89일차 시작.... (회귀분석 2)
[교육] Python ML

📊 scipy의 회귀 모델
📌 linregress 모델 사용
- 주제
- IQ(연속형)에 따른 시험점수(연속형) 예측
- 1. 라이브러리 Import
from scipy import stats import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
- 2. 데이터 준비
score_iq = pd.read_csv("../testdata/score_iq.csv") print(score_iq.head(3)) # sid score iq academy game tv # 0 10001 90 140 2 1 0 # 1 10002 75 125 1 3 3 # 2 10003 77 120 1 0 4 # 사용 feature만으로 구성 df = score_iq.loc[:, ['score', 'iq']] print(df.head(3)) # score iq # 0 90 140 # 1 75 125 # 2 77 120
- 3. 상관관계 분석
# 방법1 : pandas의 corr() print(df.corr()) # score iq # score 1.00000 0.88222 # iq 0.88222 1.00000 # 상관계수 : 0.88 -> 양의 방향으로 강한 관계를 갖는다. # 상관관계 만족 # 방법2 : numpy의 corrcoef() x = df['iq'] y = df['score'] print(np.corrcoef(x, y)[0, 1]) # 상관계수 : 0.8822203446134701
- 4. 상관분석 시각화
plt.scatter(x, y) plt.show() sns.heatmap(df.corr()) plt.show()
- 5. 인과관계가 성립되었다고 가정
- 6. 모델 생성
- 회귀모델 : stats.linregress(feature, label)lr = stats.linregress(x, y) print(lr) # LinregressResult( # slope=0.6514309527270075, # intercept=-2.8564471221974657, # rvalue=0.8822203446134699, # pvalue=2.8476895206683644e-50, # stderr=0.028577934409305443, # intercept_stderr=3.546211918048538 # ) # 괜찮은 모델임
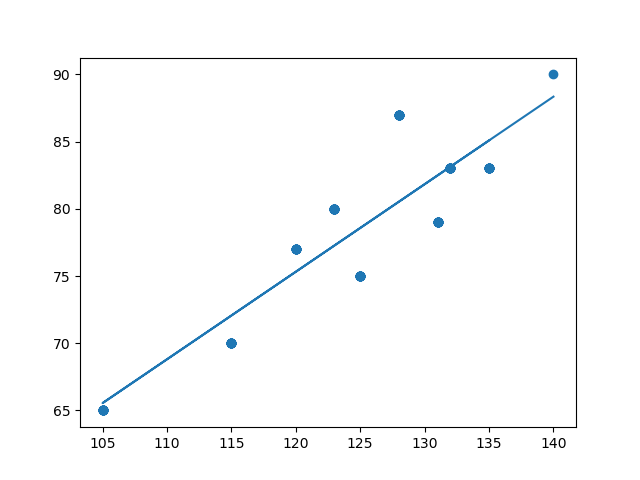
- 7. 상관관계 그래프에서 회귀 모델의 추세선 시각화
plt.scatter(x, y) # feature와 label의 상관관계 그래프 y_hat = lr.slope * x + lr.intercept plt.plot(x, y_hat) # feature와 예측값의 추세선 plt.show()
- 8. 점수 실제 예측
print("점수 예측 : ", lr.slope * 150 + lr.intercept) print("점수 예측 : ", lr.slope * 180 + lr.intercept) # 점수 예측 : 94.85819578685366 # 점수 예측 : 114.40112436866387
📊 회귀 모델 실습
📌 회귀 모델 실습1 - linregress모델
- 주제
지상파 시청 시간을 입력하면 어느 정도의 운동 시간을 갖게 되는지 회귀분석 모델을 작성한 후에 예측하시오.참고1 : [ 결측치는 해당 칼럼의 평균 값을 사용하기로 한다. ]
참고2 : [ 이상치가 있는 행은 제거. 운동 10시간 초과는 이상치로 한다. ]
- 1. 라이브러리 Import
