해당 포스팅은 How Browsers Work: Behind the scenes of modern web browsers을 번역, 의역, 구성 재배치, 첨언한 것입니다.
오역은 댓글로 남겨주시면 감사하겠습니다.
1. Introduction
웹 브라우저는 가장 널리 쓰이는 소프트웨어입니다. 이 글은 웹 브라우저들이 뒷단에서 어떻게 작동하는지 설명합니다. 브라우저의 주소창에 google.com이라고 타이핑하고 브라우저 화면에 구글 페이지가 나타나기 전까지 어떤 일이 일어나는지 말이죠.
1-1. The browsers we will talk about
오늘날 데스크탑과 모바일에서 많은 브라우저들이 사용됩니다.
2013년 6월 통계에 따르면 오픈 소스 브라우저인 Firefox, Chrome, Safari(부분적으로 오픈 소스)는 전 세계 데스크탑 브라우저 사용률의 71%를 차지합니다.
1-2. The browser's main functionality
브라우저의 주요 기능은 유저가 선택한 리소스를 제공하는 것입니다.
서버에 리소스를 요청하고 브라우저 윈도우에 리소스를 보여줌으로써 말이죠.
여기서 말하는 리소스는 보통 HTML 문서를 뜻하지만 PDF나 이미지 등 다른 컨텐츠들도 가능합니다. 리소스의 위치는 URI (Uniform Resource Identifier)에 의해 명시됩니다.
브라우저가 HTML 파일들을 해석하고 보여주는 방법은 HTML, CSS specification에 의해 명시됩니다. 이 specificatin은 웹 표준 기관인 W3C (World Wide Web Consortium)가 관리합니다. 과거에는 브라우저들이 specification의 일부만 따르고 독자적으로 확장해서 호환성 문제를 야기했습니다. 하지만 오늘날에는 대부분의 브라우저들이 specification을 따릅니다.
브라우저의 유저 인터페이스는 서로 닮아있습니다. 대부분의 유저 인터페이스 요소들은 다음과 같습니다.
- URI를 입력할 수 있는 주소창
- 이전 버튼, 다음 버튼
- 북마크
- 새로고침 버튼, 정지 버튼
- 홈 버튼
1-3. The browser's high level structure
브라우저의 기본 구성요소는 다음과 같습니다.
- The user interface
주소창, 이전 버튼, 다음 버튼, 북마크 등을 포함합니다.
유저가 요청한 페이지를 보여주는 윈도우를 제외한 브라우저의 모든 요소들입니다. - The browser engine
user interface와 rendering engine 사이의 동작을 제어합니다. - The rendering engine
요청한 컨텐츠를 보여줍니다. 예를 들어, 유저가 HTML을 요청했다면 HTML과 CSS를 파싱하고 파싱된 컨텐츠를 스크린을 통해 보여줍니다. - Networking
HTTP 요청과 같은 통신(network call)에 필요합니다.
플랫폼 별로 각기 다른 수행이 일어나며 플랫폼과 독립적인 인터페이스입니다. 각 플랫폼 하부에서 실행됩니다. - UI backend
기본적인 장치들을 그리기 위해 사용됩니다. - JavaScript interpreter
JavaScript 코드를 파싱하고 실행하기 위해 사용됩니다. - Data storage
말 그대로 데이터를 저장하는 레이어입니다. 브라우저는 데이터를 하드디스크에 저장할 필요가 있습니다. 쿠키처럼요.
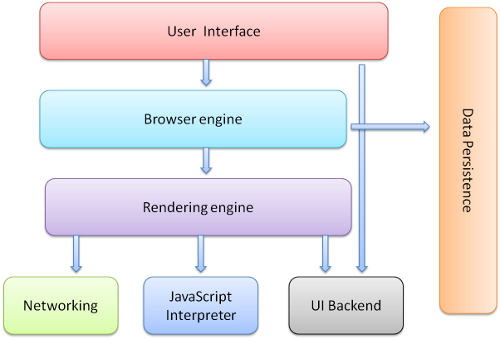
Chrome 같은 브라우저들은 각 탭마다 별도의 렌더링 엔진 인스턴스를 유지합니다. 각 탭마다 각각의 프로세스를 실행시킵니다.
2. The rendering engine
렌더링 엔진의 역할은 렌더링입니다.
렌더링이란 요청된 컨텐츠들을 브라우저 화면에 표시하는 것을 말합니다.
렌더링 엔진은 기본적으로 HTML 및 XML 문서와 이미지를 표시할 수 있습니다. 그리고 plug-in이나 확장기능을 통해 다른 타입의 데이터들도 표시할 수 있습니다. 예를 들면, PDF Viewer Plug-in을 이용해 PDF를 표시할 수 있습니다.
2-1. Rendering engines
브라우저들은 각기 다른 렌더링 엔진을 사용합니다.
| browser | rendering engine |
|---|---|
| Internet Explorer | Trident |
| Firefox | Gecko |
| Safari | Webkit |
| Chrome, Opera | Blink (a fork of Webkit) |
Webkit은 오픈 소스 렌더링 엔진입니다. Webkit은 처음엔 Linux 플랫폼에서 사용되기 위해 개발되었지만 추후에 Apple이 Mac과 Windows를 지원하기 위해 이 Webkit을 수정했습니다.
2-2. The main flow
렌더링 엔진은 networking layer에서 요청된 문서의 컨텐츠들을 가져오면서 시작합니다. 이는 8kB 단위로 이루어집니다.
다음은 렌더링 엔진의 기본 흐름입니다.

