
그래프에서 여러 노드들이 서로 연결되어있을 때, 임의의 노드가 어떤 집합에 속하는지 판별하는 알고리즘이다.
해당 기능은 다른 그래프 알고리즘 (bfs, dfs 등)으로도 구현 가능하지만 Union Find 는 시간복잡도가 상수에 가깝게 작동한다.
- Union (합치기): 두 원소가 속한 집합을 하나로 합친다 (두 원소를 한 집합으로 합친다)
- Find (찾기): 해당 원소가 속한 집합을 반환한다.
그래프를 하나의 트리로 나타낸다. 트리는 배열로 구현한다.
i번 노드의 부모 노드의 번호를 ary[i] 에 담는다.
-> root 노드가 특정 집단을 대표하게 된다.
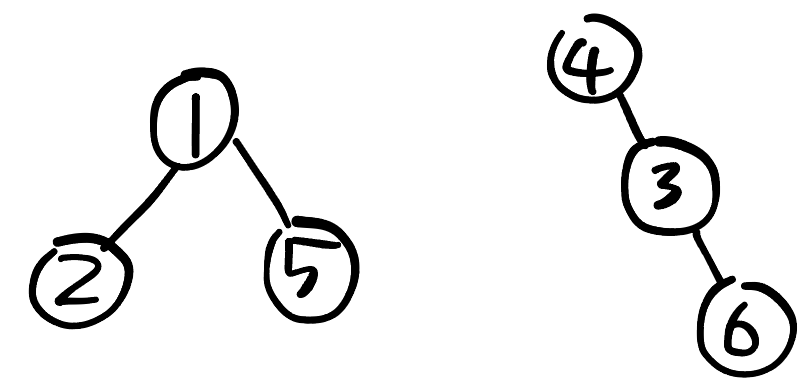
위 구조를 다음과 같이 배열로 나타낸다.
| 인덱스 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 값 | 1 | 1 | 4 | 4 | 1 | 3 |
초기화
부모 노드가 없는 경우 자기 자신의 번호를 가진다. 초기화할땐 자기 자신의 번호로 한다. (부모 노드가 없다는 뜻)
| 인덱스 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 값 | 0 | 1 | 2 | 3 | 4 |
int[] parent = new int[MAX_SIZE];
for(int i = 0; i < MAX_SIZE; i++) {
parent[i] = i;
}Find
노드 x의 Root 노드의 번호를 찾는다. (부모 노드가 자신의 번호일때 까지 찾는다)
따라서 두 노드가 같은 집단인지 검사할려면 find 해서 나온 값을 비교하면 된다.
int find(int x) {
if (x == parent[x]) {
return x;
}
return find(parent[x]);
}Find 최적화
위 find 코드는 최악의 경우(트리가 한쪽으로 치우쳐 져있을 경우) 시간복잡도가 O(N)이다.
따라서 다음과 같이 최적화하면서 재귀적으로 루트를 찾으면서, 경로상의 모든 노드가 직접 루트 노드를 가리키도록 갱신한다. -> 트리 높이가 2가 된다.
이를 통해 이후 find 연산의 탐색 경로 길이가 단축되어 시간복잡도를 상수에 가깝게 만든다.
주의점: 원래 그래프의 모습을 망가트린다. union, find 계산만 필요할 경우 사용
int find(int x) {
if (x == parent[x]) {
return x;
}
return parent[x] = find(parend[x]);
}Union
노드 a 와 노드 b를 합친다 -> 둘의 root 를 연결한다
void union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (A == B) { // 이미 같은 집합일 경우 합치면 사이클 발생하므로 넘김
return;
}
parent[rootB] = rootA;
}Union 최적화
rank 배열에 각 노드의 높이를 저장한다.
두 집합을 합칠 때 트리의 높이가 낮은 쪽을 높은 쪽 아래에 붙임으로써 전체 트리의 높이를 최소화하는 역할을 한다. 이를 통해 향후 find 연산에서 경로 탐색 길이가 짧아져 성능이 개선된다.
또한 Union 과정을 역추적 가능하다.
void union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA == rootB) {
return;
}
if (rank[A] < rank[B]) {
parent[A] = B;
} else if (rank[A] > rank[B]) {
parent[B] = A;
} else {
parent[B] = A;
rank[A]++;
}
}간단한 Union 최적화
rank 배열을 사용하지 않고 이정도로 경로 압축만 해줘도 랜덤한 테스트 케이스에서는 rank를 사용한 최적화와 유사한 성능 향상이 나타난다. 실제 알고리즘 풀이에서는 이정도만 사용해도 충분하다.
boolean union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA == rootB) {
return false;
}
if (rootA <= rootB) {
parent[rootB] = rootA;
} else {
parent[rootA] = rootB;
}
return true;
}예시 문제와 코드
import java.util.Scanner;
class Main {
static class UnionFind {
int[] parent;
// 초기화
UnionFind(int size) {
this.parent = new int[size];
for (int i = 0; i < size; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] == x) {
return x;
}
return parent[x] = find(parent[x]);
}
boolean union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA == rootB) {
return false;
}
if (rootA <= rootB) {
parent[rootB] = rootA;
} else {
parent[rootA] = rootB;
}
return true;
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int M = sc.nextInt();
UnionFind uf = new UnionFind(N + 1);
while (M-- > 0) {
int type = sc.nextInt();
int a = sc.nextInt();
int b = sc.nextInt();
// a 와 b 의 연결 표현을 위해 union 연산 수행
if (type == 0) {
uf.union(a, b);
} else if (type == 1) {
// a 와 b 가 같은 집단에 속한건지 판단하기 위해 find 연산 결과값 비교
if (uf.find(a) == uf.find(b)) {
System.out.println("YES");
} else {
System.out.println("NO");
}
}
}
}
}
같은 집합인지 검사하는 것은 다른 그래프 알고리즘으로도 해결 가능하지만 해당 문제는 Union Find 의 높은 효율성으로만 해결 가능한 문제이다.