# 1. 라이브러리 Import from io import StringIO # 일반 문자열로 구조화되지 않은 데이터를 구조화시키는 역할 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats
- 2. 데이터 준비
data = StringIO(''' 구분,지상파,종편,운동 1,0.9,0.7,4.2 2,1.2,1.0,3.8 3,1.2,1.3,3.5 4,1.9,2.0,4.0 5,3.3,3.9,2.5 6,4.1,3.9,2.0 7,5.8,4.1,1.3 8,2.8,2.1,2.4 9,3.8,3.1,1.3 10,4.8,3.1,35.0 11,NaN,3.5,4.0 12,0.9,0.7,4.2 13,3.0,2.0,1.8 14,2.2,1.5,3.5 15,2.0,2.0,3.5 ''') df = pd.read_csv(data) print(df.head(3)) # 구분 지상파 종편 운동 # 0 1 0.9 0.7 4.2 # 1 2 1.2 1.0 3.8 # 2 3 1.2 1.3 3.5
- 3. 결측값 확인
print(df.info()) # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 구분 15 non-null int64 # 1 지상파 14 non-null float64 # 2 종편 15 non-null float64 # 3 운동 15 non-null float64 # 지상파에 결측값 1개 존재
- 3-1. 결측값 채우기
df = df.fillna(df['지상파'].mean()) print(df.info()) # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 구분 15 non-null int64 # 1 지상파 15 non-null float64 # 2 종편 15 non-null float64 # 3 운동 15 non-null float64 # 지상파 feature의 결측치 제거 완료
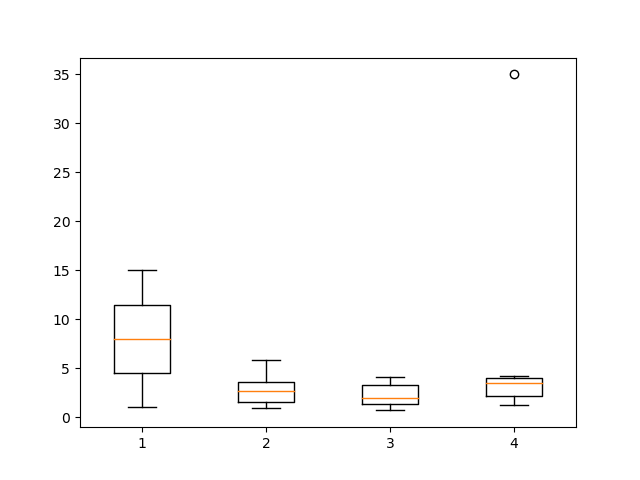
- 4. 이상치 확인
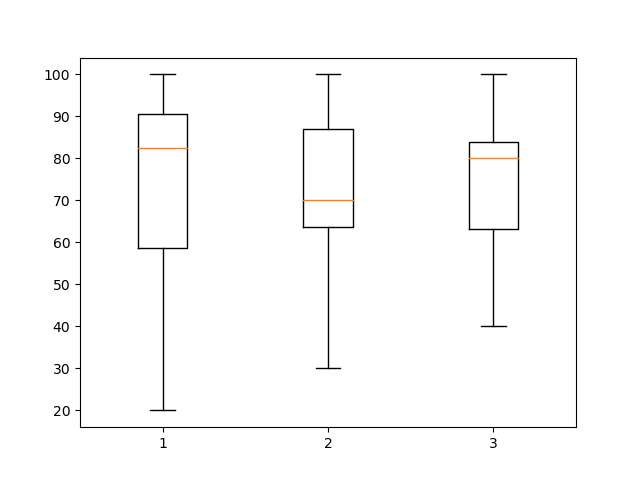
print(df.describe()) # 구분 지상파 종편 운동 # count 15.000000 15.000000 15.000000 15.000000 # mean 8.000000 2.707143 2.326667 5.133333 # std 4.472136 1.464077 1.190118 8.327379 # min 1.000000 0.900000 0.700000 1.300000 # 25% 4.500000 1.550000 1.400000 2.200000 # 50% 8.000000 2.707143 2.000000 3.500000 # 75% 11.500000 3.550000 3.300000 4.000000 # max 15.000000 5.800000 4.100000 35.000000 # 운동 feature에 이상치가 존재할 확률이 높음 plt.boxplot(df) plt.show() # 4번 feature -> 운동 feature에 이상치 1개 발견 # 추가로 운동 feature에 10시간을 초과하면 이상치로 간주
- 4-1. 이상치 행 제거
df = df[df['운동'] <= 10] print(df.describe()) # 구분 지상파 종편 운동 # count 14.000000 14.000000 14.000000 14.000000 # mean 7.857143 2.557653 2.271429 3.000000 # std 4.605300 1.395498 1.214925 1.077747 # min 1.000000 0.900000 0.700000 1.300000 # 25% 4.250000 1.375000 1.350000 2.100000 # 50% 7.500000 2.453571 2.000000 3.500000 # 75% 11.750000 3.225000 3.400000 3.950000 # max 15.000000 5.800000 4.100000 4.200000 # 이상치 행 제거 완료