렌더링 엔진은 HTML 문서를 파싱하고 element들을 DOM 노드로 변환합니다. 이 변환은 "컨텐츠 트리"라는 트리 안에서 일어납니다. 그리고 나서 렌더링 엔진은 스타일 데이터 (외부 CSS파일과 스타일 element)를 파싱합니다. 스타일 정보는 "렌더 트리"라는 또 다른 트리를 생성합니다.
렌더 트리는 색상, 크기같은 시작적 속성이 있는 사각형들을 포함합니다. 사각형들은 순서대로 화면에 표시됩니다.
렌더 트리를 생성한 뒤, "레이아웃" 프로세스를 거칩니다. 이는 각 노드에 화면에 표시 될 정확한 좌표를 제공한다는 의미입니다. 다음 단계는 페인팅입니다. 렌더 트리를 순회하며 각 노드들이 그려지는 과정이며 이 과정에서 UI 백엔드 레이어를 사용합니다.
렌더링 엔진의 흐름들이 점진적인 과정이라는 것을 이해하는 것은 매우 중요합니다. 더 나은 사용자 경험을 위해 렌더링 엔진은 가능한 빨리 컨텐츠들을 스크린에 표시하기 위해 노력합니다. HTML 문서를 모두 파싱하고 렌더 트리를 만들고 레이아웃 프로세스를 거치는 것이 아니라 네트워크로 부터 나머지 내용이 전송되기를 기다리면서 컨텐츠의 일부를 파싱하고 화면에 표시합니다.
2-3. Main flow Examples
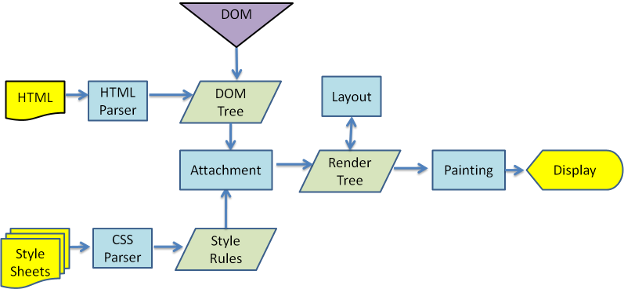
위 그림은 Webkit의 main flow 입니다. Safari, Chrome, Opera의 렌더링 엔진이 Webkit에 해당합니다.
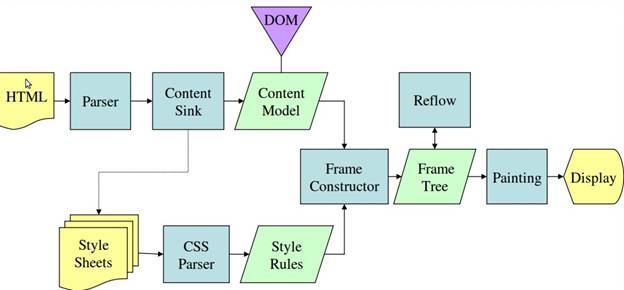
위 그림은 Gecko의 main flow 입니다. Firefox의 렌더링 엔진이 Gecko에 해당합니다.
위 두 그림들을 보면 용어들이 조금씩 다를 뿐, 기본적인 흐름은 같습니다.
Gecko는 시각적으로 구성된 element들을 "프레임 트리"라고 부릅니다. 각 element는 프레임인 것이죠.
Webkit은 "렌더 트리"라고 부르며 "렌더 객체"로 구성되어 있습니다. 또한, Webkit은 element를 배치하는 것을 "레이아웃"이라고 표현합니다. Gecko는 "Reflow"라고 부르죠. Webkit에서는 렌더 트리를 만들기 위해 DOM 노드들과 시각정보를 연결시키는 것을 "Attachment"라고 합니다. Gecko에서는 HTML과 DOM 트리 사이에 "컨텐츠 싱크"라는 DOM element들을 만드는 추가 공정이 존재합니다.
정리하자면 다음과 같습니다.
| Webkit | Gecko | |
|---|---|---|
| render tree | frame tree | |
| element | render object | frame |
| placing of elements | layout | reflow |
| connecting DOM nodes and visual information | Attachment | Content sink |
3. Parsing and DOM tree construction
3-1. Parsing-general
렌더링 엔진에서 파싱은 매우 중요한 과정입니다. 그렇기 때문에 좀 더 깊게 파싱에 대해 이해할 필요가 있습니다.
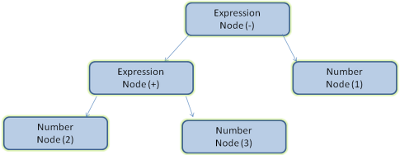
문서를 파싱한다는 것은 코드를 사용할 수 있는 구조로 번역하는 것을 의미합니다. 파싱의 결과물은 보통 문서의 구조를 나타내는 노드 트리입니다. 이를 "파스 트리" 혹은 "신택스 트리"라고 합니다.
예를 들어, 2+3-1이라는 표현을 파싱하면 다음과 같은 트리가 됩니다.
3-1-1. Grammars
파싱은 문서가 따르는 구문 규칙(문서에 쓰인 언어나 형식)을 기반으로 합니다. 파싱할 수 있는 모든 형식은 문법이 있어야 하고 문법은 어휘와 구문 규칙으로 구성되어 있어야 합니다. 이를 "문맥 자유 문법"(context free grammar)라고 부릅니다. 인간 언어들은 문맥 자유 문법 언어가 아니기 때문에 기계적인 파싱 기술로 파싱할 수 없습니다.
3-1-2. Parser–Lexer combination
파싱은 두 서브 과정으로 구분할 수 있습니다.
