다양한 평가지표
- precision(정밀도)
: 모델이 해당 클래스로 예측한 것에 대한 정확도 - recall(재현율)
: 실제 해당 클래스에 대해서 맞춘 비율 - f1-score
- ROC
from sklearn.metrics import classification_report
print(classification_report(실제 결과, 예측치))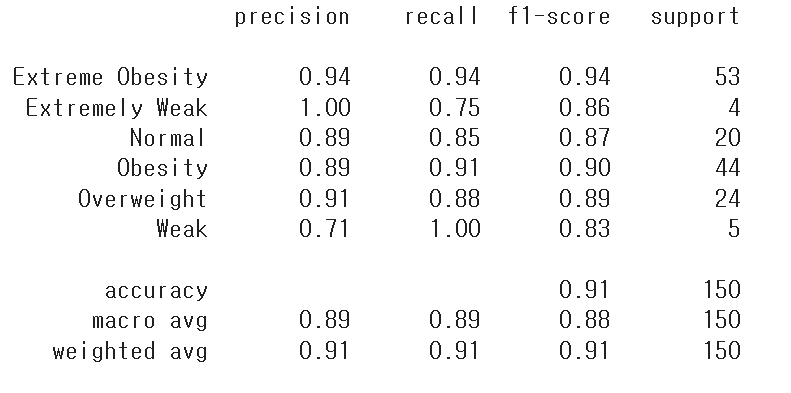
데이터의 종류
- 범주형 : 개별적으로 끊어지는 형태, 타입이 정해지지 X, 주어진 형태로 제공
ex) 혈액형, 학점 - 수치형 : 데이터의 최소나 최대가 존재 X
ex) 나이, 키와 몸무게
머신러닝 종류
- 지도학습
- 데이터에 대한 Label(명시적인 답)이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 분류(Classification)와 회귀(Regression)로 나뉘어진다.
- 가장 많이 사용되는 방법
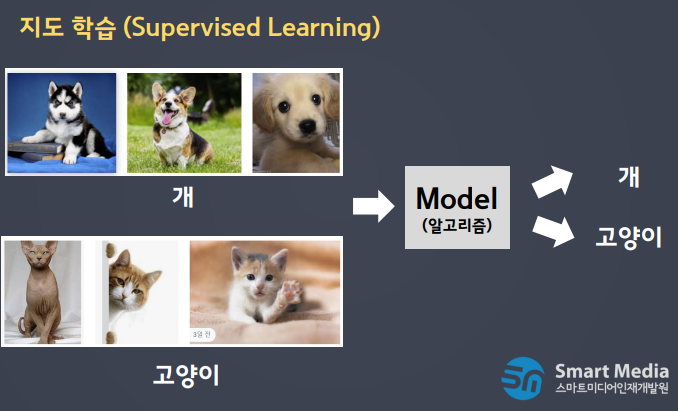
- 분류
1. 미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것
2. 속성 값을 입력, 클래스 값을 출력으로 하는 모델
3. 붓꽃(iriis)의 세 품종 중 하나로 분류, 암 분류 등
4. 이진분류, 다중 분류 등이 있다
- 회귀
1. 연속적인 숫자를 예측하는 것
2. 속성 값을 입력, 연속적인 실수 값을 출력으로 하는 모델
3. 어떤 사람의 교육수준, 나이, 주거지를 바탕으로 연간 소득 예측
4. 예측 값의 미묘한 차이가 크게 중요하지 않다
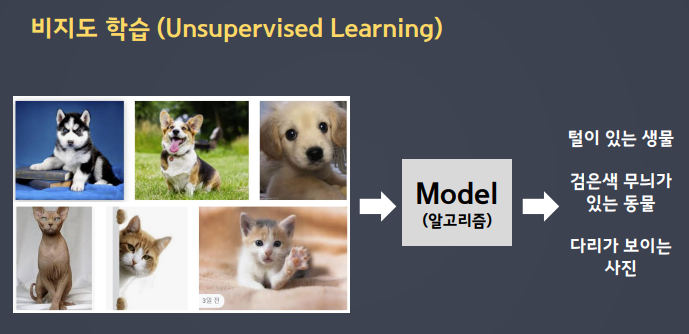
- 비지도 학습
- 데이터에 대한 Label(명시적인 답)이 없는 상태에서 컴퓨터를 학습시키는 방법
- 데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용
- 테이터를 비슷한 특성끼리 묶는 클러스터링(Clustering)과 차원축소(Dimensionality Reduction) 등이 있다

- 강화 학습
- 지도학습과 비슷하지만 완전한 답(Label)을 제공하지 X
- 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
- 주로 게임이나 로봇을 학습시키는데 많이 사용
실습
-
주택 가격 데이터를 읽어 예측해보자
-
회귀모델 import하기
from sklearn.linear_model import LinearRegression #회귀모델 house_model = LinearRegression() -
파일 위치 이동 후 데이터 읽어오기