- 5. 지상파, 운동 간의 상관관계 확인
df1 = df.loc[:, ['지상파', '운동']] print(df1.corr()) # 지상파 운동 # 지상파 1.000000 -0.865535 # 운동 -0.865535 1.000000 # 상관관계 분석 : 음의 방향으로 강한 관계를 갖는다. # 상관관계 만족
- 6. feature, label 분리
x = df['지상파'] y = df['운동']
- 7. 모델 생성
model = stats.linregress(x, y) print('p-value : ', model.pvalue) print('기울기(slope) : ', model.slope) print('편향(intercept) : ', model.intercept) # p-value : 6.347578533142469e-05 # 기울기(slope) : -0.6684550167105406 # 편향(intercept) : 4.709676019780582
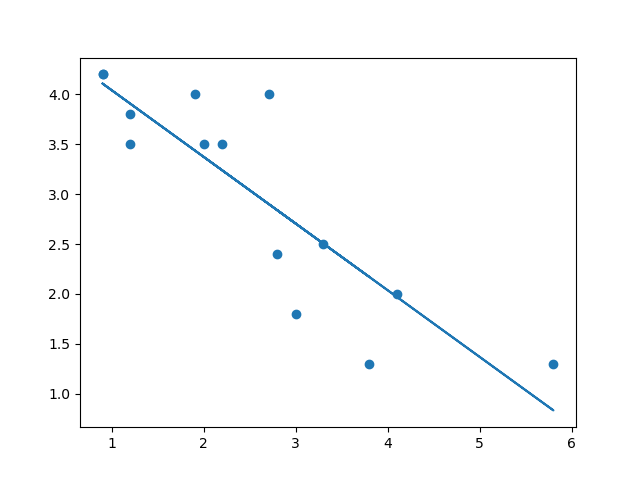
- 8. 상관관계 그래프에 모델 추세선 그리기
plt.scatter(x, y) y_hat = model.slope * x + model.intercept plt.plot(x, y_hat) plt.show()
📌 회귀 모델 실습2 - ols 모델 사용
- 주제
적절성이 만족도에 주는 영향이 어떤지 회귀 모델을 생성해서 파악하고 예측하시오.
- 1. 라이브러리 Import
import pandas as pd import matplotlib.pyplot as plt import statsmodels.formula.api as smf
- 2. 데이터 준비
df = pd.read_csv("../testdata/drinking_water.csv") print(df.head(3)) # 친밀도 적절성 만족도 # 0 3 4 3 # 1 3 3 2 # 2 4 4 4
- 3. 결측치 확인
print(df.info()) # 0 친밀도 264 non-null int64 # 1 적절성 264 non-null int64 # 2 만족도 264 non-null int64 # 결측치 없음 print(df.isnull().sum()) # 친밀도 0 # 적절성 0 # 만족도 0
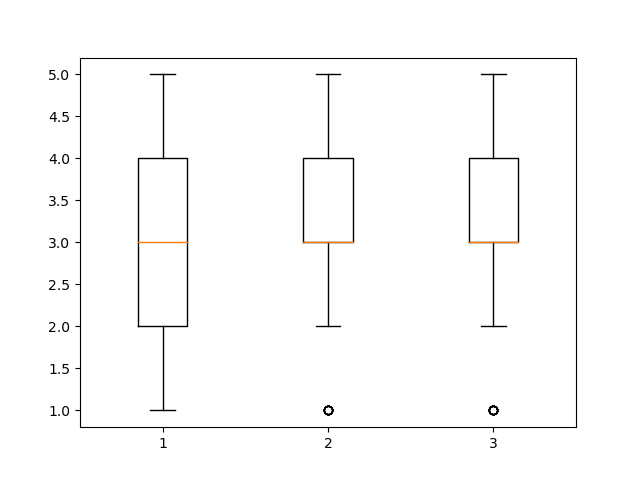
- 4. 이상치 확인
print(df.describe()) # 친밀도 적절성 만족도 # count 264.000000 264.000000 264.000000 # mean 2.928030 3.132576 3.094697 # std 0.970345 0.859657 0.828744 # min 1.000000 1.000000 1.000000 # 25% 2.000000 3.000000 3.000000 # 50% 3.000000 3.000000 3.000000 # 75% 4.000000 4.000000 4.000000 # max 5.000000 5.000000 5.000000 # 이상치가 존재하지 않아보임 plt.boxplot(df) plt.show() # 적절성, 만족도 feature에 각각 이상치 1개씩 존재
- 4-1. 이상치 행 제거
