1. 정렬
1) numpy.sort( )
정렬 후 ndarray로 리턴
a = np.array([3,5,2,7,8])
* np.sort(a)
-> [2, 3, 5, 7, 8] # 1차원 정렬
* np.sort(a)[::-1] # reverse라는 메소드가 없어서 정렬후 역순으로 슬라이싱을 한 후 리턴
-> [8, 7, 5, 3, 2]
a_2d = np.array([[20,3,100],[1,200,30],[300,10,2]])
* np.sort(a_2d, axis=0) # 2차원 열을 기준으로 정렬
-> [[ 1, 3, 2],
[ 20, 10, 30],
[300, 200, 100]]
* np.sort(a_2d, axis=1) # 2차원 행을 기준으로 정렬
-> [[ 3, 20, 100],
[ 1, 30, 200],
[ 2, 10, 300]]
* np.sort(a_2d, axis=0)[::-1] # reverse라는 메소드가 없어서 정렬후 역순으로 슬라이싱을 한 후 리턴
-> [[300, 200, 100],
[ 20, 10, 30],
[ 1, 3, 2]]2) ndarray.sort( )
ndarray 자체 정렬
* a.sort() # ndarray인 a 자체정렬
-> [2, 3, 5, 7, 8]
* a_2d.sort(axis=0) # 2차원 열을 기준으로 정렬
-> [[ 1, 3, 2],
[ 20, 10, 30],
[300, 200, 100]]
* a_2d.sort(axis=1) # 2차원 행을 기준으로 정렬
-> [[ 3, 20, 100],
[ 1, 30, 200],
[ 2, 10, 300]]3) numpy.argsort( )
정렬된 인덱스(값의 크기에 따라 인덱스를 지정)의 배열을 ndarray로 리턴
a_2d = np.array([[20,3,100],[1,200,30],[300,10,2]])
* np.argsort(a_2d)
-> [[1, 0, 2],
[0, 2, 1],
[2, 1, 0]]
* a_2d[:, 1] # 행은 전체를 추출하고 열은 1열만 추출
-> [ 3, 200, 10]
* np.argsort(a_2d[:, 1]) # 1열을 기준으로 정렬한 인덱스
-> [0, 2, 1]
* a_2d[np.argsort(a_2d[:, 1])]
# 1열을 기준으로 정렬한 인덱스를 바탕으로 행을 정렬
# 정렬한 인덱스를 바탕으로 정렬하면 오름차순으로 정렬된 값을 리턴
-> [[ 20, 3, 100],
[300, 10, 2],
[ 1, 200, 30]]2. 집계함수
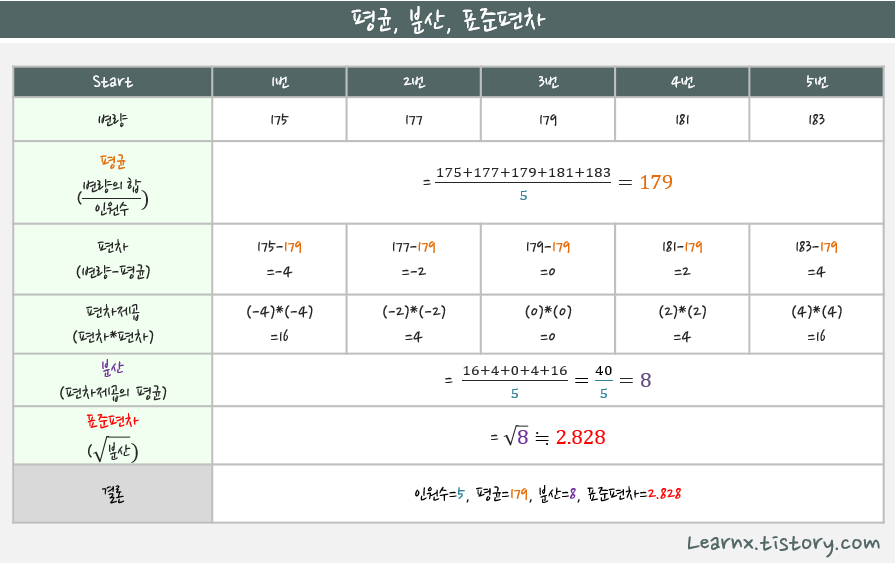
합계, 평균, 최대값, 최소값, 표준편차 , 분산
a_2d = np.arange(12).reshape(3,4)
-> [[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]1) 합계 : sum( )
* np.sum(a_2d) # 전체 요소값 합계
-> 66
* np.sum(a_2d, axis=0) # 각 열의 요소값 합계
-> [12, 15, 18, 21]
* np.sum(a_2d, axis=1) # 각 행의 요소값 합계
-> [ 6, 22, 38]2) 평균 : mean( )
* np.mean(a_2d) # 전체 요소값 평균
-> 5.5
* np.mean(a_2d, axis=0) # 각 열의 요소값 평균
-> [4., 5., 6., 7.]
* np.mean(a_2d, axis=1) # 각 행의 요소값 평균
-> [1.5, 5.5, 9.5]3) 최대값 : max( ), 최소값 : min( )
* np.max(a_2d) # 전체 요소 중 가장 큰 값
-> 11
* np.max(a_2d, axis=0) # 각 열의 요소 중 가장 큰 값
-> [ 8, 9, 10, 11]
* np.max(a_2d, axis=1) # 각 행의 요소 중 가장 큰 값
-> [ 3, 7, 11]
* np.min(a_2d) # 전체 요소 중 가장 작은 값
-> 0
* np.min(a_2d, axis=0) # 각 열의 요소 중 가장 작은 값
-> [0, 1, 2, 3]
* np.min(a_2d, axis=1) # 각 행의 요소 중 가장 작은 값
-> [0, 4, 8]4) 표준편차 : std( )
* np.std(a_2d) # 전체 요소값 표준편차
-> 3.452052529534663
* np.std(a_2d, axis=0) # 각 열의 요소값 표준편차
-> [3.26598632, 3.26598632, 3.26598632, 3.26598632]
* np.std(a_2d, axis=1) # 각 행의 요소값 표준편차
-> [1.11803399, 1.11803399, 1.11803399]5) 분산 : var( )
* np.var(a_2d) # 전체 요소값 분산
-> 11.916666666666666
* np.var(a_2d, axis=0) # 각 열의 요소값 분산
-> [10.66666667, 10.66666667, 10.66666667, 10.66666667]
* np.var(a_2d, axis=1) # 각 행의 요소값 분산
-> [1.25, 1.25, 1.25]