정규화에 대해서
1. 정규화는 어떤 배경에서 생겨났는가
한 릴레이션에 여러 엔티티의 애트리뷰트들을 혼합하게 되면 정보가 중복 저장되며, 저장 공간을 낭비하게 됨
✔️ 중복된 정보의 문제점 : 한 릴레이션에서는 변경하고, 나머지 릴레이션에서는 변경하지 않은 경우 어느 것이 정확한지 알 수 없음 등의 문제가 발생 -> 이상 발생
이러한 문제를 해결하기 위해 정규화 과정을 거치는 것
✅ 이상
- 삽입 이상 : 릴레이션에 데이터를 삽입할 때 의도와는 상관없이 원하지 않은 값들도 함께 삽입되는 현상
- 삭제 이상 : 릴레이션에서 한 튜플을 삭제할 때 의도와는 상관없는 값들도 함께 삭제되는 연쇄가 일어나는 현상
- 갱신 이상 : 릴레이션에서 튜플에 있는 속성값을 갱신할 때 일부 튜플의 정보만 갱신되어 정보에 모순이 생기는 현상
2. 그래서 정규화란 ?
함수적 종속성 등의 종속성 이론을 이용하여 잘못 설계된 관계형 스키마를 더 작은 속성의 세트로 쪼개어 바람직한 스키마로 만들어 가는 과정
- 하나의 종속성이 하나의 릴레이션에 표현될 수 있도록 분해해가는 과정이라 할 수 있음
- 정규화된 데이터 모델은 일관성, 정확성, 단순성, 비중복성, 안정성 등을 보장한다.
1) 나쁜 릴레이션은 어떻게 파악? 🤷🏻♀️
엔티티를 구성하고 있는 애트리뷰트 간에 함수적 종속성(Functional Dependency)을 판단한다.
즉, 각각의 정규형마다 어떠한 함수적 종속성을 만족하는지에 따라 정규형이 정의되고, 그 정규형을 만족하지 못하는 정규형을 나쁜 릴레이션으로 파악함
2) 함수적 종속성이란 무엇? 🤷🏻♀️
함수적 종속성이란 데이터들이 어떤 기준값에 의해 종속되는 것을 의미함
X와 Y를 임의의 애트리뷰트 집합이라고 할 때, X의 값이 Y의 값을 유일하게 결정한다면, X는 Y를 함수적으로 결정한다.라고 함
💡 예를 들어,
<수강> 릴레이션이 (학번, 이름, 과목명)으로 되어 있을 때, '학번'이 결정되면 '과목명'에 상관없이 '학번'에는 항상 같은 '이름'이 대응된다.
'학번'에 따라 '이름'이 결정될 때 '이름'을 '학번'에 함수 종속적이라고 하며, '학번->이름'과 같이 씀
3) 각각의 정규형은 어떠한 조건을 만족해야 하는가
- 분해의 대상은 무손실 조인을 보장해야 함
- 분해 집합은 함수적 종속성을 보존해야 함
📌 그냥 간단하게 !
정규화의 목적은
✔️ 불필요한 데이터를 제거해서 불필요한 중복 최소화 하기
✔️ 각종 이상 현상 방지하기
이렇게 중복된 데이터를 허용하지 않음으로서 무결성을 유지할 수 있고 디스크의 저장 효율 역시 높일 수 있다 !
그래서, 정규화를 하기 위해서는 함수적 종속성과 같은 이론을 따라 분해한다 !
