블로그 내용에 관해 수정할 사항이나 논의할 사항이 있다면 언제든 연락 부탁드립니다.
LinkedIn : devyulbae
Email : devyulbae@gmail.com
목차
0. 개론
1. RAG란?
1-1. RAG
1-2. Retriever - RAG의 꽃
1-3. Augmented
1-4. Generate
1-5. 외부 데이터 의존성2. Vector RAG vs Graph RAG
2-1. Vector RAG
2-2. Graph RAG
2-3. 무엇을 사용해야 하는가
0. 개론
오늘은 기존에 많이 사용되는 Vector RAG와 새로 발전하고 있는 Graph RAG를 간략하게 소개하고, 언제 어떤 것을 사용해야 하는지 장단점을 비교해보고자 합니다. RAG를 새로 도입하려는 분들이 이 글을 통해 본인의 상황에서 어떤 RAG를 사용하는 것이 적절할지 알아가시면 좋겠네요.
각 RAG의 자세한 글은 따로 포스팅을 할 예정입니다.
1. RAG란?
1-1. RAG의 정의와 목적
RAG(Retiever Augmented Generation)는 대규모 언어 모델(LLM)의 한계를 극복하기 위해 설계된 기술로, 외부 데이터를 검색(Retirever)하고 참조(Augmented)하여 생성(Generate)하는 매커니즘입니다. LLM은 훈련 Data 내에 있는 정보를 바탕으로 응답을 생성하지만, 학습이 되어 있지 않은 지협적인 정보에 대해서는 생성이 불가능하며,환각 증상(Hallucination)이 일어나기도 합니다.

이런 두 가지 문제를 한 번에 해결해주는 것이 RAG입니다. 기존 LLM의 환각(Hallucination) 발생률은 약 15~20%이며, 이는 훈련된 데이터에 포함되지 않은 정보에 대해 부정확하거나 근거 없는 답변을 생성하는 경우에 해당합니다. RAG를 도입하면 이러한 문제를 효과적으로 완화할 수 있습니다. Vector 기반 RAG는 환각 발생률을 약 3%로 줄이는 반면, Graph 기반 RAG는 약 1%로 더욱 낮출 수 있습니다. 이를 통해 LLM의 신뢰성과 정확성이 크게 향상됩니다.
1-2. Retriever - RAG의 꽃
1-2. Retriever - RAG의 꽃
Retriever는 외부 데이터에서 관련 정보를 검색하는 역할을 담당하며, RAG에서 가장 핵심적이면서도 어려운 요소로 꼽힙니다. 먼저, 대규모 데이터를 처리하는 과정에서 검색 속도와 정확성 간의 균형을 맞추는 것은 큰 도전 과제입니다. 데이터가 방대해질수록 검색 속도가 느려질 가능성이 있지만, 정확성을 유지하는 동시에 속도를 확보해야만 효과적인 검색이 가능합니다.
또한, 사용자의 질문이 복잡하거나 구체적인 요구를 포함할 경우, Retriever가 질문의 컨텍스트를 제대로 이해하지 못할 가능성이 존재합니다. 이는 단순히 키워드 일치에 의존하기보다는 질문의 의도를 파악하고 관련된 데이터를 검색할 수 있는 능력을 요구합니다.
마지막으로, 검색된 데이터가 LLM의 응답 생성 과정에 자연스럽게 통합되어야 합니다. 통합 과정이 매끄럽지 않을 경우, 모델이 생성하는 답변의 품질이 떨어질 수 있습니다. 따라서 Retriever 단계에서 검색된 결과가 LLM이 이해하고 활용하기 적합한 형식으로 전달되는 것이 중요합니다.
1-3. Augmented
RAG의 A인 Augmented는 Retriever에서 도출된 데이터를 LLM에게 참조시키는 과정입니다. 외부의 지식 베이스나 실시간 데이터를 활용하여 LLM에게 지식을 증가시키므로 Knowledge Injection이라고도 하는데, 이를 통해서 LLM은 특정 도메인에 대한 전문성과, 최신 정보의 업데이트, 그리고 모델의 응답 범위 증가의 효과를 얻을 수 있습니다.
1-4. Generate
Generate는 Augmented된 데이터를 바탕으로 LLM이 답변을 생성하는 과정입니다. 이 단계에서 프롬프팅을 통해서 답변을 상세하게 조절할 수 있고, 따라서 LLM의 성능에 가장 영향을 많이 받습니다. 또한, 사용자에게 직접적으로 전달되는 최종 output이기 때문에 원하는 답변을 생성하기 위해서 Fine-Tuning을 통해 학습시키기도 합니다.
1-5. 외부 데이터 의존성 조절
RAG를 적용할 때의 주요 주의사항 중 하나는, LLM이 참조된 외부 데이터에 과도하게 의존하는 것입니다. 이에 대한 대책은 RAG의 여러 단계에서 이루어질 수 있습니다:
- Retriever 단계: 참조할 데이터의 개수와 검색 범위를 조정하여 필요 이상의 데이터를 가져오지 않도록 제어합니다.
