
크루스칼 알고리즘에 사용되는 개념인 Union Find는 알고리즘 Union Find 게시글을 참고해주세요.
그래프에서 최소한의 비용으로 모든 정점을 연결하기 위한 알고리즘이다.
신장 트리 (Spanning Tree) 란
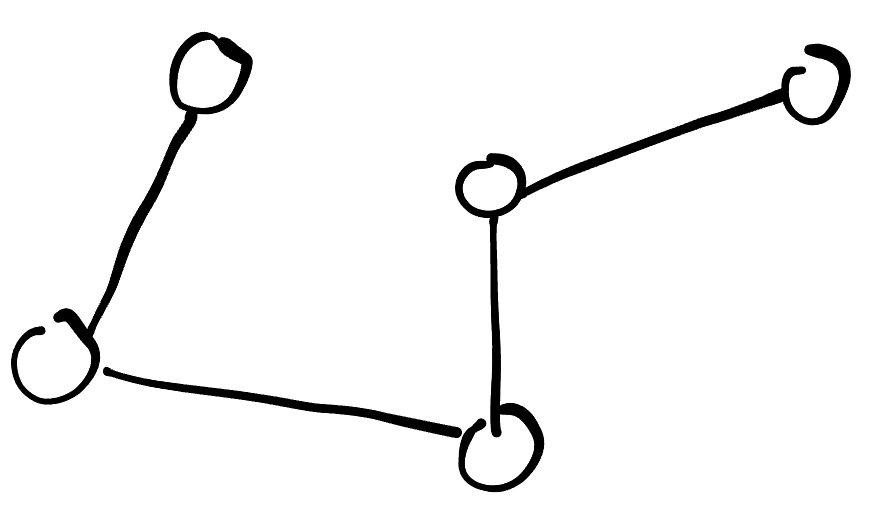
신장 트리란 위 그림처럼 그래프의 모든 정점을 포함하지만 순환하지는 않는 tree를 말한다.
특징
- 하나의 그래프에는 여러 최소 신장 트리가 있을 수 있다.
- 간선의 개수(E) 가 정점의 개수(V) - 1 이다.
- 사이클을 포함하면 안된다.
최소 신장 트리 (Minimum Spanning Tree)
간선에 가중치가 있을 때, 가중치의 합이 가장 작은 신장 트리를 최소 신장 트리라고 한다.
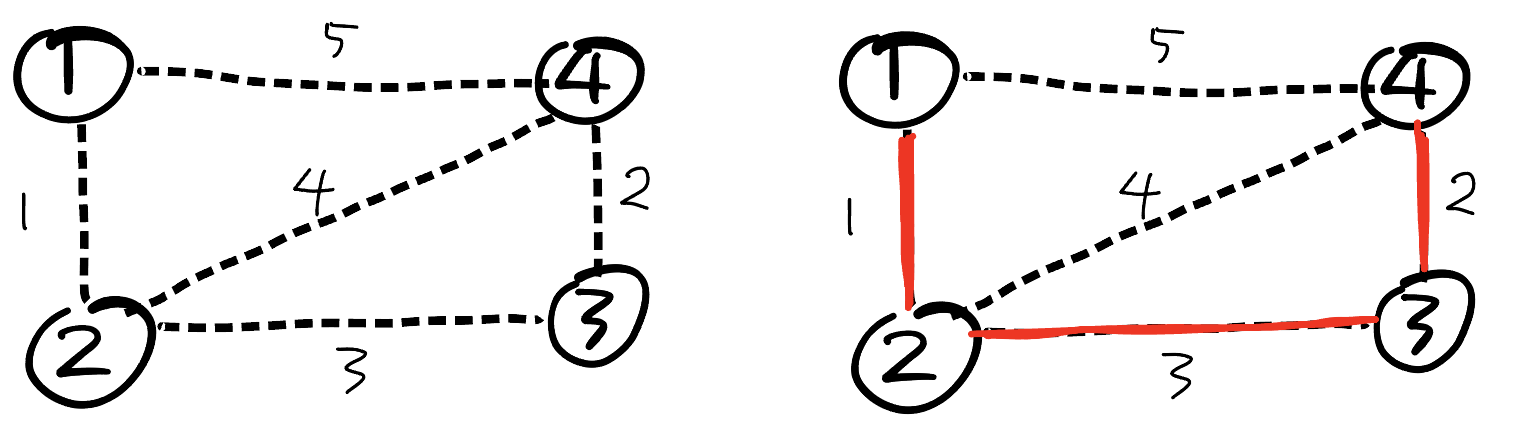
위 그림에서 최소 신장 트리는 빨간색 간선을 선택한 것과 같다. (1-2-3-4)
최소 신장 트리를 구하는 알고리즘에는 대표적으로 크루스칼 알고리즘과 프림 알고리즘이 있다. 컴퓨터 네트워크 수업중에 들어본거같다.
