
발표의 참견
- 프로젝트 명 : 발표의 참견
- 개요 : 사용자의 발표 영상을 인공지능 시스템이 언어/비언어적 표현을 분석 후 발표 능력 측정 및 피드백을 제공하는 웹 어플리케이션. 자세, 어투, 속도, 발음, 표정 등 다양한 지표를 통해 분석을 진행하여 객관적이고 구체적인 측정 결과를 제공하고, 측정 결과를 기반으로 피드백을 제공하여 사용자의 발표 능력 향상에 기여한다.
- 팀명 : Goofanaka
- 팀원 : 손기훈 김동건 유주아 김은찬
- 개발 기간 : 2021년 01월 19일 ~ 2021년 4월 28일
- Github 링크
DEMO

적용 기술
- 개발 언어 : Python, Java Script
- 웹 구현 : Django, HTML5, CSS3, JQuery, AWS EC2, Nginx
- 데이터베이스 : MongoDB Atlas
- 사용 라이브러리 : OpenPose, OpenCV, Mediapipe, Tensorflow2.0, Praat-Parselmouth, Amazon Transcribe, Numpy, Pandas, KoNLPy
- 협업 도구 : Git, Github
아키텍처
1 . 프로젝트 아키텍처
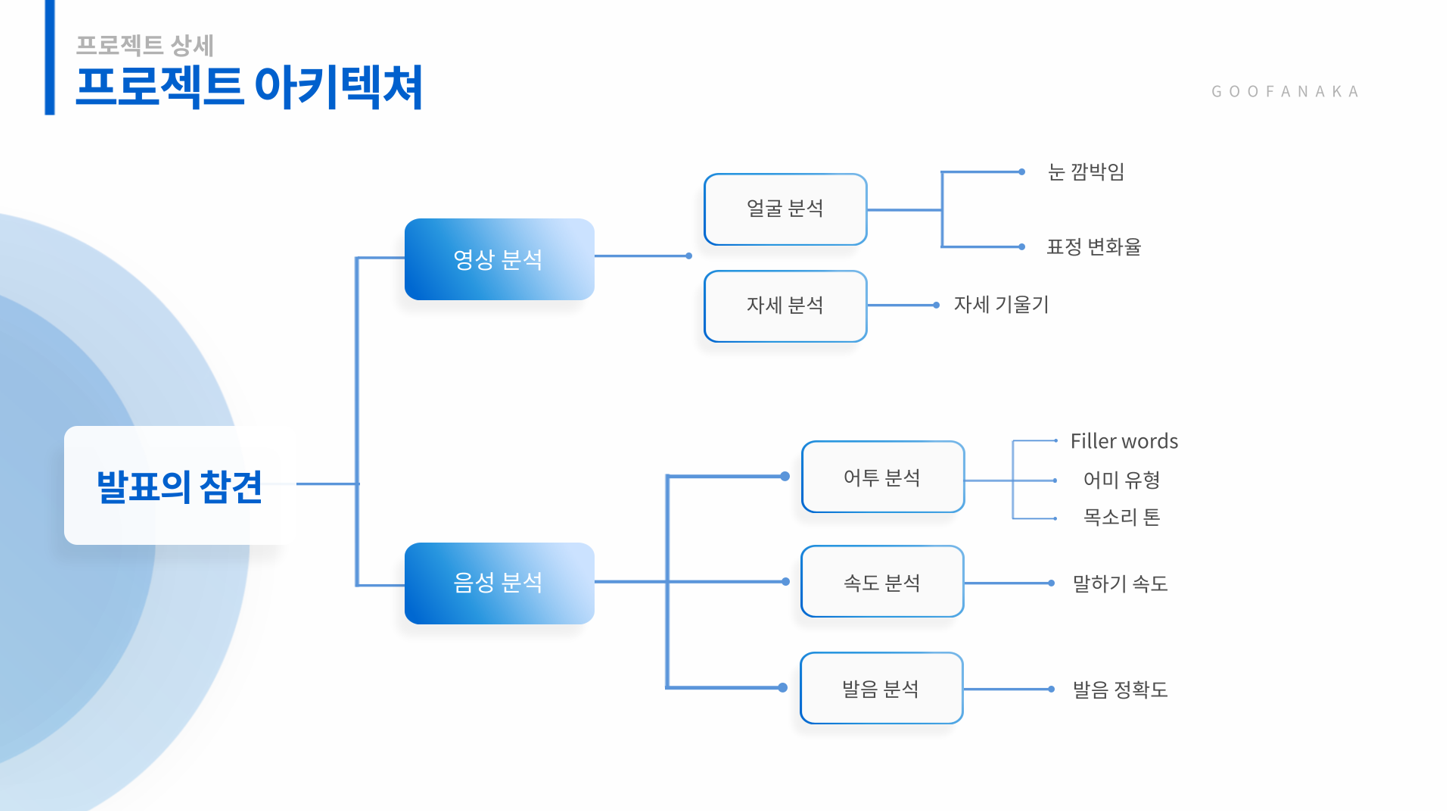
2. 서버 아키텍처

프로젝트에서 맡은 역할
-
자세 분석 엔진 제작
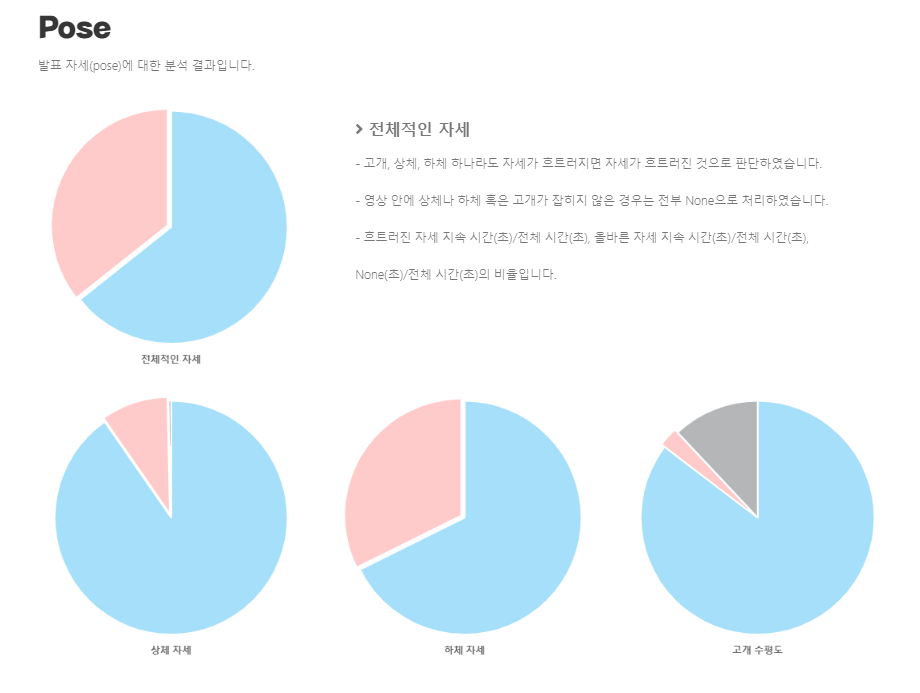
동영상 파일을 받으면 openpose의 coco모델을 사용해 동영상 내의 사람의 관절을 찾고 관절에 점을 생성한다. 점을 생성한 후 눈, 어깨, 골반, 무릎 각각 두 점의 기울기를 구해 올바른 자세인지, 흐트러진 자세인지 판별한다. -
목소리톤 분석 엔진 제작
동영상 파일에서 오디오를 추출하고, praat-parselmouth 라이브러리로 오디오를 분석해서 시간-주파수를 반환하고, 주파수의 평균과 표준편차를 구해서 목소리의 평균 주파수와 얼마나 목소리 톤이 다양하냐를 분석한다. -
자세 분석 엔진을 실행하는 개발환경 구성
AWS EC2 g4dn_2xlarge 환경에 OpenCV가 GPU를 사용하도록 설정하고, Django 서버를 구축했다. 전에 만들어놓은 자세 분석 엔진을 서버에 구축하고 영상이 들어오면 분석을 하고 json객체로 리턴하고, DB에 저장하는 환경을 구성했다.