df = df[df['적절성'] > 1] df = df[df['만족도'] > 1] print(df.describe()) # 친밀도 적절성 만족도 # count 254.000000 254.000000 254.000000 # mean 2.976378 3.204724 3.173228 # std 0.940646 0.783613 0.739560 # min 1.000000 2.000000 2.000000 # 25% 3.000000 3.000000 3.000000 # 50% 3.000000 3.000000 3.000000 # 75% 4.000000 4.000000 4.000000 # max 5.000000 5.000000 5.000000 # 이상치 행 제거 완료
- 5. 모델 생성
model = smf.ols(formula='만족도 ~ 적절성', data=df).fit() print(model.summary()) # 모델의 요약결과(능력치)를 출력 # OLS Regression Results # ============================================================================== # Dep. Variable: 만족도 R-squared: 0.523 # Model: OLS Adj. R-squared: 0.521 # Method: Least Squares F-statistic: 275.8 # Date: Tue, 15 Nov 2022 Prob (F-statistic): 2.40e-42 # Time: 11:26:39 Log-Likelihood: -189.38 # No. Observations: 254 AIC: 382.8 # Df Residuals: 252 BIC: 389.8 # Df Model: 1 # Covariance Type: nonrobust # ============================================================================== # coef std err t P>|t| [0.025 0.975] # ------------------------------------------------------------------------------ # Intercept 0.9868 0.136 7.282 0.000 0.720 1.254 # 적절성 0.6823 0.041 16.609 0.000 0.601 0.763 # ============================================================================== # Omnibus: 4.938 Durbin-Watson: 2.259 # Prob(Omnibus): 0.085 Jarque-Bera (JB): 5.518 # Skew: -0.181 Prob(JB): 0.0633 # Kurtosis: 3.624 Cond. No. 15.1 # ==============================================================================
📌 ols 모델 summary표 분석
- 회귀 모델 summary 결과
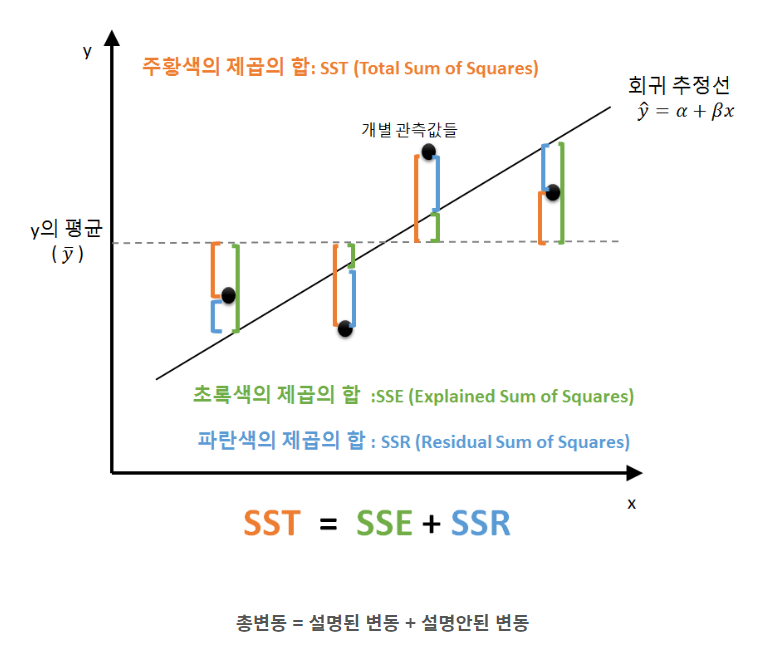
# OLS Regression Results # ============================================================================== # Dep. Variable: 만족도 R-squared: 0.523 # Model: OLS Adj. R-squared: 0.521 # Method: Least Squares F-statistic: 275.8 # Date: Tue, 15 Nov 2022 Prob (F-statistic): 2.40e-42 # Time: 11:26:39 Log-Likelihood: -189.38 # No. Observations: 254 AIC: 382.8 # Df