📌 정규화의 단계
✔️ 각 정규형은 그 선행 정규형의 조건도 지켜야 한다

✅ 제 1 정규형
테이블의 컬럼이 원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해
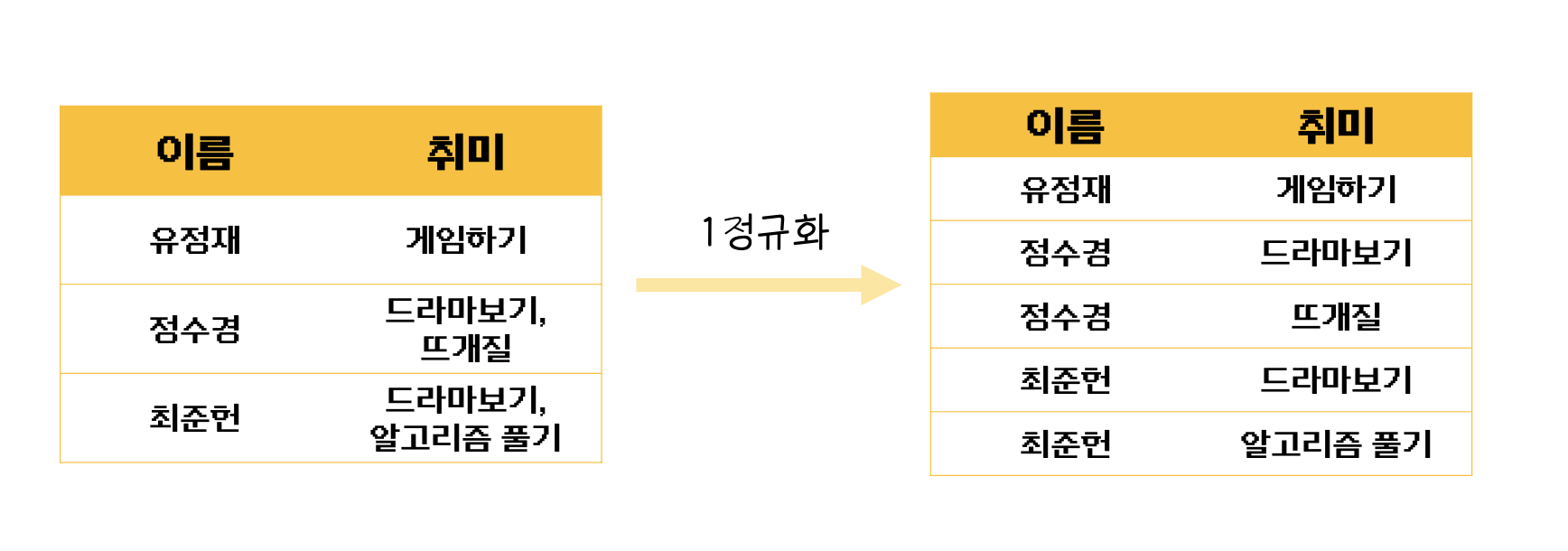
위의 그림에서 보면 수경이와 준헌이는 취미가 두개라서 제 1정규형을 만족하지 ❌
따라서 이를 제1 정규화하여 오른쪽 그림과 같이 분해할 수 있는 것
✅ 제 2 정규형
완전 함수적 종속을 만족하도록 테이블을 분해
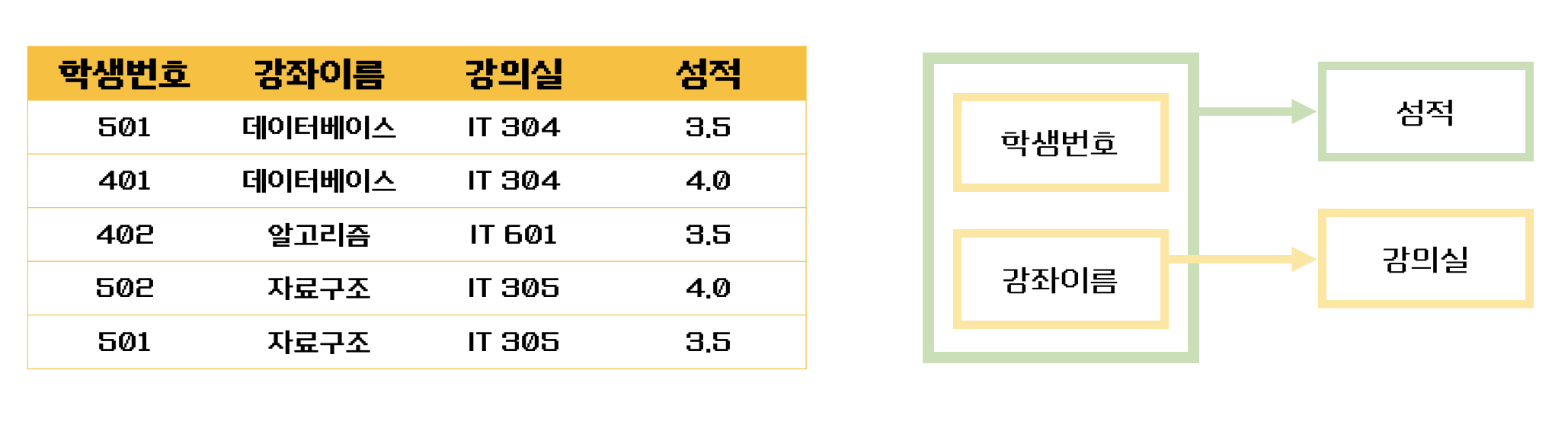
완전 함수적 종속 이면 제 2 정규형을 만족 -> 부분적 함수 종속을 제거해야 함
✔️ 완전 함수적 종속이란
