시계열 데이터(TSD, Time Series Data) 란?
Time-Stamped Data라고도 불리는 Time Series Data(시계열 데이터)는 시간에 따라 저장된 데이터를 의미한다. 시계열 데이터들은 동일한 소스로부터 시간이 지남에 따라 만들어진 데이터들로 구성되므로 시간 경과에 따른 변화를 추적하는데 용이하다.
시계열 데이터베이스(TSDB, Time Series Database) 란?
시계열 데이터베이스(TSDB, Time Series Database)란 시계열 데이터를 처리하기 위해 최적화된 데이터베이스로써 빠르고 정확하게 실시간으로 쌓이는 대규모 데이터들을 처리할 수 있도록 고안되었다.
TSDB는 데이터들과 시간이 함께 저장하는데, 이를 통해 시간의 흐름에 따라 데이터를 분석하기에 매우 용이하다. 따라서 모니터링, 주식 트래킹 시스템에서 주로 사용된다. 과거의 데이터를 시간과 함께 기록용으로 저장하므로 주된 작업은 INSERT와 DELETE이며 UPDATE가 아니다.
TSDB의 장점
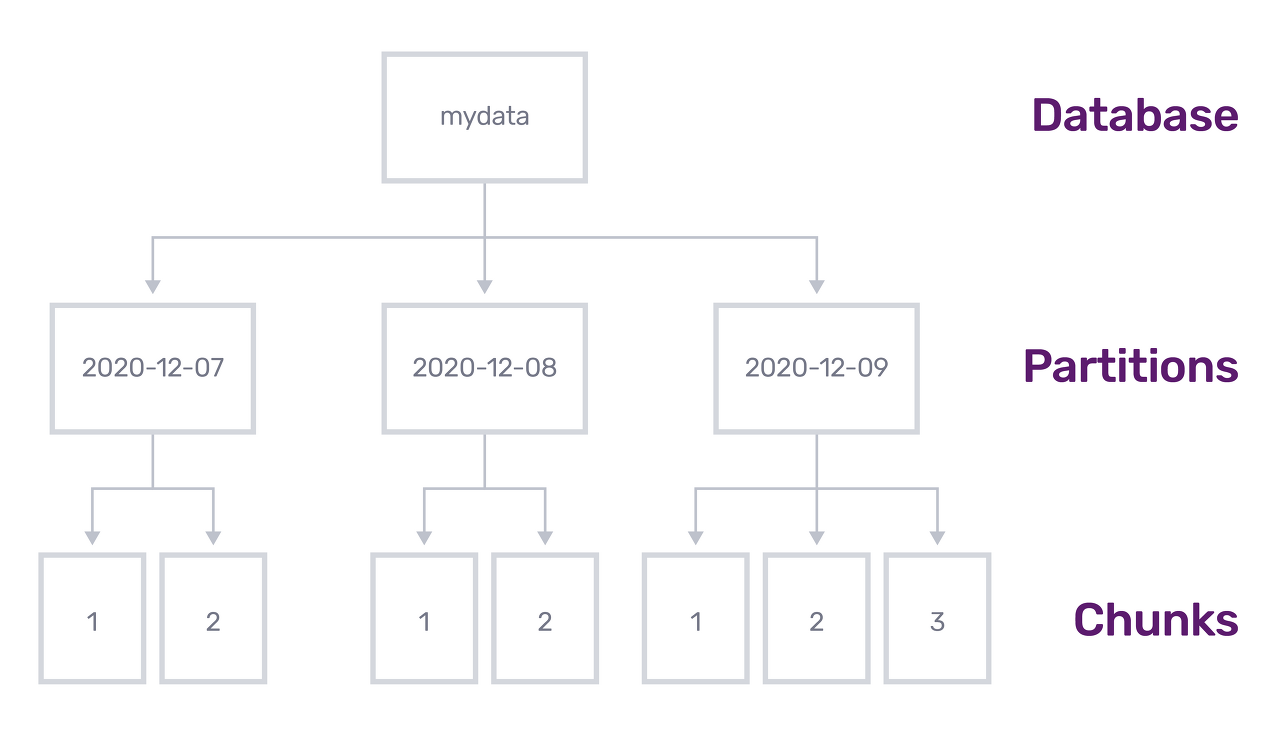
시간을 기반으로 하는 저장 공간
시계열 데이터베이스는 기존의 다른 데이터베이스들과 차별이 되는 핵심적인 아키텍처 디자인 특징이 있는데, 그것은 바로 time-stamp를 기반( timestamp = index )으로 하는 저장소를 가지고 있다는 것이다. 이를 통해 데이터를 압축하고 요약하는 등의 작업을 진행하여 대규모의 시간 기반 데이터들을 다룰 수 있고, min,sec 등 시간을 기반으로 하는 쿼리를 효율적으로 사용 가능하게 한다.
