카프카 토픽에 값 입력
bin/kafka-topic.sh --create 옵션을 사용하여 토픽을 생성하였고, 파티션을 추가, 토픽 데이터 유지 시간 변경등을 실습하였다.
이번엔 이렇게 세팅된 토픽에 데이터를 넣는 작업을 진행 해 보도록 하겠다.
생성된 토픽에 데이터를 넣을 수 있는 명령어는 kafka-console-producer.sh 이다.
토픽에 넣는 데이터는 레코드라고 불리며 메시지 키와 값으로 이루어져 있다.
키와 값 쌍으로 데이터를 전송 할 수 도 있지만, 값만 전송할 수 도 있게 할 수 도 있다.
이렇게 값만 보낼 때에는 키는 자바의 null로 기본 설정되어 브로커에 전달 된다.
키 없는 레코드 전송
bin/kafka-console-producer.sh --bootstrap-server {aws IP} --topic hello.kafka
>hello
>deuk명령어를 입력하고 뒤에 나오는 콘솔창 > 뒤에 메시지를 입력 후 엔터를 누르면 메시지가 전송된다.
여기서 알아 두어야 할 점은 kafka-console-producer.sh로 전송 되는 레코드 값은 UTF-8 기반으로 Byte로 변환되고 ByteArraySerializer로만 직렬화 된다는 점이다.
String 타입이 아닌 다른 타입으로는 직렬화하여 전송할 수 없다. 다른 타입을 직렬화 해서 전송하려면 카프카 프로듀서를 커스터마이징하여 사용하면 된다.
키 있는 레코드 전송
bin/kafka-console-producer.sh --bootstrap-server {aws IP} \
> --topic hello.kafka \
> --property "parse.key=true" \
> --property "key.separator=:"
>key1:hi
>key2:world위의 명령어의 속성 중 parse.key를 true로 두면 레코드를 전송할 때 메시지 키를 설정할 수 있다.
메시지 키와 값은 기본적으로 tab(\t)으로 구분을 하는데, key.separator를 사용하여 구분자를 변경하여 사용할 수 도 있다.
여기서 구분자를 설정하고 해당 구분자를 사용하지 않으면, KafkaException과 함께 종료된다.
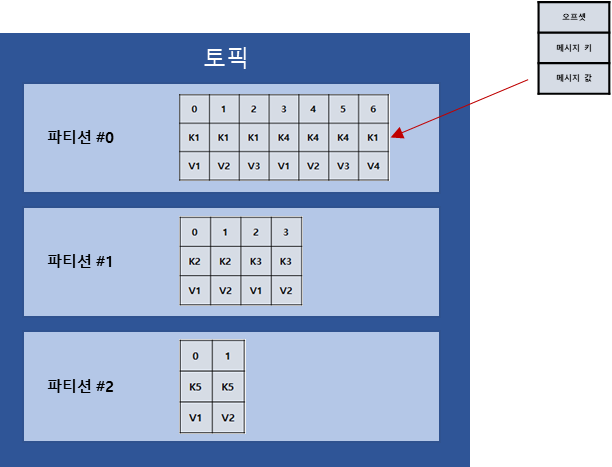
키와 메시지가 함께 전송된 레코드는 토픽의 파티션에 저장이 된다.
키값이 null인 경우 프로듀서가 파티션으로 전송을 할 때 레코드 배치 단위(전송 묶음)로 라운드 로빈으로 전송한다.
메시지 키가 존재하면, 키의 해시값을 작성하여 해당 파티션 중 하나로 할당이 되는데, 이로 인해 메시지 키가 동일한 경우에는 동일한 파티션으로 전송된다.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
hello-group hello.kafka 3 2 2 0 - - -
hello-group hello.kafka 2 0 0 0 - - -
hello-group hello.kafka 1 1 1 0 - - -
hello-group hello.kafka 0 1 1 0 - - -
---
bin/kafka-console-producer.sh --bootstrap-server {aws IP} --topic hello.kafka --property "parse.key=true" --property "key.separator=:"
>key1:sdfdsfds
>key1:dsfsdfsdfdsfdssd
---
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
hello-group hello.kafka 3 2 2 0 - - -
hello-group hello.kafka 2 0 0 0 - - -
hello-group hello.kafka 1 1 1 0 - - -
hello-group hello.kafka 0 3 3 0 - - -
파티션 0을 보면 처음에는 current-offset이 1개였지만 key1 키를 사용하는 레코드를 2개를 추가적으로 전송을 하였더니 3으로 변경이 되었다. 이것을 볼 때 처음에 전송하였던 key1:hi는 파티션 0에 할당 되었고, 추가적으로 전송된 값들도 파티션 0으로 들어간 것을 알 수 있다.
