그룹함수
-
전체 데이터에서 통계적인 결과를 구하기 위해 사용
-
하나 이상의 행을 그룹으로 묶어 연산하여 총합, 평균 등 하나의 결과를 구함
-
그룹함수 종류
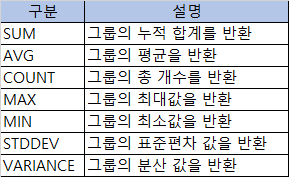
- SUN, AVG, MAX, MIN, STDDEV, VARIANCE
- NULL 값을 제외하고 계산
SELECT sum(sal), # 합계
avg(sal), # 평균
max(sal), # 최대값
min(sal), # 최소값
stddev(sal), # 표준편차
variance(sal) # 분산
FROM emp;
->
SUM(SAL) AVG(SAL) MAX(SAL) MIN(SAL) STDDEV(SAL) VARIANCE(SAL)
---------- ---------- ---------- ---------- ----------- -------------
25335 2111.25 5000 950 1186.23569 1407155.11
- COUNT
- 테이블의 행 개수 반환
* NULL 값을 제외하고 개수를 셈 - COUNT(특정칼럼명)
SELECT count(comm)
FROM emp;
->
COUNT(COMM)
-----------
4
* NULL 값을 포함하고 개수를 셈 - COUNT(*)
SELECT count(*)
FROM emp;
->
COUNT(*)
----------
12GROUP BY 절
-
데이터들을 원하는 그룹으로 묶음
-
특정 컬럼을 기준으로 그룹별로 묶을 필요가 있음
-
특정 컬럼을 기준으로 집계(sum, avg, count 등)를 구하는데 사용
-
그룹함수로 묶지 않은 컬럼을 SELECT절에 사용하면 묶은 컬럼과 묶지 않은 컬럼 결과의 개수차이로 매치가 불가능하기 때문에 오류가 발생
-
형식
SELECT 컬럼명, 그룹함수
FROM 테이블명
WHERE 조건 (연산자)
GROUP BY 칼럼명;- 예시
SELECT DEPTNO, JOB, COUNT(*), SUM(SAL)
FROM EMP
GROUP BY DEPTNO, JOB; # DEPTNO와 JOB을 그룹으로 묶음
->
DEPTNO JOB COUNT(*) SUM(SAL)
---------- ------------------ ---------- ----------
20 CLERK 1 1210
30 SALESMAN 4 5600
20 MANAGER 1 2975
30 CLERK 1 950
10 PRESIDENT 1 5000
30 MANAGER 1 2850
10 CLERK 1 1300
10 MANAGER 1 2450
20 ANALYST 1 3000
# DEPTNO와 JOB을 기준으로 하나의 그룹으로 만들어 해당 그룹의 집계(COUNT, SUM)를 계산해서 출력HAVING 절
-
GROUP BY로 그룹을 만들고 HAVING절로 그룹의 결과를 제한할 수 있음
-
그룹에 WHERE 절 처럼 조건을 추가
-
조건이 True인 것만 결과 출력
SELECT DEPTNO, JOB, COUNT(*), SUM(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
HAVING MAX(SAL) >= 3000; # 그룹으로 나눈 값에서 SAL의 가장 큰 값이 3000이상인 데이터만 출력
->
DEPTNO JOB COUNT(*) SUM(SAL)
---------- ------------------ ---------- ----------
10 PRESIDENT 1 5000
20 ANALYST 1 3000** 참고
- 성윤정 『데이터베이스 성능의 최적화 Oracle 11g 프로그래밍』, 북스홀릭(2011)