1. 어휘 분석 lexical analysis
2. 구문 분석 syntax analysis
어휘 분석은 인풋을 토큰들로 분해하는 과정입니다. 토큰은 인간의 언어로 치면 단어 같은 것입니다.
구문 분석은 구문 규칙을 적용하는 과정입니다.
파서(Parser)는 보통 작업을 두 구성요소로 나눕니다.
하나는 인풋을 토큰으로 분해하는 lexer(tokenizer)(어휘 분석기)이고
다른 하나는 구문 규칙에 따라 문서 구조를 분석해 파스 트리를 구축하는 parser입니다.
lexer는 ' '(white space)나 줄바꿈 같은 의미없는 문자를 제거합니다.
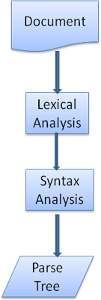
위 그림은 문서를 파스 트리로 만드는 과정입니다.
파싱 과정은 반복적입니다. 파서는 lexer에게 새 토큰을 요청하고 받아 구문 규칙에 맞는지 확인합니다. 만약 구문 규칙과 맞다면 그 토큰에 해당하는 노드가 파스 트리에 추가되고 파서는 다시 새 토큰을 lexer에게 요청합니다.
만약, 토큰이 구문 규칙에 맞지 않다면 파서는 그 토큰을 일단 내부에 저장한 뒤 토큰과 맞는 규칙을 찾을 때까지 요청합니다. 만약 맞는 규칙을 찾지 못했다면 파서는 exception을 일으키는데 이는 문서가 유효하지 않고 syntax error를 포함한 문서라는 것을 의미합니다.
3-1-3. Translation
보통 파스 트리는 최종 결과물이 아닙니다. 파싱은 종종 translation에 사용됩니다. translation이란 인풋 문서를 다른 형식으로 바꾸는 것을 말합니다. 한 예로 컴파일이 있습니다. 컴파일러는 소스코드를 기계코드로 컴파일합니다. 이 때, 소스코드를 파스 트리로 파싱한 뒤 파스 트리를 기계 코드 문서로 번역합니다.
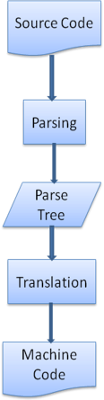
위 그림은 컴파일 과정을 나타냅니다.
3-1-4. Parsing example
3-1. Parsing-general에서 수학 표현식을 파스 트리로 만든 것을 보았는데요. 간단한 수학적 언어를 정의하고 파싱 프로세스를 살펴보겠습니다.
Vocabulary: 우리의 언어는 정수, +, -를 포함한다.
Syntax:
1. 언어 구문의 기본적인 요소들은 표현식(expressions), 항(terms), 연산자(operations)이다.
2. 표현식(expressions)의 수는 제한이 없다.
3. 표현식(expressions)이란 "항(term)" 뒤에 "연산자(operation)" 그 뒤에 또 다른 항(term)이 오는 것으로 정의한다.
4. 연산자(operation)는 +이거나 -이다.
5. 정수 토큰과 하나의 표현식(expression)은 항(term)이다.
2 + 3 - 1이라는 인풋을 분석해보겠습니다.
규칙에 매칭되는 첫번째 substring은 2 입니다.
5번 규칙에 의해 2는 항(term)입니다.
두번째로 매칭되는 것은 2 + 3 입니다.
3번 규칙에 의해 "항(term)" 뒤에 "연산자(operation)" 그 뒤에 또 다른 항(term)이 오므로 2 + 3은 표현식(expression)입니다.
2 + 3 - 1은 표현식(expression)입니다. 2 + 3은 항(term)이며 그 뒤로 연산자(operation)와 또 다른 항(term)이 오기 때문이죠.
2 + +은 어떤 규칙과도 맞지 않기 때문에 유효한 인풋이 아닙니다.
3-1-5. Formal definitions for vocabulary and syntax
어휘는 보통 정규표현식으로 표현됩니다.
예를 들어, 우리 언어는 다음과 같이 정의할 수 있습니다.
INTEGER : 0|[1-9][0-9]*
PLUS : +
MINUS : - 정수는 정규표현식으로 정의되며 구문은 보통 BNF(Backus–Naur form)라고 불리는 형식으로 정의됩니다.
우리 언어는 다음과 같이 정의할 수 있습니다.
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression만약 문법이 문맥 자유 문법(context free grammar)이라면 언어는 정규 파서로 파싱할 수 있습니다. 문맥 자유 문법의 직관적인 정의는 BNF로 표현 가능한 문법입니다. 공식적인 정의는 위키피디아의 문맥 자유 문법을 참고하시기 바랍니다.
3-1-6. Types of parsers
파서는 top down 방식과 bottom up 방식 두가지 종류의 파서가 있습니다.
top down 파서는 구문의 높은 단계의 구조를 검사하고 규칙과 맞는지 찾습니다.
bottom up 파서는 인풋에서 시작해 점진적으로 이를 구문 규칙으로 변환합니다.
두 종류의 파서들이 어떻게 파싱을 하는지 예시를 살펴보도록 하겠습니다.
top down 파서는 높은 수준의 규칙부터 시작합니다. 2 + 3을 표현식으로 인식한 뒤에 2 + 3 - 1을 표현식으로 인식합니다.
bottom up 파서는 규칙과 맞을 때까지 인풋을 스캔합니다. 그러고 나서 매칭되는 인풋을 규칙과 바꿉니다. 그리고 이러한 과정을 인풋의 끝까지 계속합니다. 부분적으로 매칭되는 표현은 파서의 스택에 위치시킵니다.
| Stack | Input |
|---|---|
| 2 + 3 - 1 | |
| 항 | + 3 - 1 |
| 항 연산자 | 3 - 1 |
| 표현식 | - 1 |
| 표현식 연산자 | 1 |
| 표현식 |
bottom up 파서는 shift-reduce 파서라고도 불립니다. 인풋의 오른쪽으로 이동(shift)하면서 점진적으로 구문 규칙으로 줄이기(reduce) 때문입니다. 이때 인풋의 오른쪽으로 이동하는 것은 인풋의 첫번째를 가르키던 포인터의 이동으로 생각하시면 됩니다.