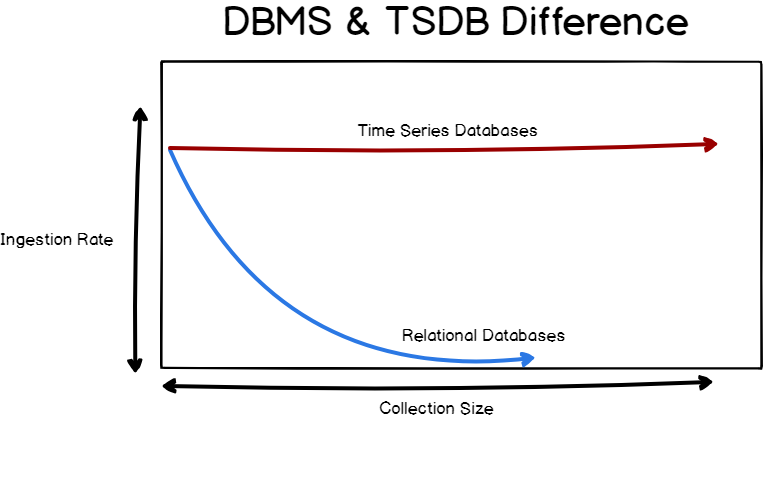
빠른 처리 속도
TSDB는 빠르고 효율적인 방법으로 데이터를 수집하기 위해 만들어졌다. 물론 RDB도 빠르지만 데이터의 양이 증가함에 따라 성능이 급격하게 느려지는 경향이 있다. 특히 테이블에 인덱싱이 걸려있다면 인덱싱의 재정렬 등에 의해 퍼포먼스는 점점 더 떨어지게 된다.
반면에 TSDB에서의 인덱스는 시간에 따라 축적된 데이터들에 최적화되었기 때문에, 시간이 지나도 데이터를 수집하는 속도가 느려지지 않고 빠른 처리 속도를 보여준다.
다양한 자동화된 기능 제공
TSDB에는 시간에 따라 변화되는 데이터들을 저장하므로 데이터의 양이 상당히 많으며, 시간에 따른 데이터의 요약 또는 통계 등과 같은 작업이 흔히 요구된다. 예를 들어 회사의 주가가 지난 6개월 대비 몇 퍼센트 데이터가 증가하였는지 등과 같은 것들이다.
TSDB는 이렇게 특정 주기마다 자동으로 데이터들을 처리하는 기능(InfluxDB의 Continous Query, 연속적인 쿼리)이나 오래된 데이터를 자동으로 삭제하도록 도와주는 기능(InfluxDB의 Retention Policy, 보존 정책) 등을 제공함으로써 편리성을 제공하고 있다.
낮은 스토리지 사용량
TSDB는 데이터 압축 및 데이터 집계(Aggregation) 등의 기술을 활용하여 시계열 데이터를 저장하는 데 필요한 Storage를 줄인다.
높은 쓰기 처리량 지원
TSDB(시계열 데이터베이스)는 대용량 쓰기 처리량(Write throughput)에 최적화되어 있어, 실시간으로 생성되는 대량의 시계열 데이터를 효율적으로 처리할 수 있다.
데이터 수집(Data Ingestion)
TSDB는 센서, 애플리케이션, 로그 파일 등 다양한 소스로부터 시계열 데이터를 수집한다.