기록하고 싶은 코드
1. opencv gpu로 가동
2차 프로젝트때는 윈도우 환경에서 세팅을 했었고, 이번 3차때는 AWS EC2환경에 빌드를 했다.
윈도우랑 필요한 파일들은 비슷했지만 ubuntu18.04 운영체제에 설치하는거여서 조금 힘들었다. 일단 EC2환경의 gpu버전을 맞춰서 nvidia-driver, CUDA, CuDNN을 깔아야 하는데 버전 맞추기가 생각보다 어려웠고, 여기서 많이 헤맸다. 한 이틀정도를 열심히 찾아서 버전을 맞추는데 성공했다. 그런데 CMake하는 과정에서 cudnn 버전을 못찾는 등의 오류가 발생했다. 이 문제도 한 이틀정도 걸렸는데 빌드하는 과정에서 직접 버전을 입력해주고 path를 직접 설정해줘서 문제를 해결했다.
전보다는 오래걸리지 않았지만 이 문제를 해결하기 위해 오랜시간을 사용했다. 하지만 로컬이 아니 EC2환경에 설치했다는 것에 큰 의미를 두고, 포기하지 않고 해냈다는 거에 뿌듯함을 느꼈다.
EC2 g4dn_2xlarge를 사용했는데 확실히 gpu가 좋아서 처리 속도가 굉장히 빨랐다.
2. 시간-주파수

동영상에서 음성만 추출해 음성을 분석하는 것이다.
동영상에서 음성만 추출하는 것은 굉장히 쉬었다. moviepy라는 라이브러리를 사용하면 간단하게 추출할 수 있다. 그런데 추출한 음성으로 원하는 x좌표는 시간, y좌표는 주파수 형태를 만들기는 좀 어려웠다.
처음에 librosa라는 라이브러리를 사용해서 시간-주파수 값을 얻으려고 했는데 시간-진폭값을 구할 수 있었고, 시간-주파수-데시벨 형식으로 구할 수 있었다. 그러나 이러한 값으로는 그래프를 읽기 어려웠고, 정확한 기준을 잡기가 어려워서 사용하지 않았다.
그러다 praat-parselmouth라는 라이브러리를 찾았고, 이걸 사용하면 원하는 시간-주파수 값을 구할 수 있었다.
음악 파일을 받아 praat-parselmouth를 사용해 시간값과 주파수 값을 얻는다.
3. 목소리 분석

시간-주파수 값을 가지고 어떻게 분석을 해야할지 고민했다. 발표를 잘하는 목소리의 기준을 어떻게 잡아야할까? 그리고 사람마다 다양한 주파수를 가지고 있는데 이 값으로 발표를 잘한다고 판단을 할 수 있을까? 등의 고민이었다.
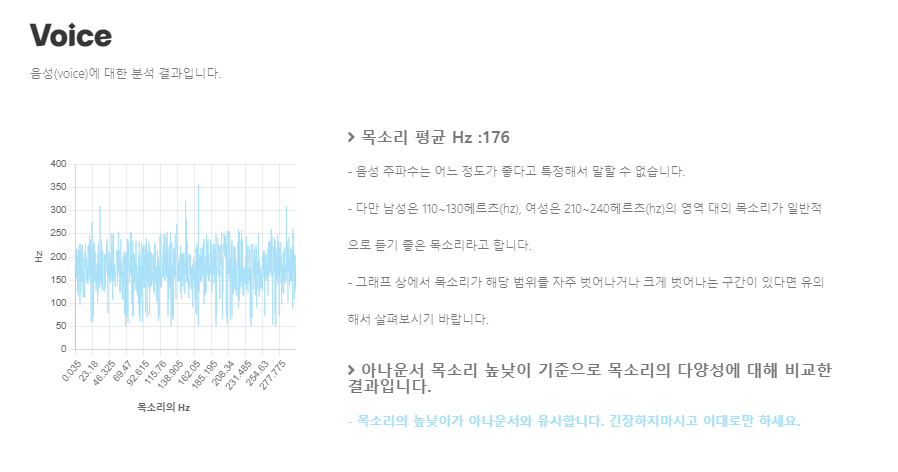
일단 발표를 잘하는 목소리의 기준을 정할 수 있는 자료를 찾기 매우 어려웠다. 그래서 아나운서가 말하는 영상을 가지고 기준을 세우면 될 것 같았다. 남녀 아나운서 영상을 구해 프로그램을 돌리고 기준을 세웠다. 그 기준으로 발표를 잘했다, 못했다가 아니라 참고하라는 식으로 피드백을 해주기로했다.