크루스칼 알고리즘을 먼저 알아보자.
크루스칼 알고리즘 (Kruskal's Algorithm)
크루스칼 알고리즘은 탐욕 (Greedy) 알고리즘 이다. 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다.
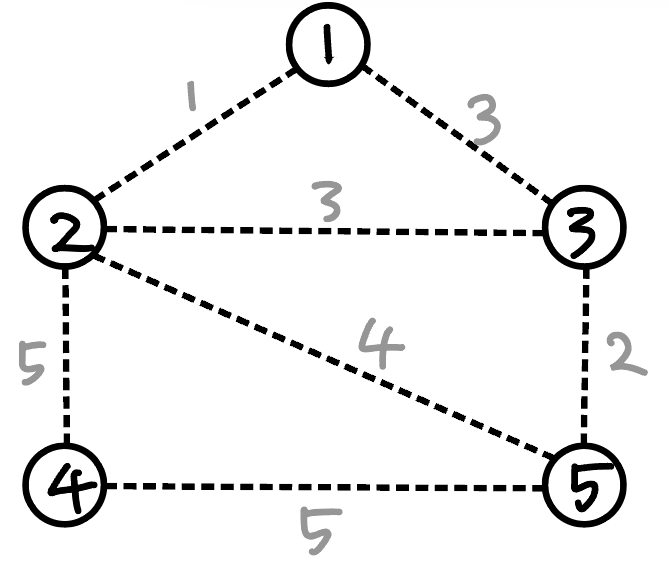
위와 같은 그래프와 간선과 가중치가 있다.
가중치가 가장 작은 간선을 일단 선택한다.
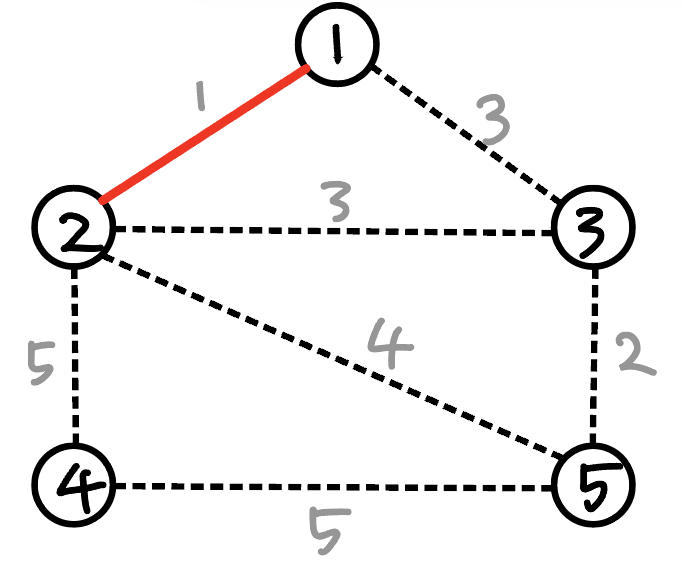
가중치가 1인 (1-2)간선을 선택했다.