X -> Y 라고 가정했을 때, X의 어떤 애트리뷰트라도 제거하면 더 이상 함수적 종속성이 성립하지 않는 경우
- 기본키의 부분집합이 결정자가 되어서는 안된다는 것
위의 수강강좌 테이블을 보자
- 기본키는 (학생번호, 강좌이름)으로 복합키이다.
- (학생번호, 강좌이름)인 기본키는 성적을 결정하고 있다.
(학생번호, 강좌이름) --> (성적) - 그런데 여기서 강의실이라는 컬럼은 기본키의 부분집합인 강좌이름에 의해 결정될 수 있다.
(강좌이름) --> (강의실)
즉, 기본키인 (학생번호, 강좌이름) 의 부분키인 강좌이름이 결정자이기 때문에 위의 테이블의 경우 다음과 같이 기존의 테이블에서 강의실을 분해하여 별도의 테이블로 관리하면 제2 정규형을 만족시킬 수 있다.
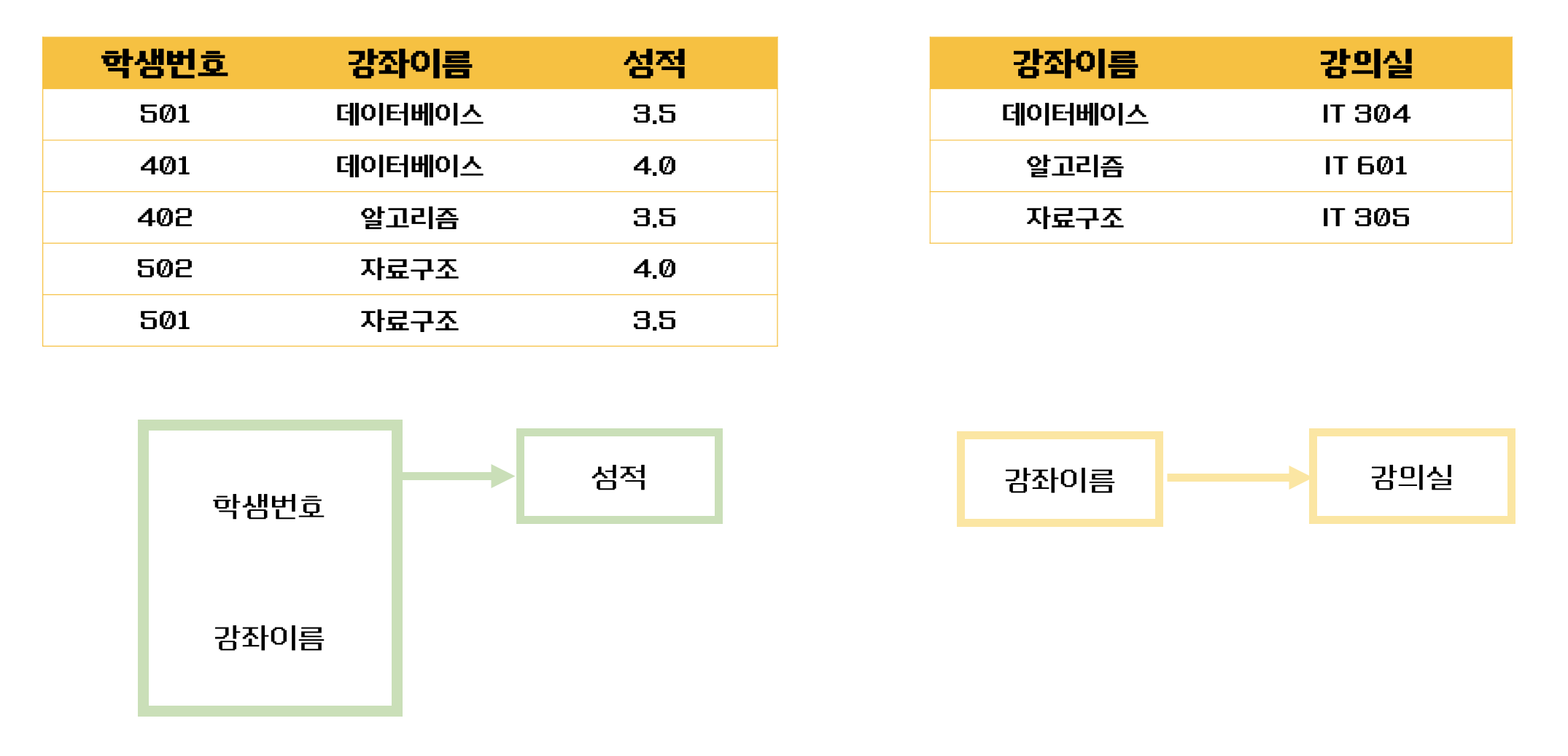
✅ 제 3 정규형