3-1-7. Generating parsers automatically
파서를 생성하는 여러 툴들이 있습니다. 이 툴에 언어의 문법(어휘, 구문 규칙)을 부여하면 파서를 만들어 줍니다. 파서를 만드려면 파싱에 대한 깊은 이해가 필요하며 최적의 파서를 직접 만드는 것은 쉽지 않습니다. 그렇기 때문에 파서 생성기는 아주 유용합니다.
Webkit은 두 파서 생성기를 사용합니다. 어휘 생성을 위한 "Flex"와 파서 생성을 위한 "Bison"입니다.
Flex의 인풋은 토큰의 정규표현식 정의를 포함하는 파일이고 Bison의 인풋은 BNF 형식의 구문규칙입니다.
3-2. HTML Parser
HTML parser가 하는 일은 HTML 마크업을 파스 트리로 파싱하는 것입니다.
3-2-1. The HTML grammar definition
HTML의 어휘와 구문은 W3C에 의해 명세로 정의되어 있습니다.
3-2-2. Not a context free grammar
문법의 구문은 BNF 같은 형식으로 정의될 수 있습니다.
불행히도 전통적인 파서들은 HTML에 적용할 수 없습니다. (하지만 CSS와 JavaScript를 파싱하는데 사용됩니다)
HTML은 파서에게 필요한 문맥 자유 문법으로 쉽게 정의할 수 없습니다.
HTML를 정의하는 공식적인 포맷 DTD (Document Type Definition)가 있지만 문맥 자유 문법은 아닙니다.
HTML은 XML과 유사하기 때문에 언뜻보면 이상해보입니다. XML 파서도 많고 HTML을 XML 형태로 재구성한 XHTML도 있는데 뭐가 크게 차이가 날까요?
차이점은 HTML이 더 "너그럽다"는 점입니다. HTML은 특정 태그들을 생략해도 됩니다(그런 태그들은 내부적으로 추가됩니다). 시작태그나 종료태그를 생략해도 되죠. XML의 뻣뻣하고 요구가 많은 문법에 비해 전반적으로 HTML은 "소프트한" 문법이라는 것입니다.
이런 작아보이는 디테일들이 큰 차이를 만들어 냅니다. HTML은 실수를 용서하고 편하다는 이유로 큰 인기를 얻었습니다. 하지만, 이러한 점이 공식 문법을 작성하기 어렵게 만들기도 했습니다.
요약하자면, HTML의 문법은 문맥 자유 문법이 아니기 때문에 전통적인 파서로 쉽게 파싱할수 없었고 XML 파서로도 파싱하기 쉽지 않다는 것입니다.
3-2-3. HTML DTD
DTD 포맷은 허용되는 모든 요소들과 요소들의 속성, 중첩 구조에 대한 정의들을 포함합니다. 앞에서 언급했듯이 HTML DTD는 문맥 자유 문법이 아닙니다.
DTD는 여러 변형들이 있습니다. strict mode는 specification만을 따르지만 다른 mode들은 과거 브라우저에서 사용된 마크업을 지원합니다. 과거 브라우저에서 사용된 마크업을 지원하는 이유는 오래된 컨텐츠와의 호환성때문입니다. 현재의 strict DTD는 이 곳에서 확인할 수 있습니다.
3-2-4. DOM
이것은 HTML 문서의 객체 표현이고 외부를 향하는 자바스크립트와 같은 HTML 요소의 연결 지점이다. 트리의 최상위 객체는 문서이다.
DOM은 마크업과 1:1의 관계를 맺는다. 예를 들면 이런 마크업이 있다.
아웃풋 트리(파스 트리)는 DOM 요소들과 속성 노드들로 이루어진 트리입니다. DOM은 Document Object Model의 약어입니다. HTML 문서의 객체에 대한 표현이며 JavaScript 같은 바깥 세상과 HTML 요소들을 연결하는 접점(interface)인 것이죠.
트리의 최상위 객체는 "Document" 입니다.
DOM은 마크업과 1:1 관계를 맺습니다.
예를 들면,
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>위의 마크업은 다음 DOM 트리로 번역됩니다.
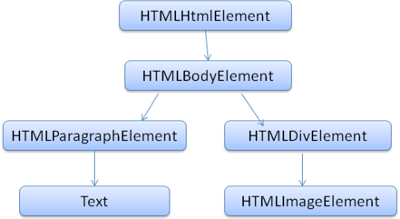
HTML처럼, DOM은 W3C에 의해 specification이 정해져 있습니다. Document를 다루기 위한 일반적인 specification이며 부분적으로 HTML의 특정 요소에 대한 설명도 포함하고 있습니다. HTML에 대한 정의는 이 곳에서 확인할 수 있습니다.
트리가 DOM 노드를 포함한다는 뜻은 트리가 DOM interface 하나를 실행하는 요소들로 구성되어 있다는 뜻입니다. 브라우저는 브라우저 내부에서 사용되는 다른 속성을 가진 구체적 구현을 사용합니다.
3-2-5. The parsing algorithm
HTML은 기존의 top-down방식, bottom-up 방식의 파서들로 파싱할 수 없습니다.
