일반화, 과대적합, 과소적합
1. 과대적합(OverFitting)
: 훈련 데이터에 대해 온갖 규칙을 다 세워 훈련데이터에만 맞추고 새로운 데이터에 대해서는 판단, 예측을 못하는 경우
2. 과소적합(UnderFitting)
: 훈련 데이터에 대한 정보, 데이터가 너무 작고 테스트 데이터에 대한 판단,예측을 하지 못할 경우
3. 일반화(Generalization)
: 훈련 세트로 학습한 모델이 테스트 세트에 대해 정확히 예측하도록 하는 경우
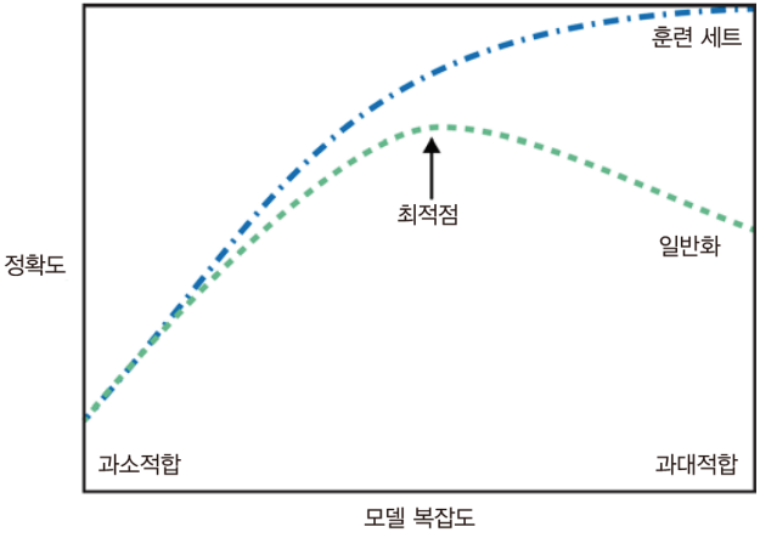
-
최근접 분류 알고리즘
: 근접한 이웃의 수에 따라 영역을 판단
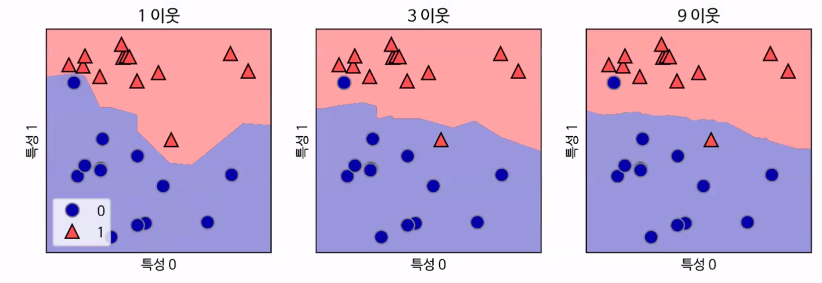
-
해결방법
- 주어진 훈련데이터의 다양성이 보장되어야한다. 다양한 데이터 포인트를 골고루 나타내야 한다.
- 일반적으로 데이터 양이 많으면 일반화에 도움이 된다.
- 하지만 편중된 데이터를 많이 모으는 것은 도움이 되지 않는다.
- 규제(Regularization)을 통해 모델의 복잡도를 적정선으로 설정한다.
머신러닝 vs 딥러닝
-
머신러닝
: 정형화된 데이터를 다룰 때 좋음 -
딥러닝
: 비정형 데이터를 다룰 때 좋음(이미지, 영상, 텍스트)- 이미지 분류
- Classification
: 데이터가 들어왔을 때 어떤 이미지인 지 분류 - Object Detecting
: 이미지에 대한 위치(영역)까지 판단 - 세크메테이션?
: 그 객체의 실제 디테일한 영역까지 찾아서 판단
- Classification
- 이미지 분류
크롤링 기본 개념
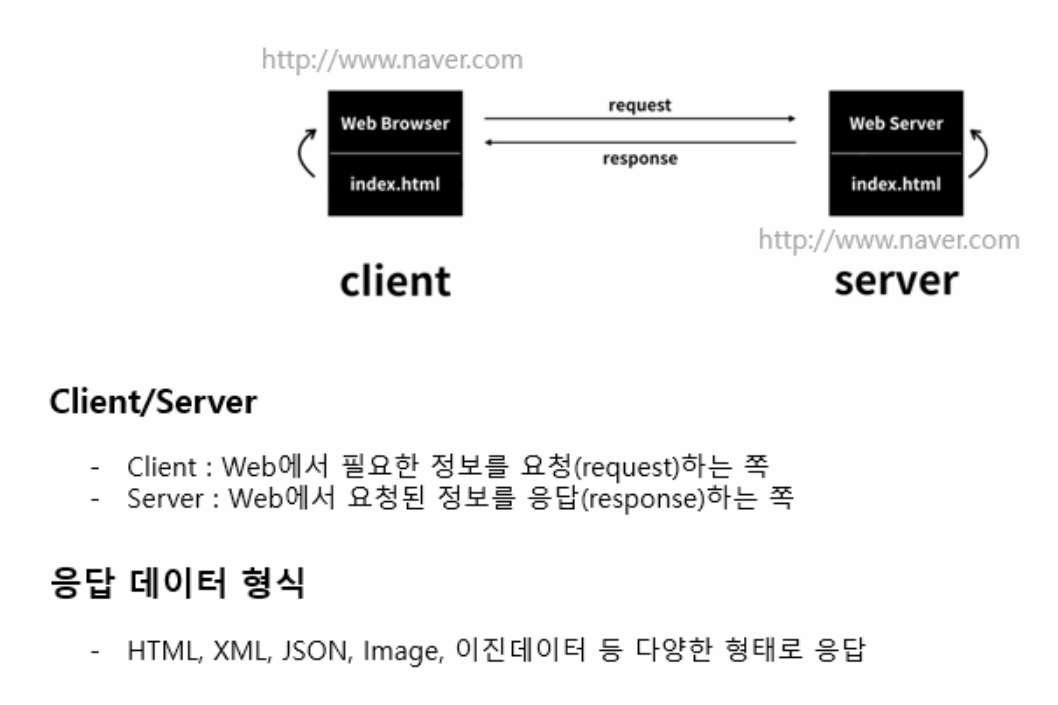