Residuals: 252 BIC: 389.8 # Df Model: 1 # Covariance Type: nonrobust # ============================================================================== # coef std err t P>|t| [0.025 0.975] # ------------------------------------------------------------------------------ # Intercept 0.9868 0.136 7.282 0.000 0.720 1.254 # 적절성 0.6823 0.041 16.609 0.000 0.601 0.763 # ============================================================================== # Omnibus: 4.938 Durbin-Watson: 2.259 # Prob(Omnibus): 0.085 Jarque-Bera (JB): 5.518 # Skew: -0.181 Prob(JB): 0.0633 # Kurtosis: 3.624 Cond. No. 15.1 # ==============================================================================1. 상관계수, 표준오차, 결정계수의 관계
[ R-squared ]
- 결정계수 (분산의 설명력)
- 독립변수 x가 종속변수 y의 분산을 얼마나 잘 설명하는 지를 나타내는 확률
- R-squared = 0.523 == 52.3% 설명력
- 높을수록 좋음
[ Adj. R-squared ]
- 다중선형회귀일 때 사용하는 결정계수
- 독립변수가 2개 이상일 때 사용한다.
- 높을수록 좋음
[ std err ]
- 표준오차값
- 모집단에서 표본집단을 추출하여 나온 표본평균들의 표준편차
- 각 표본의 평균 간의 표준화된 차이
- 표준편차가 작을수록 각 표본간의 차이가 작고, 모집단과 표본간의 차이도 작아진다.
- std err = 0.041
- 낮을수록 좋음
[ 상관계수와 표준오차와 결정계수의 관계 ]
- 상관계수가 높으면 데이터간의 밀도가 높아지고 표준오차가 작아지고 결정계수는 높아진다.
↪ 모델 회귀식의 정확도가 높다.
↪ 모델이 도출한 결과의 정확도가 높다.
2. t-value, F-value, p-value의 관계
[ t-value 분석 ]
- 두 개 집단의 평균 차이를 구함
- 기울기 / 표준오차 == t-value
- 높을수록 좋음
[ F-statistic ]
- 세 개 이상의 집단의 평균 차이를 구함
- t-value의 거듭제곱한 값
- 높을수록 좋음
[ Prob (F-statistic) ]
- p-value
- p-value = 2.40e-42
→ 모델의 성능을 파악하는 p-value이다.
→ p-value < 0.05 이므로 유의미한 결과를 도출 가능
→ 해당 회귀 모델은 적합하다. == 유의하다.
→ 모델의 성능이 좋음
- 낮을수록 좋음
[ t, F 값과 p-value의 관계 ]
- t-value, F-value의 크기가 커질수록 p-value의 값은 낮아진다.
↪ 유의수준 안에 있으면 모델이 적합성을 만족
↪ 모델이 문제를 해결하기에 적합하다.
3. 모델의 함수식 파악
[ 기울기와 편향 ]
- 상관관계의 밀도와 상관없이 패턴이 같으면 동일한 기울기와 편향을 제공한다.
- 같은 함수식을 갖는 모델이라도 아래의 요소들을 확인해 모델 성능을 판단해야한다.1) p-value가 유의수준 안에 있으면 좋은 모델이라고 판단할 수 있다.
2) 표준오차가 낮아지고 분산의 설명력(결정계수)가 높아지면 좋은 모델이라고 판단할 수 있다.