그 이유는 다음과 같습니다.
1. HTML 언어의 너그러운 속성
2. 잘 알려져 있는 invalid HTML을 지원하는 브라우저의 관용
3. 파싱 프로세스은 반복적입니다. 다른 언어들의 경우, 파싱동안 소스는 변하지 않습니다. 하지만, HTML의 경우 dynamic code(예 : document.write () 호출을 포함하는 스크립트 요소)에 의해 토큰을 추가할 수도 있기 때문에 파싱 프로세스는 인풋을 수정합니다.
일반적인 파싱 기술을 사용할 수 없기 때문에, 브라우저는 HTML을 파싱하기 위해 custom parser를 생성합니다.
파싱 알고리즘은 HTML5 specification에 자세히 서술되어 있습니다.
파싱 알고리즘은 두 단계로 이루어져 있습니다.
Tokenization 과 Tree Construction입니다.
Tokenization은 어휘 분석입니다. 인풋을 토큰으로 파싱합니다.
HTML에서 토큰은 시작 태그, 종료 태그, 속성 이름과 속성 값입니다.
Tokenizer는 토큰을 인지해서 Tree constructor에게 토큰을 줍니다. 그리고 다음 토큰을 인지하기 위해 다음 문자를 확인합니다. 이 과정을 인풋의 끝까지 반복합니다.
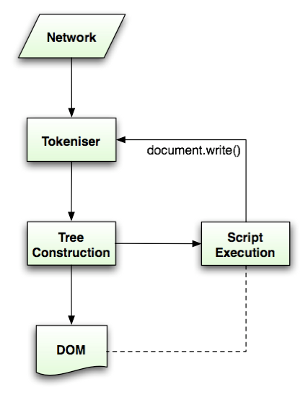
3-2-6. The tokenization algorithm
토큰화 알고리즘의 아웃풋은 HTML 토큰입니다. 이 알고리즘은 state machine이라고도 표현할 수 있습니다. 각 상태(state)는 인풋 스트림의 하나 이상의 문자를 소비하고 그 문자들에 따라 다음 상태를 업데이트 합니다.
결정은 현재의 tokenization state와 tree construction state에 의해 영향을 받습니다.
그러므로 같은 문자를 소비하더라도 현재 상태에 따라 다음 상태에 다른 결과물을 생산할 수 있습니다.
이 알고리즘을 전부 설명하는 것은 너무 복잡하기 때문에 원리를 이해하기 위해 간단한 예제를 살펴보도록 하겠습니다.
<html>
<body>
Hello world
</body>
</html>초기 상태는 "Data state"입니다.
그리고 <문자를 맞닥뜨렸을 때, 상태는 "Tag open state"으로 변하게 됩니다. 그리고 a부터 z까지의 문자들을 소비함으로써 "Start tag token"을 생성하고 상태는 "Tag name state"으로 변합니다. 그리고 >문자를 소비하기 전까지 "Tag name state"에 머무르는 것입니다. 각 문자에는 새로운 토큰 이름이 붙는데 이 경우 생성된 토큰은 html 토큰입니다. > 태그에 도달하게 되면, 현재의 토큰이 발행되고 상태는 다시 "Data state"로 변하게 됩니다.
<body> 태그도 같은 절차로 다뤄지게 됩니다. 지금까지 html 태그와 body 태그를 발행했고 다시 "Data state"로 돌아왔습니다.
이제 Hello world의 H문자를 소비해서 character token을 생성하고 발행하며 </body>의 <를 만나기 전까지 진행되며 Hello World의 각 문자를 위한 character token을 발행할 것입니다.
그리고 다시 "Tag open state"로 돌아왔습니다. 다음 인풋인 /문자로 인해 end tag token을 생성하고 상태는 "Tag name state"로 변하게 됩니다. 그리고 >를 만나기 전까지 "Tag name state"에 머무릅니다. 새로운 태그 토큰이 발행되고 다시 "Data state"로 돌아가고 </html> 인풋도 전과 같은 방식으로 처리됩니다.
3-2-7. Tree construction algorithm
파서가 생성되면 Document 객체도 생성됩니다. Tree construction 단계동안 DOM 트리가 수정되고 요소들이 추가됩니다. tokenizer에 의해 발행된 각 노드는 tree constructor에 의해 처리됩니다. 각 토큰을 위한 DOM 요소의 spcification는 정의되어 있습니다.
요소는 DOM 트리에 추가되기도 하고 open elements의 스택에 추가되기도 합니다. 이 스택은 nesting mismatch와 종료되지 않은 태그들을 교정하기 위해 사용됩니다. 이 알고리즘 역시 state machine으로 표현될 수 있는데 각 state들은 "insertion modes"로 불립니다.
예시를 통해 tree construction 과정을 살펴보도록 하겠습니다.
<html>
<body>
Hello world
</body>
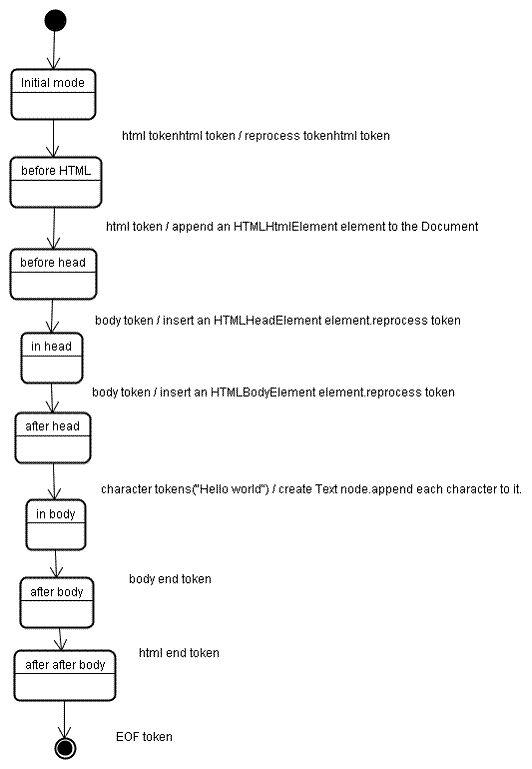
</html>tree construction 단계의 인풋은 tokenization 단계에서 넘어오는 일련의 토큰들입니다.
