InfluxDB란?
Influx DB란 많은 쓰기 작업과 쿼리 부하를 처리하기 위해 2013년에 Go 언어로 개발된 오픈소스 Time Series Database(시계열 데이터베이스)이다.
Influx DB는 많은 TSDB들(Prometheus, TimescaleDB, Graphite, 등) 중에서 가장 유명하고, 많이 사용되는 데이터베이스이다. Influx DB는 Distributed, Scale horizontally하게 설계되어 새로운 노드만 추가하면 손쉽게 scale-out할 수 있으며, Restful API를 제공하고 있어 API 통신이 가능하다.
InfluxDB는 스키마가 없는(Schema-less) 구조를 지닌 DB다.
데이터 구조(Data organization)
Bucket
데이터를 저장하는 이름 있는 위치.
버킷은 데이터를 저장하는 가장 높은 수준의 그룹으로, 하나의 버킷에 여러 개의 Measurement가 포함될 수 있다.
예시: temperature_data, humidity_data, stock_prices
버킷은 데이터를 저장하는 논리적 컨테이너로, 실제로 데이터는 시계열로 기록된다.
Measurement
시간 시계열 데이터의 논리적인 그룹화. 동일한 태그를 공유하는 데이터들을 하나의 Measurement로 묶는다. 하나의 측정치는 하나의 특정 유형의 데이터를 저장하며, 모든 데이터 포인트는 동일한 태그를 가진다.
예시: temperature, humidity, cpu_usage
Tags
태그는 키-값 쌍 구조이다. 데이터를 구별하거나 필터링할 때 사용되며, 변경되지 않는 값들을 저장한다. 주로 데이터의 출처, 위치, 상태 등을 나타냄.
예시:
host: server01
location: korea
station: station_01
Fields
키-값 쌍으로 이루어진 필드는 주요 데이터 값을 저장하는 곳으로, 시간에 따라 계속 변화하는 값들이 기록됩니다.
temperature: 23.5
pressure: 101.3
stock_price: 150.75
Timestamp
모든 데이터는 타임스탬프와 함께 기록되며, 데이터는 시간 순서대로 정렬된다.
예시:
timestamp: 2024-02-25T10:00:00Z
timestamp: 2024-02-25T10:01:00Z
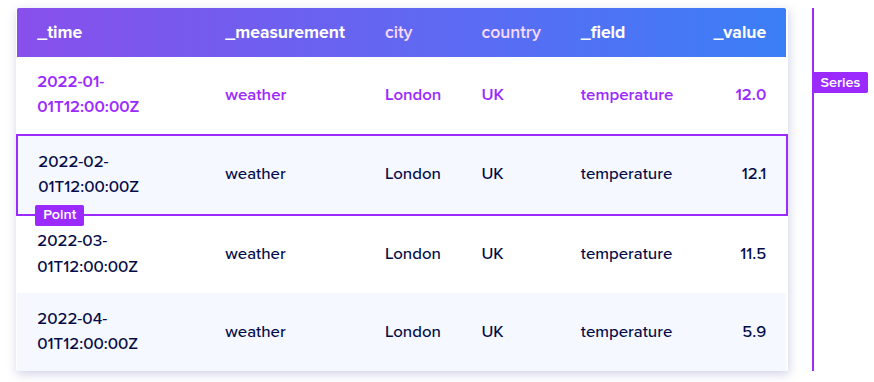
Point
단일 데이터 기록을 말하며, 각 포인트는 measurement, tag, field, timestamp에 의해 고유하게 식별된다.
Series
같은 measurement, tag key, tag value를 들고 있는 point의 그룹.
데이터 조회
| time | location | temperature humidity |
|---|---|---|
| 2024-02-26T12:00:00Z | Seoul | 10.5 |
| 2024-02-26T13:00:00Z | Seoul | 12.0 |
| 2024-02-26T14:00:00Z | Seoul | 13.2 |
| 2024-02-26T12:00:00Z | Busan | 15.0 |
| 2024-02-26T13:00:00Z | Busan | 16.5 |
위와 같은 데이터가 있다고 치자.
SQL문과 비슷한 InfluxQL가 있고 InfluxDB의 자체 언어인 Flux가 있다.
2.x 버전부턴 Flux를 통해 더 많은 기능을 수행할 수 있으므로, Flux를 기준으로 설명하겠다.
from(bucket: "sensor_data")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "temperature_measurements")
|> filter(fn: (r) => r.location == "Seoul")