또 전체 간선중에 가중치가 가장 작은 것을 선택한다.
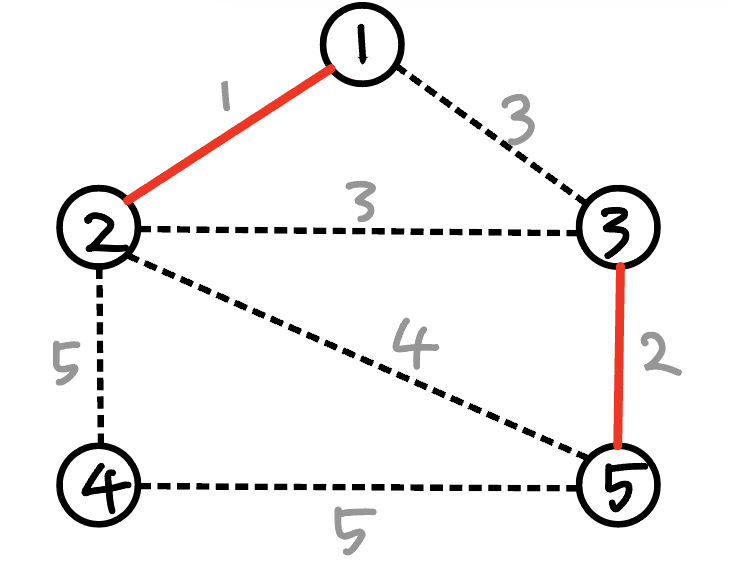
가중치가 2인 (3-5) 간선을 선택했다.
다음으로 가중치가 작은 간선은 두개이므로, 둘 중에 아무거나 선택한다.
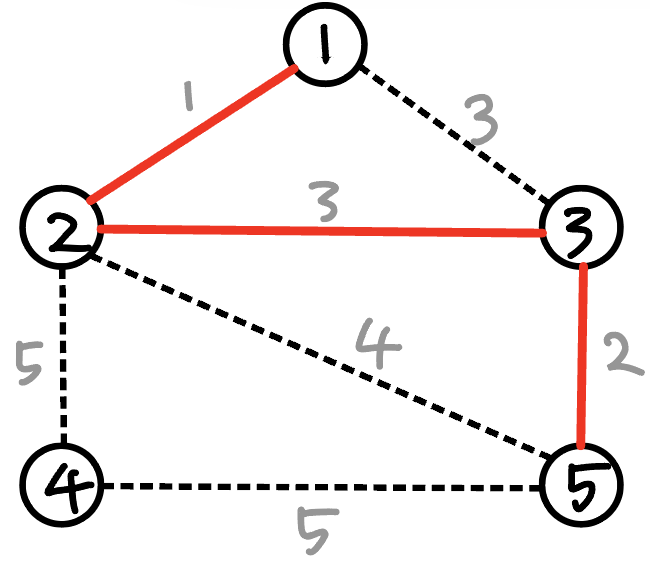
(2-3)간선 을 선택했다.
남은 간선중 가중치가 작은 간선은 가중치 3인 (1-3) 간선인데, 이를 선택해버리면 그래프가 순환하여 신장 트리의 조건에서 벗어난다.
가중치 4인 (2-5)도 마찬가지로 순환하므로 가중치가 5인 간선 중 하나를 선택한다.
