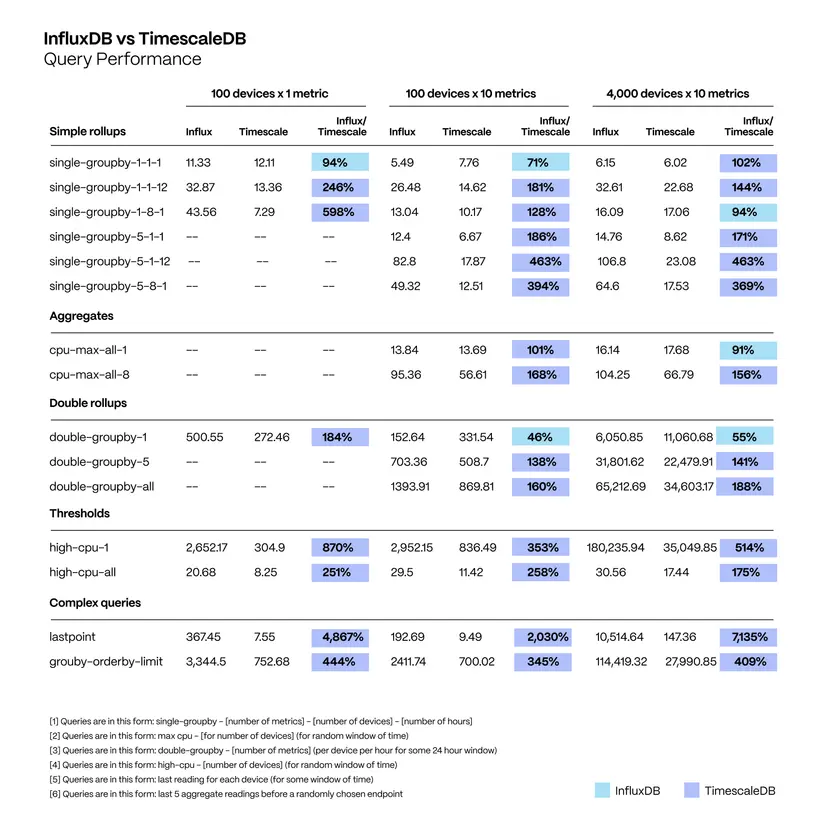
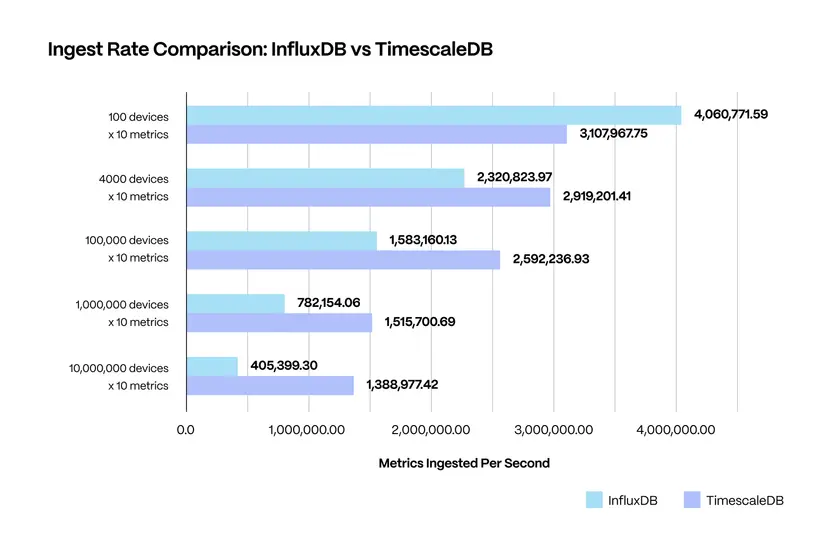
카디널리티(cardinality)가 낮은 경우 InfluxDB가 빠르나, 높은 경우 TimescaleDB가 더 빠른 경우를 보여주고 있다.
반대로 devices의 개수가 적고 metrics가 많은 경우(카디널리티가 낮은 경우) InfluxDB가 더 높은 퍼포먼스를 보인다는 것을 의미한다. InfluxDB에서는 2.6버전부터 스키마를 지원하여 카디널리티를 낮추기 위한 노력을 하고 있다.
HyperTable
Timescale DB는 시계열 데이터를 저장할 때 Hyper Table이라는 특수한 테이블에 저장한다.
CREATE TABLE korea_temperature (
time TIMESTAMPTZ NOT NULL,
name TEXT NOT NULL,
temperature DOUBLE PRECISION NULL
);SELECT create_hypertable('korea_temperature', 'time');위와 같이 테이블을 만들고 하이퍼 테이블로 변환시켜주는 식으로 하이퍼 테이블을 만들 수 있다.
이렇게 만들게 되면 time열을 기준으로 인덱스가 생성된다.
HyperTable 구조
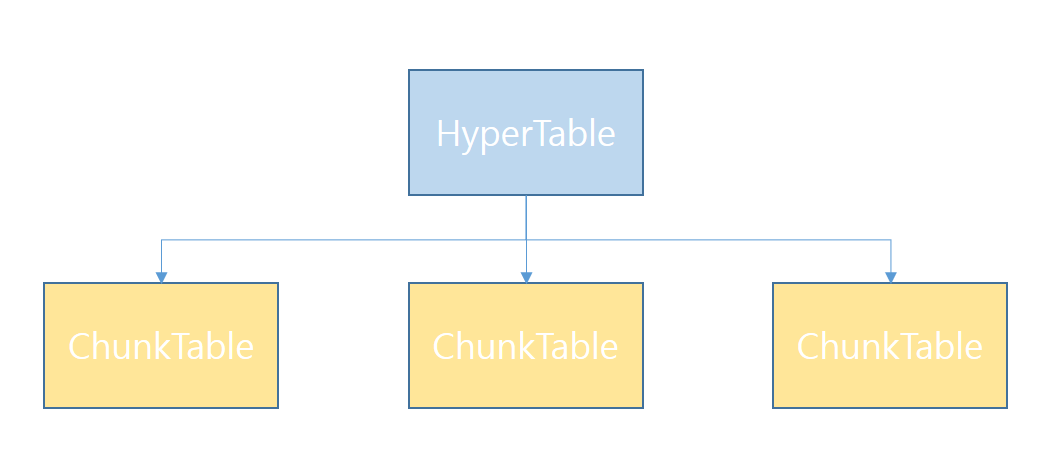
시계열 테이블 : Hyper Table(View) + Chunk Table (데이터 저장)
Chunk 테이블 : Hyper 테이블의 시간 컬럼 기준 파티션 테이블
Chunk
TimescaleDB에서 Hypertable이 내부적으로 데이터를 저장하는 단위.
Hypertable은 보통 하나의 큰 테이블처럼 보이지만, 실제로는 여러 개의 작은 파티션(Chunk) 으로 나뉘어 저장된다.
table 생성후 hypertable을 적용하면 chunk table이 생성된다.
chunk table을 따로 설정하지 않았다면 기본 주기는 7일이며, 7일 뒤에 새로운 chunk table을 생성한다.
table에 저장된 data를 가지고 있으며 chunk table 삭제 시 date들도 삭제된다.
결론
위 결과를 보아 device가 적거나 schema를 통해 카디널리티를 낮출 수 있는 확실한 도메인인 경우 InfluxDB, 조금 더 보편적이고 유동적인 도메인인 경우 TimescaleDB가 나은 선택지인 것 같다.
출처