그리고 사람마다 다양한 주파수를 가지고 있고 주파수로 발표를 잘한다 못한다의 기준을 내릴 수 없어 발표자의 평균 주파수 값과 아나운서의 평균 주파수를 보여주고 참고하라는 식으로 피드백을 주기로 했다.
또 주파수의 표준편차를 가지고 목소리 높낮이 다양성을 얼마나 가져가냐를 구할 수 있어서 평균을 구하고 표준편차를 구하고 아나운서와 비교해 발표시 얼마나 목소리 높낮이의 다양성을 가지냐도 피드백을 주기로 했다.
기준은 아래와 같이 정했다.

Preview image
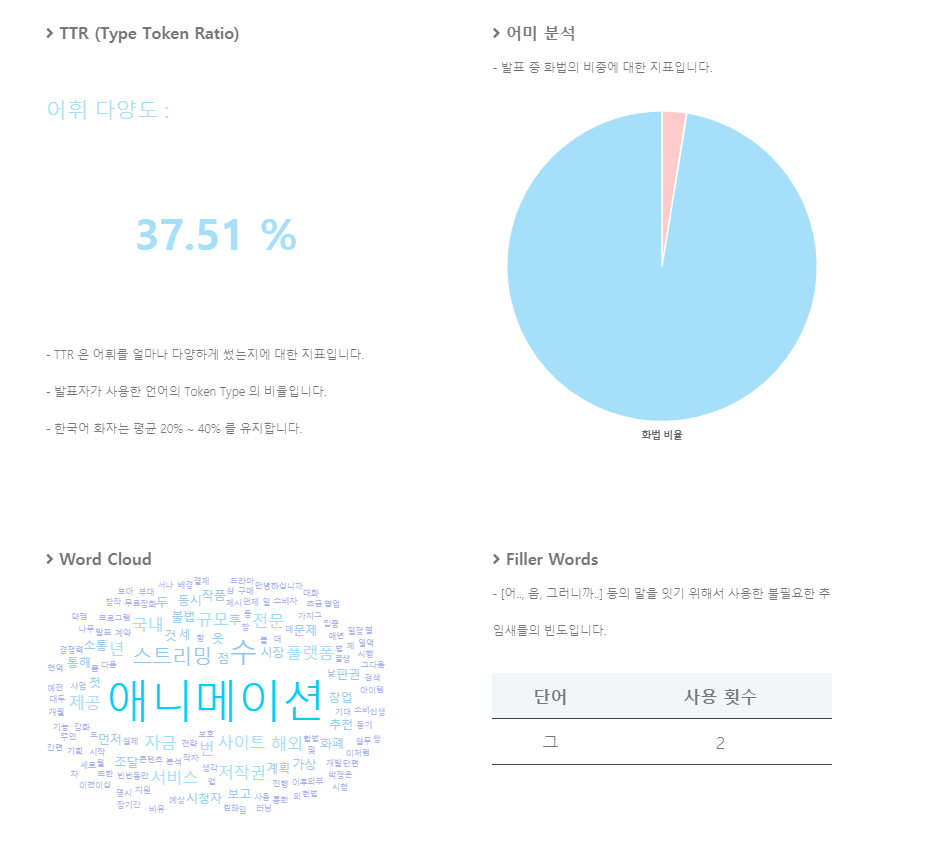
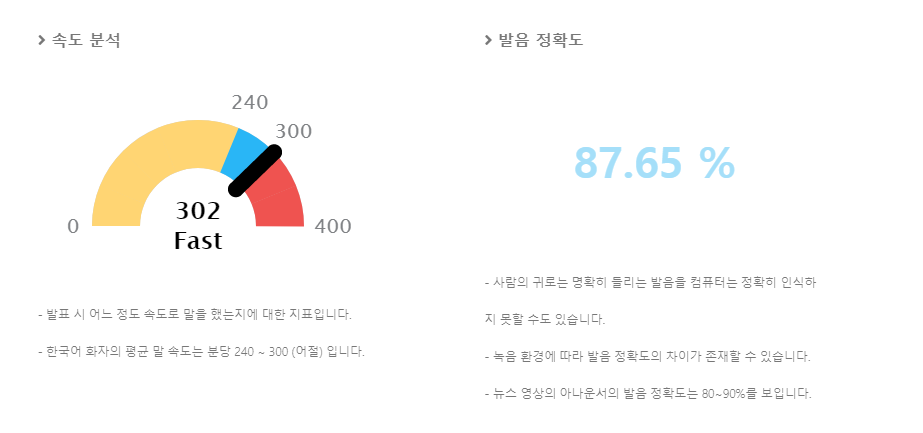
.png)
느낀점
1. 잘한점
-
1차 프로젝트부터 마지막 프로젝트까지 같은 팀원들로 진행했는데 불화없이 매일 웃으면서 재밌게 프로젝트를 진행했다. 정말 좋은 팀원들을 만났고 감사하다.
-
AWS EC2 환경에 서버와 엔진을 구축하고 실행시킨 점
-
opencv gpu로 가동시킬때 환경설정 하는 부분에서 많은 시간을 쏟았는데 그 때 포기하지않고 해결한 점
-
시간에 쫓겨 급하게 하지 않고, 계획을 잘 세워서 시간안에 프로젝트를 완성도 있게 마무리했다.
2. 아쉬운점
-
학습된 모델을 가져와서 사용했고, 직접 데이터를 수집하고 모델을 학습해서 사용하지 못한 점이 아쉽다.
