Kafka
1.Kafka에 대하여

비즈니스 소셜 네트워크 사이트인 LinkedIn에서 파편화된 데이터 수집 및 분배 아키텍처를 운영하는 데에 큰 어려움을 겪었다. 서비스가 커지면서 애플리케이션의 개수가 점점 많아져 데이터 전송라인이 기하급수적으로 많아져 복잡해지기 시작했다.이것을 극복하기 위하여 각각의
2.Kafka 학습을 위한 AWS 서버 구축
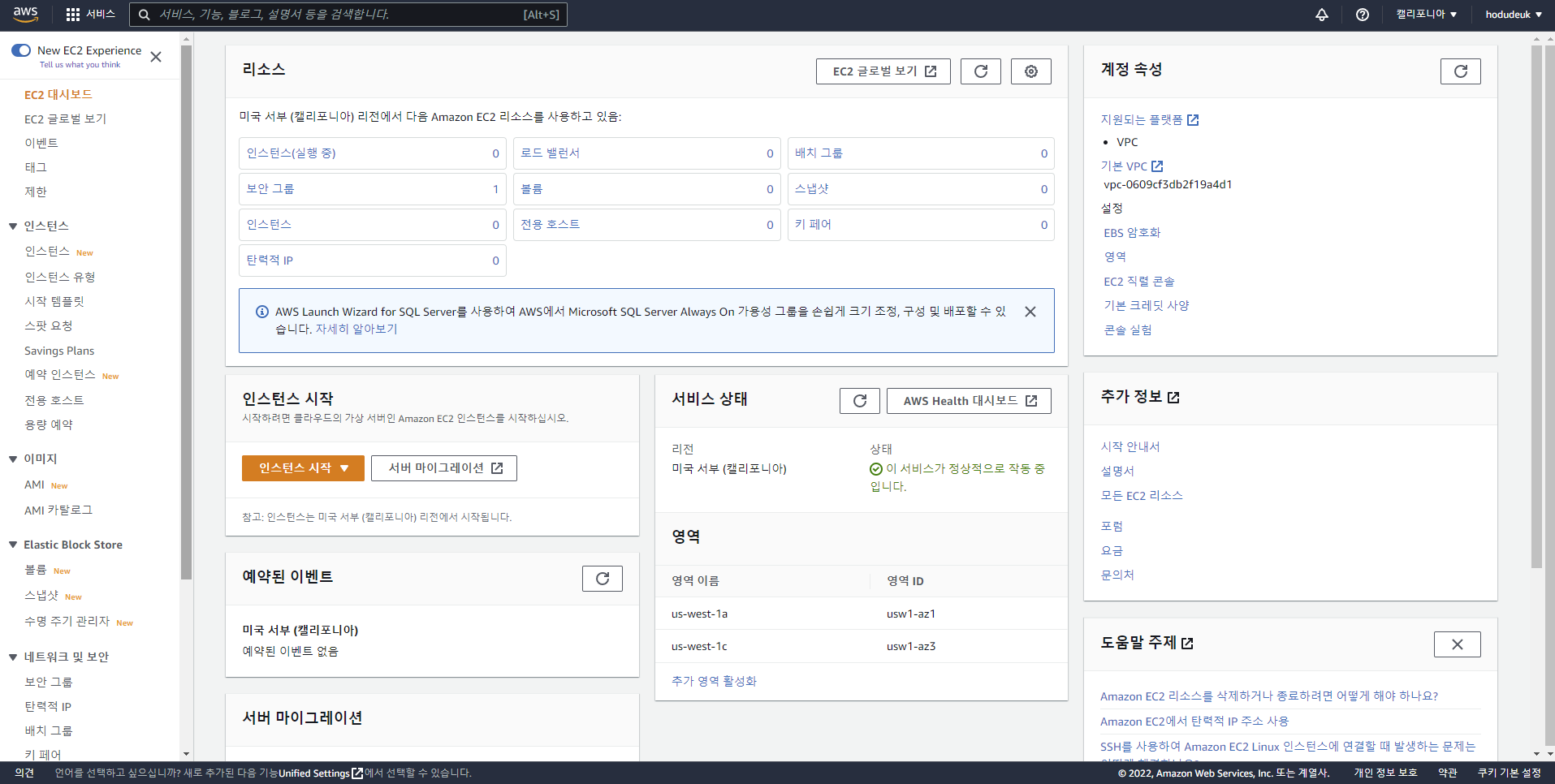
AWS 클라우드 서버를 사용하기 위하여 가입을 진행 한 후 콘솔로 이동을 한다.최근 방문 서비스에는 처음이면 여러 서비스를 추천해준다.해당 메뉴에서 EC2를 선택하여 EC2 관리 콘솔로 진입한다.가운데 보이는 인스턴스 시작 버튼을 눌러 EC2 프로젝트를 하나 생성한다.