이행적 종속을 없애도록 테이블을 분해
어떤 애트리뷰트도 기본키에 대해 이행적 함수 종속되지 않으면 제 3 정규형을 만족한다고 볼 수 있음 -> 이행적 함수 종속을 제거해야 함
✔️ 이행적 함수 종속이란
X -> Y, Y -> Z의 경우에 의해서 추론될 수 있는 X -> Z의 종속관계를 말함

위의 계절학기 테이블을 보자
- 학생 번호는 강좌 이름을 결정하고 있고, 강좌 이름은 수강료를 결정한다.
(학생번호) --> (강좌이름), (강좌이름) --> (수강료) - 이는 이행적 함수 종속을 만족하기 때문에 없애야 함
💡 이행적 종속을 제거하는 이유 : 예를 들어 501번 학생이 수강하는 강좌를 알고리즘으로 바꿨다 이행적 종속이 존재한다면 501번의 학생은 알고리즘 수업을 20000원이라는 수강료로 듣게 된다. 물론 강좌 이름에 맞게 수강료를 다시 변경할 수 있지만, 이러한 번거로움을 해결하기 위해 제3 정규화를 하는 것
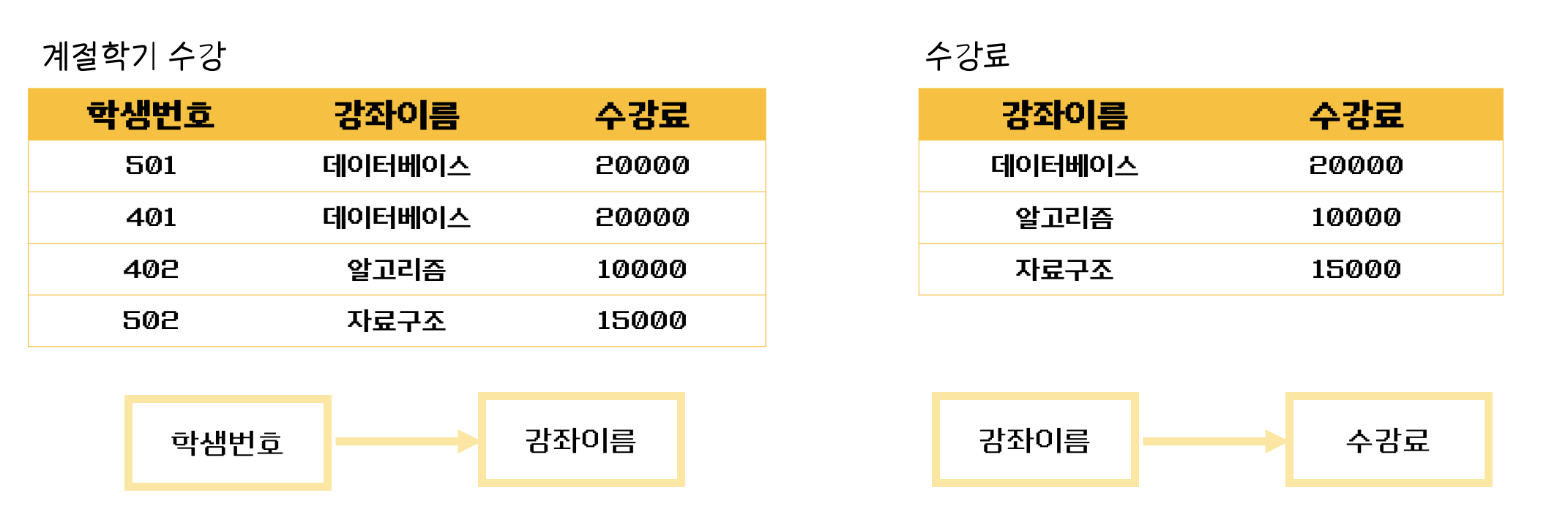
즉, 위와 같이 학생 번호를 통해 강좌 이름을 참조하고, 강좌 이름으로 수강료를 참조하도록 테이블을 분해해야 함
✅ BCNF 정규형 (Boyce-Codd)
모든 결정자가 후보키가 되도록 테이블을 분해하는 것
여러 후보 키가 존재하는 릴레이션에 해당하는 정규화 내용임. 제 3 정규형을 보완하는 데 의미가 있음 -> 결정자이면서 후보키가 아닌 것을 제거
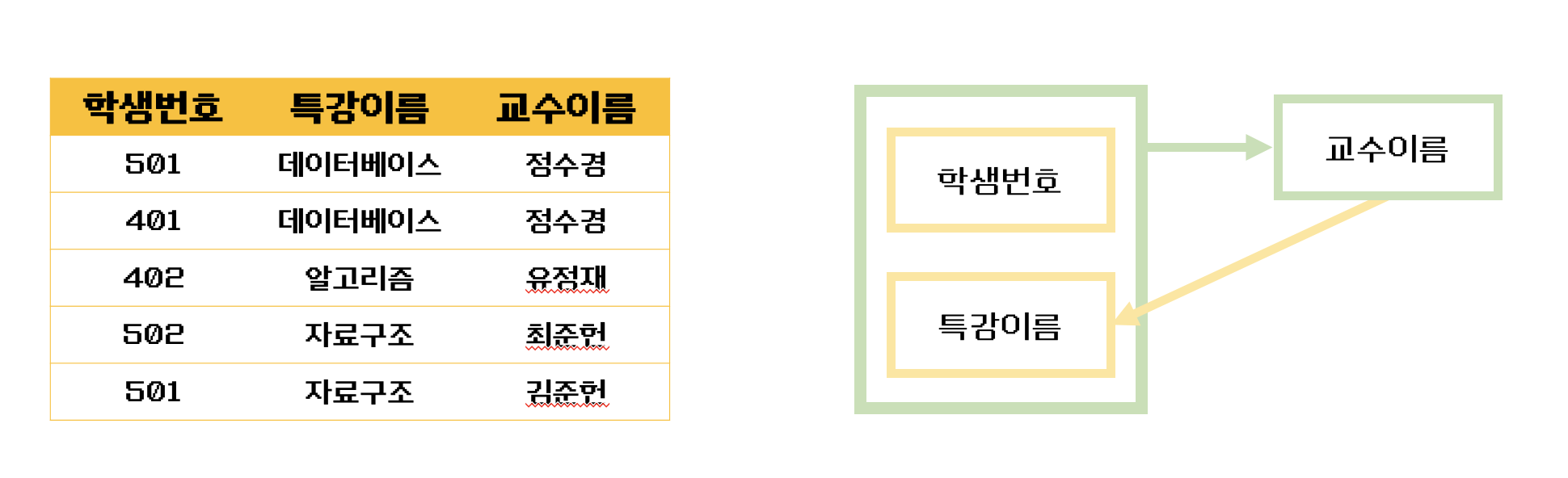
위의 특강 테이블을 보자
- 기본키는 (학생번호, 특강이름)이다. 그리고 기본키 (학생번호, 특강이름)는 교수 이름을 결정하고 있다.
