-
인공지능
: 사고나 학습 등 인간이 가진 지적능력을 컴퓨터를 통해 구현하는 기술 -
머신러닝
: 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상 시키는 기술 방법 -
딥러닝
: 인간의 뉴런과 비슷한 인공신경망 방식으로 정보를 처리 -
영역 크기
인공지능 > 머신러닝 > 딥러닝
머신러닝이란?
-
데이터를 기반으로 학습을 시켜서 예측하게 만드는 기법
-
인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
-
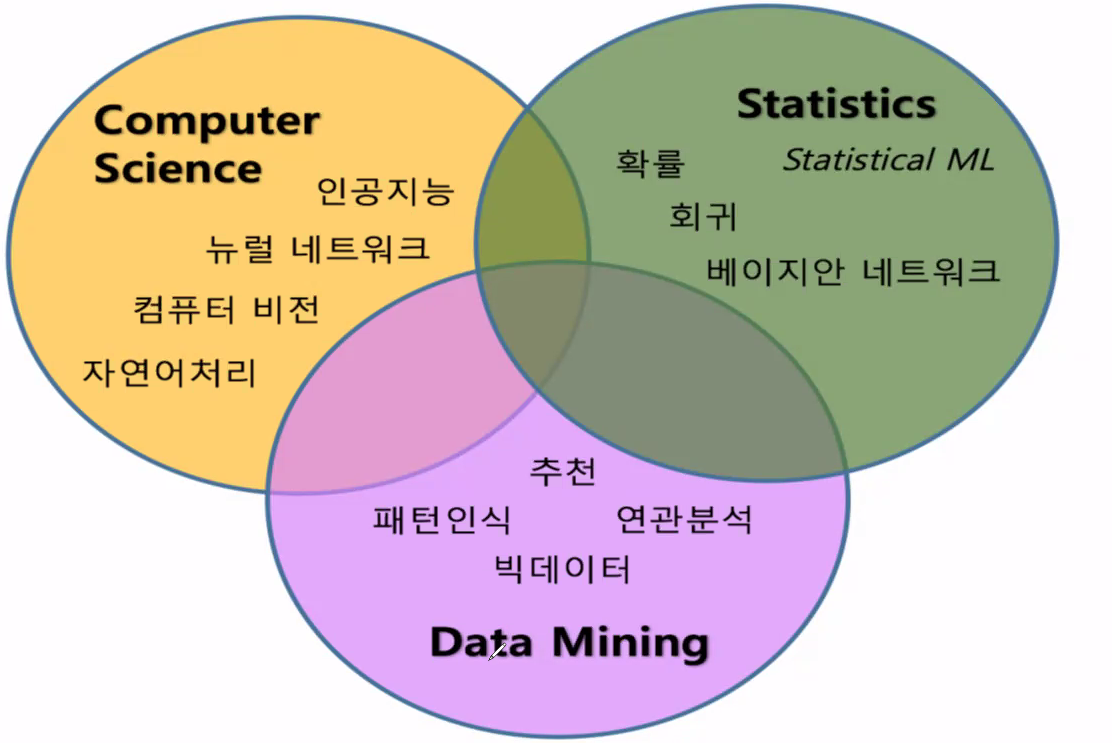
통계학, 데이터 마이닝, 컴퓨터 과학이 어우러진 분야
-
Rule-based expert system(규칙 기반 전문가 시스템)
: if문과 else문으로 하드 코딩된 명령을 사용하는 시스템- 단점 : 많은 상황에 대한 규칙들을 모두 만들어 낼 수 X
-
요즘의 머신러닝
데이터를 이용하여 특성과 패턴을 학습하고, 그 결과를 바탕으로 미지의 데이터에 대한 미래결과(값, 분표)를 예측하는 것

-
실습
-
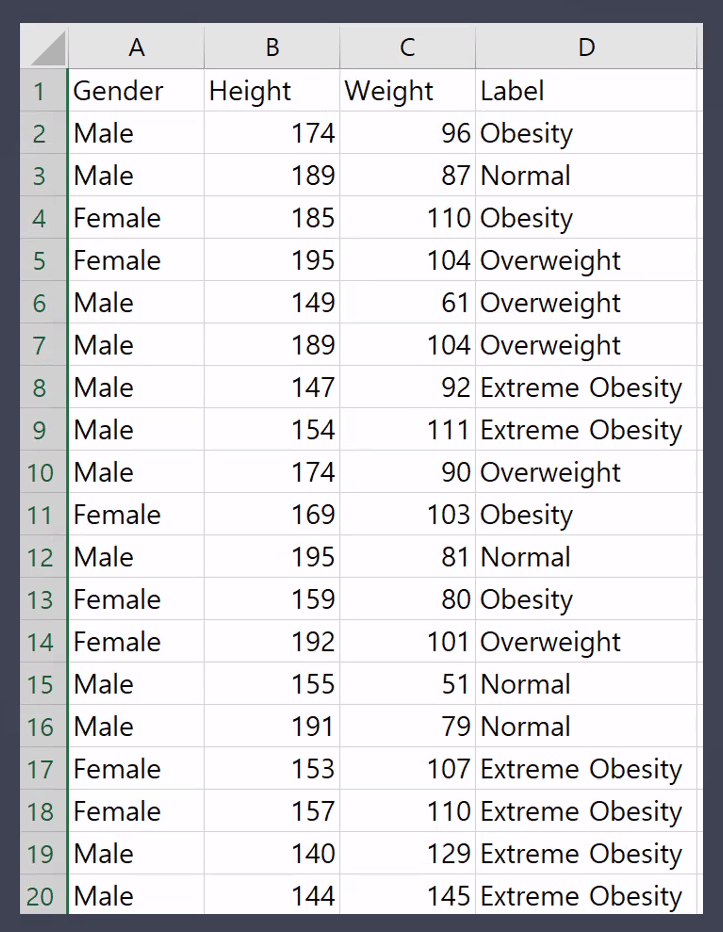
비만도 데이터를 이용해 학습 해보자
-
scikit-elarn을 사용
- 파이썬에서 쉽게 사용할 수 있는 머신러닝 프레임워크, 라이브러리
- 회귀, 분류, 군집 차원축소, 특성공학, 전처리. 교차검증 등 머신러닝에 필요한 기능을 갖춤
- 학습에 필요한 데이터 제공
-
KNN 라이브러리 사용
- 특징
: 비슷한 데이터끼리 비슷한 결과를 나올거다라는 전제하에 진행
- 특징
-
학습 순서
-
모델정의
```python from sklearn.neighbors import KNeighborsClassifier # KNN클래스 bmi_model = KNeighborsClassifier(n_neighbors=5) #가장 가까운 이웃 수 ``` -
학습
- 작업 경로가 다를 시
```python #현재 작업 경로 표시 !pwd #!를 쓰면 프롬프트 창(시스템 명령어) 사용할 수 있다. # 현재 폴더 내부 상황 !ls #작업경로 변경 %cd ./drive/MyDrive/Colab\ Notebooks/22.04.11\ 머신러닝 ``` - 데이터불러오기
-
#1. 판다스 import import pandas as pd #2. csv파일 로딩 bmi_data = pd.read_csv('./data/bmi_lbs.csv', encoding='euc-kr') #3. 위쪽 5개 살펴보기 bmi_data.head()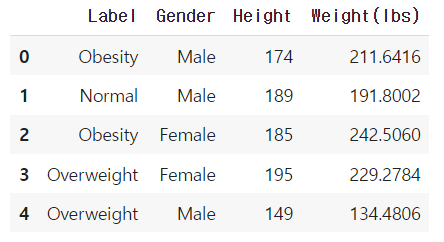
-
비만도 컬럼의 종류를 확인해보자.