첫번째 모드는 "initial mode"입니다. "html" 토큰을 받으면서 "before html" mode로 이동하고 이 mode에서 토큰이 재처리됩니다. 이로 인해 "HTMLHtmlElement" 요소가 만들어지고 이 요소는 Document 객체에 추가됩니다.
그리고 나서 상태는 "before head"로 변하게 되고 "body" 토큰을 받습니다. "head" 토큰이 없더라도 "HTMLHeadElement" 요소가 내부적으로 생성되며 트리에 추가됩니다.
그리고 "in head" mode로 이동한 뒤, "after head" mode로 이동합니다. "body" 토큰이 재처리되면 "HTMLBodyElement" 요소가 생성되고 삽입된 뒤에 "in body" 모드로 이동합니다.
Hello world의 각 문자 토큰들을 받고나면 첫번째 토큰으로 인해 "Text" 노드가 생성되고 삽입됩니다. 그리고 나머지 문자들이 이 노드에 추가됩니다.
"body end token"을 받으면 "after body" mode로 이동합니다. 그리고 나서 "html end tag"를 받고 "after after body" mode로 이동합니다. 마지막 파일 토큰을 받고 나면 파싱이 종료됩니다.
3-2-8. Actions when the parsing is finished
파싱이 끝났으면 브라우저는 Document를 상호작용가능한 것으로 인식하고 document 파싱 이후에 실행되어야 하는 "deferred" mode에 있는 스크립트를 파싱합니다. document state는 "complete"가 되고 "load" 이벤트가 발생합니다. 자세한 내용은 HTML5 Specification에서 확인할 수 있습니다.
3-2-9. Browsers' error tolerance
HTML 페이지에서 "Invalid Syntax" 에러를 볼 수 없습니다. 브라우저는 어떠한 invalid content라도 고치기 때문입니다.
다음과 같은 HTML 문서를 예로 들어보겠습니다.
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>많은 규칙들을 어겼습니다. ("mytag"는 표준 태그가 아니며, "p"와 "div" 태그는 잘못 nesting 되었습니다.) 하지만, 브라우저는 올바른 결과를 보여주고 에러를 표시하지 않습니다. 이는 파서 코드가 HTML 제작자의 실수들을 수정하기 때문입니다.
브라우저에서 에러 핸들링은 일관적입니다. 하지만 이는 HTML specification의 어느 부분도 아닙니다. 북마크나 이전 버튼, 다음 버튼처럼 그냥 브라우저 내에서 개발된 것들이죠. 많은 사이트에서 반복되는 잘 알려진 invalid HTML 구조들이 있습니다. 브라우저는 이런 것들을 수정하기 위해 노력합니다. 다른 브라우저들도 늘 해왔듯, 관습적으로요.
HTML5 specification는 이런 요구 사항 중의 일부를 정의했습니다. (WebKit은 이것을 HTML 파서 클래스의 시작 부분에 주석으로 잘 요약해 놓았습니다.)
WebKit이 에러를 어떻게 처리하는지 예시를 보겠습니다.
instead of
일부 사이트들은 <br>이 아니라 </br>을 사용하곤 합니다. IE와 Firefox와의 호환성을 위해서 WebKit은 </br>을 <br>처럼 취급합니다.
코드는 다음과 같습니다.
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}에러 핸들링은 내부적으로 이루어지며 사용자에게 표시하지 않습니다.
A stray table
stray table이란 어떤 테이블 내에 위치한 테이블인데 셀이 아닌 곳에 위치한 경우를 말합니다.
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>WebKit은 위의 계층 구조를 다음과 같이 두개의 sibling table들로 바꿉니다.
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>코드는 다음과 같습니다.
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);WebKit은 이러한 오류 처리를 위해 스택을 사용합니다. 그렇기 때문에 inner table은 outer table 바깥쪽으로 옮겨져서 sibling이 되는 것 입니다.
Nested form elements
form 안에 또다른 form 를 넣은 경우, 안에 넣은 form은 무시됩니다.
코드는 다음과 같습니다.
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}3-3. CSS Parsing
HTML과 달리 CSS는 문맥 자유 문법입니다. 그래서 일반적인 파서로 파싱이 가능합니다. CSS specification은 CSS 어휘와 문법을 정의하고 있습니다.
몇가지 예를 보겠습니다.
어휘 문법은 각 토큰에 대해 정규 표현식으로 정의되어 있습니다.
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*"ident"는 클래스 이름처럼 identifier를 줄인 것입니다. "name"은 요소의 id(#으로 참조하는)입니다.
구문 문법은 BNF로 작성되어 있습니다.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;룰셋(ruleset)은 다음과 같은 구조를 나타냅니다.
div.error, a.error {
color: red;
font-weight: bold;
}div.error와 a.error 는 선택자(selector)입니다. 중괄호 안쪽에는 이 룰셋에 적용된 규칙이 포함되어 있습니다.