-
실습하기
- 라이브러리 설치하기
!pip install requests bs4 - import하기
import requests as req #서버에 요청을 보내는 도구 from bs4 import BeautifulSoup #응답 받은 문서에서 데이터를 추출하는 도구 - url 설정과 요청 보내고 확인하기
url = "요청할 서버 주소" res = req.get(url) #요청보내기 res.status_code #응답 성공 시 : 200, 페이지 없음 : 404, 서버오류 : 500 - 파싱할 데이터
naver_dom = BeautifulSoup(res.text,'html.parser') a = naver_dom.select("div.news_area>a.news_tit") a- 출력화면

- 출력화면
- 기사들의 제목 따오기
for tag in a : print(tag.text)- 출력화면

- 출력화면
- 라이브러리 설치하기
-
html 받아오기
- 요청할 페이지 변수에 저장하기, 요청하고 응답받기
url = "요청할 주소" res = req.get(url2) res.status_code - html 요청하기
이렇게 하면 실행이 되지않는다.naver_img_dom = BeautifulSoup(res.text,'html.parser') img_tags = naver_img_dom.select("img._img._listImage") img_tags
현재 requests로 이용해서 얻어오는 페이지는 동적으로 나중에 정보를 상입하기 때문에 내가 원하는 정보를 추출하기 어렵다.
동적인 페이지는 selenium을 활용해 수집한다.
- 요청할 페이지 변수에 저장하기, 요청하고 응답받기
-
html 요청하여 받아오기
- 라이브러리 설치하기
!pip install selenium - 브라우저 객체, 크롬 브라우저 생성하기
from selenium import webdriver browser_obj = webdriver.Chrome() browser_obj.get(url2) - html 갖고오기
naver_img_dom2 = BeautifulSoup(browser_obj.page_source,'html.parser') img_tags = naver_img_dom2.select("img._image._listImage") img_tags[0]
- src 갖고오기
src = img_tags[0].get('src') img_tags[0]['src']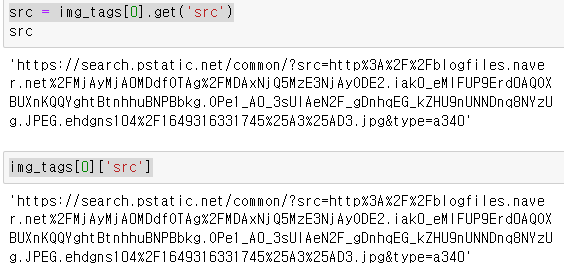
- 라이브러리 설치하기
-
파일 다운로드 받기
from urllib.request import urlretrieve dest="./포켓몬빵.png" urlretrieve(src,dest)url로부터 파일을 다운받는 기능
다운 받을 원본의 URL, 다운로드할 경로 설정

초보 코딩