[ 회귀 모델 f(x) ]
y^hat = 0.6823 * x + 0.9868
4. 모델 왜도와 첨도 및 잔차의 독립성 확인
- Durbin-Watson : 자기 상관 (잔차의 독립성) -> 2에 가까울수록 좋음
- Skew : 왜도 -> 기본은 0, +는 왼쪽, -는 오른쪽으로 쏠림
- Kurtosis : 첨도 -> 기본은 0, +는 뽀족, -는 완만
📊 다중 선형 회귀
📌 다중 선형 회귀분석이란?
- 정의
- 단순 선형회귀와는 다르게 독립변수(feature)가 2개 이상일 때, 다중 선형 회귀분석을 사용한다.
📌 ols 모델의 다중선형회귀 분석
- 모델 생성
- smf.ols(formula='label ~ feature1 + feature2', data=데이터프레임)
📌 ols 모델의 다중선형회귀 실습
- 1. 라이브러리 Import
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import statsmodels.formula.api as smf
- 2. 데이터 준비
data = pd.read_csv('../testdata/student.csv') print(data.head(3)) # 이름 국어 영어 수학 # 0 박치기 90 85 55 # 1 홍길동 70 65 80 # 2 김치국 92 95 76
- 3. 결측치 확인
print(data.info()) # 0 이름 20 non-null object # 1 국어 20 non-null int64 # 2 영어 20 non-null int64 # 3 수학 20 non-null int64 print(data.isnull().sum()) # 이름 0 # 국어 0 # 영어 0 # 수학 0 # 결측값 존재하지 않음
- 4. 이상치 확인
print(data.describe()) # 국어 영어 수학 # count 20.000000 20.000000 20.000000 # mean 72.900000 71.750000 73.700000 # std 23.834738 19.931131 17.747053 # min 20.000000 30.000000 40.000000 # 25% 58.750000 63.750000 63.250000 # 50% 82.500000 70.000000 80.000000 # 75% 90.500000 87.000000 84.000000 # max 100.000000 100.000000 100.000000 # 국어와 영어 변수에 이상치가 있을 확률이 높음 # -> boxplot으로 확인 plt.boxplot(data.iloc[:, 1:]) plt.show() # 정량 데이터인 국어, 영어, 수학 변수를 확인했을 때, 이상치는 확인되지 않음
- 5. 상관관계 분석 : feature(국어, 영어), label(수학)
data = data.loc[:, ['국어', '영어', '수학']] print(data.corr()) # 국어 영어 수학 # 국어 1.000000 0.915188 0.766263 # 영어 0.915188 1.000000 0.809668 # 수학 0.766263 0.809668 1.000000 # 상관계수 분석 # 영어와 수학 : 양의 방향으로 강한 관계를 갖는다. -> 상관관계 만족 # 국어와 수학 : 양의 방향으로 살짝 강한 관계를 갖는다. -> 상관관계 만족
- 6. 상관관계 그래프 시각화
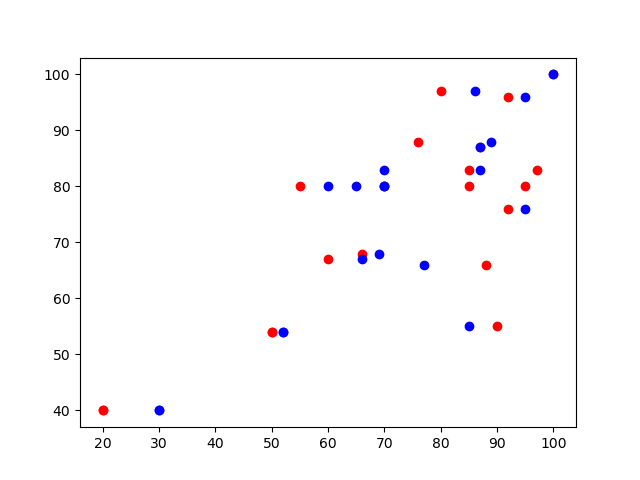
x1 = data['국어'] x2 = data['영어'] y = data['수학'] plt.scatter(x1, y, color='r') plt.scatter(x2, y, color='b') plt.show() # 전체적으로 우상향 그래프를 그린다. + 밀도가 높다. => 모델의 적확성을 만족할 확률이 높다.