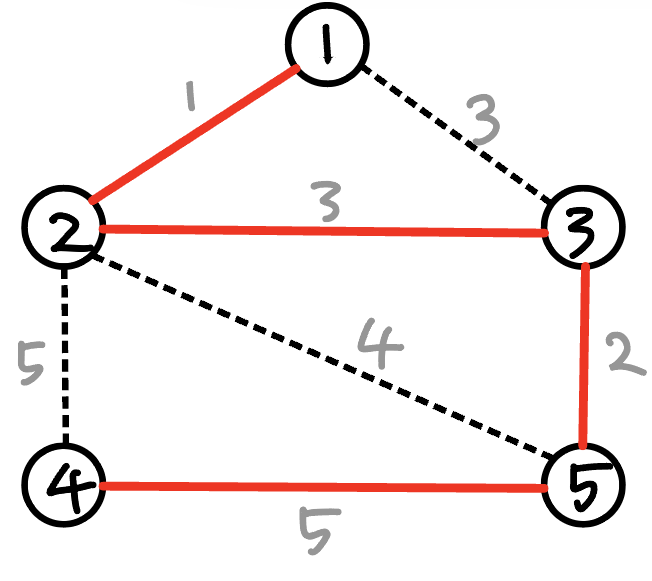
정점이 5개인데 4개의 간선을 선택 했으므로 최소 신장 트리가 완성됐다.
정리
- 남은 간선 중 가장 작은 가중치를 가진 간선을 선택한다. (여기서 Union 연산 활용)
- 하지만 트리가 순환하게 되면 안된다. (여기서 Find 연산 활용)
위를 반복하면 최소 신장 트리를 구할 수 있다.
특별한 케이스의 예외가 있을 것 같으면서도 없는게 신기한 알고리즘이다.
구현
코드로 이를 나타내보자
백준 1922 - 네트워크 연결
시간복잡도
간선의 개수를 E 라고 할때
Union Find는 연산을 모두 최적화한다면 상수 수준이라 무시하고,
간선을 비용 오름차순으로 정렬할때만 시간복잡도가 유의미하므로
이다.
간선
class Edge {
int from;
int to;
int cost;
Edge(int from, int to, int cost) {
this.from = from;
this.to = to;
this.cost = cost;
}
}우선 간선을 나타내기 위해 Edge 클래스를 구현했다.
간선이 가지고 있어야 할 정보는 정점의 번호 두개, 가중치이다.
물론 이정도 문제에서는 이차원배열 int[M][3] 을 사용해도 되지만, 문제가 복잡해지면 클래스가 편할때도 많으므로 클래스로 구현했다.
비용순으로 간선 정렬
List<Edge> edges = new ArrayList<>();
// ..
edges.sort((e1, e2) -> Integer.compare(e1.cost, e2.cost));간선을 낮은 비용순으로 알기위해 간선을 저장한 배열을 간선의 비용을 기준으로 오름차순 정렬해준다.
트리로 집합 표현 - Union Find 연산
static class UnionFind {
int[] parent;
UnionFind(int size) {
this.parent = new int[size];
for(int i = 0; i < size; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] == x) {
return x;
}
return parent[x] = find(parent[x]);
}
// 같은 집합이라면 false 반환
boolean union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA == rootB) {
return false;
}
if (rootA <= rootB) {
parent[rootB] = rootA;
} else {
parent[rootA] = rootB;
}
return true;
}
}간선의 관계를 트리로 표현하기 위해 배열을 사용했다. parent[i]의 값은 i번 노드의 부모 노드의 번호이다. 참고: 알고리즘 Union Find
크루스칼 알고리즘
int answer = 0;
for(Edge edge: edges) {
if (uf.union(edge.from, edge.to)) {
answer += edge.cost;
}
}Union-find 만 구현하고, 가중치 기준으로 정렬만 해주면 크루스칼 알고리즘 자체는 간단하다.
- 정점을 비용이 낮은 순서대로 순회하며
- 루트 노드가 같지 않으면 (같은 집합이 아니면)
- 선택한다. (간선을 트리에 추가한다)
추가로 추가한 간선의 개수가 정점개수 - 1개 일때 반복문을 탈출하면 실행시간을 조금 줄일 수 있다.