#위치 변경하기 %cd ./drive/MyDrive/Colab\ Notebooks/22.04.11\ 머신러닝 #데이터불러오기 #1. 판다스 import import pandas as pd #2. csv파일 로딩 melb_data = pd.read_csv('./data/melb_data.csv', encoding='euc-kr') #3. 위쪽 5개 살펴보기 melb_data.head()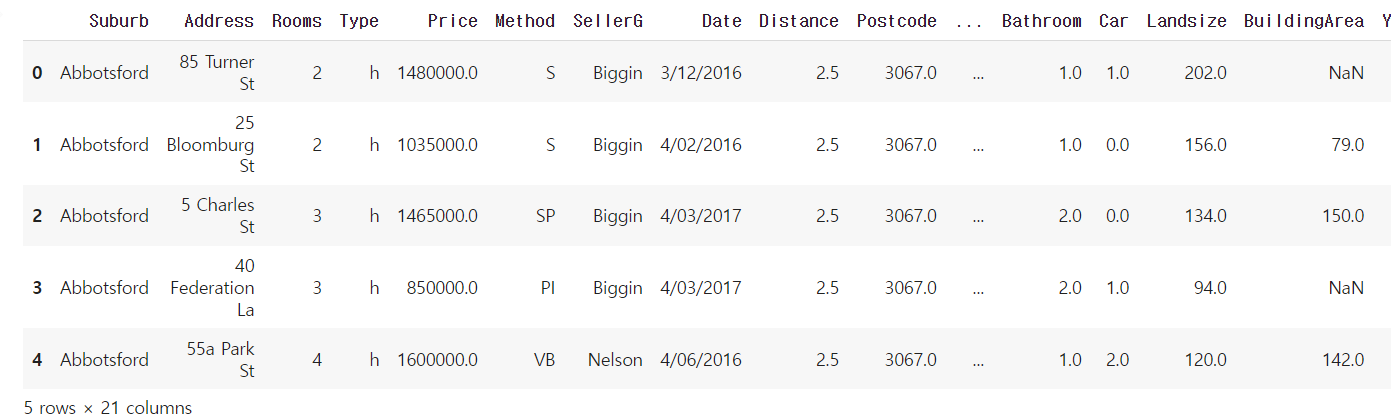
정보 간단하게 보려면house_data.info()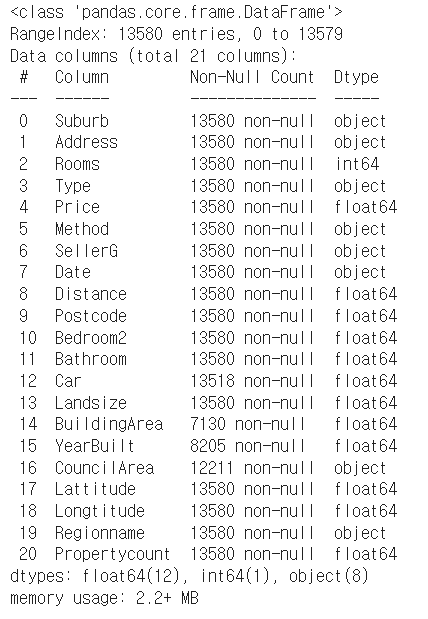
-
결측치가 없고, 숫자로 구성된 데이터중에 일부로 선택해서 사용해보자
X = house_data[['Rooms','Distance','Bathroom','Landsize','Lattitude','Longtitude']] y = house_data['Price'] -
훈련용과 평가용으로 데이터 분리, 비율은 8:2, random_state = 412
from sklearn.model_selection import train_test_split #훈련용, 평가용 데이터 분리 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.8,random_state=412)#기본적으로 75:25 비율, test_size를 통해 비율 조절 가능, random_state - 고정된 데이터로 X_train.head() -
출력화면
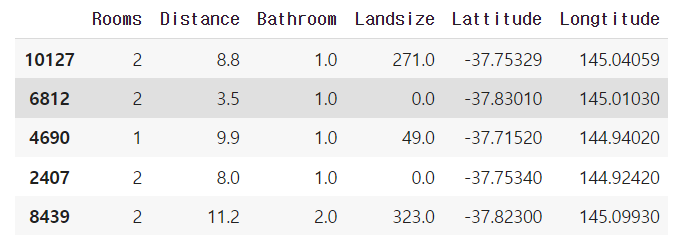
-
지도학습 시키기
```python house_model.fit(X_train,y_train) #지도 학습 ``` -
가중치 확인하기
X_train.columns house_model.coef_ #선형모델이 입력특성에 대해서 학습한 가중치 -
출력화면
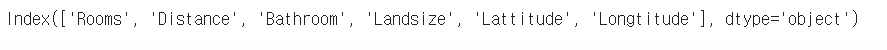
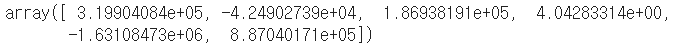
-
-
모델 예측
pre = house_model.predict(X_test) -
모델 평가
- 집 가격은 데이터의 형태가 수치형이기 때문에 정답인지 아닌지 명확하지않다.(개인 기준에 따라서 달라질 수 있음)
- 수치형 데이터는 예측값과 실제값의 차이인 오차를 이용해서 모델을 평가
- 평균 절대값 오차로 모델 평가
from sklearn.metrics import mean_absolute_error #평균 절대값 오차 house_mae = mean_absolute_error(y_test,pre) #실제값, 예측값 house_mae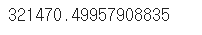
-
다른 평가지표
- 내부 평가(모델에 내장된 기능)
house_model.score(X_test, y_test)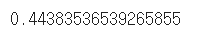
- 내부 평가(모델에 내장된 기능)

초보 코딩