-
빌드된 환경을 도커 이미지로 만들어 다른 팀원들과 환경을 공유하지 못한 점이 아쉽다.
-
내가 맡은 부분은 잘 아는데 다른 팀원이 맡은 부분의 내용이나 코드는 제대로 살펴보지 않았다. 그래서 프로젝트 도중에 이해 안 가는 부분이 많았다.
-
이번 3차때는 엔진을 만들고, 서버를 구축하느라 git을 제대로 활용하지 않았다.
3. 해결 / 개선 방법
-
데이터를 수집해서 모델을 직접 만들어보는 연습을 해야된다.
-
도커 이미지 빌드 하는 방법을 공부하고 직접 만들어서 배포해보기
-
다른 팀원들이 짠 코드나 내용을 숙지하고 공부하기
-
git을 적극적으로 활용하기 코드를 추가하거나 수정한 부분이 있으면 바로바로 git에 올려 관리하기
6개월이라는 길지만 짧은 시간이 끝났다. 처음에 시작할 때는 6개월이라는 시간이 엄청나게 긴 시간이라 생각했다. 근데 뒤돌아보면 정말 짧은 시간이었다.
6개월동안 실력적으로는 많이 안 늘었을 수 있다. 그러나 정말 좋은 친구들을 만났고, 하나는 확실하게 얻은 것 같다. 오랜시간이 걸리더라도 공부를 하고 찾다보면 해결책을 찾을 수 있다는 것! 포기만 하지 않으면 된다!는 것

오랜시간이 걸리더라도 존버를 하다보면 해결책을 찾을 수 있다는 것! 포기만 하지 않으면 된다!
저도 오늘 존버 성공입니다!