- Augmented 단계: 검색된 데이터의 중요도에 가중치를 부여하거나, 필터링을 통해 LLM이 적절한 정보를 참조하도록 설정합니다.
- Generate 단계: 프롬프트 설계와 내부 지식을 강조하여 외부 데이터가 보조적 역할을 하도록 답변 생성 방식을 조율합니다.
2. Vector RAG vs Graph RAG
2-1. Vector RAG
Vector RAG는 벡터 임베딩과 벡터 검색 기술을 활용하여 정보를 검색하고, 이를 바탕으로 LLM이 답변을 생성하는 방식입니다. 먼저 문서나 데이터를 고차원 벡터로 변환한 뒤, 사용자의 질문도 벡터화하여 벡터 공간에서 가장 유사한 항목을 검색합니다. 이는 대규모 데이터 환경에서도 빠르고 효율적인 검색이 가능하도록 돕습니다.
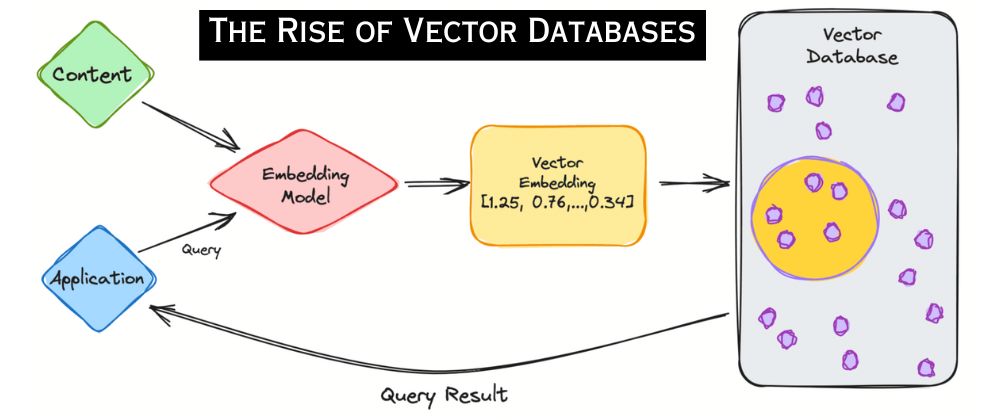
Vector RAG는 데이터가 자주 변경되거나 추가되는 환경에서 특히 유리합니다. 데이터의 유연한 추가와 삭제가 가능하며, 구조화되지 않은 데이터도 효과적으로 처리할 수 있습니다. 그러나 벡터화 과정에서 문맥이 일부 상실될 수 있으며, 대규모 데이터에 대해 상당한 메모리가 필요하다는 한계가 있습니다.
FAQ 봇, 기술 문서 검색, 의료 정보 시스템과 같은 단순 정보 검색 및 빠른 응답이 중요한 응용 사례에서 Vector RAG가 널리 사용됩니다.
먼저 문서나 데이터를 고차원 벡터로 변환한 뒤, 사용자의 질문도 벡터화하여 벡터 공간에서 가장 유사한 항목을 검색합니다. 이는 대규모 데이터 환경에서도 빠르고 효율적인 검색이 가능하도록 돕습니다.
Vector RAG는 데이터가 자주 변경되거나 추가되는 환경에서 특히 유리합니다. 데이터의 유연한 추가와 삭제가 가능하며, 구조화되지 않은 데이터도 효과적으로 처리할 수 있습니다. 그러나 벡터화 과정에서 문맥이 일부 상실될 수 있으며, 대규모 데이터에 대해 상당한 메모리가 필요하다는 한계가 있습니다.
FAQ 봇, 기술 문서 검색, 의료 정보 시스템과 같은 단순 정보 검색 및 빠른 응답이 중요한 응용 사례에서 Vector RAG가 널리 사용됩니다.