구문 문법에 있던 룰셋을 다시 한번 살펴 보겠습니다.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;룰셋은 콤마와 스페이스(공백)(위 코드에서 S는 스페이스를 뜻함)로 구분되는 하나 이상의 selector라는 것을 의미합니다. 룰셋은 중괄호 내부에 있는 declaration이나 세미콜론으로 구분되는 여러 개의 declaration을 포함합니다. "declaration" 과 "selector"은 다음 BNF에 정의되어 있습니다.
3-3-1. WebKit CSS Parser
WebKit은 CSS 문법 파일로부터 파서를 자동적으로 생성하기 위해서 Flex와 Bison이라는 파서 생성기를 사용합니다.
Bison은 bottom up shift-reduce 방식 파서를 생성합니다.
Firefox는 직접 작성한 top down 방식 파서를 사용합니다.
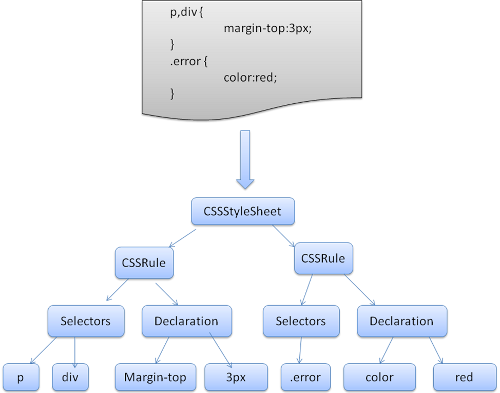
두 경우 모두 CSS 파일은 스타일시트 객체로 파싱됩니다. 그리고 각 객체는 CSS 규칙을 포함하고 있습니다. CSS 규칙 객체는 선택자와 선언 객체 그리고 CSS 문법과 일치하는 다른 객체를 포함합니다.
3-4. The order of processing scripts and style sheets
3-4-1. Scripts
웹은 동기화 모델입니다. 웹 제작자는 파서가
스크립트가 외부에 있는 경우엔 네트워크로 부터 자원을 가져와야 하는데 이것도 동기적으로 처리되며 자원을 가지고 올 때까지 파싱은 중단됩니다.
수년간 이런 모델을 유지했고 HTML4, 5 specification에도 명시되어 있습니다.
웹 제작자는 스크립트를 "defer"로 표시할 수 있는데 표시하게 되면 문서 파싱을 중단하지 않고 문서 파싱을 완료한 이후에 스크립트가 실행됩니다.
HTML5는 스크립트를 비동기(asynchronous)로 처리하는 속성을 추가했기 때문에 별도의 스레드에 의해 파싱되고 실행됩니다.
3-4-2. Speculative parsing
WebKit과 Firefox 둘 다 Speculative parsing이라는 최적화를 합니다. 스크립트를 실행하는 동안 다른 스레드는 문서의 나머지 부분을 파싱하고 네트워크로 부터 받을 또 다른 자원이 있는지 찾은 뒤 로드(load)합니다. 이 방법은 자원을 병렬 연결로 load 할 수 있고 전체적인 속도를 향상시킵니다.
Note: speculative parser는 외부 스크립트, 스타일 시트, 이미지 같은 외부 자원만을 파싱합니다. 또한 DOM 트리를 수정하지 않으며 메인 파서에게 일을 넘깁니다.
3-4-3. Style sheets
스타일 시트의 경우, 다른 모델을 사용합니다. 개념적으로, 스타일 시트는 DOM 트리를 바꾸지 않기 때문에 문서 파싱이 끝나기까지 기다릴 이유가 없는 것처럼 보입니다. 하지만 문서를 파싱하는 동안 스크립트가 스타일 정보를 요청하는 경우에 관한 이슈가 있습니다. 스타일이 아직 load 되지 않았고 파싱이 되지 않은 경우에는 스크립트가 잘못된 결과를 얻어 많은 문제들을 야기합니다. 꽤나 빈번하게 발생하는 케이스입니다.
Firefox는 load 중이거나 파싱 중인 스타일 시트가 있는 경우, 모든 스크립트를 중단합니다.
하지만, WebKit의 경우 아직 load 되지 않는 스타일시트에 의해 영향을 받을 받을 수도 있는 스타일 속성에 접근하려고 할때에만 스크립트를 중단합니다.
4. Render tree construction
DOM 트리가 구축되는 동안 브라우저는 렌더 트리를 구축합니다. 렌더 트리는 시각적 요소로 구성된 트리인데 디스플레이 되는 순서로 구성됩니다. 이 트리의 목적은 올바른 순서로 컨텐츠들이 그려지도록 하는 것입니다.
Firefox는 이 렌더 트리의 요소들을 "frame"이라고 부르며
WebKit은 renderer 혹은 render object라고 부릅니다.
| Firefox | WebKit | |
|---|---|---|
| render tree element | frame | renderer, render object |
renderer는 자신과 자식 요소들을 어떻게 레이아웃하고 페인팅할지 알 고 있습니다.
WebKit의 RenderObject 클래스(renderer의 기본 클래스)는 다음 정의를 가지고 있습니다.
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}각 renderer는 node의 CSS Box에 부합하는 사각형을 나타냅니다. 너비, 높이, 위치와 같은 기하학적 정보를 포함하고 있습니다. 박스 타입은 style 속성의 display 값에 영향을 받습니다.
다음 웹킷 코드는 display 속성에 따라 DOM 노드에 어떤 유형의 렌더러를 만들어야 하는지 결정하는 코드입니다.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}요소의 타입도 고려해야 하는데 예를 들면, form controls과 tables는 특별한 구조입니다. WebKit의 경우, 만약 요소가 특별한 renderer를 만들어야 하는 상황이라면 createRenderer() 메서드를 무시하고 renderer는 비기하학적 정보를 포함하는 스타일 객체를 표시합니다.