bmi_data['Label'].unique() bmi_data['Label'].value_counts()
-
단위 변경하기
# 몸무게를 파운드 -> kg단위로 변경 bmi_data['Weight(kg)'] = bmi_data['Weight(lbs)']*0.453592 -
상위 데이터 출력
bmi_data.head() -
기술 통계확인(describe()함수 사용)
bmi_data.describe()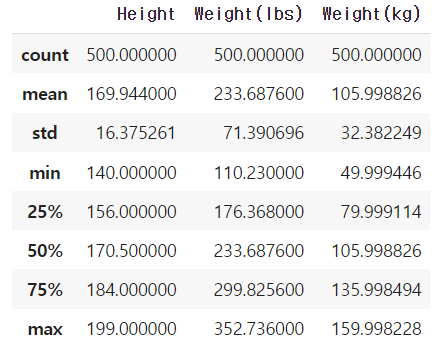
-
문제와 정답 분리하기
X = bmi_data[['Height','Weight(kg)']] y = bmi_data['Label']
- 예측
- 샘플데이터 추출
X_sample = bmi_data.iloc[[80,105,275,300,345],[2,4]] y_sample = bmi_data.iloc[[80,105,275,300,345],0]- 예측결과 변수에 담기
pre = bmi_model.predict(X_sample)
- 평가 <- 젤 중요(검증)
- 모델평가 함수 활용
#정확도(전체 중에서 정확히 맞춘 비율 계산) from sklearn.metrics import accuracy_score #실제 정답, 모델의 예측값, 0.0(하나도 못맞췄을 경우) ~ 1.0(다 맞췄을 경우) score = accuracy_score(y_sample, pre)
-
문제점
- 500명의 비만도 데이터를 학습하고 그중에 5명을 추출해서 평가를 진행하는 방법은 옳지않다.
- 이미 모델에 500명에 대해서 학습했기 때문에 상대적으로 추출한 5명을 잘 맞출 확률이 높다
- 그래서 머신러닝에서는 훈련용 데이터와 평가용 데이터를 사전에 구분해서 활용한다.
- 일반적으로 비율은 7:3으로 활용한다.
- train 데이터(70%), test 데이터(30%)
-
훈련용, 평가용 데이터 분리
from sklearn.model_selection import train_test_split #기본적으로 75:25 비율, test_size를 통해 비율 조절 가능, random_state - 고정된 데이터로 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=219) -
훈련용, 평가용으로 정의부터 평가하기
bmi_model2 = KNeighborsClassifier() bmi_model2.fit(X_train,y_train) pre2 = bmi_model2.predict(X_test) score2 = accuracy_score(y_test,pre2) score2 -
출력화면
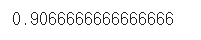
-
모델 활용하기
bmi_model2.predict([[178,74],[188,65]])

초보 코딩
잘 보고갑니다