3.Kafka Broker, Zookeeper 설치
카프카 브로커를 설치하기 앞서 카프카를 실행하기 위한 자바를 설치하도록 한다.카프카는 스칼라와 자바로 작성되어 JVM 환경 위에서 실행된다.자바는 Open JDK를 사용할 예정이다.설치가 완료되었으면 자바가 잘 설치 되었는지 확인한다.위와 같이 자바 버전에 나오면 성공
4.카프카 브로커 실행

카프카를 실행하기 앞서 config 폴더에서 server.properties 파일을 설정하여 클러스터 운영에 필요한 옵션들을 지정할 수 있다. Kafka 설정파일 카프카의 브로커 번호를 지정하는 역할을 수행, 클러스터를 구축할 때 브로커들을 구분하기 위한 단 하나뿐
5.Kafka Topic

카프카는 커멘드 라인 툴을 지원하는데,카프카 브로커 운영에 가장 많이 접하는 도구이다.브로커를 운영할 때 다양한 명령어를 내릴 수 있다.커멘드 라인 툴을 사용하는 방법은 SSH를 통하여 사용하는 방법과 카프카를 사용하기 위해 열어논 포트로 접속할 수 있는 컴퓨터로 접속
6.Kafka 데이터 전송 및 수신
bin/kafka-topic.sh --create 옵션을 사용하여 토픽을 생성하였고, 파티션을 추가, 토픽 데이터 유지 시간 변경등을 실습하였다.이번엔 이렇게 세팅된 토픽에 데이터를 넣는 작업을 진행 해 보도록 하겠다.생성된 토픽에 데이터를 넣을 수 있는 명령어는 ka
7.Kafka Produce, Consumer 간편 테스트
kafka-console-producer, kafka-console-consumer을 통하여 직접 토픽에 데이터를 넣고 전달하는 것으로 테스트를 할 수 도 있지만, 단순히 명령어 만으로 테스트를 할 수 있는 것이 있다.해당 명령어는 String 타입의 메시지 값을 코드
8.카프카 브로커
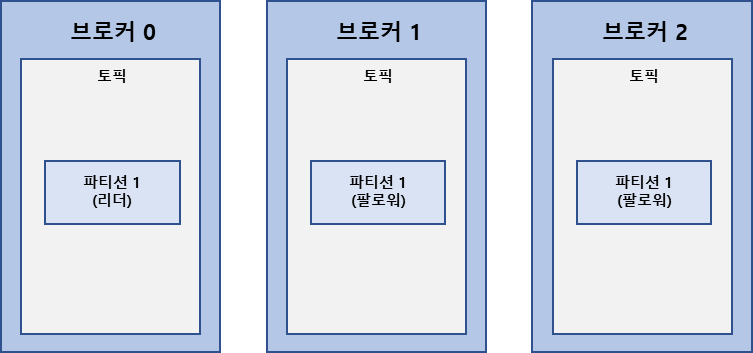