4-1. The render tree relation to the DOM tree
renderer는 DOM 요소와 부합하지만 1대1 관계는 아닙니다. non-visual DOM 요소는 렌더 트리에 추가되지 않습니다. 예를 들어 "head" 같은 요소들이요. 또한, display 속성에 "none" 값이 할당된 요소는 트리에 나타나지 않습니다.(visibility 속성에 "hidden" 값이 할당된 요소는 트리에 나타납니다.)
여러 시각적 객체와 대응되는 DOM 요소들도 있습니다. 보통 하나의 사각형으로 표현할 수 없는 복잡한 구조를 가진 요소들입니다. 예를 들어, "select" 요소는 세개의 renderer를 갖습니다. 하나는 표시 영역(display area), 하나는 드랍다운 리스트 박스, 하나는 버튼을 위한 renderer이죠. 또한, 너비가 충분하지 않아 여러 줄로 나누어지는 텍스트의 경우 새 줄은 별도의 renderer가 추가됩니다.
여러 renderer를 갖는 또다른 예는 깨진 HTML입니다. CSS specification에 따르면, inline 요소는 block 요소만 포함하거나 inline 요소만 포함해야합니다. 그런데 inline과 block이 섞인 경우에는 inline 요소를 감싸는 block renderer가 생성됩니다.
어떤 렌더 객체는 DOM 노드에 대응하지만 트리의 같은 위치에 있지 않습니다. float 요소나 position이 absolute로 처리된 요소는 프로세스의 flow 에 벗어나서 트리의 다른 부분에 위치합니다. 그리고 진짜 frame 에 연결됩니다. 그리고 placeholder frame이 원래 있어야 할 자리에 배치됩니다.
4-2. The flow of constructing the tree
Firefox에서는 presentation은 DOM 업데이트를 위한 리스너로 등록됩니다. presentation은 frame 생성을 FrameConstructor가 하도록 하며 FrameConstructor는 스타일을 결정하고 frame을 생성합니다.
WebKit에서는 스타일을 결정하고 renderer를 만드는 과정을 "attachment"라고 부릅니다. 모든 DOM 노드는 "attach" 메서드를 가지고 있습니다. "attachment"는 동기적이며 DOM 트리에 노드를 추가하면 새로운 노드의 "attach" 메서드를 호출합니다.
html 태그와 body 태그를 처리하면 렌더 트리 루트를 구성합니다. 루트 렌더 객체는 containing block(CSS specification에서 부르는 것)(다른 모든 block들을 포함하는 최상위 block)과 일치합니다.
Firefox에서는 이것을 ViewPortFrame라고 부르며 웹킷은 RenderView라고 부릅니다. 이것이 문서가 가르키는 렌더 객체입니다. 트리의 나머지 부분은 DOM 노드를 추가함으로써 구성됩니다.
4-3. Style Computation
렌더 트리를 구축하기 위해서는 각 렌더 객체의 시각적 속성을 계산해야 합니다. 이는 각 요소의 스타일 속성을 계산함으로써 행해집니다.
스타일은 다양한 형태의 스타일 시트들을 포함합니다. 인라인 스타일 요소, HTML의 visual property("bgcolor" 같은 것들) 등의 스타일 시트들이요. 그런데 HTML의 visual property들은 매칭되는 CSS 스타일 속성으로 변환됩니다.
브라우저가 제공하는 기본 스타일 시트, 웹 제작자나 유저가 제공하는 스타일 시트들이 스타일 시트의 origin 입니다.
스타일을 계산하는 일은 다음과 같은 어려움이 있습니다.
- 스타일 데이터는 매우 큰 구조물이며 수많은 스타일 속성을 가지고 있고 이로 인해 메모리 문제가 야기될 수 있습니다.
- 만약 최적화가 되어있지 않다면 각 요소에 맞는 규칙을 찾는 것은 퍼포먼스 이슈를 야기할 수 있습니다. 전체적인 규칙들 중에 각 요소에 맞는 규칙을 찾는 일은 매우 무거운 일입니다.
다음과 같이 복잡한 선택자를 예로 들겠습니다.
div div div div{
...
}위 선택자는 3번째 자식
- 규칙을 적용하는 것은 규칙의 계층을 정의하는 복잡한 cascade 규칙들을 수반합니다.
4-3-1. Sharing style data
WebKit 노드는 스타일 객체(RenderStyle)를 참조합니다. 이 객체들은 몇몇 조건하에 노드끼리 공유할 수 있습니다.
4-3-2. Firefox rule tree
Firefox는 스타일 계산을 쉽게 처리하기 위해 두개의 추가적인 트리를 가지고 있습니다. rule tree 와 style context tree 입니다.
WebKit 역시 스타일 객체를 가지고 있지만 style context tree 같은 트리에 저장시키진 않습니다. 오직 DOM 노드가 관련된 스타일을 가리킵니다.
스타일 문맥에는 최종 값이 저장되어 있습니다. 모든 매칭 규칙들을 올바른 순서로 적용하고 논리에서 구체적인 값으로 변환함으로써 최종값이 계산됩니다. 예를 들어, 논리적인 값이 화면의 퍼센트(%)라면 계산을 통해서 절대적인 단위(px)로 변환됩니다. 노드 사이에서 값을 공유함으로써 다시 계산하는 것을 방지하기 때문에 매우 효율적이고 현명한 과정입니다.
