
📊 회귀모델의 적합성을 위한 5가지 요소
📌 적합성을 위한 5가지 요소
- 요소 소개
1) 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다.
(정규분포 따라야해~!)2) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다.
(제3 정규성 만족~!)3) 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 일정한 패턴(비선형)을 가지면 안된다.
(상관관계 비선형 안돼~!)4) 등분산성 : 독립변수들의 잔차의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포해야 한다.
(분산이 동등하게~!)5) 다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다.
(독립변수간에 너무 강한 상관관계 안돼~!)
📌 0. 모델 적합성 확인을 위한 사전 준비
- 잔차 구하기
- 잔차 = 실제값 - 예측값# 예측값 y_pred = model.predict(data.iloc[:, :2]) # 실제값 y = data['sales'] # 잔차 residual = y - y_pred print('잔차 : \n', residual) # 0 1.544535 # 1 -1.945362 # 2 -3.037018 # 3 0.882884 # 4 -0.323908 # ... # 195 2.235488 # 196 1.547625 # 197 0.031952 # 198 1.707077 # 199 -1.757543
📌 1. 정규성 만족 확인
- 포인트
- 잔차항이 정규분포를 따르는지 확인
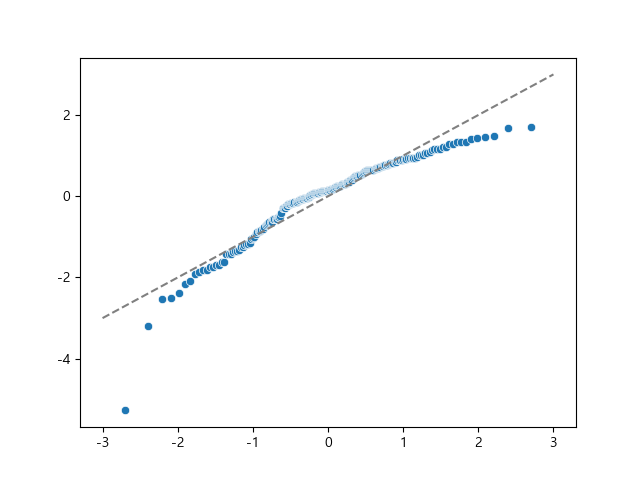
1) Q-Q plot 사용
[ 필요 라이브러리 ]
import scipy.stats as stats[ 그래프 생성 ]
sr = stats.zscore(residual) (x, y), _ = stats.probplot(sr) sns.scatterplot(x, y) # 정규분포 추세선을 따르는 점(scatter) 찍기 plt.plot([-3, 3], [-3, 3], '--', color='grey') # 추세선 그리기 plt.show()
[ 정규성 결과 분석 ]
- 추세선 양쪽에 추세선을 따르지 않는 잔차 데이터가 존재
→ 정규성 불만족
2) stats.shapiro() 메소드 사용
[ 필요 라이브러리 ]
import scipy.stats as stats[ 정규성 p-value 출력 ]
print('정규성 : ', stats.shapiro(residual).pvalue) # 정규성 : 4.190036317908152e-09[ 정규성 결과 분석 ]
- p-value = 0.00 < 0.05
→ 유의확률이 유의수준 안에 속한다.
→ 정규성 불만족
- 해결 방법
[ feature scaling 필요 ]
- 데이터 log 취하기
- Std Scaler : 데이터 표준화 스케일링 (평균0, 표준편차1)
- MinMax Scaler : 최소0, 최대1 값을 갖도록 스케일링
- Normalizer : 데이터 정규화 스케일링 (유클리디안 거리 1)
📌 2. 독립성 만족 확인
- 포인트
- 독립변수 간의 관련성이 없어야 한다. (제 3 정규성 만족 여부 확인)
1) Durbin-Watson 지표 사용 (모델 Summary 확인)
[ Durbin-Watson 지표 특징 ]
- 잔차의 독립성 만족여부 확인 가능
- 2에 근사할수록 자기상관이 없다.
- 0(양의상관) < 2(독립성 만족) > 4(음의상관)[ 독립성 결과 분석 ]
Durbin-Watson : 2.081→ 2에 가까운 값을 갖는다.