카프카 브로커는 카프카 클라이언트와 데이터를 주고 받기 위해 사용하는 주체또한 브로커는 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션이다.하나의 서버에는 기본적으로 1개의 카프카 프로세스가 실행된다.카프카를 사용할 때 조금
9.카프카 클러스터

브로커들로 구성되어 있는 클러스터는 1개의 리더 브로커와 팔로워로 구성이 된다.이 다수의 브로커들 중 하나가 컨트롤러 역할을 수행한다.컨트롤러의 역할은 브로커들의 상태를 체크하고 브로커가 클러스터에서 빠지는 경우에는 브로커에 존재하는 리더 파티션을재분배한다.컨트롤러 임
10.주키퍼
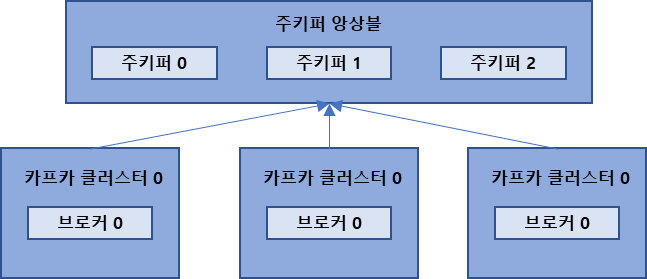
주키퍼는 카프카의 메타데이터를 관리하는데 사용한다.주키퍼는 분산 애플리케이션을 위한 코디네이션 시스템으로 더욱 안정적인 서비스를 할 수 있도록 분산 애플리케이션의 정보를 중앙에 집중하고 구성관리, 그룹 관리네이밍, 동기화등의 서비스를 제공한다.카프카 클러스터로 묶인 브
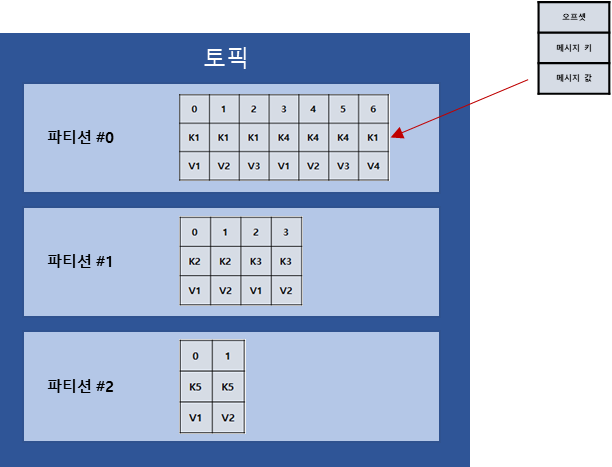
11.토픽, 파티션
토픽은 카프카에서 데이터를 구분하기 위해 사용하는 단위이다. 토픽 내부에는 기본적으로 1개의 파티션이 있고, 프로듀서가 보낸 데이터(레코드)들이 저장되어있다. 파티션은 카프카의 병렬처리의 핵심이다.
12.레코드
토픽의 파티션에 저장되는 데이터를 '레코드'라고 일컷는다고 저번에 학습을 하였다.레코드는 타임스탬프, 메시지 키, 메시지 값, 오프셋, 헤더로 구성되어 있다.프로듀서가 브로커에 레코드를 전송하면 오프셋과 타임스탬프가 지정되어 저장된다.브로커에 저장된 레코드는 수정 할
13.카프카 클라이언트 - 프로듀서 API
카프카 클러스터에 명령을 내리거나 데이터를 송수신하기 위해 카프카 클라이언트 라이브러리는카프카 프로듀서, 컨슈머, 어드민 클라이언트를 제공하는 카프카 클라이언트를 사용하여 애플리케이션을 개발한다.카프카 클라이언트는 라이브러리이기 때문에 라이프사이클을 가진 프레임워크나