장점:
- 유연성, 확장성
단점:
- 문맥 상실 가능성, 메모리 사용량
활용 사례:
- FAQ 봇, 기술 문서 검색, 의료 정보 시스템
2-2. Graph RAG
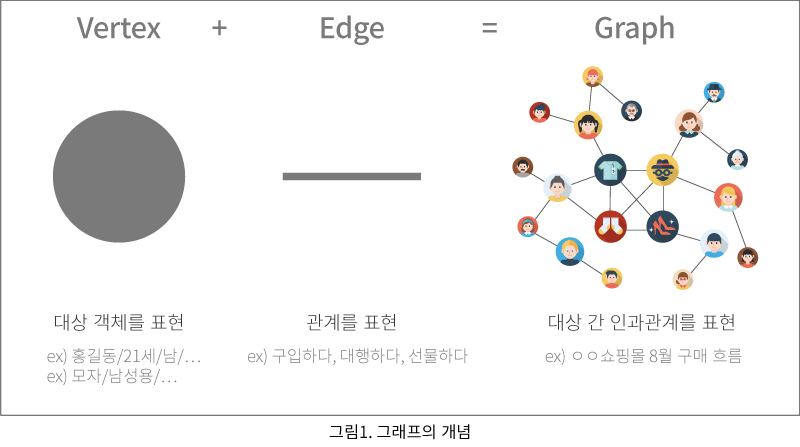
Graph RAG는 그래프 구조를 활용하여 정보를 저장하고 검색하는 방식입니다. 데이터 항목은 노드(Node)로, 노드 간의 관계는 엣지(Edge)로 표현됩니다. 이를 통해 데이터 간의 복잡한 연결성을 유지하고 관계 기반의 검색과 분석이 가능합니다.
Graph RAG는 데이터 간의 관계를 중요시하는 환경에서 유리합니다. 예를 들어, 추천 시스템에서는 사용자의 선호도를 기반으로 최적의 결과를 도출하며, 네트워크 분석에서는 복잡한 연결망에서 중요한 노드와 관계를 파악할 수 있습니다. 다만, 초기 설정이 복잡하고 데이터 규모가 커질수록 성능 저하 가능성이 있다는 점에서 신중한 설계가 요구됩니다.
의료 지식 그래프, 추천 시스템, 소셜 네트워크 분석과 같이 도메인 지식이 중요하고 복잡한 관계를 분석해야 하는 응용에서 Graph RAG가 활용됩니다.
장점:
- 관계 표현, 맥락 보존, 특정 도메인 최적화
단점:
- 구현 난이도, 속도
활용 사례:
- 추천 시스템, 네트워크 분석, 도메인 지식 응용
2-3. 무엇을 사용해야 하는가
Vector RAG와 Graph RAG 비교:
| 측면 | Vector RAG | Graph RAG |
|---|---|---|
| 성능 | 빠른 검색 및 높은 확장성 | 관계 기반의 심층적 분석 가능 |
| 적합성 | 단순 정보 검색 | 복잡한 관계 분석 |
| 유연성 | 자주 변경되거나 추가되는 데이터에 유리 | 고정적이고 구조화된 데이터에 유리 |
| 환각 발생률 | 약 3% | 약 1% |
| 활용 분야 | 기술 문서, FAQ 봇 | 추천 시스템, 네트워크 분석 |
상황별 선택 가이드:
단순 질의응답과 같은 비교적 간단한 정보 검색이 필요한 경우에는 Vector RAG가 적합합니다. 이는 Vector RAG가 대규모 데이터에서 효율적으로 검색을 수행하며, 빠른 응답 속도를 제공하기 때문입니다. 데이터가 자주 추가되거나 변경되는 환경에서도 Vector RAG는 뛰어난 유연성을 발휘하여 새로운 데이터를 쉽게 통합할 수 있습니다.
반면에, 데이터 간의 복잡한 관계를 분석해야 하는 경우에는 Graph RAG가 더 효과적입니다. Graph RAG는 데이터 간의 연결성과 맥락을 유지하면서 심층적인 관계 분석을 가능하게 합니다. 이러한 특성 덕분에 추천 시스템이나 네트워크 분석과 같은 복잡한 도메인 문제를 해결하는 데 적합합니다.
결론적으로, Vector RAG와 Graph RAG의 선택은 사용 사례의 특성과 데이터 요구 사항에 따라 결정되어야 합니다. 적절한 방식을 선택함으로써 각 RAG가 가진 강점을 최대한 활용할 수 있으며, 이를 통해 데이터 활용의 효율성과 정확성을 극대화할 수 있습니다.
예제
Retriever 예제
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
# 벡터 스토어 및 임베딩 초기화
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = Chroma(persist_directory="./chroma_db", embedding_function=embedding_model)
# 쿼리를 기반으로 가장 관련 있는 문서 검색
query = "How do I optimize LLM inference?"
retrieved_docs = vector_store.similarity_search(query, k=3)
# 검색된 문서 출력
for doc in retrieved_docs:
print(doc.page_content)Augmented 예제
def augment_query_with_context(query, retrieved_docs):
# 검색된 문서를 텍스트로 결합
context = "\n".join([doc.page_content for doc in retrieved_docs])
# 확장된 입력 생성
augmented_input = f"Context:\n{context}\n\nQuery:\n{query}"
return augmented_input
# Augmented Query 생성
augmented_query = augment_query_with_context(query, retrieved_docs)
print(augmented_query)Generate 예제
from langchain.llms import OpenAI
# OpenAI LLM 초기화
llm = OpenAI(model="text-davinci-003", temperature=0.5)
# 생성 모델로 응답 생성
response = llm(augmented_query)
print("Generated Response:")
print(response)