데이터는 배치(batch) 또는 스트림(stream) 형태로 TCP, UDP 등의 네트워크 프로토콜을 통해 전송된다.
수집된 데이터는 유효성 검사(Validation), 파싱(Parsing), 태깅(Tagging) 등의 처리를 거쳐 효율적으로 색인(Indexing) 및 조회(Querying)될 수 있도록 한다.
열 지향 데이터 모델(Columnar Data Model)
TSDB는 열 지향(Columnar) 데이터 모델을 사용하며, 각 열(column)이 하나의 시계열(time series) 또는 메트릭(metric)을 나타낸다.
데이터는 검증(Validation) 및 파싱(Parsing) 후, 압축된 열 형식(Compressed Columnar Format)으로 저장되어 저장 효율과 검색 성능이 최적화된다.
효율적인 데이터 저장(Efficient Data Storage)
TSDB의 스토리지 엔진(Storage Engine)은 메모리(In-memory)와 디스크(Disk-based Storage)를 조합하여 성능과 저장 효율을 균형 있게 유지한다.
델타 인코딩(Delta Encoding), 런-렝스 인코딩(Run-Length Encoding) 등의 압축 기법을 적용하여 저장 공간을 최적화한다.
색인(Indexing)
TSDB는 대량의 데이터셋을 빠르게 조회할 수 있도록 색인(Indexing) 기능을 제공한다.
시간 기반 색인(Time-based Indexing): 데이터를 타임스탬프(Timestamp)를 기준으로 정렬 및 검색.
태그 기반 색인(Tag-based Indexing): 데이터를 디바이스명(Device Name), 위치(Location), 기타 메타데이터(Metadata) 등의 태그를 기준으로 정렬.
메타데이터 색인(Metadata Indexing): 데이터에 대한 추가적인 컨텍스트(Context)를 제공.
SQL과 유사한 쿼리(SQL-like Querying)
대부분의 TSDB는 SQL과 유사한 쿼리 언어(Query Language)를 지원한다.
주로 집계(Aggregation), 롤업(Rollup), 시간 기반 윈도우(Time-windowed queries) 등의 복잡한 분석 쿼리를 수행할 수 있다.
색인(Indexing)된 데이터를 활용하여 빠르게 원하는 정보를 검색할 수 있다.
데이터 보존(Data Retention)
TSDB는 시계열 데이터를 장기간 저장할 수 있도록 설계되었다.
데이터 보존 정책(Data Retention Policy)을 설정하여 일정 기간이 지나면 데이터 삭제 또는 보관(Archiving) 가능.
일부 TSDB는 데이터 압축(Compression) 및 다운샘플링(Downsampling) 기능을 제공하여 장기 보존에 필요한 저장 공간을 최적화한다.
확장성(Scalability)
TSDB는 대량의 시계열 데이터를 처리할 수 있도록 수평 확장(Scale-out) 기능을 지원한다.
대부분의 TSDB는 분산 아키텍처(Distributed Architecture)를 갖추고 있어 데이터가 증가하면 노드를 추가하여 확장 가능.
일부 TSDB는 샤딩(Sharding) 기술을 지원하여 데이터를 여러 노드에 분할하여 저장하고 처리 성능을 향상시킨다.
TSDB의 단점
상대적으로 어려운 난이도
TSDB는 retention 기간, Tag 설정 등 setup과 maintain을 위한 더 많은 설정을 요구한다.
TSDB는 특성상 대용량의 데이터가 빠르게 기록되기에 적절한 retention 기간을 설정하지 않으면,
디스크에 매우 많은 부담이 간다. 반대로 너무 적게 설정하면 조회할 때 데이터가 없는 경우가 발생한다. 즉 이러한 설정은 곧 성능과 직결되기에 관계형 DB나 NoSQL DB에 비해 상대적으로 난이도가 어렵다.
특정 도메인에서만 사용 가능한 구조
TSDB는 timestamp를 기반으로 데이터를 저장하기에 앞서 말한 TSD(시계열 데이터)와 무관한 데이터라면 오히려 도입하는게 비효율적일 수 있다.