전체 코드
import java.util.*;
import java.io.*;
class Main
{
static class Edge {
int from;
int to;
int cost;
Edge(int from, int to, int cost) {
this.from = from;
this.to = to;
this.cost = cost;
}
}
static class UnionFind {
int[] parent;
UnionFind(int size) {
this.parent = new int[size];
for(int i = 0; i < size; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] == x) {
return x;
}
return parent[x] = find(parent[x]);
}
boolean union(int a, int b) {
int rootA = find(a);
int rootB = find(b);
if (rootA == rootB) {
return false;
}
if (rootA <= rootB) {
parent[rootB] = rootA;
} else {
parent[rootA] = rootB;
}
return true;
}
}
public static void main(String args[]) throws Exception
{
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.valueOf(bf.readLine());
int M = Integer.valueOf(bf.readLine());
UnionFind uf = new UnionFind(N + 1);
List<Edge> edges = new ArrayList<>();
while(M-- > 0) {
StringTokenizer st = new StringTokenizer(bf.readLine());
int a = Integer.valueOf(st.nextToken());
int b = Integer.valueOf(st.nextToken());
int c = Integer.valueOf(st.nextToken());
edges.add(new Edge(a, b, c));
}
edges.sort((e1, e2) -> Integer.compare(e1.cost, e2.cost));
int answer = 0;
int count = 0;
for(Edge edge: edges) {
if (uf.union(edge.from, edge.to)) {
answer += edge.cost;
if (++count == N - 1) {
break;
}
}
}
System.out.println(answer);
}
}프림 알고리즘 (Prim's Algorithm)
최소 신장 트리를 구하는 두번째 알고리즘이다.
Union-Find 와 다르게 추가적인 메소드를 구현하지 않아도 되서 개인적으로는 프림 알고리즘을 우선적으로 사용한다.
프림 알고리즘도 마찬가지로 탐욕 (Greedy) 알고리즘이다.
개념 자체는 크루스칼 알고리즘과 유사하다. (가장 작은 가중치를 가진 간선을 탐욕적으로 선택)
- 아무 정점을 트리 집합에 추가한다.
- 트리 집합과 인접한 간선중 가장 가중치가 작은 간선을 트리에 추가한다.
(이미 트리에 포함되어있는 정점으로 가는 간선은 제외) - 트리 집합이 전체 정점의 집합과 같아질 때 까지 2번 과정을 반복한다.
되게 심플하다. 이를 코드로 효율적으로 구현하려면 다음과 같은 아이디어를 사용한다.
우선순위큐에 인접한 간선들을 넣고, 가장 가중치가 작은 간선 꺼냄boolean[] visited배열로 트리 집합에 추가됐는지 판별count로 트리 집합에 포함된 정점 개수 카운팅
백준 1197 - 최소 스패닝 트리
또 다른 MST 문제이다.
인접 리스트로 구현했다.
class Edge {
int to, weight;
Edge(int to, int weight) {
this.to = to;
this.weight = weight;
}
}
int prim(List<List<Edge>> graph, int v, int start) {
int ans = 0;
Queue<Edge> pq = new PriorityQueue<>(
(e1, e2) -> Integer.compare(e1.weight, e2.weight));
boolean[] visited = new boolean[v + 1];
// 시작 지점 설정을 위해 시작 간선으로 가는 가중치 0인 가상의 간선 추가
pq.add(new Edge(start, 0));
int count = 0; // 트리 집합에 포함된 정점 개수 카운팅
while (!pq.isEmpty() && count < v) { // 트리 집합의 개수가 v와 같아지면 멈춤
Edge cur = pq.poll();
if (visited[cur.to]) continue;
visited[cur.to] = true;
ans += cur.weight;
count++;
for (Edge next : graph.get(cur.to)) {
if (!visited[next.to]) {
pq.offer(next);
}
}
}
return ans;
}입출력 부분은 작성하지 않겠다.
visited 배열 대신 Set 으로 트리 집합을 구현해도 상관없다.
코드를 보면 우선순위큐를 사용하는 부분에서 다익스트라가 생각난다.
둘 다 "인접한 것 중 가장 작은 가중치를 가진 것을 탐욕적으로 선택" 한다는 점에서 유사한 점이 있다. 물론 로직 자체는 완전 다르다.