(학생번호, 특강 이름) --> (교수 이름) - 또한 여기서 교수 이름은 특강이름을 결정하고 있다.
(교수 이름) --> (특강 이름)
그런데 문제는 교수가 특강이름을 결정하는 결정자이지만, 후보키가 아니라는 점이다. 그렇기 때문에 BCNF 정규화를 만족시키기 위해서 위의 테이블을 분해해야 함

관계 데이터베이스 설계의 목표는 각 릴레이션이 3NF or BCNF 를 갖게 하는 것
=> 실무에서는 대체로 1~3 정규화까지 한다고 함
3. 정규화의 장점?
- 데이터베이스 변경 시 이상 현상들이 발생하는 문제점 해결 가능
- 데이터베이스 구조 확장 시 재디자인 최소화 가능 : 정규화 된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 되고, 이는 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 됨
- 사용자들에게 데이터 모델을 더욱 의미있게 제공 가능
4. 정규화의 단점?
릴레이션의 분해로 인해 릴레이션 간의 조인 연산이 많아짐. 이로 인해 질의에 대한 응답 시간이 느려질 수 있음.
5. 그럼 언제 정규화를?
조회를 하는 SQL 문장에서 조인이 많이 발생해서 성능 저하가 일어나면 반정규화를 적용
1) 반정규화란
반정규화는 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위배하는 행위임
- 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 함.
2) 반정규화의 방법
1. 테이블 통합 : 두 개의 테이블이 조인되는 경우가 많아 하나의 테이블로 합쳐 사용하는 것이 성능 향상에 도움이 될 경우 수행
2. 테이블 분할 : 테이블을 수직 또는 수평으로 분할하는 것
3. 중복 테이블 추가 : 여러 테이블에서 데이터를 추출해서 사용해야 하거나 다른 서버에 저장된 테이블을 이용해야 하는 경우 중복 테이블을 추가하여 작업의 효율성 향상 가능
4. 중복 속성 추가 : 조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것
3) 반정규화 과정에서 주의할 점 ?
데이터의 무결성이 깨질 수도 있고, 성능이 더 저하될 수도 있음
🚀 정규화, 반정규화의 대상
✔️ 정규화 : 온라인 거래 시스템 같은 OLTP(OnLine Transaction Processing) 데이터베이스는 CRUD(Create, Read, Update, Delete) 가 많이 일어나 정규화가 적절하다.
✔️ 반정규화 : 분석 리포트 같은 OLAP(OnLine Analytical Processing) 데이터베이스는 분석과 리포팅을 위해 사용되기 때문에 연산의 속도를 위해 반정규화를 사용하는 게 좋습니다.
참조 : https://mangkyu.tistory.com/110
https://velog.io/@wldus9503/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%EC%A0%95%EA%B7%9C%ED%99%94Normalization%EB%9E%80