트랜잭션 및 동시성 부족
TSDB는 ACID를 지원하지 않거나 제한적으로 지원한다. 따라서 여러 클라이언트가 동시에 데이터를 조작할 경우 정합성에 문제가 발생할 수 있다. 따라서 트랜잭션이 필요한 경우 RDBMS와 섞어 하이브리드 방식으로 사용하는 것을 권장한다.
수정과 삭제가 제한적임
TSDB는 RDB와 다르게 수정과 삭제가 불가능(Immutable)하거나 제한적이다.
예를 들어 InfluxDB 같은 경우 field 기준으로 데이터를 삭제할 수 없다.
수정 같은 경우는 새로운 최신의 데이터를 하나 더 삽입하여 덮어쓰는 방식으로 해결한다.
따라서 실시간으로 데이터가 변해야 하는 도메인에서는 적절하지 않은 선택일 수 있다.
TSDB의 주요 스키마 개념
Measurement (측정값)
TSDB에서 가장 중요한 개념으로, 수집하려는 특정 데이터 유형을 의미함.
관계형 DB(RDBMS)에서의 테이블(Table) 개념과 유사하지만, TSDB에서는 시계열 데이터를 저장하는 단위임.
temperature → 온도 데이터 저장
cpu_usage → CPU 사용률 저장
humidity → 습도 데이터 저장
Tags (태그)
데이터를 분류하거나 필터링하는 데 사용되는 메타데이터.
RDB에서의 컬럼(Column) 개념과 비슷하지만, 태그는 색인(Index) 기능을 하여 빠른 조회를 가능하게 함.
태그 값은 변하지 않는 정적인 값이어야 함.
location = "Seoul" → 데이터가 서울에서 수집되었음을 나타냄
sensor_type = "DHT22" → 특정 센서 유형을 구분
server = "web01" → 웹 서버의 이름
Fields (필드)
실제 측정된 데이터 값을 저장하는 곳.
RDB에서의 컬럼(Column)과 유사하지만 색인이 적용되지 않음.
필드 값은 지속적으로 변경될 수 있음.
temperature = 23.5 (온도 데이터)
cpu_usage = 75.3 (CPU 사용률)
humidity = 65.2 (습도 데이터)
Timestamp (타임스탬프)
데이터가 기록된 시간 정보를 의미함.
TSDB에서는 모든 데이터가 타임스탬프를 기반으로 정렬되고 조회됨.
ISO 8601 형식 (YYYY-MM-DD HH:MM:SS) 또는 UNIX 타임스탬프(초/밀리초)로 저장됨.
2025-02-25T14:30:00Z (ISO 8601)
1708866600 (UNIX timestamp)
Retention Policy (데이터 보존 정책)
데이터를 얼마나 오래 보관할지 결정하는 정책.
일정 시간이 지나면 데이터를 자동으로 삭제하여 저장 공간을 절약함.
7d → 7일간 데이터 보관 후 삭제
30d → 30일간 데이터 유지 후 삭제
INF → 데이터를 영구 보관
TSDB 예제 (InfluxDB 기준)
다음은 temperature 데이터를 저장하는 TSDB의 예제이다.
InfluxDB는 스키마를 정의하지 않고 데이터를 삽입할 수 있다.(Schema-less)
INSERT INTO temperature,location=Seoul,sensor=DHT22 value=23.5 1708866600
INSERT INTO temperature,location=Busan,sensor=DHT22 value=22.8 1708866660| Time (타임스탬프) | Measurement (측정값) | Tags (태그) | Fields (필드) |
|---|---|---|---|
| 2025-02-25T14:30:00Z | temperature location=Seoul | sensor=DHT22 | value=23.5 |
| 2025-02-25T14:31:00Z | temperature location=Busan | sensor=DHT22 | value=22.8 |
출처
https://mangkyu.tistory.com/188
https://medium.com/@vinciabhinav7/time-series-database-fdb2881027fc
https://medium.com/@vinciabhinav7/whats-tsdb-part-2-concepts-and-example-ce12a4c8be9f