→ 독립성 만족
📌 3. 선형성 만족 확인
- 포인트
- 예측값과 잔차가 특정 패턴없이 비슷하게 유지되어야 함
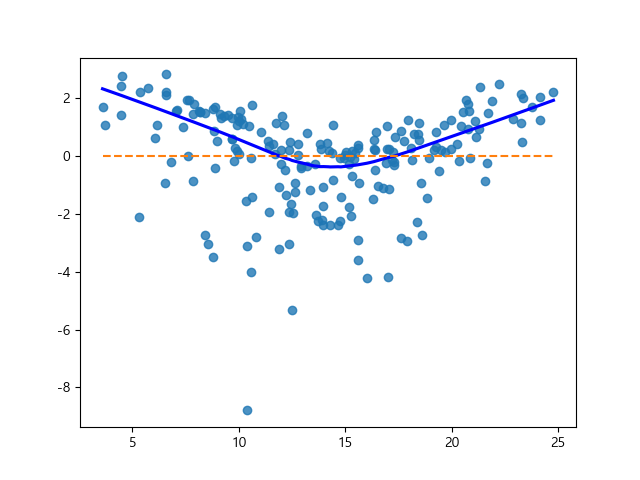
1) sns.regplot 그래프 사용
[ 필요 라이브러리 ]
import seaborn as sns[ 그래프 생성 ]
sns.regplot(y_pred, residual, lowess=True, line_kws={'color':'blue'}) plt.plot([y_pred.min(), y_pred.max()], [0,0], '--') plt.show()
[ 선형성 결과 분석 ]
→ 특정한 비선형 패턴을 그린다.
→ 선형성 불만족
📌 4. 등분산성 만족 확인
- 포인트
- 독립변수들의 오차의 분산이 특정 패턴없이 일정해야 한다.
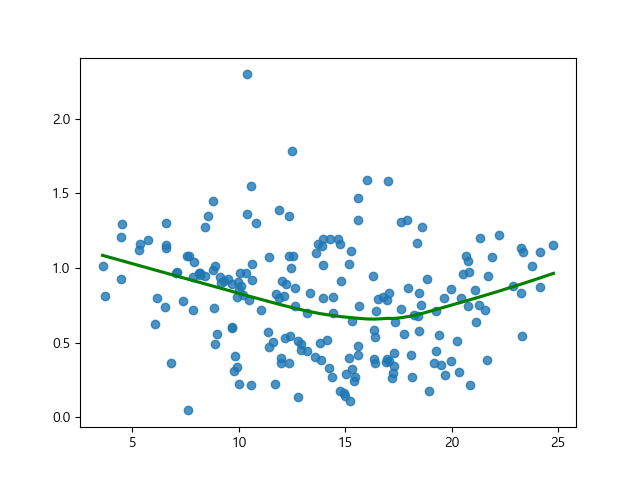
1) sns.regplot 그래프 사용
[ 필요 라이브러리 ]
import seaborn as sns[ 그래프 생성 ]
sns.regplot(y_pred, np.sqrt(np.abs(sr)), lowess=True, line_kws={'color':'green'}) plt.show()
[ 등분산성 결과 분석 ]
→ 오차의 분산이 특정한 비선형 패턴을 그린다.
→ 등분산성 불만족
- 해결 방법
- 이상치 확인
- 정규성 확인
→ 정규성 만족, 등분산성 불만족 시, 가중회귀모델 사용
📌 5. 다중공선성 만족 확인
- 포인트
- 독립변수들 간에 강한관계를 갖지 않는 것을 확인
1) VIF(분산팽창계수) 사용
[ VIF 특징 ]
- VIF가 10을 넘으면 다중공성성을 불만족
- 5를 넘으면 주의 필요[ 필요 라이브러리 ]
from statsmodels.stats.outliers_influence import variance_inflation_factor[ feature별 VIF 지수 확인 ]
print(data.columns[0], ' : ', vif(data.values, 1)) print(data.columns[1], ' : ', vif(data.values, 2)) # tv : 12.570312383503682 # radio : 3.1534983754953845[ 다중공선성 결과 분석 ]
→ tv 독립변수는 10을 넘어 다중공선성 불만족
→ radio 독립변수는 5를 넘지 않아 다중공선성 만족
→ tv feature에 대한 해결책 필요
📊 모델 저장 및 읽기
📌 필요 라이브러리
- 라이브러리 Import
import joblib
📌 모델 저장
- 모델 저장
joblib.dump(model, 'lm_model.model')
📌 모델 읽기
- 모델 읽기
lm = joblib.load('lm_model.model') print(lm) # <statsmodels.regression.linear_model.RegressionResultsWrapper object at 0x000001BB9C321E80>