카프카 토픽 값 수신
카프카 토픽으로 전송한 데이터는 kafka-console-consumer.sh로 확인 할 수 있다.
--from-beginning 옵션을 주게 되면 가장 처음 데이터 부터 출력한다.
키 없이 메시지만 확인
bin/kafka-console-consumer.sh --bootstrap-server {aws IP} \
> --topic hello.kafka \
> --from-beginning
hello
world
deuk
hi키와 메시지 함께 확인
bin/kafka-console-consumer.sh --bootstrap-server 54.183.147.139:9092 \
> --topic hello.kafka \
> --property print.key=true \
> --property key.separator="-" \
> --group hello-group \
> --from-beginning
null-hello
key2-world
null-deuk
key1-hi메시지 키를 확인 하기 위해서 print.key=true를 선언한다. => 기본은 false
메시지 키를 구분하기 위한 구분자를 설정한다. key.separator="구분자" => 기본값 Tab(\t)
신규 컨슈머 그룹을 선언하기 위해서 --group을 선언한다. 없으면 여기서 그룹이 생성된다.
해당 컨슈머 그룹을 통해 가져간 토픽의 메시지는 가져간 메시지에 대해 커밋을 한다.
커밋?
커밋은 컨슈머가 특정 레코드를 처리 완료했다고 레코드의 오프셋 번호를 카프카 브로커에 저장하는 것을 말한다.
커맛 정보는 __consumer_offsets 이름으로 내부 토픽에 저장된다.
위에 결과를 확인하면 사용자가 넣은 순서대로 출력이 되지는 않는것으로 확인된다.
이것은 파티션 개념 때문에 생기는 것으로, 동일한 중요도로 consumer가 가져갈 때 순서 상관 없이 가져가서 생기는 현상이다. 순서에 맞게 가져가기 위해서는 파티션을 1개로 설정하면 가능하다. 하나의 파티션에서는 순서를 보장한다.
카프카 컨슈머 그룹
카프카 컨슈머가 수신을 할 때 그룹으로 지정하여 받았다. 이것은 자동으로 해당 레코드들이 지정된 그룹으로 등록이 되는데
현재 등록된 그룹 리스트를 확인 하기 위해서는 bin/kafka-consumer-groups.sh 명령어로 확인 할 수 있다.
bin/kafka-consumer-groups.sh --bootstrap-server 54.183.147.139:9092 --list
hello-group해당 그룹이 가져간 토픽의 데이터 정보를 확인 하기 위해서는 --describe 옵션으로 확인할 수 있다.
bin/kafka-consumer-groups.sh --bootstrap-server 54.183.147.139:9092 --group hello-group --describe
Consumer group 'hello-group' has no active members.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
hello-group hello.kafka 3 2 2 0 - - -
hello-group hello.kafka 2 0 0 0 - - -
hello-group hello.kafka 1 1 1 0 - - -
hello-group hello.kafka 0 3 3 0 - - ---group을 통해 어떤 그룹을 확인 할 것인지 작성을 할 수 있다.
- GROUP, TOPIC, PARTITION은 컨슈머 그룹이 마지막으로 커밋한 토픽과 파티션을 나타낸다.
- CURRENT-OFFSET은 컨슈머 그룹이 가져간 가장 최신의 오프셋을 나타낸다.
- LOG-END-OFFSET은 그룹의 컨슈머가 어느 오프셋까지 커밋했는지 알 수 있다.
- LAG(랙)은 컨슈머 그룹이 토픽의 파티션에 있는 데이터를 가져가는데 얼마나 지연이 발생하는지 나타내는 지표이다. 커밋한 오프셋과 현재 최신 오프셋이 같으면 0으로 표시된다.
해당 상세 정보는 컨슈머를 개발할 때, 카프카를 운영할 때 둘다 중요하게 사용된다.
그룹이 중복이 되지는 않는지, 랙이 증가하고 있는지 확인하여 컨슈머 상태를 최적화 하는데 도움을 준다.
카프카 운영시 컨슈머 그룹을 알아내고 상세정보를 파악하면, 카프카에 연결된 컨슈머의 호스트 명 or IP를 알애낼 수 있다. 이렇게 되면 인가한 사람에게만 사용중인지도 알아 낼 수도 있다.