- 7. 다중 선형회귀모델 생성 : feature(국어, 영어), label(수학)
# 7. 다중 선형회귀모델 생성 : feature(국어, 영어), label(수학) model = smf.ols(formula='수학 ~ 국어+영어', data=data).fit() print(model.summary()) # OLS Regression Results # ============================================================================== # Dep. Variable: 수학 R-squared: 0.659 # Model: OLS Adj. R-squared: 0.619 # Method: Least Squares F-statistic: 16.46 # Date: Tue, 15 Nov 2022 Prob (F-statistic): 0.000105 # Time: 16:21:32 Log-Likelihood: -74.617 # No. Observations: 20 AIC: 155.2 # Df Residuals: 17 BIC: 158.2 # Df Model: 2 # Covariance Type: nonrobust # ============================================================================== # coef std err t P>|t| [0.025 0.975] # ------------------------------------------------------------------------------ # Intercept 22.6238 9.482 2.386 0.029 2.618 42.629 # 국어 0.1158 0.261 0.443 0.663 -0.436 0.667 # 영어 0.5942 0.313 1.900 0.074 -0.066 1.254 # ============================================================================== # Omnibus: 6.313 Durbin-Watson: 2.163 # Prob(Omnibus): 0.043 Jarque-Bera (JB): 3.824 # Skew: -0.927 Prob(JB): 0.148 # Kurtosis: 4.073 Cond. No. 412. # ============================================================================== # 다중 선형회귀 ols모델 summary 결과 분석 # 1) 모델 p-value = 0.000105 < 0.05 이므로 모델이 해당 문제를 풀기에 적합하다.(유의미하다) = 모델 적합성 만족 # 1-1) 국어 p-value = 0.663 > 0.05 이므로 해당 독립변수는 유의미한 결과를 도출하기에는 부족하다고 판단 = 독립변수 적합성 불만족 -> 데이터 전처리 필요 # 1-2) 영어 p-value = 0.074 > 0.05 이지만 유의수준에서 별로 차이가 없다고 판단하여 적합하다고 판단 = 독립변수 적합성 만족 # 2) Adj. R-squared = 0.619 = 61.9% 결정력이므로 모델이 도출한 결과가 결정력있게 정확한 값을 도출한다. = 모델 정확성 만족 # 3) Skew = -0.927 = 왜도가 음수이므로 정규분포가 오른쪽으로 쏠려있다. # 4) Kurtosis = 4.073 = 첨도가 0보다 크므로 정규분포는 뾰족한 형태를 띈다.[ 다중 선형회귀 ols모델 summary 결과 분석 ]
1) 모델 p-value = 0.000105 < 0.05 이므로 모델이 해당 문제를 풀기에 적합하다.(유의미하다)
→ 모델 적합성 만족1-1) 국어 p-value = 0.663 > 0.05 이므로 해당 독립변수는 유의미한 결과를 도출하기에는 부족하다고 판단
→ 독립변수 적합성 불만족
→ 데이터 전처리 필요1-2) 영어 p-value = 0.074 > 0.05 이지만 유의수준에서 별로 차이가 없다고 판단하여 적합하다고 판단
→ 독립변수 적합성 만족2) Adj. R-squared = 0.619 = 61.9% 결정력이므로 모델이 도출한 결과가 결정력있게 정확한 값을 도출한다.
→ 모델 정확성 만족3) Skew = -0.927 = 왜도가 음수이므로 정규분포가 오른쪽으로 쏠려있다.
4) Kurtosis = 4.073 = 첨도가 0보다 크므로 정규분포는 뾰족한 형태를 띈다.
- 8. 예측값, 실제값 비교
print('실제값 : \n', y[:5]) print('예측값 : \n', model.predict(data.loc[:, ['국어', '영어']])[:5]) # 실제값 : # 0 55 # 1 80 # 2 76 # 3 88 # 4 83 # 예측값 : # 0 83.553470 # 1 69.353332 # 2 89.727038 # 3 84.308871 # 4 85.552547
- 9. 실제 예측
ko_w = model.params[1] en_w = model.params[2] b = model.params[0] x_ko = int(input('국어점수 : ')) x_en = int(input('영어점수 : ')) print(f'국어점수 {x_ko}, 영어점수 {x_en}에 대한 수학점수는 ', (ko_w * x_ko) + (en_w * x_en) + b) # 국어점수 100, 영어점수 100에 대한 수학점수는 93.62451049715798